Пр ремонт 4и46. Документ (17). Тема 9 введение в биомедицинскую статистику
 Скачать 0.66 Mb. Скачать 0.66 Mb.
|

ТЕМА 9 ВВЕДЕНИЕ В БИОМЕДИЦИНСКУЮ СТАТИСТИКУВ медицине проведение клинических исследований напрямую связано с всесторонним анализом полученных данных. Поэтому изучение прикладной статистики является неотъемлемой частью обучения персонала, принимающего участие не только в статистическом анализе результатов, но и в процессе сбора клинических данных. Этические и экономические соображения диктуют необходимость внимательного отношения к планированию клинических исследований. Кроме того, владение методиками обработки информации позволяет персоналу более эффективно организовать процедуру сбора исходных данных. В здравоохранении и клинической медицине часто используются, сознательно или неосознанно, различные статистические концепции при принятии решений по таким вопросам, как клинический диагноз, прогнозирование возможных результатов осуществления тех или иных программ в данной группе населения, прогнозирование течения заболевания у отдельного больного, выбор лечения для конкретного больного, и т.п. Статистика находит повседневное применение в лабораторной практике. Знание статистики стало важным для понимания и критической оценки сообщений в медицинских журналах. Таким образом, знание принципов статистики абсолютно необходимо для планирования, проведения и анализа исследований, посвященных оценке различных ситуаций и тенденций в здравоохранении, а также для выполнения научных исследований в области медицинской биологии, клиники и здравоохранения. Применение статистики в здравоохранении необходимо как на уровне сообщества, так и на уровне отдельных пациентов. Медицина имеет дело с индивидуумами, которые отличаются друг от друга по множеству характеристик, таких, как масса тела, возраст, рост, артериальное давление, уровень холестерина, иммуноглобулинов и т.д. Значения показателей, на основании которых человека можно считать здоровым, варьируются от одного индивидуума к другому. Нет двух совершенно одинаковых пациентов или двух групп индивидуумов, однако решения, касающиеся отдельных больных или групп населения, приходится принимать, исходя из опыта, накопленного в отношении других больных или популяционных групп со сходными биологическими и социальными характеристиками. Ввиду существующих различий эти решения не могут быть абсолютно точными – они всегда сопряжены с некоторой неопределенностью. В этом и заключается вероятностная природа медицины. Вариация признака (или фактора, или результатов измерения) возникает, если их значения меняются от индивидуума к индивидууму или для одного индивидуума во времени. Едва ли не всем характеристикам организма человека, будь то физиологические, биохимические или иммунологические, свойственна вариабельность. Кроме того, возникает проблема обработки результатов очень большого числа измерений. Например, если бы можно было изучить всех больных туберкулезом в мире, то такая группа больных составила бы генеральную совокупность. Генеральная совокупность состоит из всех единиц наблюдения, которые могут быть к ней отнесены в соответствии с целью исследования. Естественно, практически это невозможно, поэтому при изучении здоровья населения генеральная совокупность рассматривается в пределах конкретных границ, очерченных территориальным или производственным признаком, и поэтому включает в себя определенное число наблюдений. Выборочная совокупность (выборка) – часть генеральной совокупности, по свойствам которой судят о генеральной совокупности. На основе анализа выборочной совокупности можно получить достаточно полное представление о закономерностях, присущих всей генеральной совокупности. Выборочная совокупность должна быть репрезентативной, т.е. в отобранной части должны быть представлены все элементы в том соотношении, как и в генеральной совокупности. Выборочная совокупность должна отражать свойства генеральной совокупности, т.е. правильно ее представлять. Сложности возникают при попытках обобщить характеристики в группе больных или популяционной группе; решить, какое значение той или иной характеристики будет идеальным, нормальным, средним и т.п.; сопоставить две группы больных или две популяционных группы по конкретной характеристике. Поскольку обычно имеется совокупность наблюдений (десятки, сотни, а иногда – тысячи результатов измерений индивидуальных характеристик), то возникает задача компактного описания имеющихся данных. Для этого используют методы описательной статистики– описания результатов с помощью различных показателей и графиков. Все изучаемые показатели варьируются, но не все они поддаются непосредственному измерению. Так возникает деление на количественные и качественные показатели. Классификация типов данных (рис. 5.1) приведена согласно [7]. В зависимости от типа данных используются те или иные описательные статистики. Для результатов измерений в шкале отношений показатели описательной статистики можно разбить на несколько групп: показатели (меры) положения описывают положение экспериментальных данных на числовой оси. Примеры таких данных – максимальный и минимальный элементы выборки, среднее значение, медиана, мода и др.; - показатели (меры) рассеяния описывают степень разброса данных относительно своего центра (среднего значения). К ним относятся: выборочная дисперсия, разность между минимальным и максимальным элементами (размах, интервал выборки) и др. показатели асимметрии: положение медианы относительно среднего и др. - графическое представление распределения данных, например, в виде гистограммы, эмпирической функции распределения и др. Данные показатели используются для наглядного представления и первичного («визуального») анализа результатов измерений характеристик экспериментальной и контрольной группы. 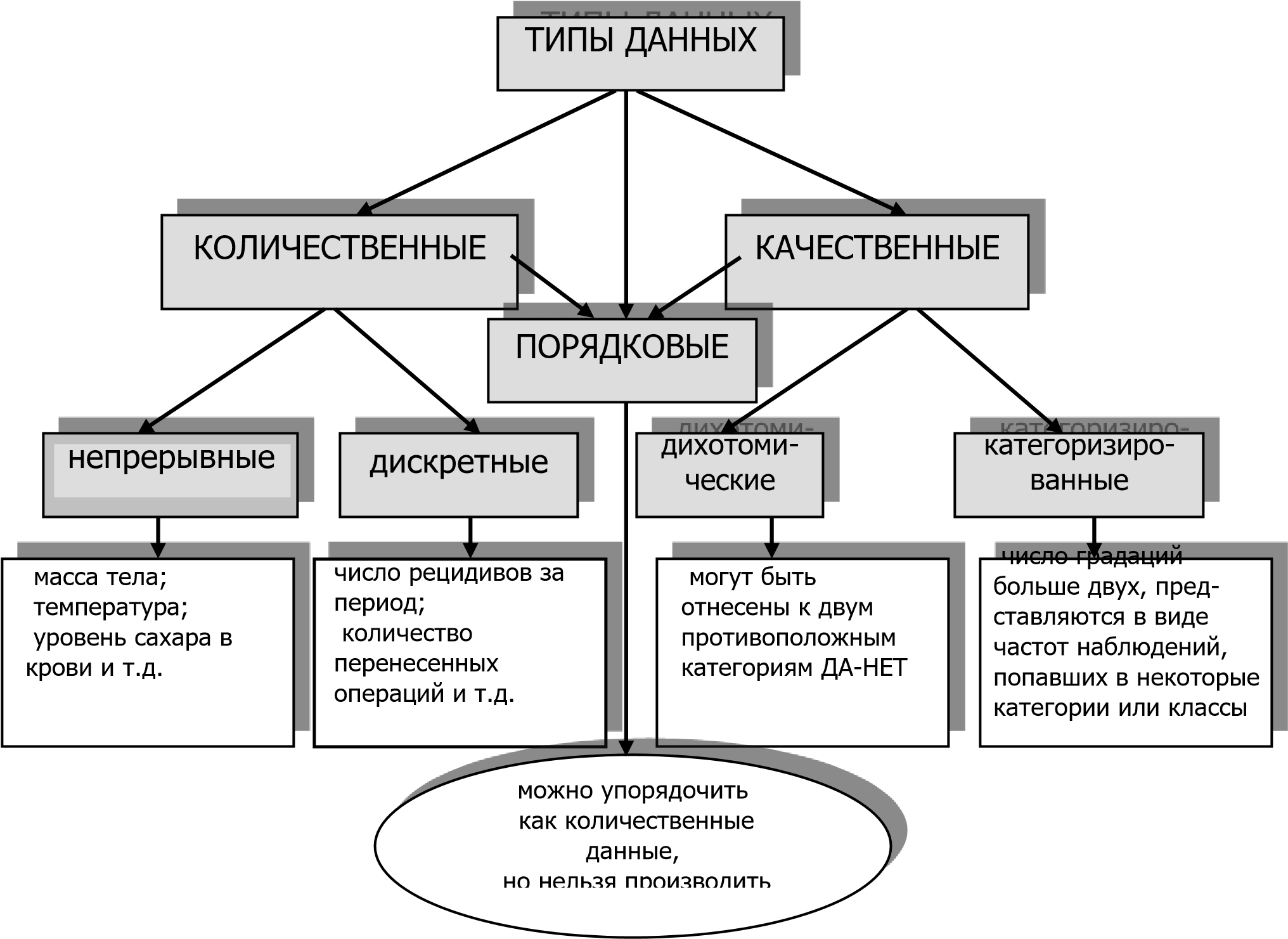 Рис. 5.1. Типы медико-биологических данных, используемых в статистическом анализе. Меры положения – это общее понятие для числового выражения локализации данных (на числовой оси) как типичного результата измерения. Самыми распространенными из них являются среднее и медиана. Среднее арифметическое, которое очень часто называют просто «среднее», получают путем сложения всех значений и деления этой суммы на число значений в наборе. Это можно показать с помощью алгебраической формулы. Набор n наблюдений переменной x можно изобразить как {𝑥1; 𝑥2; ...; 𝑥𝑛}. В таком случае формула для определения среднего арифметического наблюдений 𝜇 имеет вид (5.1): 𝑥1+𝑥2+...+𝑥𝑛 ∑𝑛𝑖=1 𝑥𝑖 𝜇 = = (5.1). 𝑛 𝑛 Например, измерив артериальное давление у десяти пациентов с целью исследовать систолическое давление, т.е. только одно число, получим: серия наблюдений (статистическая совокупность) артериального систолического давления в 11-ти наблюдениях имеет следующий вид: Таблица 5.1
Среднее арифметическое значение в данном ряду будет равно получить характеристику, которая одним числом описывает ряд значений. Средняя арифметическая величина обладает тремя свойствами: Средняя занимает серединное положение в проранжированном (выстроенном по возрастанию или убыванию) ряду. В строго симметричном ряду среднее совпадает с модой и медианой. Средняя является обобщающей величиной и за средней не видны случайные колебания, различия в индивидуальных данных. Она отражает то типичное, что характерно для всей совокупности. Сумма отклонений всех вариант от средней равна нулю: Медиана.Если упорядочить данные по величине, начиная с самой маленькой величины и заканчивая самой большой, то медиана также будет характеристикой усреднения в упорядоченном наборе данных. Медиана делит ряд упорядоченных значений пополам с равным числом этих значений как выше, так и ниже ее (левее и правее медианы на числовой оси). Вычислить медиану легко, если число наблюдений n нечетное. Это будет наблюдение номер 𝑛  +1. Если n четное, то, строго говоря, медианы нет. +1. Если n четное, то, строго говоря, медианы нет. 2 Однако обычно можно вычислять ее как среднее арифметическое двух соседних средних наблюдений в упорядоченном наборе данных (т. е. наблюдений номер 𝑛 и 𝑛 + 1). 2 2 В рассмотренном выше примере медиана равна 120. Мода– это значение, которое встречается наиболее часто в наборе данных; если данные непрерывные, то их обычно группируют и вычисляют модальную группу. Некоторые наборы данных не имеют моды, потому что каждое значение встречается только 1 раз. Иногда бывает более одной моды; это происходит тогда, когда 2 значения или больше встречаются одинаковое число раз и встречаемость каждого из этих значений больше, чем любого другого значения. В этом случае мода совпадает с минимальным модальным значением. Для данных из таблицы 1 мода, очевидно, равна 120. Заметим важную особенность моды и медианы: на их величины не оказывают влияние числовые значения крайних вариант. Меры рассеяния – это статистические показатели, характеризующие степень вариации, разброса значений признака относительно среднего значения (для признаков, имеющих количественный характер) и равномерного распределения (для признаков качественного типа). В зависимости от типа признаков существуют различные меры рассеяния. Размах (интервал изменения) – это разность между максимальным и минимальным значениями переменной в наборе данных. Расположим данные, полученные в таблице 5.1, упорядоченно: Таблица 5.2
размах = 115 − 125 = 10. Размах, полученный из процентилей. Предположим, что данные расположены упорядоченно от самой маленькой величины и до самой большой величины. Величина X, до которой расположен 1% наблюдений (и выше которой расположены 99% наблюдений), называется первым процентилем. Величина X, до которой находится 2% наблюдений, называется 2-м процентилем, и т.д. Величины X, которые делят упорядоченный набор значений на 10 равных групп, т. е. 10-й, 20-й, 30-й,..., 90 и процентили, называются децилями. Величины X, которые делят упорядоченный набор значений на 4 равные группы, т.е. 25-й, 50-й и 75-й процентили, называются квартилями. 50-й процентиль – это медиана. Ряд из таблицы 5.2 можно охарактеризовать так: I квартиль (25 процентиль)=115, II квартиль (50 процентиль, медиана) = 120, III квартиль (75 процентиль)=120 (Рис. 5.2).  Рис. 5.2. Квартили и медиана в ряду измерений. Дисперсия.Величина одного и того же признака неодинакова у всех членов совокупности. Например, в группе студентов рост каждого учащегося отличается от роста сверстников. В этом проявляется разнообразие изучаемого параметра. Один из способов измерения рассеяния данных заключается в том, чтобы определить степень отклонения каждого наблюдения от средней арифметической. Очевидно, что чем больше отклонение, тем больше изменчивость, вариабельность наблюдений. Однако невозможно использовать среднее этих отклонений как меру рассеяния, потому что положительные отклонения компенсируют отрицательные отклонения (их сумма равна нулю). Чтобы решить эту проблему, можно возвести в квадрат каждое отклонение и найти среднее возведенных в квадрат отклонений; эта величина называется дисперсией. Если имеется n наблюдений {𝑥1; 𝑥2; ...; 𝑥𝑛}, 𝜇среднее арифметическое, то дисперсия рассчитывается по формуле (5.2):  𝜎2 = ∑𝑛𝑖=1(𝑥𝑖−𝜇)2 (5.2) 𝑛−1 Единицы измерения (размерность) дисперсии – это квадрат единиц измерения первоначальных наблюдений. Например, если измерения производятся в килограммах, то единица измерения дисперсии будет «килограмм в квадрате». Стандартное отклонение.Стандартное (среднеквадратичное) отклонение (𝜎) – это положительный квадратный корень из дисперсии. Оно вычисляется в тех же единицах (размерностях), что и исходные данные и характеризует степень рассеивания вариационного ряда вокруг средней. Чем меньше , тем более типична, точна средняя. На практике часто приходится сравнивать изменчивость признаков, выраженных разными единицами, например, рост в см и масса в кг. Если разделить стандартное отклонение на среднее арифметическое и выразить результат в процентах, получится коэффициент вариации. Он является мерой рассеяния, не зависящей от единиц измерения (безразмерной) (5.3). 𝜎 𝐶𝑣 = 𝜇  × 100% (5.3). × 100% (5.3). При 𝐶𝑉 < 10% наблюдается слабое разнообразие признака, при 10% Стандартная ошибка среднего. Случайные ошибки выборок возникают за счет того, что для анализа всей совокупности используется только ее часть. Хотя выборочный метод и позволяет обоснованно судить о средней арифметической некоторого количественного признака генеральной совокупности по средней арифметической, исчисленной по выборке, это, однако, не означает, что выборочная средняя совпадает с генеральной средней. Она, как правило, в той или иной степени от нее отличается. Величина ошибки выборки представляет собой разность между генеральной и выборочной средними. Ошибки выборки различны для каждой конкретной выборки и в принципе могут быть обобщенно охарактеризованы с помощью средней из всех таких отдельных ошибок. В математической статистике получены формулы, которые позволяют приближенно вычислить среднюю ошибку выборки, основываясь на данных только той выборки, которая имеется в распоряжении исследователя. Стандартная ошибка среднего отражает точность оценки среднего значения признака в популяции по его выборке. Небольшая стандартная ошибка (существенно меньше соответствующего среднего значения) означает достаточно точную оценку. Стандартная ошибка уменьшится, т. е. оценка станет более точной, если объем выборки увеличится или данные имеют небольшое рассеяние (дисперсию). При неограниченном увеличении объема выборки стандартная ошибка среднего обращается в 0. Следовательно, эта величина не имеет никакого биологического смысла. Cтандартная ошибка среднего арифметического может быть найдена по формуле (5.4): 𝜎 𝜎 𝑛 где 𝜎 – среднее квадратическое отклонение, 𝑛 – количество параметров в выборочной совокупности. Доверительный интервал. Выборка из популяции позволяет получить точечную оценку интересующего нас параметра и вычислить стандартную ошибку для того, чтобы указать точность оценки. Следует отметить, что для большинства исследований стандартная ошибка как таковая неприемлема, поскольку она, в отличие от стандартного отклонения, не отражает вариабельности в значениях данных. Гораздо полезнее объединить эту меру точности с интервальной оценкой для параметра популяции. Для этого нужно вычислить доверительный интервал (ДИ), который дает вероятное значение верхней и нижней границ оцениваемой неизвестной величины, что позволяет заявить: «Я утверждаю, что точное значение неизвестной величины с определённой вероятностью (чаще всего эта вероятность составляет 0,95) находится между этими двумя числами». Обычно доверительные интервалы показывают, насколько надежной в действительности является статистическая оценка. Например, утверждение, что в результате проведения лечебных мероприятий у группы больных (табл. 5.1) среднее значение АД = 119,5 мм рт.ст. содержит некоторую определенную информацию. Однако утверждение, что врач на 95% уверен в том, что истинное (среднее популяционное) АД будет находиться в пределах от 115 до 125 мм рт.ст., позволяет сделать гораздо более глубокие выводы об эффективности лечения (рис.5.3). Доверительный интервал визуально удобно представлять в виде ящика с усами. Ящик с усами (англ. box-and-whiskers plot, box plot) – график, компактно изображающий одномерное распределение вероятностей. Несколько таких ящиков можно нарисовать бок о бок, чтобы визуально сравнивать одно распределение с другим. В случае нормального распределения «ящик» рисуется на промежутке (𝜇 − tm; 𝜇 + tm), где t – коэффициент Стьюдента – величина, зависящая от объема выборки (или соответствующего числа степеней свободы) и выбранного уровня доверительной вероятности, определяется по таблицам распределения Стьюдента; а m – стандартная ошибка среднего. Внутри «ящика» проводится риска – среднее арифметическое 𝜇 (рис. 5.3). 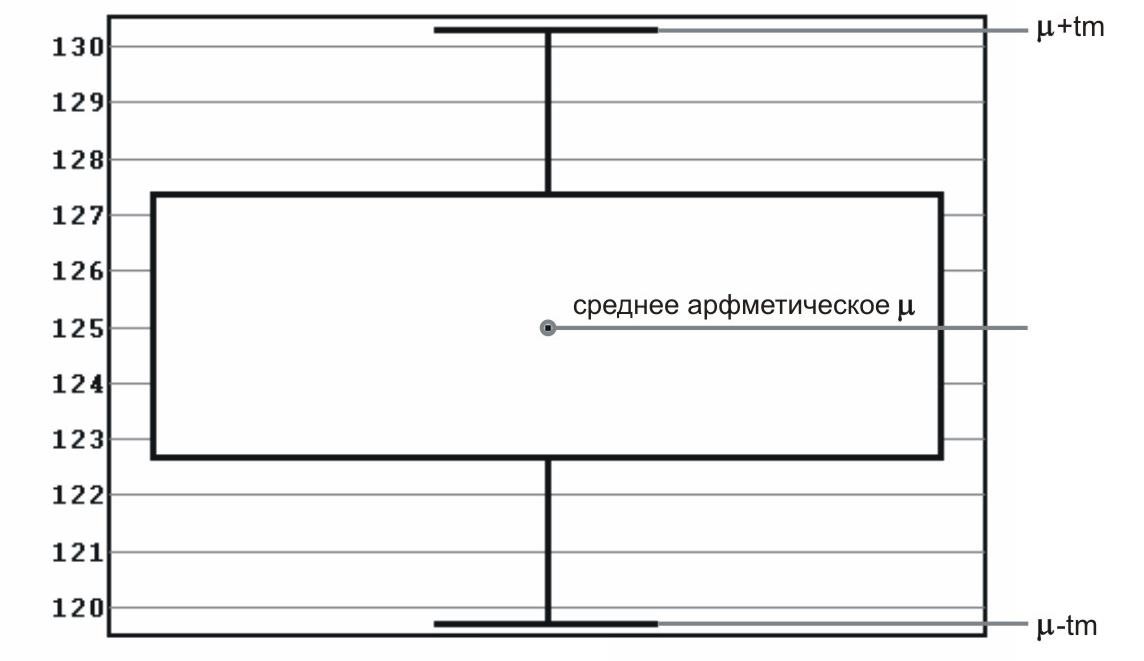 Рис. 5.3. Доверительный интервал для среднего в случае нормального распределения. В случае распределения, отличного от нормального, вычисляют медиану x50, квартили (x25, x75) и статистически значимый диапазон — 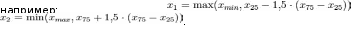 ; «Ящик» рисуется от квартиля до квартиля, внутри него проводится риска – медиана. «Усы» тянутся от квартилей до статистически значимых крайних точек x1 и x2. Не входящие в статистически значимый диапазон точки (выбросы) изображаются отдельно (рис. 5.4). ; «Ящик» рисуется от квартиля до квартиля, внутри него проводится риска – медиана. «Усы» тянутся от квартилей до статистически значимых крайних точек x1 и x2. Не входящие в статистически значимый диапазон точки (выбросы) изображаются отдельно (рис. 5.4). 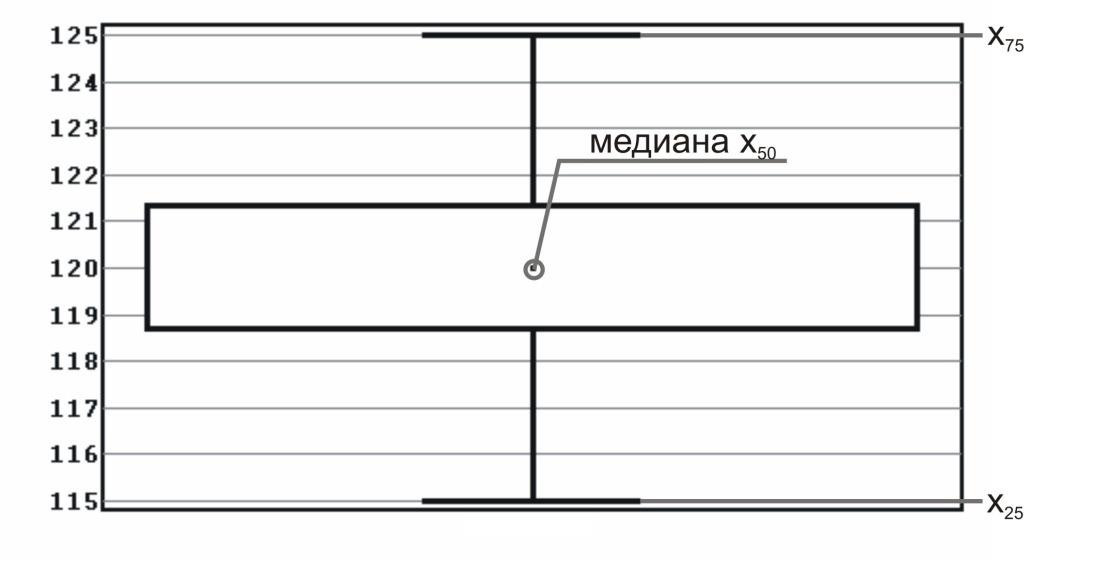 Рис. 5.4. Доверительный интервал для среднего (медианы) в случае распределения, отличного от нормального. Доверительные интервалы представляют оценку в некоторой перспективе и позволяют избежать необходимости указывать одно и то же число как точное значение, в то время как фактически в биологии это число точным никогда и не является. При интерпретации ДИ исследователь формулирует следующие вопросы: Насколько широк ДИ? Широкий ДИ указывает на менее точную оценку, узкий - на более точную оценку. Какой клинический (биологический) смысл можно извлечь из рассмотрения ДИ? Верхние и нижние пределы показывают, будут ли результаты клинически (биологически) значимы. Включает ли ДИ какие-либо значения, представляющие особый интерес? Можно проверить, попадает ли вероятное значение для параметра популяции в пределы ДИ. Если да, то результаты согласуются с этим вероятным значением. Если нет, то маловероятно (для 95% ДИ шанс меньше 5%), что параметр имеет это значение. Понятие вероятности. Вероятность того или иного события при числе наблюдений N оценивается по простой формуле. Если число наблюдаемых конкретных событий при числе наблюдений N равно n , то вероятность равна отношению числа наблюдений, в которых было обнаружено событие к общему числу наблюдений (5.5): 𝑛 𝑃(𝐴) = (5.5) 𝑁 Пример: Пусть мы изучили 2000 историй болезни больных туберкулезом. В этом случае число наблюдений N=2000. Среди просмотренных историй болезни у 100 пациентов было обнаружено снижение количества тромбоцитов (тромбоцитопения) (n=100). В этом случае вероятность тромбоцитопении равна: p=n/ N =100/2000 =1/20 = 0,05. Вероятность можно оценить в непрерывной шкале от 0 до 1 включительно. Событие, которое невозможно, имеет вероятность 0, а событие, которое произойдет обязательно, имеет вероятность 1. Вероятность дополнительного события (события не происходящего) равна единице минус вероятность события. Математическое ожидание.Пусть определена совокупность измерений систолического давления у некоторой группы обследуемых (табл. 5.2). Что можно сказать о величине АД в следующем, двенадцатом наблюдении, которое мы не проводили? В полной мере оценить эту величину мы не можем, а лишь дать вероятностную оценку, т.е. предсказать значение с той или иной долей вероятности. Любое измеренное нами значение АД является случайной величиной. Если имеется какая-либо зависимость, описывающая эту случайную величину, то принято говорить, что случайная величина характеризуется функцией вероятности. В этом случае, основываясь на полученных результатах, можно прогнозировать ту величину, которая будет получена в следующих измерениях. Такая прогнозируемая величина называется математическим ожиданием. Попытаемся определить величину математического ожидания для нашего случая. Для этого вначале сгруппируем одинаковые результаты и оценим вероятность (в долях единицы) их появления в нашем наблюдении (табл. 5.3): Таблица 5.3
Так как общее число наблюдений составило 11, то каждое появление того или иного результата представляет собой вероятность, равную 1/11. Очевидно, что любой эмпирический опыт дает возможность с той или иной степенью правильности предсказывать или прогнозировать будущее. В теории статистики бытовое понимание феномена предсказания приобретает более очерченное звучание в форме понятия математического ожидания. M f (x) Математическое ожидание ( ) вычисляется по следующей формуле (5.6): M f (x) = X1 p1 + X 2 p2 ++ X n pn (5.6) . Математическое ожидание - это сумма попарных произведений X i на вероятность ее появления pi в данном наблюдаемой величины наблюдении. В рассмотренном нами случае вариационного ряда систолического давления математическое ожидание исследуемой величины составляет: 𝑀𝑓(𝑥) = 115 ⋅ 3⁄11 + 120 ⋅ 6⁄11 + 125 ⋅ 2⁄11 ≈ 119,55. Таким образом, наиболее вероятной будет величина, составляющая 119,55 мм рт. ст. Распределение вероятности. Случайная переменная – это величина, которая может принимать любое из набора взаимоисключающих значений с определенной вероятностью. Распределение вероятности показывает вероятности всех возможных значений случайной переменной. Это теоретическое распределение, которое выражено математически и имеет среднее и дисперсию – аналоги среднего и дисперсии в эмпирическом распределении. Каждое распределение вероятности определяется некоторыми параметрами. Параметры служат обобщающими величинами (например: среднее, дисперсия), характеризующими данное распределение (т.e. их знание позволит подробно описать распределение) С помощью соответствующей статистики можно произвести оценку этих параметров в выборке. В зависимости от того, является ли случайная переменная дискретной или непрерывной, распределение вероятности может быть либо дискретным, либо непрерывным. Функция F(x), связывающая значения xi переменной случайной величины Х с их вероятностями pi называется законом распределения (или функцией распределения) этой случайной величины. Закон распределения описывает распределение вероятностей случайной переменной Х. С понятием закона распределения случайной величины неразрывно связано понятие плотности распределения, которую можно представить себе как предельную кривую р(х), аппроксимирующую выборочную гистограмму распределения данной случайной величины (рис. 5.5). 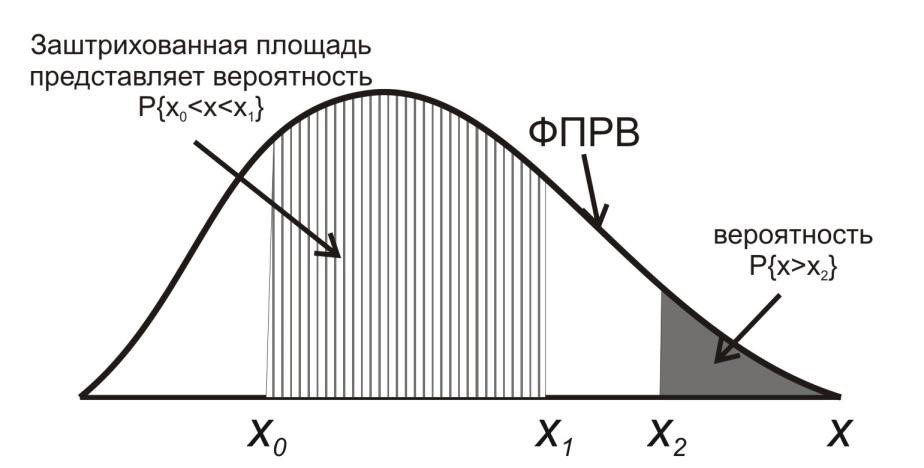 Рис. 5.5. Функция плотности распределения вероятности. Нормальное (гауссово) распределение. Одним из самых важных распределений в статистике является нормальное распределение. Непрерывная случайная величина Х называется распределенной по нормальному закону, если ее плотность распределения равна () 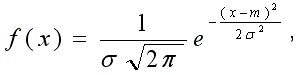 () () где m - математическое ожидание случайной величины; Его функция плотности распределения вероятности представлена на рис. 5.6. 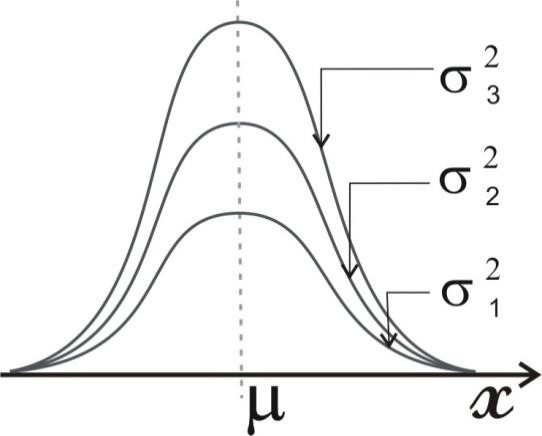 Рис. 5.6. Функция плотности нормального распределения вероятности. Функция плотности нормального распределения вероятности симметрична относительно среднего 𝜇. Результат изменения 𝜎2 (𝜎12 > 𝜎22 > 𝜎32). Свойства функции плотности нормального распределения вероятности: полностью определяется двумя параметрами – средним (𝜇) и дисперсией (𝜎2); колоколообразная (унимодальная) форма; симметричная относительно среднего; сдвигается вправо, если среднее увеличивается, и влево, если среднее уменьшается (при постоянной дисперсии); сплющивается, если дисперсия увеличивается, но становится более остроконечной, если дисперсия уменьшается (для постоянного среднего). среднее и медиана нормального распределения равны. Нормальное распределение не является единственным известным распределением. Ниже мы приводим краткие сведения о некоторых других законах распределения дискретных и непрерывных случайных величин. t-распределение(рис. 5.7) получено Вильямом Госсетом, который публиковал свои работы под псевдонимом «Student» («Студент»), поэтому его часто называют tраспределением Стьюдента; t-распределение характеризуется степенями свободы (df); форма кривой подобна форме кривой стандартизованного нормального распределения, но более приплюснута и с более длинными «хвостами». Форма приближается к нормальной кривой по мере увеличения степеней свободы; t-распределение применяют для вычисления доверительных интервалов и исследования гипотез с одной или двумя средними. 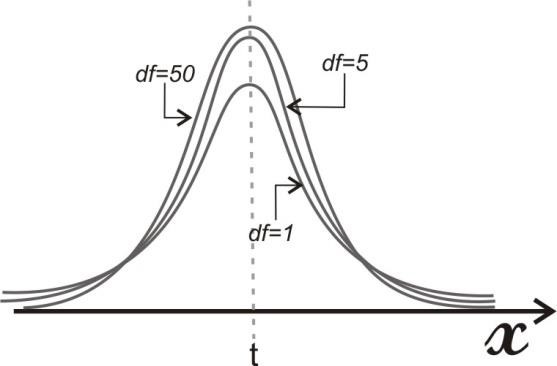 Рис. 5.7. t-распределение со степенями свободы df=1, df=5, df=50. Хи-квадрат (𝜒2) распределение Пирсона (рис. 5.8) скошено вправо, принимает только положительные значения; характеризуется степенями свободы; форма кривой зависит от числа степеней свободы. Кривая становится более симметричной и приближается к нормальной с увеличением числа степеней свободы; особенно часто используется для анализа категориальных данных. 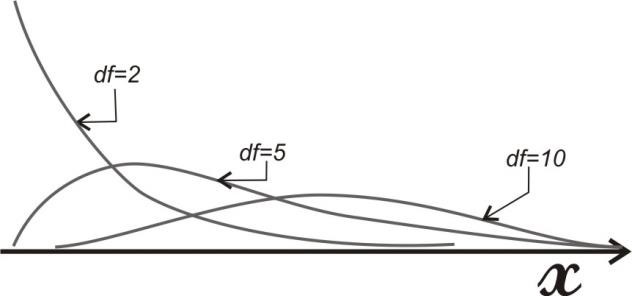 Рис. 5.8. Хи-квадрат распределение Пирсона со степенями свободы df=2, df=5, df=10 F-распределение (рис. 5.9) кривая скошена вправо; определяется как отношение. Распределение отношения двух оценок дисперсий, вычисленных для нормально распределенных данных, аппроксимируется F-распределением; характеризуется степенями свободы числителя d1 и знаменателя d2 отношения; особенно полезно для сравнения двух дисперсий и более чем двух средних при использовании дисперсионного анализа. 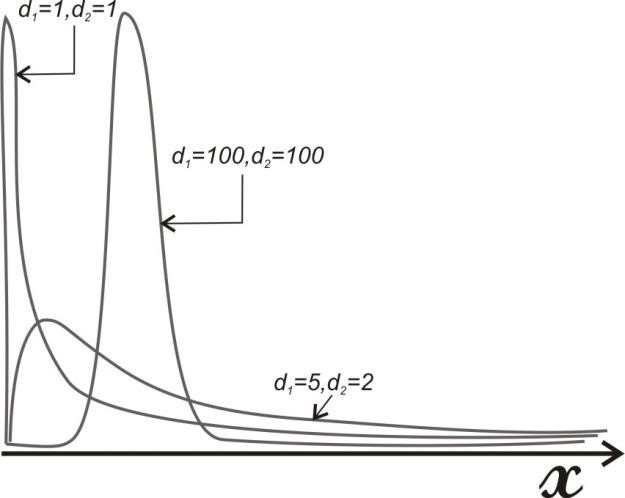 Рис. 5.9. F- распределение с разными степенями свободы числителя и знаменателя. Логнормальное распределение(рис. 5.10) распределение вероятности случайной переменной, логарифм которого (по основанию 10 или е) имеет нормальное распределение; сильно скошено вправо; если набор данных имеет логнормальное распределение, то используют среднее геометрическое как обобщающий показатель. 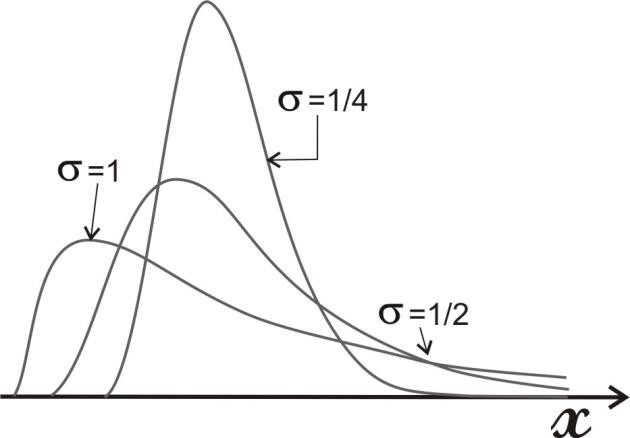 Рис. 5.10. Логнормальное распределение с разными показателями стандартного отклонения. Многие переменные в медицине имеют логнормальное распределение. Поэтому можно использовать свойства нормального распределения для того, чтобы сделать выводы относительно этих переменных после логарифмического преобразования данных. Биномиальное распределение (рис. 5.11) Предположим, что существуют только два результата – «успех» и «неудача». Например, нас интересует, забеременеет ли женщина в результате экстракорпорального оплодотворения. Если мы примем п = 100 не имеющих отношения друг к другу женщин, перенесших процедуру экстракорпорального оплодотворения (каждая с одинаковой вероятностью забеременеть), то биномиальная случайная переменная – это наблюдаемое число зачатий. Часто это понятие представляют как п независимых повторных испытаний, при которых результатом будет либо успех, либо неудача. Биномиальное распределение описывают: п - число индивидуумов в выборке (или число повторений испытания), и 𝜋 - точная вероятность успеха для каждого индивидуума (или при каждом испытании). Свойства биномиального распределения можно использовать, чтобы сделать выводы относительно пропорций. Особенно часто используется аппроксимация биномиального распределения нормальным при анализе пропорций. 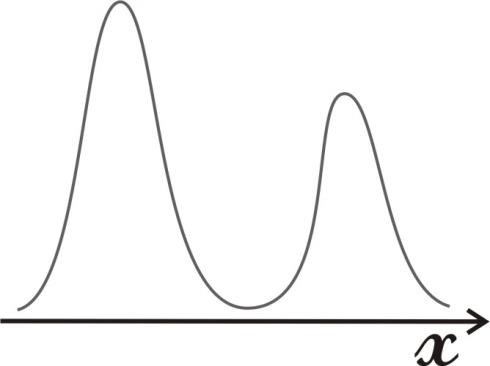 Рис. 5.11. Функция биномиального распределения величины х. Распределение Пуассона (рис. 5.12) Пуассоновская случайная переменная – это число событий, которые происходят независимо и случайно во времени или пространстве со средней интенсивностью 𝜇. Например, число госпитализаций в день типично отвечает распределению Пуассона. Распределение Пуассона может быть использовано в данном случае, чтобы вычислить вероятность конкретного числа госпитализаций в любой отдельный день. Параметр, которым описывают распределение Пуассона, – это среднее, т.е. средняя интенсивность 𝜇. В распределении Пуассона среднее арифметическое равняется дисперсии. Если среднее мало, распределение скошено вправо. По мере того, как среднее увеличивается, оно становится более симметричным, приближаясь к нормальному распределению. 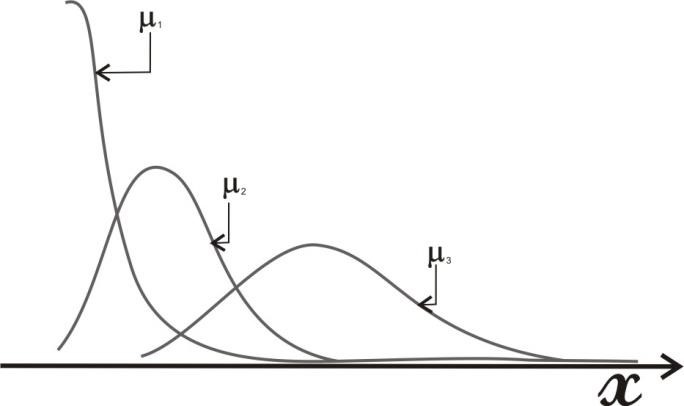 Рис. 5.12. Функция пуассоновского распределения (𝜇1 < 𝜇2 < 𝜇3). Большинство критериев и статистических тестов относятся к так называемым параметрическим критериям. Это значит, что они могут применяться только к нормально распределенным рядам данных. Во всех остальных случаях используются так называемые непараметрические критерии. В случае, кода распределение ряда параметров является отличным от нормального или о природе распределения ничего не известно, необходимо обращаться именно к таким методам. Говоря более специальным языком, непараметрические методы не основываются на оценке параметров (таких как среднее или стандартное отклонение) при описании выборочного распределения интересующей величины. Поэтому эти методы иногда также называются свободными от параметров или свободно распределенными. Если данные не являются нормально распределенными, а измерения, в лучшем случае, содержат ранжированную информацию, то вычисление обычных описательных статистик (например, среднего, стандартного отклонения) не слишком информативно. Например, в психометрии хорошо известно, что воспринимаемая интенсивность стимулов (например, воспринимаемая яркость света) представляет собой логарифмическую функцию реальной интенсивности (яркости, измеренной в объективных единицах - люксах). В данном примере, обычная оценка среднего (сумма значений, деленная на число стимулов) не дает верного представления о среднем значении действительной интенсивности стимула. Непараметрическая статистика вычисляет разнообразный набор мер положения (среднее, медиану, моду и т.д.) и рассеяния (дисперсию, гармоническое среднее, межквартильный размах и т.д.), позволяющий представить более "полную картину" данных. Альтернативное распределение признака. Если из всей массы наблюдений использовать для статистического анализа только наблюдения за исходами, например, получен эффект от проводимой терапии – да или нет; выявлены побочные эффекты – да или нет; отмечено появление определенных симптомов – да или нет и т.д., то необходим способ учета реакций в альтернативной форме (реакция, которая или наступает, или – нет). Альтернативное распределение – это распределение элементов совокупности на 2 части (2 альтернативы) по какому-либо признаку, чаще по качественному. Единственный способ описания качественных признаков состоит в том, чтобы подсчитать число объектов, имеющих одно и то же значение, или долю от общего числа объектов, которая приходится на то или иное значение. В отношении доли вариант в альтернативном распределении возникают те же статистические задачи, что и для параметров, представленных в количественной форме: оценка доли р в генеральной совокупности по выборочным данным, нахождение доверительного интервала для р; выявления различия между генеральными долями р1 и р2 двух совокупностей по выборочным данным, т.е. сравнение двух выборочных долей вариант. Таким образом, статистический анализ медико-биологических данных должен начинаться с их первичной обработки, т.е. представления исходных данных в подходящей для анализа форме, и проведения проверки качества данных. Порядок первичной обработки данных (предварительный анализ данных) представлен на рис 5.13. 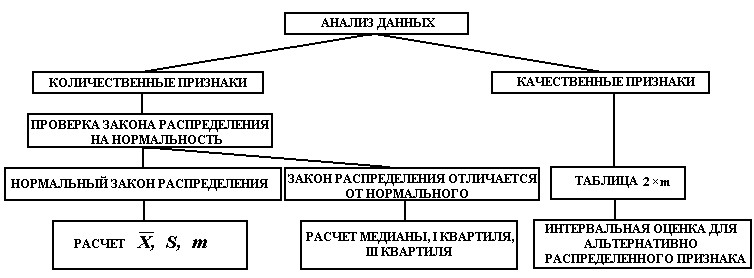 Рис 5.13. Первичная обработка (предварительный анализ)данных. Контрольные вопросыДля чего может применяться математическая статистика в медицине? Перечислите основные описательные статистики, используемые в предварительном анализе данных. Что такое меры положения? Что такое меры рассеяния? Что такое среднее арифметическое? Какими свойствами оно обладает? Что такое мода? Укажите моду в ряду {36,6; 36,6; 37,1; 37,1; 37,2; 38}. Что такое процентили, квартили и медиана? Для чего используется доверительный интервал? Что такое дисперсия? Что такое среднее квадратическое отклонение? Что такое коэффициент вариации? Что отражает стандартная ошибка среднего? Что такое вероятность? По какой формуле она вычисляется? Что такое математическое ожидание? Что такое закон распределения случайной величины? Какие виды распределений вам известны? В чем разница между параметрическими и непараметрическими критериями? Список литературыЛях Ю.Е., Гурьянов В.Г., Хоменко В.Н., Панченко О.А. Основы компьютерной биостатистики: анализ информации в биологии, медицине и фармации статистическим пакетом Medstat. – Донецк:, 2006. – 214 с. Островок здоровья. – Режим доступа: www.bono-esse.ru Петри А., Сэбин К. Наглядная статистика в медицине. – М.: ГЭОТАРМЕД, 2003. – 139 с. Платонов А.Е. Статистический анализ в медицине и биологии: задача, терминология, логика, компьютерные методы. – М.: Издательство РАМН, 2000. – 52 с. Реброва О.Ю. Статистический анализ медицинских данных. Применение пакета прикладных программ STATISTICA. – М.: МедиаСфера, 2002. – 312 с. |