отравить. Содержание Введение Искусственные нейронные сети Параллели из биологии
 Скачать 0.49 Mb. Скачать 0.49 Mb.
|

|
2.1 Алгоритм обратного распространения Самый известный вариант алгоритма обучения нейронной сети - так называемый алгоритм обратного распространения (back propagation). Существуют современные алгоритмы второго порядка, такие как метод сопряженных градиентов и метод Левенберга-Маркара, которые на многих задачах работают существенно быстрее (иногда на порядок). Алгоритм обратного распространения наиболее прост для понимания, а в некоторых случаях он имеет определенные преимущества. Сейчас мы опишем его, а более продвинутые алгоритмы рассмотрим позже. Разработаны также эвристические модификации этого алгоритма, хорошо работающие для определенных классов задач, - быстрое распространение (Fahlman, 1988) и Дельта-дельта с чертой (Jacobs, 1988). В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Этот вектор указывает направление кратчайшего спуска по поверхности из данной точки, поэтому если мы "немного" продвинемся по нему, ошибка уменьшится. Последовательность таких шагов (замедляющаяся по мере приближения к дну) в конце концов приведет к минимуму того или иного типа. Определенную трудность здесь представляет вопрос о том, какую нужно брать длину шагов. При большой длине шага сходимость будет более быстрой, но имеется опасность перепрыгнуть через решение или (если поверхность ошибок имеет особо вычурную форму) уйти в неправильном направлении. Классическим примером такого явления при обучении нейронной сети является ситуация, когда алгоритм очень медленно продвигается по узкому оврагу с крутыми склонами, прыгая с одной его стороны на другую. Напротив, при маленьком шаге, вероятно, будет схвачено верное направление, однако при этом потребуется очень много итераций. На практике величина шага берется пропорциональной крутизне склона (так что алгоритм замедляет ход вблизи минимума) с некоторой константой, которая называется скоростью обучения. Правильный выбор скорости обучения зависит от конкретной задачи и обычно осуществляется опытным путем; эта константа может также зависеть от времени, уменьшаясь по мере продвижения алгоритма. Обычно этот алгоритм видоизменяется таким образом, чтобы включать слагаемое импульса (или инерции). Этот член способствует продвижению в фиксированном направлении, поэтому если было сделано несколько шагов в одном и том же направлении, то алгоритм "увеличивает скорость", что (иногда) позволяет избежать локального минимума, а также быстрее проходить плоские участки. Таким образом, алгоритм действует итеративно, и его шаги принято называть эпохами. На каждой эпохе на вход сети поочередно подаются все обучающие наблюдения, выходные значения сети сравниваются с целевыми значениями и вычисляется ошибка. Значение ошибки, а также градиента поверхности ошибок используется для корректировки весов, после чего все действия повторяются. Начальная конфигурация сети выбирается случайным образом, и процесс обучения прекращается либо когда пройдено определенное количество эпох, либо когда ошибка достигнет некоторого определенного уровня малости, либо когда ошибка перестанет уменьшаться (пользователь может сам выбрать нужное условие остановки). 2.2 Переобучение и обобщение Одна из наиболее серьезных трудностей изложенного подхода заключается в том, что таким образом мы минимизируем не ту ошибку, которую на самом деле нужно минимизировать, - ошибку, которую можно ожидать от сети, когда ей будут подаваться совершенно новые наблюдения. Иначе говоря, мы хотели бы, чтобы нейронная сеть обладала способностью обобщать результат на новые наблюдения. В действительности сеть обучается минимизировать ошибку на обучающем множестве, и в отсутствие идеального и бесконечно большого обучающего множества это совсем не то же самое, что минимизировать "настоящую" ошибку на поверхности ошибок в заранее неизвестной модели явления (Bishop, 1995). Сильнее всего это различие проявляется в проблеме переобучения, или слишком близкой подгонки. Это явление проще будет продемонстрировать не для нейронной сети, а на примере аппроксимации посредством полиномов, - при этом суть явления абсолютно та же. Полином (или многочлен) - это выражение, содержащее только константы и целые степени независимой переменной. Вот примеры: y=2x+3 y=3x2+4x+1 Графики полиномов могут иметь различную форму, причем чем выше степень многочлена (и, тем самым, чем больше членов в него входит), тем более сложной может быть эта форма. Если у нас есть некоторые данные, мы можем поставить цель подогнать к ним полиномиальную кривую (модель) и получить таким образом объяснение для имеющейся зависимости. Наши данные могут быть зашумлены, поэтому нельзя считать, что самая лучшая модель задается кривой, которая в точности проходит через все имеющиеся точки. Полином низкого порядка может быть недостаточно гибким средством для аппроксимации данных, в то время как полином высокого порядка может оказаться чересчур гибким, и будет точно следовать данным, принимая при этом замысловатую форму, не имеющую никакого отношения к форме настоящей зависимости (см. рис.). 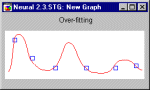 Рис 6 – График полинома Нейронная сеть сталкивается с точно такой же трудностью. Сети с большим числом весов моделируют более сложные функции и, следовательно, склонны к переобучению. Сеть же с небольшим числом весов может оказаться недостаточно гибкой, чтобы смоделировать имеющуюся зависимость. Например, сеть без промежуточных слоев на самом деле моделирует обычную линейную функцию. Как же выбрать "правильную" степень сложности для сети? Почти всегда более сложная сеть дает меньшую ошибку, но это может свидетельствовать не о хорошем качестве модели, а о переобучении. Ответ состоит в том, чтобы использовать механизм контрольной кросс-проверки. Мы резервируем часть обучающих наблюдений и не используем их в обучении по алгоритму обратного распространения. Вместо этого, по мере работы алгоритма, они используются для независимого контроля результата. В самом начале работы ошибка сети на обучающем и контрольном множестве будет одинаковой (если они существенно отличаются, то, вероятно, разбиение всех наблюдений на два множества было неоднородно). По мере того, как сеть обучается, ошибка обучения, естественно, убывает, и, пока обучение уменьшает действительную функцию ошибок, ошибка на контрольном множестве также будет убывать. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть начала слишком близко аппроксимировать данные и обучение следует остановить. Это явление чересчур точной аппроксимации в процессе обучения и называется переобучением. Если такое случилось, то обычно советуют уменьшить число скрытых элементов и/или слоев, ибо сеть является слишком мощной для данной задачи. Если же сеть, наоборот, была взята недостаточно богатой для того, чтобы моделировать имеющуюся зависимость, то переобучения, скорее всего, не произойдет, и обе ошибки - обучения и проверки - не достигнут достаточного уровня малости. Описанные проблемы с локальными минимумами и выбором размера сети приводят к тому, что при практической работе с нейронными сетями, как правило, приходится экспериментировать с большим числом различных сетей, порой обучая каждую из них по нескольку раз (чтобы не быть введенным в заблуждение локальными минимумами) и сравнивая полученные результаты. Главным показателем качества результата является здесь контрольная ошибка. При этом, в соответствии с общенаучным принципом, согласно которому при прочих равных следует предпочесть более простую модель, из двух сетей с приблизительно равными ошибками контроля имеет смысл выбрать ту, которая меньше. Необходимость многократных экспериментов ведет к тому, что контрольное множество начинает играть ключевую роль в выборе модели, то есть становится частью процесса обучения. Тем самым ослабляется его роль как независимого критерия качества модели - при большом числе экспериментов есть риск выбрать "удачную" сеть, дающую хороший результат на контрольном множестве. Для того, чтобы придать окончательной модели должную надежность, часто (по крайней мере, когда объем обучающих данных это позволяет) поступают так: резервируют еще одно - тестовое множество наблюдений. Итоговая модель тестируется на данных из этого множества, чтобы убедиться, что результаты, достигнутые на обучающем и контрольном множествах реальны, а не являются артефактами процесса обучения. Разумеется, для того чтобы хорошо играть свою роль, тестовое множество должно быть использовано только один раз: если его использовать повторно для корректировки процесса обучения, то оно фактически превратится в контрольное множество. 2.3 Модели теории адаптивного резонанса Напомним, что дилемма стабильности-пластичности является важной особенностью обучения методом соревнования. Как обучать новым явлениям (пластичность) и в то же время сохранить стабильность, чтобы существующие знания не были стерты или разрушены? Карпентер и Гроссберг, разработавшие модели теории адаптивного резонанса (ART1, ART2 и ARTMAP), сделали попытку решить эту дилемму. Сеть имеет достаточное число выходных элементов, но они не используются до тех пор, пока не возникнет в этом необходимость. Будем говорить, что элемент распределен (не распределен), если он используется (не используется). Обучающий алгоритм корректирует имеющийся прототип категории, только если входной вектор в достаточной степени ему подобен. В этом случае они резонируют. Степень подобия контролируется параметром сходства k, 0 Чтобы проиллюстрировать модель, рассмотрим сеть ART1, которая рассчитана на бинарный (0/1) вход. Упрощенная схема архитектуры ART1 представлена на рис. 7. Она содержит два слоя элементов с полными связями. 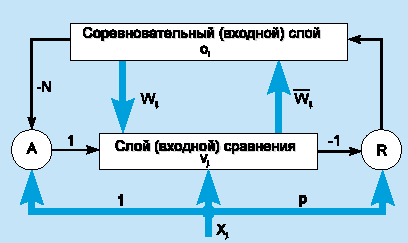 Рис.7 - Архитектура ART1 Направленный сверху вниз весовой вектор wj соответствует элементу j входного слоя, а направленный снизу вверх весовой вектор i связан с выходным элементом i; i является нормализованной версией wi . Векторы wj сохраняют прототипы кластеров. Роль нормализации состоит в том, чтобы предотвратить доминирование векторов с большой длиной над векторами с малой длиной. Сигнал сброса R генерируется только тогда, когда подобие ниже заданного уровня. Модель ART1 может создать новые категории и отбросить входные примеры, когда сеть исчерпала свою емкость. Однако число обнаруженных сетью категорий чувствительно к параметру сходства.
Вероятно, эта архитектура сети используется сейчас наиболее часто. Она была предложена в работе Rumelhart, McClelland (1986) и подробно обсуждается почти во всех учебниках по нейронным сетям. Вкратце этот тип сети был описан выше. Каждый элемент сети строит взвешенную сумму своих входов с поправкой в виде слагаемого и затем пропускает эту величину активации через передаточную функцию, и таким образом получается выходное значение этого элемента. Элементы организованы в послойную топологию с прямой передачей сигнала. Такую сеть легко можно интерпретировать как модель вход-выход, в которой веса и пороговые значения (смещения) являются свободными параметрами модели. Такая сеть может моделировать функцию практически любой степени сложности, причем число слоев и число элементов в каждом слое определяют сложность функции. Определение числа промежуточных слоев и числа элементов в них является важным вопросом при конструировании MLP. Количество входных и выходных элементов определяется условиями задачи. Сомнения могут возникнуть в отношении того, какие входные значения использовать, а какие нет, - к этому вопросу мы вернемся позже. Сейчас будем предполагать, что входные переменные выбраны интуитивно и что все они являются значимыми. Вопрос же о том, сколько использовать промежуточных слоев и элементов в них, пока совершенно неясен. В качестве начального приближения можно взять один промежуточный слой, а число элементов в нем положить равным полусумме числа входных и выходных элементов. Опять-таки, позже мы обсудим этот вопрос подробнее. 3.1 Обучение многослойного персептрона После того, как определено число слоев и число элементов в каждом из них, нужно найти значения для весов и порогов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Именно для этого служат алгоритмы обучения. С использованием собранных исторических данных веса и пороговые значения автоматически корректируются с целью минимизировать эту ошибку. По сути, этот процесс представляет собой подгонку модели, которая реализуется сетью, к имеющимся обучающим данным. Ошибка для конкретной конфигурации сети определяется путем прогона через сеть всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений с желаемыми (целевыми) значениями. Все такие разности суммируются в так называемую функцию ошибок, значение которой и есть ошибка сети. В качестве функции ошибок чаще всего берется сумма квадратов ошибок, т.е. когда все ошибки выходных элементов для всех наблюдений возводятся в квадрат и затем суммируются. В традиционном моделировании (например, линейном моделировании) можно алгоритмически определить конфигурацию модели, дающую абсолютный минимум для указанной ошибки. Цена, которую приходится платить за более широкие (нелинейные) возможности моделирования с помощью нейронных сетей, состоит в том, что, корректируя сеть с целью минимизировать ошибку, мы никогда не можем быть уверены, что нельзя добиться еще меньшей ошибки. В этих рассмотрениях оказывается очень полезным понятие поверхности ошибок. Каждому из весов и порогов сети (т.е. свободных параметров модели; их общее число обозначим через N) соответствует одно измерение в многомерном пространстве. N+1-е измерение соответствует ошибке сети. Для всевозможных сочетаний весов соответствующую ошибку сети можно изобразить точкой в N+1-мерном пространстве, и все такие точки образуют там некоторую поверхность - поверхность ошибок. Цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности самую низкую точку. В случае линейной модели с суммой квадратов в качестве функции ошибок эта поверхность ошибок будет представлять собой параболоид (квадрику) - гладкую поверхность, похожую на часть поверхности сферы, с единственным минимумом. В такой ситуации локализовать этот минимум достаточно просто. В случае нейронной сети поверхность ошибок имеет гораздо более сложное строение и обладает рядом неприятных свойств, в частности, может иметь локальные минимумы (точки, самые низкие в некоторой своей окрестности, но лежащие выше глобального минимума), плоские участки, седловые точки и длинные узкие овраги. Аналитическими средствами невозможно определить положение глобального минимума на поверхности ошибок, поэтому обучение нейронной сети по сути дела заключается в исследовании поверхности ошибок. Отталкиваясь от случайной начальной конфигурации весов и порогов (т.е. случайно взятой точки на поверхности ошибок), алгоритм обучения постепенно отыскивает глобальный минимум. Как правило, для этого вычисляется градиент (наклон) поверхности ошибок в данной точке, а затем эта информация используется для продвижения вниз по склону. В конце концов алгоритм останавливается в нижней точке, которая может оказаться всего лишь локальным минимумом (а если повезет - глобальным минимумом).
Задача оценки плотности вероятности (p.d.f.) по данным имеет давнюю историю в математической статистике и относится к области байесовой статистики. Обычная статистика по заданной модели говорит нам, какова будет вероятность того или иного исхода (например, что на игральной кости шесть очков будет выпадать в среднем одном случае из шести). Байесова статистика переворачивает вопрос вверх ногами: правильность модели оценивается по имеющимся достоверным данным. В более общем плане, байесова статистика дает возможность оценивать плотность вероятности распределений параметров модели по имеющимся данных. Для того, чтобы минимизировать ошибку, выбирается модель с такими параметрами, при которых плотность вероятности будет наибольшей. При решении задачи классификации можно оценить плотность вероятности для каждого класса, сравнить между собой вероятности принадлежности различным классам и выбрать наиболее вероятный. На самом деле именно это происходит, когда мы обучаем нейронную сеть решать задачу классификации - сеть пытается определить (т.е. аппроксимировать) плотность вероятности. Традиционный подход к задаче состоит в том, чтобы построить оценку для плотности вероятности по имеющимся данным. Обычно при этом предполагается, что плотность имеет некоторый определенный вид (чаще всего - что она имеет нормальное распределение). После этого оцениваются параметры модели. Нормальное распределение часто используется потому, что тогда параметры модели (среднее и стандартное отклонение) можно оценить аналитически. При этом остается вопрос о том, что предположение о нормальности не всегда оправдано. Другой подход к оценке плотности вероятности основан на ядерных оценках. Можно рассуждать так: тот факт, что наблюдение расположено в данной точке пространства, свидетельствует о том, что в этой точке имеется некоторая плотность вероятности. Кластеры из близко лежащих точек указывают на то, что в этом месте плотность вероятности большая. Вблизи наблюдения имеется большее доверие к уровню плотности, а по мере отдаления от него доверие убывает и стремится к нулю. В методе ядерных оценок в точке, соответствующей каждому наблюдению, помещается некоторая простая функция, затем все они складываются и в результате получается оценка для общей плотности вероятности. Чаще всего в качестве ядерных функций берутся гауссовы функции (с формой колокола). Если обучающих примеров достаточное количество, то такой метод дает достаточно хорошее приближение к истинной плотности вероятности. Метод аппроксимации плотности вероятности с помощью ядерных функций во многом похож на метод радиальных базисных функций, и таким образом мы естественно приходим к понятиям вероятностной нейронной сети (PNN) и обобщенно-регрессионной нейронной сети (GRNN). PNN-сети предназначены для задач классификации, а GRNN - для задач регрессии. Сети этих двух типов представляют собой реализацию методов ядерной аппроксимации, оформленных в виде нейронной сети. Сеть PNN имеет по меньшей мере три слоя: входной, радиальный и выходной. Радиальные элементы берутся по одному на каждое обучающее наблюдение. Каждый из них представляет гауссову функцию с центром в этом наблюдении. Каждому классу соответствует один выходной элемент. Каждый такой элемент соединен со всеми радиальными элементами, относящимися к его классу, а со всеми остальными радиальными элементами он имеет нулевое соединение. Таким образом, выходной элемент просто складывает отклики всех элементов, принадлежащих к его классу. Значения выходных сигналов получаются пропорциональными ядерным оценкам вероятности принадлежности соответствующим классам, и пронормировав их на единицу, мы получаем окончательные оценки вероятности принадлежности классам. Базовая модель PNN-сети может иметь две модификации. В первом случае мы предполагаем, что пропорции классов в обучающем множестве соответствуют их пропорциям во всей исследуемой популяции (или так называемым априорным вероятностям). Например, если среди всех людей больными являются 2%, то в обучающем множестве для сети, диагностирующей заболевание, больных должно быть тоже 2%. Если же априорные вероятности будут отличаться от пропорций в обучающей выборке, то сеть будет выдавать неправильный результат. Это можно впоследствии учесть (если стали известны априорные вероятности), вводя поправочные коэффициенты для различных классов. Второй вариант модификации основан на следующей идее. Любая оценка, выдаваемая сетью, основывается на зашумленных данных и неизбежно будет приводить к отдельным ошибкам классификации (например, у некоторых больных результаты анализов могут быть вполне нормальными). Иногда бывает целесообразно считать, что некоторые виды ошибок обходятся "дороже" других (например, если здоровый человек будет диагностирован как больной, то это вызовет лишние затраты на его обследование, но не создаст угрозы для жизни; если же не будет выявлен действительный больной, то это может привести к смертельному исходу). В такой ситуации те вероятности, которые выдает сеть, следует домножить на коэффициенты потерь, отражающие относительную цену ошибок классификации. Вероятностная нейронная сеть имеет единственный управляющий параметр обучения, значение которого должно выбираться пользователем, - степень сглаживания (или отклонение гауссовой функции). Как и в случае RBF-сетей, этот параметр выбирается из тех соображений, чтобы шапки " определенное число раз перекрывались": выбор слишком маленьких отклонений приведет к "острым" аппроксимирующим функциям и неспособности сети к обобщению, а при слишком больших отклонениях будут теряться детали. Требуемое значение несложно найти опытным путем, подбирая его так, чтобы контрольная ошибка была как можно меньше. К счастью, PNN-сети не очень чувствительны к выбору параметра сглаживания. Наиболее важные преимущества PNN-сетей состоят в том, что выходное значение имеет вероятностный смысл (и поэтому его легче интерпретировать), и в том, что сеть быстро обучается. При обучения такой сети время тратится практически только на то, чтобы подавать ей на вход обучающие наблюдения, и сеть работает настолько быстро, насколько это вообще возможно. Существенным недостатком таких сетей является их объем. PNN-сеть фактически вмещает в себя все обучающие данные, поэтому она требует много памяти и может медленно работать. PNN-сети особенно полезны при пробных экспериментах (например, когда нужно решить, какие из входных переменных использовать), так как благодаря короткому времени обучения можно быстро проделать большое количество пробных тестов. |