Девятко И. Ф. Методы социологического исследования. Екатеринбург, Изд-во Урал, ун-та, 1998. 208 с. Девятко И. Ф. Методы социологического исследования. Екатеринбург. Социологического исследования екатеринбург Издательство Уральского университета
 Скачать 1.7 Mb. Скачать 1.7 Mb.
|

Конструирование индексов и шкалИспользование нескольких индикаторов, как было показано выше, увеличивает валидность и надежность измерения переменных. Здесь, однако, возникает новая проблема: как использовать полученные значения индикаторов для того, чтобы охарактеризовать каждый «случай» (каждого респондента, группу, страну и т. п.) одним числовым значением, однозначно определяющим его положение на одномерном континууме переменной-признака, для измерения которой мы использовали данный набор индикаторов. Иными словами, нужно осуществить обратный переход от набора значений эмпирических индикаторов, описывающих каждую конкретную единицу анализа, к упорядочению всех единиц анализа по оси интересующей нас переменной. Такое упорядочение и называется собственно шкалой, мерой выраженности переменной-признака, а логика перехода от набора наблюдаемых значений к шкальным значениям называется моделью шкалирования. Заметим сразу, что некий набор индикаторов — например, набор оценочных шкал (см. гл. 5) — может использоваться для измерения более чем одной переменной, и, следовательно, данные о наблюдаемых значениях этих индикаторов в принципе позволяют упорядочить «случай» по нескольким переменным, т.е. по нескольким шкалам. Однако это уже задача многомерного шкалирования, мы же пока ограничимся обсуждением одномерных шкал и индексов. Если вернуться к структурированной матрице данных «переменная х случай», то можно увидеть, что процедура конструирования шкалы может быть описана и как процедура «сжатия» матрицы данных, уменьшения ее размерности. Предположим, три строки нашей матрицы соответствуют переменным-индикаторам «доход», «род занятий» и «образование». Мы включили эти индикаторы в наше исследование ради того, чтобы охарактеризовать социально-экономический статус каждого респондента, т.е. расположить их от низкого статуса к высокому. Если мы вместо трех строк, соответствующих доходу, образованию и профессии, введем в нашу матрицу данных одну строку, отражающую положение каждого респондента на сконструированной нами шкале СЭС, размерность матрицы уменьшится. Однако сначала нам нужно решить, как объединить три значения — три строки матрицы — в одно, т. е. нам нужно избрать модель шкалирования. Пусть, скажем, три строки нашей матрицы данных — это полученные каким-то образом (тестирование, опрос экспертов и т. п.) оценки «жизнерадостности», «энергичности» и «независимости». Исследователь предполагает, что эти три индикатора могут быть использованы для измерения важной для его теории переменной «сила Я». Все, что ему нужно сделать — это решить, как перевести оценки в строках 1—3 в оценки «силы Я» (см. рис. 12).
 «Сила Я»? Рис. 12. Фрагмент матрицы данных «переменные х субъекты» Самый простой и очевидный способ — это суммировать для каждого индивида оценки по каждому индикатору. Получившийся суммарный балл будет отражать индивидуальные различия в «силе Я», так как позволит упорядочить всех респондентов от минимального к максимальному значению этой переменной (в нашем примере — от 0 до 6 баллов). Еще одно преимущество суммирования — увеличение разброса индивидуальных значений. Действительно, максимально возможное различие по первичным индикаторам составляло 2 балла (от 0 до 2). В суммарном показателе разница между индивидуальными значениями может составить 6 баллов. Следовательно, суммарный балл — это более «чуткий» и надежный инструмент для упорядочения и может быть назван шкалой в смысле определения, данного нами выше. Однако в социологии суммарные показатели чаще называют индексами, чтобы подчеркнуть их единственное важное отличие от «больших» шкал. Индекс позволяет эффективно «свернуть» информацию, содержавшуюся в исходных индикаторах (вопросах, пунктах, тестах), однако от суммарного балла нельзя вернуться к исходной матрице, точнее, к тому паттерну ответов, который стоит за данным значением индекса. Если сформулировать это корректнее, индекс не позволяет учитывать различия в структуре ответов респондентов. Если снова обратиться к рисунку 12, то можно заметить, что субъекты Л. М. и Ф.Ж. имеют одинаковый суммарный балл, равный 4 (достаточно высокое значение!). Но можно ли считать несущественным то обстоятельство, что у Л. М. нулевой уровень независимости, а Ф. Ж. получил тот же суммарный балл из-за недостатка оптимизма? Предположим, даже довольно мрачный человек может обладать значительной «силой Я», но следует ли считать столь же «сильным» того, кто легко поддается давлению окружения? В принципе индексы безусловно применимы в тех случаях, когда модель измерения (см. выше) предполагает, что некая латентная, т. е. не измеряемая непосредственно переменная, может быть измерена с помощью совокупности качественно однородных показателей. Во многих случаях различия в значимости, важности отдельных индикаторов можно учесть с помощью «взвешивания», пересчета значений с учетом «веса» каждого индикатора в латентной переменной. Так в примере с «силой Я» можно домножить все индивидуальные значения в строке «независимость» на 2, если принять предположение о том, что независимость влияет на латентную переменную с двукратным эффектом. Экономисты часто используют индексы розничных цен, отражающие динамику стоимости жизни. При этом разные товарные группы, например, имеющие неодинаковое значение в потребительском бюджете, — как, скажем, хлеб и деликатесы — учитываются с разными весовыми коэффициентами. Но и в этом случае индекс остается несовершенным типом шкалы: эмпирическая информация здесь используется лишь для шкалирования различий между субъектами (или другими единицами анализа), но не для шкалирования различий между пунктами-ответами {эмпирическими индикаторами). Используя «взвешивание», мы вводим априорные ограничения на упорядочение входящих в индекс индикаторов, не зависящие от данных наблюдения. Своеобразным переходом между моделью суммарного балла (индекса) и основными моделями шкалирования является шкала Р. Ликерта (Лайкерта). Исходным материалом для ее построения служат оценочные шкалы согласия-несогласия с суждениями, которые выражают более или менее «благожелательную» установку (см. раздел «Выбор формата для ответов» в гл. 5). Количество категорий ответа — «согласен», «совершенно согласен» и т. п. — обычно варьирует от двух до семи. Респондент получает балл по каждому суждению в зависимости от избранного им ответа. Присуждаемый данному ответу балл в свою очередь определяется «благожелательностью» ответа по отношению к измеряемой установке (интенсивностью согласия с суждением), т. е. ответы также упорядочены на одномерном континууме (от крайне негативной установки к крайне позитивной). Баллы, полученные за каждый ответ, суммируются. Суммарный балл, полученный индивидуумом, характеризует уже его собственное положение на установочном континууме (например, «консерватор», «умеренный консерватор», «умеренный либерал», «либерал»). Отметим сразу, что эта же модель шкалирования может использоваться и для измерения мотивации или осведомленности (соответственно респондента просят оценить степень важности какого-то объекта или сказать, верно или неверно определенное утверждение). Для отбора списка суждений, составляющих шкалу Ликерта, исходный список высказываний предъявляют репрезентативной выборке респондентов (так называемой выборке стандартизации). В окончательный список попадают те высказывания, для которых были получены высокие оценки надежности — согласованности и валидности. Обычно используют описанные нами ранее методы оценки надежности и валидности (коррелирование с суммарным баллом, сравнение «крайних групп» и т. п.). Приведем в качестве примера некоторые высказывания «Теста для измерения художественно-эстетической потребности молодежи»1 (в скобках дан ключ к каждому высказыванию, показывающий, за какой ответ присуждается балл): 1. Думаю, что вполне можно обойтись без общения с произведениями искусства (неверно). 2. Я не люблю стихов (неверно). 3. Я коллекционирую записи классической музыки (верно). 4. ................................................................................................ Шкалирование по описанной модели дает ординальный уровень измерения. Шкалы социальной дистанции Э. Богардуса — старейшая модель социологического шкалирования, не утратившая, однако, своей популярности. Исследователь разрабатывает совокупность вопросов, отражающих различную степень близости отношений с определенной социальной или этнической группой, например: 1. Согласны ли Вы, чтобы хорваты жили с Вами в одном городе? 2. Согласны ли Вы жить по соседству с хорватами? 3. Согласны ли Вы работать в одном отделе (учреждении) с хорватом? 4. Позволите ли Вы своей дочери выйти замуж за хорвата? Предполагается, что согласие с каждым последующим утверждением отражает переход к очередной градации ординальной шкалы установок — от меньшей близости к большей. Существенным требованием к избранной совокупности вопросов является их содержательная валидность, иными словами, здесь необходимы экспертные процедуры, описанные выше. Важно также убедиться в обоснованности предположения об одномерности шкалируемой переменной. Если в данных, полученных при использовании шкал социальной дистанции, встречаются «нелогичные» (так называемые нешкалируемые) индивидуальные паттерны ответов, причиной чаще всего бывает влияние другой переменной. Примером нешкалируемого паттерна ответов может служить ситуация, когда респондент, отрицательно ответивший на «слабые» вопросы, неожиданно соглашается с более «сильными», предполагающими высокую степень близости (среди специалистов по социологическим методам имеет хождение соответствующая шутка: если человек, не желающий жить в одном городе с черными, согласен выдать свою дочь замуж за черного, это не ошибка измерения: просто он одинаково ненавидит негров и собственную дочь). Шкала равнокажущихся интервалов Л. Терстоуна позволяет достичь более высокого уровня измерения установок, чем ординальный. Она представляет собой целый класс методов интервального шкалирования и будет рассмотрена здесь в качестве наиболее простого примера1. Первая шкала равнокажущихся интервалов была описана в работе 1929 года и предназначалась для измерения остановок по отношению к церкви как социальному институту2. Этой работой мы воспользуемся для того, чтобы проиллюстрировать основные этапы предложенной Терстоуном процедуры. Шкала Терстоуна позволяет расположить и суждения, и индивидов вдоль одномерного континуума установки, полюсам которого соответствует крайне благожелательное и крайне негативное отношение к объекту установки (церкви, партии, прогрессивному налогообложению или чему-либо еще). Шкальный балл суждения или индивида отражает степень этой благожелательности или неблагожелательности. На первом этапе исследователь составляет максимально широкий список суждений (высказываний), выражающих интересующую его установку. Так, Терстоун собирал мнения коллег, студентов, высказывания из публикаций, касающихся церкви. Здесь уместны также интервьюирование, использование открытых вопросов («Что Вы думаете о...?»), групповая дискуссия и т. п. Собранные суждения были подвергнуты первичному отбору. Исследователи отсеяли те высказывания, которые не удовлетворяли обычным требованиям к конструированию вопросов — двусмысленные, слишком длинные, содержащие специальные термины и т.п. (см. гл. 5 ). При первичном отборе суждений для шкалы Терстоуна используют и некоторые специальные критерии: 1. Исключаются суждения, относящиеся скорее к прошлому, чем к настоящему (например, «В средневековье церковь играла важную роль в общественной жизни»). 2. Исключаются суждения, описывающие факты, а не мнения и отношения. Конечно, далеко не всегда можно отделить высказывания, описывающие фактическое положение дел, от прочих. Скажем, слова «Бог любит нас всех» — факт для верующего, хотя другие люди могут усмотреть в них определенное отношение к религии. В практических целях вполне достаточно руководствоваться следующим критерием для выявления фактических суждений, подлежащих устранению из шкалы Терстоуна: фактом является любое высказывание, для установления истинности которого могут быть использованы какие-то «посюсторонние» процедуры верификации. 3. Исключаются также суждения, содержащие слова «все», «всегда», «никто», «никогда», так как этим словам люди обычно придают различный смысл, что затрудняет интерпретацию. В результате исходный список из 350—400 суждений сокращается до 100—120. Следующим этапом является «судейская» процедура, позволяющая определить шкальное значение для каждого суждения и провести среди них окончательный отбор. Терстоун предложил разделить гипотетический континуум благожелательного-неблагожелательного отношения к церкви на 11 категорий (от «А» до «К»), разделенных субъективно равными интервалами. Требование субъективного равенства интервалов между градациями весьма существенно для построения шкалы Терстоуна и обычно его специально подчеркивают в инструкции для «судей» (например, «Представьте, что карточки с буквами от „А" до “К" представляют расположенные на равном расстоянии градации шкалы, так что градации „А" соответствует максимально благожелательное отношение к Х (объекту установки), а „К" — максимально неблагожелательное, негативное отношение»). Каждое из утверждений списка печатается на отдельной карточке, которые и раздаются «судьям» (в конструировании шкалы установок по отношению к церкви участвовало 300 таких экспертов). Задача «судей» заключается в том, чтобы разложить все 100—120 суждений по 11 рубрикам соответственно степени выраженного в них благожелательного или неблагожелательного отношения к объекту остановки. Подчеркнем, что «судей» не просят высказать их собственное мнение, они должны лишь рассортировать высказывания. Шкальное значение (балл) каждого из высказываний определяется распределением оценок «судей», поэтому началом следующего этапа (собственно построения шкалы) является подсчет процента экспертов, положивших высказывание в определенную стопку. Далее подсчитывается суммарный (кумулятивный) процент «судей», отнесших суждение к данной градации и предшествующим градациям. Терстоун присваивал использовавшимся градациям числовые значения от 1 (градация «А», максимально благожелательное отношение к церкви) до 11 (градация «К»). Проиллюстрируем дальнейшее на примере гипотетического суждения N, данные для которого представлены в таблице 6.1. Таблица 6.1 Распределение «судейских» оценок для суждения N
Распределение кумулятивных (накопленных) процентов позволяет вычислить значения медианы и междуквартильного размаха. Медиана, или процентиль 50 в распределении накопленных частот, — это такое значение на шкале «А» — «К», относительно которого половина судей дала большие, а другая половина — меньшие оценки данного утверждения1. Медиана, таким образом, делит пополам упорядоченное множество значений признака. Вычислить медиану мы можем по следующей формуле: 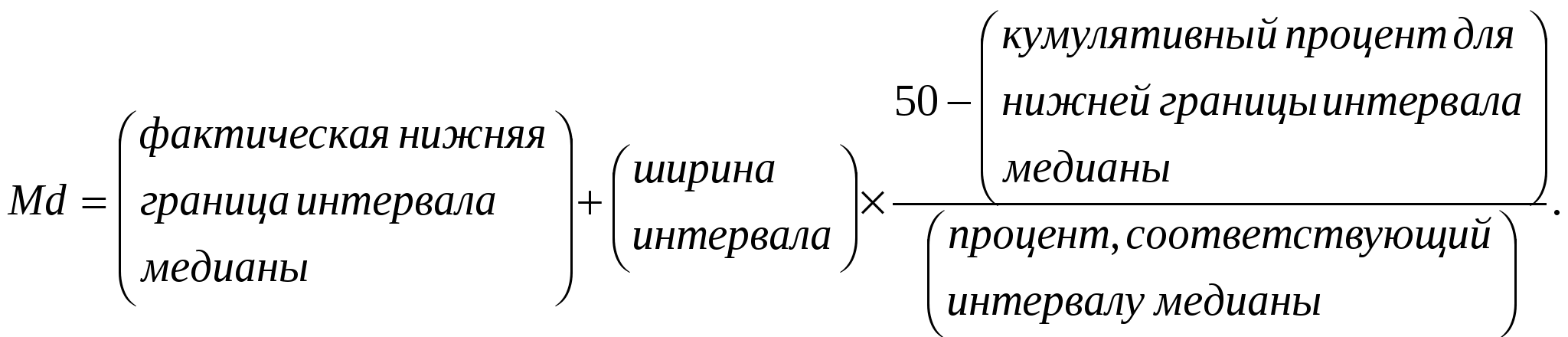 В методе Терстоуна ширина интервала между соседними численными градациями по определению равна 1 (равнокажущиеся интервалы). В используемом нами примере границами интервала, где расположена медиана (процентиль 50), являются градации «F» и «G» (см. табл. 6.1). Фактической нижней границей интервала медианы будет значение 6,51, отсюда: Значение медианы и принимается за шкальный балл («цену») суждения. Для гипотетического суждения N в нашем примере он оказался равен 6,7. (В принципе более простым является графический метод нахождения медианы. Для этого на миллиметровой бумаге строится кривая накопленных процентов — огива, позволяющая легко найти числовое значение, соответствующее процентилю 50.) Ясно, однако, что не все суждения, получившие оценку «судей», в равной мере пригодны для шкалы: некоторые из суждений получат весьма согласованные и единодушные оценки экспертов, тогда как другие вызовут разнобой во мнениях. Для оценки внутренней согласованности отдельных высказываний шкалы Терстоун применил меру разброса судейских оценок — междуквартильный размах. (Здесь снова вместо распределения абсолютных частот экспертных оценок используется распределение процентилей, т. е. накопленные частоты выражают в кумулятивных процентах, что позволяет сравнивать выборки разного объема.) Междуквартильный размах — это расстояние между первым и третьим квартилем распределения. Первый квартиль (Q1) задается точкой на оси, до которой лежит 25% полученных оценок суждения, а третий ((Q3) — точкой, выше которой лежит 25% оценок. (Легко видеть, что второму квартилю соответствует медиана.) Для вычисления междуквартильного размаха (Q3 Q1)сначала устанавливаются значения, соответствующие первому и третьему квартилям распределения. Для этого используются формулы, аналогичные формуле для медианы, с соответствующими поправками: берется фактическая нижняя граница интервала соответствующего квартиля, кумулятивный процент для нижней границы интервала данного квартиля и т. д. Так, для первого квартиля формула подсчета такова:  Для нашего примера с суждением N: Читатель может самостоятельно выписать аналогичную формулу для третьего квартиля (75 процентиль), произвести необходимые подсчеты и убедиться, что для вымышленного суждения Nмеждуквартильный размах (Q3 Q1) составит 1,7. Те суждения, для которых разброс оценок, измеренный через междуквартильный размах, оказывается слишком велик, исключаются из шкалы Терстоуна. Предполагается, что высказывание, получившее столь разные оценки, воспринимается слишком неоднозначно. Так, Терстоун исключил из первоначально предъявленного «судьям» списка 90 высказываний из 130. В результирующей шкале оставляют одно-два высказывания для каждого деления шкалы, чтобы все градации предполагаемого установочного континуума оказались в равной мере представлены. Если получившуюся шкалу предъявить теперь группе респондентов, то индивидуальным баллом каждого субъекта, выражающим меру «благожелательность» его установки, можно считать медиану (или средний балл) всех суждений, с которыми он согласился. Многие критики шкалы Терстоуна указывали на возможность влияния на получаемые результаты характеристик «судейской» группы и широты диапазона предлагаемых суждений1. Все же существуют веские основания считать, что такая шкала обладает вполне удовлетворительной воспроизводимостью и в среднем диапазоне дает уровень измерения, превосходящий ординальный (является так называемой шкалой разностей). Удаление или прибавление пункта шкалы не меняет шкальных значений других пунктов-высказываний. Приведем некоторые примеры высказываний, включенных Терстоуном в окончательный вариант шкалы установок по отношению к церкви (в скобках указан шкальный балл суждения): «Я думаю, что церковь – это наиважнейший социальный институт в современной Америке» (0,2); «Когда я нахожусь в храме, мне доставляет удовольствие наблюдать за службой, особенно если при этом звучит хорошая музыка» (4,0); «Я ощущаю потребность в какой-то религии, но не нахожу того, что мне нужно, ни в одной из существующих церквей» (6,1); «С моей точки зрения, церковь безнадежно устарела» (9,1). В основе шкалы Гутмана также лежит идея кумулятивности: одни высказвания-пункты имеют большую «нагрузку» на одномерном континууме шкалируемой переменно-признака, другие – меньшую. Модель шкалирования, предложенная Гутманом, подразумевает, что в идеальном случае респондент, согласившийся с более «нагруженным» пунктом, согласится и со всеми менее «нагруженными». Таким образом, знание максимального шкального балла респондента позволяет полностью воссоздать паттерн его ответов. Шкалируемая переменная-признак не обязательно является установкой, она может характеризовать поведение: одна из первых гутмановских шкал, например, содержала пункты, описывающиен симптомы реактивного невроза, расстройства сна, тошнота, страх и т.п.1 В предложенной Гутманом процедуре обычно используется совокупность дихотомических вопросов, т.е. вопросов, на которые могут быть даны лишь два ответа: “да” или “нет”, “согласен” или “не согласен”. Совокупность вопросов или утверждений, составляющих гутмановскую шкалу, должна обладать одним существенным свойством: вероятность положительного ответа монотонно возрастает с ростом значения шкалируемой (латентной) переменной. Отсюда следует, что субъекты, имеющие больший шкальный балл, т.е. большее значение латентной переменной, с большей вероятностью дают положительный ответ на каждый отдельный вопрос2. Это условие легко проиллюстрировать на примере следующих вопросов о росте (для простоты изложения предположим, что ошибка измерения отсутствует, т.е. все респонденты знают и точно сообщают свой истинный рост):
Эти вопросы образуют идеальную гутмановскую шкалу: если ошибка измерения отсутствует, любой респондент, ответивший положительно на вопрос 3, дает положительный ответ и на вопросы 2 и 1. Вообще, зная максимальный балл респондента, мы можем полностью воссоздать его паттерн ответов. Для вопросов о росте все возможные паттерны ответов (шкальные типы) приведены в табл. 6.2. Таблица 6.2 Ответы на вопросы о росте для четырех гипотетических респондентов
Если респондентов и вопросы расположить на одной шкале латентной переменной (в данном случае, «роста»), то станет очевидным, что респонденты реагируют на вопросы в зависимости от своего ранга (положения) на этой же шкале: респондент данного роста, позитивно прореагировавший на некий вопрос-пункт, будет также позитивно реагировать на все пункты, имеющие более низкий ранг (в нашем примере, на все более «низкорослые» вопросы-пункты). Скажем, для примера с ростом совместное упорядочение вопросов и респондентов на гутмановской шкале могло бы выглядеть, как на рисунке 13. Вопрос 1 Вопрос 2 Вопрос 3  Низкий рост Высокий рост    Респондент Г Респондент В Респондент Б Респондент А Рис. 13. Шкала Гутмана для трех вопросов о росте и четырех респондентов Легко видеть, что в нашем примере самыми «популярными» (имеющими наибольшую частоту положительных ответов) будут менее «нагруженные» по шкалируемой переменной вопросы. С другой стороны, большее число положительных ответов будет у тех респондентов, для которых значение шкалируемой переменной выше. Для того чтобы определить, является ли данная совокупность вопросов шкалируемой, т.е. дает ли она хорошее приближение к идеальной модели шкалирования по Гутману, нужно, во-первых, убедиться, что вопросы по своему смыслу могут соответствовать вышеописанному условию монотонного возрастания вероятности положительного ответа. Так, например, рассмотренные выше вопросы шкалы социальной дистанции Богардуса теоретически могут составить гутмановскую шкалу. Однако так называемые точечные вопросы например: «Верно ли, что Ваш рост равен 1,65 м?» наверняка не могут быть использованы в рамках рассматриваемой шкальной модели. Дальнейшая процедура построения гутмановской шкалы заключается в проверке соответствия реальных данных модели совершенной шкалы Гутмана и ее лучше рассмотреть на конкретном примере. Допустим, некий социолог пытается измерить переменную «благопристойность», которую он почему-то связывает со стремлением следовать нормативным предписаниям, регулирующим публичное (т. е. безличное) социальное общение. Среди использованных им вопросов есть три следующих: 1. Вы обычно стучите в дверь кабинета или комнаты, прежде чем войти (верно, неверно). 2. В публичных обсуждениях или дискуссиях Вы высказываете свое мнение лишь тогда, когда Вас прямо об этом попросят (верно, неверно). 3. Вы предпочтете промолчать, если Вам покажется, что Ваше справедливое и существенное замечание может вызвать раздражение у окружающих (верно, неверно). Конечно, можно предположить, что некоторые из изобретенных исследователем вопросов отражают скорее «социальную тревожность» или «конформизм», но в данном случае мы будем руководствоваться тем, что идеальных индикаторов не бывает: бывают индикаторы, дающие лучшее или худшее приближение к идеальной шкале для реальных данных. Итак, социологу предстоит проверить, насколько полученное им эмпирическое распределение ответов соответствует тем теоретически возможным паттернам ответов на три вопроса, которые в таблице 6.2 образуют безупречный «параллелограмм», характерный для идеальной гутмановской шкалы. Для случая трех вопросов возможны четыре «правильных» паттерна ответов, обозначаемых обычно как школьные типы ответов: 1. + + + 2. + + 3. + 4. — — Предположим, что наш социолог получил следующую картину распределения шкальных типов (см. табл. 6.3). Таблица 6.3 Распределение ответов для шкальных типов
Судя по таблице 6.3, априорное упорядочение вопросов совпало с реальным: самый «легкий» первый вопрос оказался и самым популярным (см. выше), тогда как на самый «тяжелый» вопрос шкалы положительно ответили лишь 30 опрошенных: нежелание высказывать свою точку зрения требует значительно большего количества «благопристойности», чем привычка стучать в дверь. Если бы использованный нами исходный порядок вопросов не совпал бы с их реальным ранжированием по числу позитивных ответов, то это само по себе не доказывало бы «нешкалируемости» данной совокупности пунктов: для того, чтобы получить столь же красивую «гутмановскую» картину распределения ответов, как в предыдущей таблице 6.2, было бы достаточно просто переставить столбцы таблицы так, чтобы первым оказался самый популярный вопрос с наибольшим числом положительных ответов и т. д. (Упорядоченную таким образом таблицу обычно называют шкалограммной матрицей, или шкалограммой.) Реальной проблемой в нашем примере, как и в большинстве случаев построения гутмановской шкалы, стало наличие так называемых нешкальных типов, т. е. таких паттернов ответа, которые попросту не укладываются в логику одномерной модели с монотонно возрастающей вероятностью ответа. Примером «нешкального» паттерна мог бы быть положительный ответ на третий вопрос при отрицательных ответах на первые два вопроса (— — +). То обстоятельство, что некий респондент, бесцеремонно входящий в чужую дверь без стука, боится открыто выразить свое мнение, может быть и случайной ошибкой, и результатом влияния какой-то посторонней переменной: возможно, отвечая на третий вопрос, этот человек думал не о хороших манерах, а о том, что высказывать свое мнение открыто в его привычной среде «невыгодно», недальновидно и т. п. Для того чтобы проверить шкальную гипотезу о том, что данная совокупность вопросов дает хорошее приближение к гутмановской шкале, нам следует трактовать «нешкальные» типы ответа как ошибки и оценить, насколько велико отклонение от идеальной модели. Пусть наш исследователь получил следующее распределение «нешкальных» типов (см. табл. 6.4). Разумно предположить, что «нешкальный» тип — — + можно отнести к шкальному типу — — — с одной ошибкой. Второй «нешкальный» паттерн ответа — + + можно рассматривать как отклонение от школьного типа + + + также с одной ошибкой (если бы мы отнесли этот «нешкальный» паттерн к типу — — —, то ошибок было бы две, а не одна). Существуют разные способы оценки приемлемости наблюдаемых отклонений от совершенной шкалы, содержащей лишь шкальные паттерны ответа. Здесь мы воспользуемся самым простым и грубым, рассчитав коэффициент воспроизводимости шкалы Rep(от англ. reproducibility) по следующей формуле: В нашем примере мы, основываясь на идеальной модели шкалы, можем воспроизвести (предсказать) по три ответа для 143 респондентов. Всего мы сделаем 429 предсказаний для отдельных ответов. Из них 8 ответов окажутся ошибочными (каждая ошибка будет отличаться от ожидаемого ответа только на 1 балл). Коэффициент воспроизводимости составит, таким образом, 0,98 (или 98%). Таблица 6.4 Распределение ответов для «нешкальных» типов
На практике принято считать приемлемым любое значение коэффициента воспроизводимости, которое превышает 0,90 (90%). Очевидно, что 100%-й воспроизводимостью может обладать лишь совершенная гутмановская шкала. Если полученное значение коэффициента воспроизводимости превосходит заданный порог, данная совокупность вопросов может использоваться в качестве шкалы Гутмана. При этом вопросам присваиваются шкальные значения, отражающие их ранжирование по шкале (скажем, 1, 2 и 3), так что самый «легкий» вопрос получает самый низкий балл. Респонденты получают индивидуальный балл, соответствующий их шкальным типам (число положительных ответов либо суммарный балл). Следует помнить о том, что полученная шкала отражает наличие определенной упорядоченности в той матрице реальных данных, для которых проверялась гутмановская модель. Иными словами, вывод о том, что данная совокупность вопросов составляет шкалу Гутмана, верен для данной выборки и для данной серии наблюдений. Перенос шкалы с одной популяции на другую требует новых данных и нового обоснования. Мы рассмотрели лишь некоторые, относительно простые, методы конструирования индексов и шкал в социологии. Проанализированные нами примеры подтверждают полезность шкал для повышения качества социологического измерения (т. е. его надежности и валидности) и для экономного представления эмпирической информации, получаемой в ходе исследования. Наконец, анализ моделей измерения, лежащих в основании любой шкалы, часто помогает прояснить природу теоретических понятий и взаимосвязей между ними. Еще одним шагом к содержательным и основанным на реальных эмпирических наблюдениях выводам является анализ данных. Основам анализа данных посвящена глава 8. Дополнительная литератураАванесов В. С. Тесты в социологическом исследовании. М.: Наука, 1982. Грин Б. Ф. Измерение установки // Математические методы в современной буржуазной социологии. М.: Прогресс, 1966. Девятко И. Ф. Диагностическая процедура в социологии: очерк истории и теории. М.: Наука, 1993. Клигер С. А., Косолапов М. С., Толстова Ю. Н. Шкалирование при сборе и анализе социологической информации. М.: Наука, 1978. Осипов Г. В., Андреев Э. П. Методы измерения в социологии. М.: Наука, 1977. Толстова Ю. Н. Логика математического анализа социологических данных. М.: Наука, 1991. Ядов В. А. Социологическое исследование: методология, программа, методы. 2-е изд. М.: Наука, 1987. Гл. 3. Глава 7. Построение выборки социологического исследования | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||