Реферат. Существует следующие основные формы статического анализа программного обеспечения
 Скачать 145.66 Kb. Скачать 145.66 Kb.
|

ВведениеВ процессе разработки ПО требуются меры по выявлению ошибок и недочетов в его работе и исходном коде. Для выполнения данной задачи используются различные методы анализа ПО. Анализ ПО можно разделить на две категории: статический и динамический. Статический анализ ПО выявляет ошибки в исходном коде и проводится без реального выполнения программ. Динамический анализ, наоборот, проводится при помощи выполнения программного кода, таким образом, он позволяет выявить ошибки в работе ПО. Данное исследование заостряет внимание на статическом анализе программного кода. Один из самых старых методов выявления дефектов в исходном коде — это обзор кода (code review). Он заключается в совместном внимательном чтении исходного кода и высказывании рекомендаций по его улучшению. [1] Однако появляется желание автоматизировать данный процесс, поэтому придуманы другие методы, которые реализованы в различных инструментах анализа ПО. Существует следующие основные формы статического анализа программного обеспечения: метрики программного обеспечения, при данном методе анализа ПО программный код рассматривается с перспективы разных численных показателей, на основе которых уже в дальнейшем делаются выводы об улучшении программы; визуализация программного обеспечения, визуализируются различные абстрактные структуры, представляющие компоненты или динамику работы программы; выявление ошибок в коде, помимо синтаксических, семантические и др., например, неопределенное поведение, нарушение алгоритма пользования библиотекой, переполнение буфера и т. д. В данной работе метрики и визуализации (один из методов обратного инжиниринга) считаются формами статического анализа. Однако многие считают по-другому, но в любом случае метрики и визуализация совмещаются со статическим анализом. Актуальность темыКак уже говорилось в предыдущем разделе, созданы различные инструменты анализа ПО. Данные инструменты реализованы, как standalone-приложения, которые производят анализ локально хранящегося кода. Однако статический анализ не требует реального выполнения программы, соответственно его можно провести на исходном коде, который хранится любым способом. То есть, весь процесс интеграции сводится только к проблеме получения исходного кода проекта инструментами статического анализа. В настоящее время существует множество способов хранения исходного кода проекта: веб-сервисы для хостинга программных проектов, частные (закрытые) репозитории, собственный хостинг репозиториев и т.д. Самым популярными среди таких подходов являются веб-сервисы для хостинга проектов. Данные веб-сервисы основаны на разных системах контроля версий, из-за чего они обладают всеми возможностями систем контроля версий и также дополнительными уникальными для этих сервисов. Наличие всех возможностей СКВ у данных веб-сервисов позволяет им хранить исходный код проекта удаленно. В связи с популярностью подобных веб-сервисов и наличия у них возможности хранения кода, актуально рассмотреть интегрирование статического анализа с веб-сервисами для хостинга программных проектов. Статья Интегрируемый статический анализ для программного проекта с использованием архитектурного стиля REST [2] представлена на III Международной научно-практической конференции Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС-2020). В ней описывается подробно данный интегрируемый подход к статическому анализу программного проекта. 2. Цель и задачи исследованияЦелью исследования является разработка подхода к статическому анализу, при котором его можно интегрировать в существующий программный проект, хранящимся на веб-сервисе для хостинга проектов. Подход разрабатывается с учетом преимуществ и недостатков существующих подходов. Исследование фокусируется на статическом анализе императивных языков программирования, конкретно, на анализе программных проектов на языке С. Также в конце исследования должна быть разработана программная модель, представляющая собой систему статического анализа программного проекта, написанного на языке C, которая интегрируется с проектом, хранящимся на веб-сервисе для хостинга проектов. Основные задачи исследования: исследование архитектурного подхода REST для создания веб-сервисов, метрик программного кода для императивных языков программирования, методов визуализации ПО; анализ существующих методов и средств оценки программного обеспечения, написанного на императивных языках программирования (язык С и другие подобные), выявление недостатков в алгоритмах для вычисления и визуализации метрик и методов оценки ПО в существующих решениях; поиск возможных способов устранения найденных недостатков в алгоритмах вычисления и визуализации метрик ПО, предложения по улучшению существующих алгоритмов, разработка интегрируемого подхода к статическому анализу; разработка архитектуры программной модели статического анализа с использованием архитектурного подхода REST, выбор средств реализации клиентской и серверной части; реализация клиентской и серверной части программной модели; оптимизация, тестирование архитектуры программной модели; анализ эффективности предложенных улучшений существующих алгоритмов и нового интегрируемого метода для анализа ПО. Объекты исследования: статический анализ ПО и архитектурный подход REST. Предмет исследования: интеграция статического анализа ПО в существующих программный проект с использованием REST. 3. Обзор исследований и разработок Исследование затрагивает следующие области разработки ПО: метрики программного обеспечения, визуализация метрик и кода программного проекта, распределенные системы и архитектурный подход к созданию веб-сервисов REST. Рассмотрим различные исследования в каждой из этих областей. 3.1 Обзор исследований в области метрик ПО Разные авторы рассматривают различные метрики для программного обеспечения. Данная работа рассматривает метрики только для императивных языков программирования, но даже для императивных языков есть различное множество метрик. Морис Холстед предложил полноценный набор метрик ПО, который отображает характеристики существующей программы. [3] Данные метрики не полагаются на традиционный подсчет строк кода (LOC), а на подсчет количества операндов и операторов. Набор метрик делится на: базовые показатели, различные метрики объема программы, уровня качества, трудоемкости и затрат. Томас Мак-Кейб описал метрику цикломатической сложности программы. [4] Метрика основана на анализе потока передачи управления от одного оператора к другому. Такой подход позволяет учесть логику программы. Программа представляется в виде управляющего ориентированного графа, такой граф называют графом управления, графом потока управления или управляющим графом программы. Метрика Мак-Кейба является цикломатическим числом графа управления, сумма количества ребер и вершин графа. Для данной метрики существуют модификации, предложенные разными авторами, две самые известные — Майерса и Хансена. [5]. В работе описываются различные метрики Холстеда, цикломатическая метрика Мак-Кейба. Также помимо этих метрик, разобраны различные метрики для объектно-ориентированных языков: количество вызываемых удаленных методов (NORM), отклик на класс (RFC), взвешенная насыщенность класса (WMPC1, WMPC2) и др. Представлены количественные метрики: количество строк кода (LOC), количество классов (NOC), число происходящих классов (NDC), число локальных методов (NLM) и т. д. Виктор Базили и Ричард Сэлби рассмотрели различные стратегии тестирования. [6] Работа показывает, что существует широкий диапазон стратегий тестирования. Из-за такого широкого диапазона стратегий тестирования, полезно использовать метрики, которые подсчитывают количество тестовых случаев, требуемых для каждой стратегии для заданной программы, например, метрика Мак-Кейба может измерить количество тестовых случаев требуемых для структурного тестирования. Большинство современных языков поддерживают модульность. Одним из намерений при разбиении программы на модули — предотвратить влияние изменения одного модуля на другой. Для того чтобы измерить подобную связь, Норман Фэнтон предложил классифицировать модули на 6 классов сцепления. [7] В дальнейшем сцепление для программы может быть построен граф модели сцепления. Граф модели сцепления может предоставить хороший метод визуализации сцеплений между модулями. Обычно модульные программы состоят из модулей с данными, протекающими через них способом, называемым информационным потоком. Информационные потоки могут показать сложные взаимодействия и сложное алгоритмическое поведение в программе. Сэлли Гэнри и Дэннис Кафура предложили метрику для модулей, которая подсчитывает кол-во таких потоков, завершающихся в модуле и происходящих из модуля. [8] Данная метрика позволяет определить влияние модулей на информационный поток программы, и, таким образом, выявить, что делает изменения и тестирования в программе более сложным. 3.2 Обзор исследований в области визуализации ПО Диана Сидаркевичуте утверждает, что самыми часто используемыми инструментами визуализации являются просмотрщики кода. [9] Просмотрщики предоставляют фиксированный набор графических представлений ввода программы: графовые структуры, прямые и обратные слайсеры, дайсеры, просмотр “мертвого” кода (недостижимый код). Но в связи с огромным размером современных программ, использование графовых структур или различного вида просмотра кода не всегда находит свое применение, в процессе визуализации представления могут стать сильно загроможденными. Янг П. и Манро М. описали визуализацию, основанную на трехмерных геометрических формах, таких как кубы и цилиндры [10]. Их система состоит из двух частей, CallStax и FileVis, которые можно объединить в одну систему визуализации. Есть и другие виды визуализаций с использованием абстрактных структур: представления кода в виде реального мира (например, города), полиметрические представления, гиперболические деревья, тримапинг, радар эволюции и др. 3.3 Обзор исследований в области распределенных систем и архитектурного подхода REST Можно подойти к созданию интегрируемого статического анализатора по-разному. Например, можно создать анализатор в виде утилиты, однако это усложняет разработку под несколько платформ. Поэтому лучше использовать подход, при котором анализатор создается как веб-сервис. Чтобы облегчить процесс интеграции анализатора при разработке, можно использовать серверную архитектуру REST. Однако перед рассмотрением подхода REST и ограничений, которые он накладывает на архитектуру приложения, необходимо рассмотреть понятие промежуточного программного обеспечения. Щелоков С. А. выделяет следующие требования к распределенным системам: открытость, масштабируемость, стабильность и безопасность. Он утверждает, что для удовлетворения этим требованиям, система должна включать дополнительный уровень программного обеспечения, который находится между прикладным и транспортным уровнями по модели OSI, называемый промежуточное программное обеспечение. [11] Промежуточная среда должна обеспечивать обмен данными между компонентами распределенной системы. В сети интернет на базе протоколов TCP, HTTP можно построить протоколы более высокого уровня для реализации удаленного вызова процедур. Удаленный вызов процедур можно представить как обычный HTTP-запрос (GET или POST, такой запрос называют REST-запрос). На этом и основан архитектурный стиль REST, который является одним из способов обмена данными между компонентами распределенной системы. Архитектурный стиль REST предложен Роем Филдингом в своей диссертации «Архитектурные стили и дизайн сетевых программных архитектур» в Калифорнийском университете в Ирвайне в 2000 году. [13] По сути понятие REST относится не к архитектуре, а к набору ограничений, накладываемых на архитектуру системы. Приведем обязательные: приведение архитектуры системы к модели клиент-сервер, отсутствие состояний между запросами, кэширование запросов, единообразие интерфейса, слои (промежуточные сервера), код по требованию (необязательное требование). Единообразие интерфейса — сложное требование, состоящее из подпунктов: идентификация ресурсов; манипуляция ресурсами через представление; самоописываемые сообщения; гипермедиа, как средство изменения состояния приложения (HATEOAS). [14] Таким образом, REST — это набор принципов при проектировании архитектуры системы, а не архитектура или протокол. Также при проектировании необязательно четко придерживаться набора требований, тогда подобная система будет называться REST-like. Использование REST делает разработку распределенных веб-сервисов простой и гибкой. 4. Подход к статическому анализу с интеграцией с веб-сервисами хостинга проектов Как говорилось в предыдущем разделе, инструмент для статического анализа кода должен быть создан как веб-сервис. Веб-сервис проще интегрируется с другими инструментами сборки, развертывания и тестирования проекта. Это упрощает его использование в непрерывной интеграции (CI) [15] и в непрерывном развертывании (CD) [16]. Также веб-сервис позволяет сделать систему статического анализа кросс-платформенной, снизить нагрузку на систему, в которую интегрируется статический анализ. 4.1. Требования к веб-сервису для статического анализа кодаНаличие REST API у веб-сервиса позволяет упростить интеграцию с веб-сервисами для хостинга программных проектов. Все популярные веб-сервисы для хостинга проектов, например Github [17] или Gitlab [18], обладают REST API. То есть веб-сервис для статического анализа должен быть спроектирован с использованием архитектурного подхода REST. Статический анализ существует в следующих формах: метрики ПО, визуализация ПО и выявление ошибок в коде. Необходимо определиться какие виды метрик и визуализаций будут использоваться в системе статического анализа. У веб-сервиса присутствует REST интерфейс, соответственно для него тоже необходимо выдвинуть требования. 4.1.1. Требования к метрикам, используемым веб-сервисомВеб-сервис статического анализа должен вычислять следующие метрики ПО: разнообразные метрики строк кода (SLOC, NCLOC, CLOC, количество пустых строк кода, процент комментариев, среднее число строк для функций, среднее число строк исходного кода для функций и т.д.); метрики Хотстеда (полагаются на подсчет операндов и операторов); метрики цикломатической сложности (для оценки сложности потока управления программы); метрики покрытий кода для измерения сложности тестирования; метрики для измерения сложности модулей программы (для языка C модулями выступают функции). Также помимо используемых метрик, можно выдвинуть требования к их отображению, фильтрации и экспорту. Для фильтрации следует использовать следующие критерии: набор функций, набор файлов. Также метрики должны вычисляться для 3-х уровней: проект, файлы, функции. Должны выводиться рекомендуемые значения для метрик (верхние и нижние границы). Возможность сравнения метрик между релизами проекта должна присутствовать в системе. Самым важным форматом для экспорта метрик является CSV [19], т.к. он позволяет улучшить интеграцию с другими утилитами. Также должен быть хотя бы один формат удобный для чтения, например, HTML [20]. 4.1.2. Требования к визуализациям, используемым веб-сервисомВ качестве подходов к визуализации веб-сервис должен использовать следующие: графовые структуры (в особенности, для отображения потока управления программы), однако с возможностью интерактивного взаимодействия с графом, таким образом решается проблема загроможденности представления графов; тримапинг для отображения объемов функций (модулей) и файлов по различным метрикам и критериям выбора, например, файлы текущей директории; полиметрические представления для отображения различных метрик, которые не только измеряют объем какого-либо объекта программы; эволюционные радары для демонстрации сцепления функций (модулей). Также стоит добавить фильтрацию с использованием динамических запросов по значениям метрик при визуализации ПО. 4.1.3. Требования к REST интерфейсу и веб интерфейсу сервисаЗапросы к REST API можно поделить на 2 типа: записи и чтения. Запросы типа чтения используются для получения информации о проекте или вычисленных метриках. Запросы типа записи позволяют создавать проект или изменять его содержимое. Основная идея запросов типа записи в том, что все метрики вычисляются по связанным с запросом файлам (или по проекту в целом). В дальнейшем клиент получает просто информацию о вычисленных метриках при помощи запросов чтения. Все запросы манипулируют ресурсами проекта посредством представлений, которые можно получить через определенный ресурс. Ресурсы могут быть вложенными друг в друга. В итоге они образуют древовидную структуру. Данная структура ресурсов представлена на рис. 1. 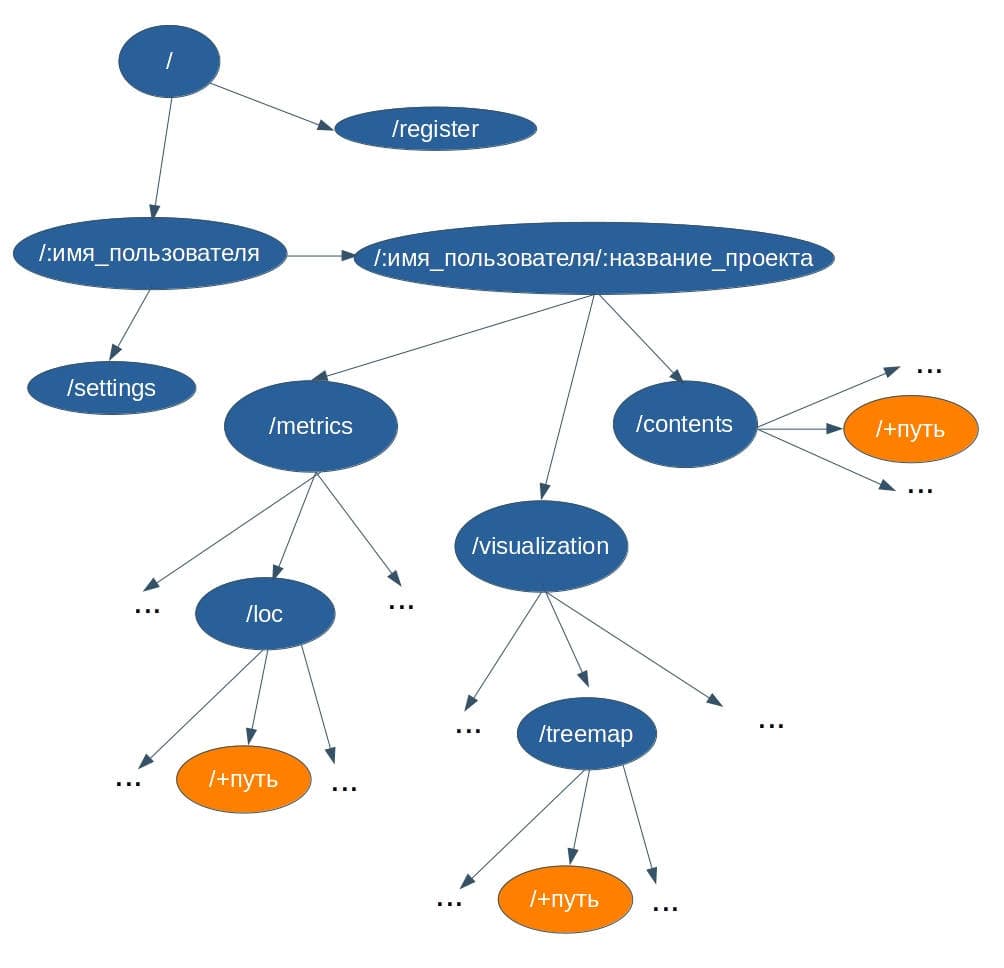 Рисунок 1 — Дерево ресурсов REST API веб-сервиса От корня ответвляются следующие ресурсы: register и :имя_пользователя (параметр, который указывается при запросе, например, /omegadog). Используя запрос register, можно создать аккаунт в системе. Затем, используя имя пользователя, указанное в аккаунте, можно управлять проектами этого аккаунта. Таким образом ресурс /:имя_пользователя/:название_проекта (:название_проекта — это параметр, который определяет имя проекта на аккаунте с именем пользователя :имя_пользователя) является корневым ресурсом для всех запросов, которые управляют проектом. При помощи ресурса contents управляют содержимым проекта, добавляют или удаляют файлы, или получают информацию о файле или директории проекта. Затем впоследствии можно получить метрики файла, директории или проекта при помощи ресурса metrics, используя полученные пути при помощи contents. То есть, если клиент получил какой-то путь при помощи contents, например, /contents/директория1/файл1, то используя ресурс metrics и тот же путь (/metrics/директория1/файл1), можно получить метрики по этому пути. Тот же самый подход к запросам используется и для ресурса visualization, который позволяет получить визуализации для указанного пути. Ресурс /:имя_пользователя/settings используется для изменения настроек аккаунта с именем пользователя :имя_пользователя. Запросы сервиса принимают разные параметры, существует 2 способа передачи параметров: параметры запроса или в теле запроса. Параметры, которые передаются в теле запроса, обычно сложно представить в параметрах запроса, например, HTTP [21] ссылка на другой ресурс. Тело запроса описывается в JSON формате, параметры внутри тела представляются в виде ключ-значение (поле-значение) JSON [22] объекта. В запросах используются следующие методы HTTP: GET, PUT, POST. Метод POST используется при создании представления или ресурса, например, запрос на создание проекта. При запросе на создание проекта, клиент обращается к ресурсу /:имя_пользователя/:название_проекта с использованием метода POST и передает параметры, необходимые для создания проекта. Для получения представлений используется метод GET, клиенту при обращении к ресурсу с использованием данного метода возвращается JSON объект (представление ресурса). В случае, если клиенту необходимо только внести изменения в существующий ресурс, то он проделывает тот же протокол действий, как и в случае с методом POST, только использует метод PUT. Запросы типа записи должны быть аутентифицированы, поэтому при в запросе должно быть поле для передачи HMAC [23] запроса. Если запрос не был аутентифицирован, то запрос должен вернуть ответ 403 Forbidden. Подписывание запросов HMAC сделано для того, чтобы разграничить права среди клиентов. Для доверенных клиентов следует сгенерировать секретные ключи, сервис и данные клиенты должны разделять эти ключи. Для доверенных клиентов должна быть возможность создания аккаунтов в системе, чтобы привязать секретные ключи к аккаунтам. Процесс создания аккаунта можно выполнить при помощи REST интерфейса, однако его проще выполнить с использованием графического интерфейса или интерфейса командной строки. Для сервиса лучше всего использовать веб-интерфейс в качестве графического интерфейса, поэтому сервис должен обладать данным видом интерфейса. Также возможно добавление интерфейса командной строки при дальнейшей разработке сервиса. Веб-интерфейс должен обладать минимальными возможностями для создания и управления аккаунтами, генерации и получения секретных ключей для пользования REST API сервиса. Остальные возможности сервиса могут быть добавлены в интерфейс при дальнейшей разработке. 4.2. Пример интеграции веб-сервиса статического анализа с веб-сервисом хостинга проектовРассмотрим пример интеграции веб-сервиса статического анализа с веб-сервисом Github, который является крупнейшим сервисом для хостинга проектов на данный момент. Данный сервис, как и многие подобные, поддерживает подписку на события, которые происходят в репозитории проекта. При возникновении события отправляется POST запрос на указанный URL REST интерфейса, данная возможность называется веб-хуками (webhooks) [24]. Сервис поддерживает разные события: create, Git ветка или тэг созданы; delete, Git ветка или тэг удалены; fork, пользователь создал форк репозитория; pull_request, произошел запрос на получение (git pull) ветки или тэга репозитория; push, один или несколько коммитов отправлены (git push) в ветку или тэг репозитория; и т.д. Из перечисленных событий ниже, для сервиса статического анализа наиболее важным является push. Т.к. необходимо отслеживать изменения, происходящие в ветке репозитория, и затем вычислять метрики и визуализации с учетом новых изменений. Также REST интерфейс сервиса статического анализа должен обладать ресурсом для обработки веб-хуков, то есть для каждого проекта должен быть выделен ресурс для данного обработчика. Например, для обработчика веб-хуков сервиса Github, можно выделять следующий ресурс /:имя_пользователя/:название_проекта/webhook/github, где :имя_пользователя и :название_проекта — это параметры, которые изменяются в зависимости от аккаунта владельца проекта и самого названия проекта. Веб-хук для события push передает большое количество параметров в теле запроса, однако самым важным параметром является after, который хранит SHA-хеш [25] последнего отправленного коммита в ветку. Имея данное значение хеша, сервис в дальнейшем может обработать изменения в ветке репозитория с использованием REST API Github. Опишем процесс обработки изменений в ветке репозитория при получении веб-хука push сервисом статического анализа. Процесс состоит из следующих этапов: Получив SHA-хеш последнего коммита, сервис отправляет запрос на получения информации о коммите с использованием запроса REST API Github /repos/:имя_пользователя/:название_проекта/git/commits/:хеш_коммита. В ответе на запрос, приходит много параметров, но важным является параметр tree. Параметр tree — это объект, внутри которого хранится свойство sha. Свойство sha хранит SHA-хеш дерева BLOB-объектов [26], на которое указывает коммит. При помощи запроса /repos/:имя_пользователя/:название_проекта/git/trees/:хеш_дерева, в ответе на запрос получаем структуру дерева. Данная структура хранится в параметре tree, это массив объектов JSON. Важными параметрами каждого объекта являются: path (путь к файлу или директории), type (BLOB или дерево (tree)) и sha (SHA-хеш BLOB-объекта или поддерева). В случае возникновения новых путей, необходимо добавить соответствующе ресурсы для проекта. Необходимо сверить для каждого уже существующего пути хеш-значения со значениями, которые хранятся на сервисе статического анализа. В случае несовпадения значений и если путь является типа BLOB, необходимо получить содержимое при помощи запроса /repos/:имя_пользователя/:название_проекта/git/blobs/:хеш_blob. Для каждого нового пути тоже необходимо получить содержимое, если тип нового пути BLOB. Ответ на данный запрос содержит 2 поля: content (содержимое BLOB-объекта) и encoding (кодирование данных в поле content, например, base64 [27]). В случае несовпадений хеш-значений и если путь является поддеревом (тип tree), рекурсивно повторить шаги 2–5. Для нового пути с типом tree, тоже повторить шаги 2–5 для поддерева. На рисунке 2 показан конкретный пример процесса обработки изменений в ветке репозитория при отправке веб-хука push сервису статического анализа, в данном примере в ветку репозитория отправляется коммит, который изменяет файл file1.c и добавляет file2.c. 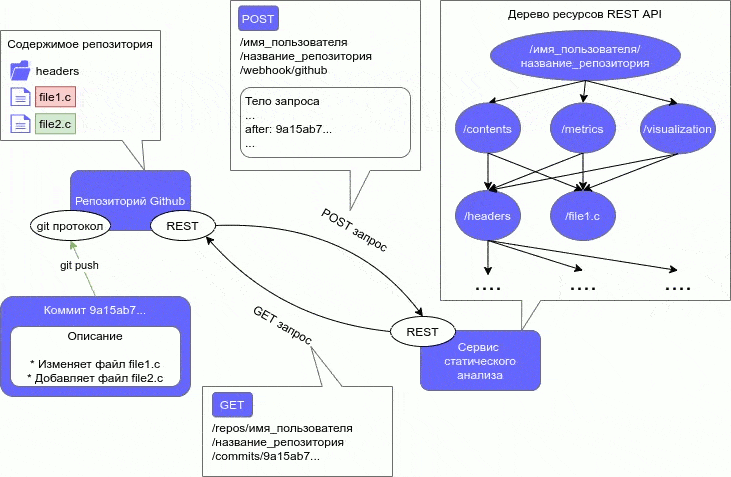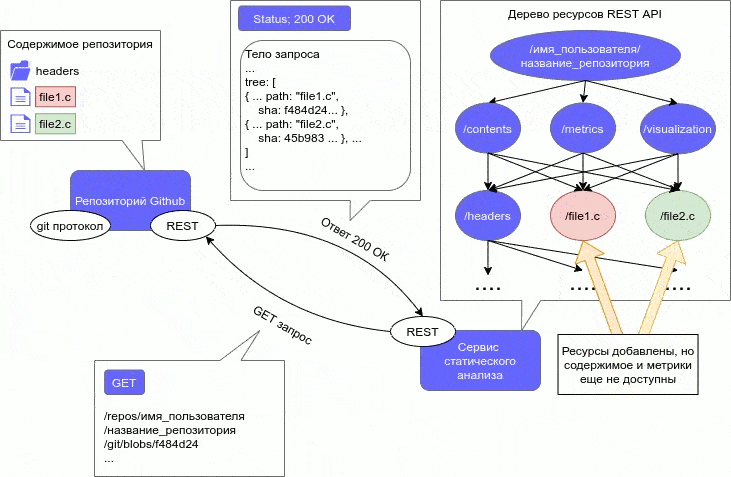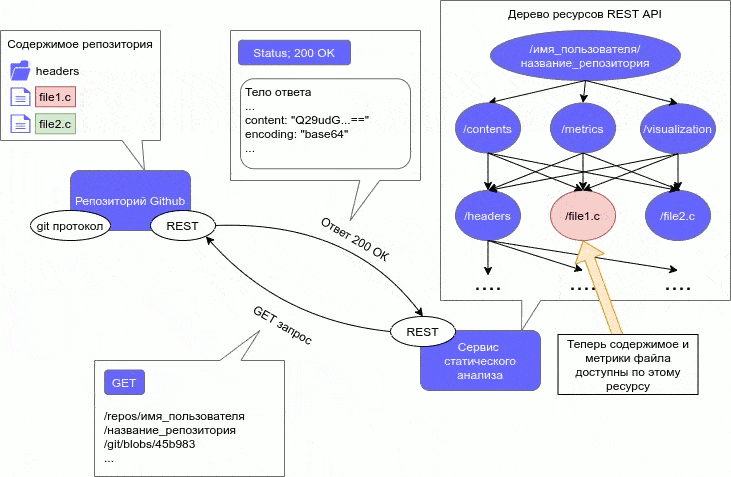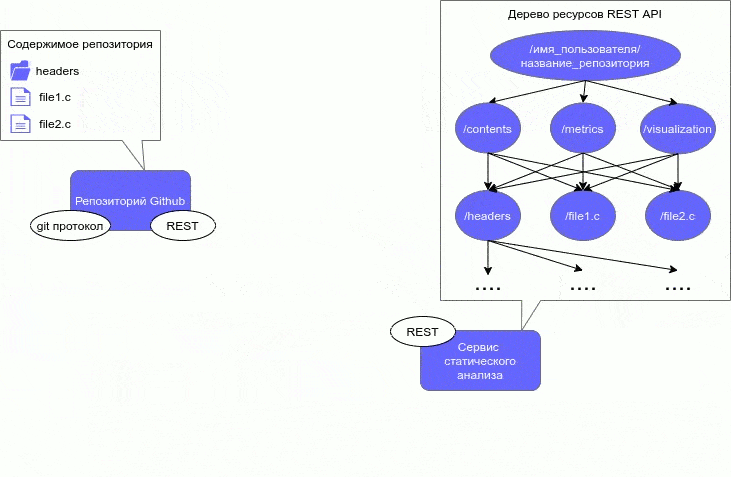 Рисунок 2 — Пример обработки веб-хука push (анимация: 6 кадров, 65.3 килобайт) ВыводВ рамках данной работы рассмотрен подход к статическому анализу программного проекта, который упрощает интеграцию с веб-сервисами хостинга проекта и другими инструмента разработки ПО. Данный подход делает процесс анализа ПО более гибким, упрощает его взаимодействие c непрерывной интеграцией (CI) и непрерывной разверткой (CD). В дальнейшем планируется расширить поддержку веб-сервисом статического анализа не только для императивных языков программирования, но и для языков других парадиг |