Рекомендации по написанию sqlзапросов в Хранилище данных Oracle dwh
 Скачать 244 Kb. Скачать 244 Kb.
|

 Рекомендации по написанию SQL-запросов в Хранилище данных Oracle DWH. Введение Оптимизатор Постулаты Как оптимизировать запрос. Основы Как узнать, что делает запрос и получить список плохих запросов План выполнения запроса Подсказки Оптимизатору (hints) План выполнения запроса (Explain Plan) Эффективный SQL запрос Часто используемые запросы за длительный период времени Секционированные таблицы Параллельность выполнения запросов Агрегаты Что делать не нужно Использование индексов Использование собственных таблиц Использование сложных запросов Использование аналитических функций Полезные ссылки Контакты УАС Клыпо Д.А. daklypo@rsb.ru Заблотный А.В. azablotniy@rsb.ru Введение Под управлением сервера Oracle хранятся и обрабатываются значительные объемы данных. Поэтому, чтобы не допустить ухудшения характеристик отдельных выполняемых операций, так и всей системы в целом, требуется использование специальных методов, повышающих скорость доступа к данным. По разным оценкам, общая производительность при выполнении задач на 15-20% зависит от настройки базы данных, а остальные 80-85% приходятся эффективное написание запроса. Оптимизатор Оптимизатор представляет собой программный продукт, который является важнейшей частью сервера Oracle и предназначен для оптимизации — поиска наиболее эффективного способа доступа к данным. Оптимизатор должен выбрать такую последовательность действий, которая обеспечит самый эффективный путь доступа к данным, и сформировать план выполнения запроса, основанный на найденных методах доступа. Под методом доступа (access path) подразумевается вариант алгоритма доступа, а под планом выполнения (execution plan) — последовательность выполняемых действий, которые обеспечивают выбранные методы доступа Основным оптимизатором является Оптимизатор по стоимости (cost-based optimizer) — оптимизатор, основанный на анализе накладных затрат системы. Для этого оптимизатора выбор метода доступа основан на хранимой внутренней статистике. Под статистикой понимаются точные или аппроксимированные сведения о распределении значений данных в таблицах. Для построения наилучшего плана требуется регулярно собирать статистику по таблицам. Стоимость – это величина относительная и зависит от многих факторов, которые очень часто находятся в неактуальном состоянии. Поэтому ориентироваться на низкую стоимость при оптимизации запросов нельзя. И утверждение «Чем ниже стоимость, тем быстрее выполниться запрос» - НЕВЕРНО!! Постулаты Ресурсы сервера ограничены. Каждый запрос потребляет процессорные мощности, использует память и диски. При этом неоптимизированные запросы могут потреблять неоправданно много ресурсов, мешая работе системным процессам и остальным пользователям. Поэтому, если оптимизированный скрипт начал выполняться не приемлемо, это заслуга других пользователей. Примечание Утилизацию ресурсов сервера можно посмотреть на портале: http://wh.rs.ru/monitor/dwh_ulilization.php Не бывает быстро или медленно - ТОЛЬКО приемлемо или нет! Из-за разной утилизации ресурсов сервера, запрос может выполняться различное время. Как оптимизировать запрос. Основы Для того чтобы составить эффективный план запроса необходимо: Закрепить план выполнения запроса Изучить структуру Хранилища: структуру таблиц: типы полей, партиции, индексы (http://wh.rs.ru/doc/tables.html) понимать источники данных Хранилища (http://wh.rs.ru/official/DWH.jpg) понимать как и во сколько обновляются таблицы (http://wh.rs.ru/monitor/monitoring.php?full=1) Изучить данные: распределение данных селективность полей взаимозаменяемость информации – возможно, то, что нужно, можно получить другим (более простым) способом Уменьшать объем чтений при помощи: использования агрегатов схемы MART секционированных таблиц дополнительных фильтров по данным при помощи материализации собственных агрегатов Знать приблизительную выборку в запросе каждой таблицы Знать в «какой последовательности» и «каким способом» соединить таблицы в запросе А также: Запрос должен быть обязательно структурирован и форматирован в читабельном виде (это требование не только для эстетического удовлетворения, но и один стиль написания запросов позволяет Oracle’у наиболее эффективно работать). Пример
Примечание. В PL/SQLDeveloper’е есть специальная опция, которая форматирует запрос.  Если запрос работает более 4-х часов или читает undo(сегмент отката), то пора заняться оптимизацией запроса. Если запрос читает более 100ГБ или потребляет более 0.1% CPU ), то пора заняться оптимизацией запроса. Примечание. Что делает запрос можно посмотреть по ссылке http://wh.rs.ru/monitor/dwh_tools.php в блоке «Информация о сессиях пользователя» Необходима регулярная актуализация запускаемых процессов (возможно уже что-то не должно запускаться, тем самым освободив ресурсы сервера) Далее будут рассмотрены подробно методы и способы оптимизации запросов. Как узнать, что делает запрос и получить список плохих запросов Для того чтобы узнать что делает запрос нужно зайти на страницу http://wh.rs.ru/monitor/dwh_tools.php Блок «Информация о сессиях пользователя» покажет следующую информацию по сессиям пользователя:
В блоке «Информация о пользователе» можно посмотреть информация о тяжелых операциях пользователя за 2 дня. План выполнения запроса Настройка любого запроса начинается с просмотра плана. План выполнения можно посмотреть до запуска в любом клиенте (PL/SQL Developer (клавиша F5), SQL Navigator, Oracle SQL Developer …). Реальный план выполнения можно посмотреть, кликнув на значок в блоке «Информация о сессиях пользователя». Планом запроса можно управлять различными способами, в том числе с использованием хинтов (подсказок оптимизатору): Select /*+ hint*/ ... Update /*+ hint*/ ... Insert /*+ hint*/ ... Подсказки Оптимизатору (hints) Для управления оптимизатором используются специализированные подсказки (hint), которые записываются в SQL-выражениях. Подсказки влияют на выбор сервером конкретного способа/метода обращения к данным (см. таблицу 1). Представленный ниже пример содержит выражение SELECT, включающее подсказку оптимизатору для использования индекса. Для задания в подсказке конкретного индекса из нескольких имеющихся следует использовать имя таблицы и имя нужного индекса.
Подсказка является частью комментария, следующего сразу же после начала оператора SQL (ключевых слов INSERT, UPDATE, SELECT). В примере подсказка начинается с символов “/*”, за которыми следуют символы “+”, пробел, затем сама подсказка и в скобках краткое название таблицы, ‘,’ и название индекса , скобка и заканчивается символами “*/”. Основные подсказки:
Эффективный SQL запрос Для изменения и фиксации плана выполнения запроса с помощью подсказок необходимо выполнить следующие операции: Если нужно, следует переписать запрос, выделив некоторые блоки запроса, при помощи конструкции WITH (при необходимости c подсказкой MATERIALIZE). Переписывать нужно: когда не удается достичь необходимого плана выполнения запроса и нужно раздробить запрос на блоки для того чтобы слишком громоздкий запрос приобрел читабельный вид, тем самым увеличив простоту сопровождения и восприятия запроса. Пример: Следующий запрос
можно переписать так:
Проанализировать, нужно ли для подзапросов в разделе FROM закрепить их план подсказкой NO_MERGE. Если не удается зафиксировать нужный план запроса, в который входят подзапросы в разделе FROM, то можно заставить Oracle строить план выполнения для подзапроса и встраивать его в план всего запроса при помощи подсказки NO_MERGE. Пример:
Зафиксировать порядок обхода таблиц с помощью подсказки ORDERED. При выполнении такого запроса таблицы будут соединены в том порядке, в котором они указаны в разделе FROM. Первой должна быть указана таблица, в которой при первой фильтрации отсекается наибольшее кол-во записей. Далее по мере возможности соединения таблиц и наибольшей фильтрацией строк при соединении. Соединяйте таблицы в правильном порядке. Порядок соединения таблиц в запросах с соединениями нескольких таблиц имеет критическое значение. Если таблицы соединяются в правильном порядке, то общее число обрабатываемых строк будет меньше. Зафиксировать методы доступа с помощью подсказок FULL, INDEX и т.д Нужно придерживаться следующего правила – если число извлекаемых данных в общем случае составляет 5-10% записей таблицы, к которым обращается запрос, то целесообразно использовать индекс. Но есть исключения, например, при извлечении больше 100000 записей из большой (более 100 млн. записей) таблицы эффективней будет полное сканирование (full scan). При необходимости доступа к значительной части строк какой-либо таблицы полное сканирование (full scan) является более эффективным, чем использование индексов. Дело в том, что для сканирования индекса и извлечения строки требуются, по крайней мере, две операции чтения для каждой строки (одна — для чтения индекса, другая для чтения данных из таблицы); а при полном сканировании таблицы для извлечения строки требуется только одна операция чтения. Для небольших таблиц полное сканирование практически всегда оказывается эффективнее использования индекса. Зафиксировать методы соединения таблиц с помощью подсказок USE_NL, USE_HASH, USE_MERGE (см. основные подсказки) USE_HASH (хэш-соединение) – при данном соединении создается хэш-таблица для значений столбца, по которому производится объединение. Данный метод подходит для соединения больших объемов и когда используется полный просмотр таблицы, т.е. таблицы читаются целиком. Этот метод соединения самый популярный в Хранилищах данных, так как аналитика всегда проводится на больших объемах информации. Пример:
USE_NL (вложенные циклы) – соединение способом вложенных циклов использует в цикле строки ведущей таблицы для поиска подходящих по условию соединения строк другой таблицы: после первой – вторую, третью и т.д. Ведущей таблицей должна быть та, у которой меньшее после применения фильтров остается наименьшее количество записей. Для ведомой таблицы, при использовании этого метода соединения, чтение должно происходить по индексу. Данный метод необходимо использовать, когда из ведомой большой таблицы необходимо получить маленькую выборку информации по индексу. Пример:
USE_MERGE (сортировка слиянием) – производится сортировка строк таблиц по столбцу, по которому выполнятся соединение и затем производится их слияние. Этот способ характеризуется большими затратами ресурсов на сортировку и должен использоваться аккуратно. В пользу его выбора может повлиять необходимость получения отсортированных результатов (наличие в запросе конструкции ORDER BY) или наличие подходящих индексов. Для работы, в 99% случаев, достаточно первых двух методов. Дополнительно тонко настроить запрос. Максимально использовать доступные логические фильтры, в том числе фильтры по диапазонам, Пример:
При необходимости указать временной период, значения необходимо приводить к формату даты функцией to_date(), DATE. Нельзя использовать функцию trunc() на поле таблицы в разделе where!!! Вместо trunc(), используйте >=, <= Пример:
Запрос с trunc() можно переписать так:
Особенно внимательно следует отнестись к использованию операторов DISTINCT, ORDER BY и UNION, поскольку при выполнении этих операций происходит создание временных таблиц с дополнительными накладными расходами на выполняемую сортировку. При необходимости использования оператора DISTINCT желательно сохранять результаты его выполнения для последующего использования. Вместо оператора UNION рекомендуется применять оператор UNION ALL (если это допускается логикой запроса), при использовании которого не выполняется исключение дубликатов и, соответственно, сортировка. Вместо операции DISTINCT можно использовать GROUP BY Пример:
Оператор MINUS может выполняться гораздо быстрее, чем запросы с WHERE NOT IN (SELECT) или WHERE NOT EXISTS. Пример:
Оба запроса фактически возвращают один результат (если результирующий набор не содержит дубликатов). С помощью просмотра статистических сведений о выполнении запросов можно обнаружить, что общее количество логических операций чтения для первого варианта запроса гораздо больше, чем для второго. Использование оператора MINUS может оказаться очень эффективным. Избегайте условий неравенства «<>» или «!=». В таких случаях лучше менять неравенства на (NOT) IN или (NOT) EXIST, со списком значений или подзапросом. Однако условия с хотя бы одной границей диапазона, такие как BETWEEN, >, >=, <,=<, работают. Поэтому пользуйтесь их комбинацией вместо неравенства. Старайтесь минимизировать число просмотров таблиц. Обычно уменьшение числа просмотра таблиц в SQL-запросах приводит к повышению эффективности. Запросы с меньшим числом просмотров таблиц - более быстрые запросы. Часто используемые запросы за длительный период времени Иногда возникает ситуация, когда необходимо получать с довольно высокой периодичностью данные за длительный период времени. Например, нужно получать данные по БВК за весь период времени нарастающим итогом. Неправильная реализация – запускать запрос, получающий данные за весь период непосредственно перед датой предоставления отчёта. Более правильным и рациональным будет следующий подход: значительная часть исторических данных не меняется. Например, если мы получаем данные в феврале 2011 года, то можно смело считать что до 01.01.2010 данные неизменны. Соответственно, правильно будет создать таблицу-агрегат, содержащий необходимые данные за период времени до 01.01.2010. рассчитывать недостающие новые данные (инкремент) только за небольшой период времени, в нашем примере – это с 01.01.2010 по настоящее время. в целях снижения нагрузки на базу, расчёт пункта 2 лучше всего производить не во время рабочего дня, когда работает много пользователей, а создать задание (Job) на расчёт в ночное время, когда база наименее загружена. За помощью в создании job-а вы всегда можете обратиться в УАС ДР. Секционированные таблицы В таблицах ХД содержится огромное количество данных. Чем больше размер таблицы, тем больше времени потребуется для некоторых операций по выборке строк таблицы. Для повышения скорости доступа к данным в больших таблицах в Oracle существует специальная опция – секционирование. Секционирование – это физическое разбиение одной большой таблицы на множество более мелких партиций (секций) по заданному ключу секционирования (колонка таблицы). В нашем Хранилище наиболее часто в качестве ключа секционирования используется дата, период месяц. Пример, таблица mart.agr_dogovors секционирована начиная с 2007 года по полю datenter помесячно: 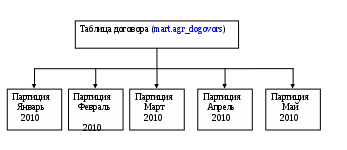 Для того, чтобы получить выигрыш в скорости выполнения запроса и воспользоваться партициями достаточно указать в условии запроса ключ секционирования (колонка, по которой табличка разбита): Пример:
В результате выполнения данного запроса будет прочитано 3 партиции (январь, ферваль, март) вместо полного сканирования таблицы, в случае отсутствия партицирования. _____________________________________________________________________________ !!! Очень важно !!! Обязательно всегда указывать дату в формате to_date() Использование функций на поле секционирования не даёт использовать чтение по партициям и таблица будет читаться целиком. Пример грубой ошибки:
В данном случае партиции использоваться не будут!!! _____________________________________________________________________________ Таблица может быть секционирована не только по одному полю – составное секционирование. Запросы позволяющие выяснить, по каким полям секционирована таблица: запрос показывает по какому основному полю секционирована таблица
запрос показывает по какому дополнительному полю секционирована таблица
Основные секционированные таблицы из схем ORAWH, DWH, TMS, MART:
Агрегаты Желательно использовать агрегаты. В данных таблицах в удобном для исследования виде собраны данные по договорам, счетам, проводкам: mart.agr_dogovors mart.operation_text_accounts mart.bookentry_text_accounts mart.stg_mpcs_slips_fact mart.dq_vitr mart.agr_cards orawh.wh_accbalance_mv orawh.rm_accbalance Что делать не нужно! Запрос НЕ должен содержать соединения (join) двух одинаковых больших таблиц.
Крайне не рекомендуется использовать полное соединение (full join). Если в плане выполнения запроса вы видите Merge Join Cartesian, то ни в коем случае его не запускайте(!!!) Посмотрите, все ли таблицы связаны, и связаны правильно. Если не удается исправить план, обратитесь в УАС ДР за помощью в оптимизации запроса. В запросе в разделе WHERE при указании соединения таблиц ни в коем случае(!) не использовать соединения вида:
В данном случае гораздо лучше будет разбивать запрос на части. Соединение данного вида хорошо работает только на маленьких таблицах! Использование индексов При необходимости использования индекса, нельзя использовать любые функции на индексированной колонке в разделе WHERE, они исключают использование индекса. Индекс на колонке не будет использоваться, если выполняется проверка значения колонки на NULL. То есть при использовании IS NULL или IS NOT NULL индекс не используется потому, что IS NULL не указывает допустимый диапазон. Пример
В этих случаях индекс использоваться не будет! Использование собственных таблиц В случае использования таблиц в своей схеме обязательно и регулярно(!) необходимо собирать статистику функциями:
Использование сложных запросов Рекомендуется разбивать любой сложный запрос на несколько простых подзапросов. Можно использовать конструкцию WITH. Старайтесь писать как можно более простые запросы. Оптимизатор может не справиться со слишком сложными запросами; иногда написание нескольких более простых запросов позволяет добиться лучшей эффективности. Часто более эффективным подходом является использование временных таблиц и разбиение сложного запроса с соединением нескольких таблиц в последовательность простых запросов. Например, если соединяются восемь крупных таблиц, лучше раздробить запрос на два или три, в каждом из которых соединяется не более четырех таблиц, и хранить промежуточные результаты в заранее созданных временных таблицах. Использование аналитических функций Пример Следующий скрипт найдет последний договор для выбранного клиента:
Ниже приводится перечень основных аналитических функций
Про аналитические функции можно прочитать по ссылкам ниже.Полезные ссылки Общий справочник по Oracle http://docs.oracle.com/cd/E11882_01/index.htm Справочник по SQL http://docs.oracle.com/cd/E11882_01/server.112/e41084/toc.htm Справочник по оптимизации http://docs.oracle.com/cd/E11882_01/server.112/e41573/toc.htm Ошибки http://docs.oracle.com/cd/E11882_01/server.112/e17766/toc.htm Информация по хинтам https://iusoltsev.wordpress.com/profile/individual-sql-and-cbo/cbo-hints/ Форум по Oracle http://www.sql.ru/forum/oracle Аналитические функции в Oracle http://www.interface.ru/home.asp?artId=1774 http://www.oracloid.ru/index.php?t=206&st=0Расшифровка операторов в плане запроса http://juliandyke.com/Optimisation/Operations/Operations.htmlПостановка в очередь (Enqueues) http://docwiki.embarcadero.com/DBOptimizer/en/Oracle:Enqueues SQL*Loader FAQ http://www.orafaq.com/wiki/SQL*Loader_FAQ Мониторинг блокировок http://my-oracle.it-blogs.com.ua/post-38.aspx Понимание событий Oracle (Дэн Хотка) http://baks.gaz.ru/oradoc/ora/ora016.htm |