Базовые информационные технологии. Тема Информатизация общества Вопрос Цели и задачи информатизации общества
 Скачать 4.13 Mb. Скачать 4.13 Mb.
|

|
Тема 6. Документальные информационные системы Вопрос 1. Основные понятия. Текст является универсальным средством представления, накопления и передачи знаний в человеческом обществе. Поэтому технологии работы с естественно-языковыми текстами (а также с текстами на ограниченном естественном языке) всегда считались важнейшими для информационных технологий. Документальные ИС служат для работы с документами на естественном языке. Наиболее распространенный тип документальных информационных систем – это информационно-поисковые системы, предназначенные для накопления документов и подбора документов, удовлетворяющих заданным критериям. Основным элементом данных в документальных информационных системах является неструктурированный на более мелкие элементы документ. В ранних системах документ рассматривался как атомарная (неделимая) единица. Для системы он выступал как «черный ящик». В более развитых системах содержание документа доступно для обработки и анализа. Таким образом, можно дать следующее определение документа: Документ – это порция информации, обладающая законченным содержанием и какого-либо рода уникальным идентификатором. Основной задачей документальных информационных систем является накопление и предоставление пользователю документов, содержание, тематика, реквизиты которых адекватны его информационным потребностям. Поэтому можно дать следующее определение документальной ИС: документальная ИС – это единое хранилище документов с инструментарием поиска и отбора необходимых документов. Системы текстового поиска оперируют электронными документами, т.е. документами, хранимыми в памяти компьютеров и доступными для автоматизированной обработки. Компьютерная обработка и анализ текстовых документов возможны лишь в случае, если программно доступны отдельные элементы текстового документа. Поэтому совершенно недостаточно просканировать бумажный текстовый документ и хранить полученное его факсимиле в памяти компьютера в виде какого-либо графического файла. Необходимо иметь документ в оцифрованном виде, т.е. в таком формате, когда каждая буква (литера) представляющего его текста программно доступна. Первые информационно-поисковые системы (ИПС) были предназначены для поиска книг в библиотеках и получили название библиографические. Позже их стали применять для поиска документов в больших хранилищах и стали называть документальными. Основным объектом информационного фонда документальной информационно-поисковой системы является аннотация (реферат) и библиографическое описание документа. Аннотация (реферат) пишется на естественном языке и отражает основные характеристики документа. Из реферата выделяются ключевые слова и словосочетания, которые в последующем используются для поиска. Ключевые слова и словосочетания по-другому называются дескрипторами. Запрос к документальной ИПС формулируется в виде перечня дескрипторов, которые, по мнению пользователя, характеризуют искомый документ. Совокупность индексов, соответствующих полному набору дескрипторов реферата, составляет его поисковый образ. Таким образом, признаки документа, отражающие его содержание в информационно-поисковой системе (ИПС), называют поисковым образом документа (ПОД), а признаки запроса в ИПС – поисковым предписанием (ПП). Процедура перевода документа и запроса в форму представления, принятую в ИПС, называется индексированием. При проведении информационного поиска в системе рассматривается не фактическая информационная потребность пользователя, а только информационный запрос, в ответ на который выдаются те или иные документы системы. Для выражения этих отношений в теории документальных ИПС введены два фундаментальных понятия: пертинентность и релевантность. Под пертинентностью понимается соответствие смыслового содержания документа информационной потребности потребителя. Документы, содержание которых удовлетворяет информационной потребности, называются пертинентными. Релевантность представляет собой соответствие содержания документа информационному запросу в том виде, в каком он сформулирован, а документы, содержание которых отвечает запросу потребителя, носят название релевантных. При сопоставлении поискового образа и поискового предписания используется тот или иной критерий смыслового соответствия (релевантности). В состав типовой документальной ИПС входят четыре подсистемы: 1. Подсистема ввода и регистрации. 2. Подсистема обработки. 3. Подсистема хранения. 4. Подсистема поиска. Основные задачи подсистемы ввода и регистрации документов зависят от представления текстовых документов, поступающих на вход системы. Они могут быть представлены как в бумажном, так и в электронном виде. Поэтому эта подсистема решает такие задачи, как: · создание электронных копий бумажных документов (например, сканирование с последующим распознаванием текста или ввод с клавиатуры); · обеспечение подключения к каналам доставки электронных документов; · распознавание, а при необходимости и преобразование, формата электронных документов; · присвоение электронным документам уникальных идентификаторов (регистрация), а также ведение таблицы синхронизации имен (при необходимости сохранения прежних имен). Все поступающие документы без внесения в них каких-либо изменений направляются в подсистему хранения для сохранения в базе данных документов. База документов может представлять собой простую совокупность файлов, распределенную по каталогам жесткого диска. Однако такой тип представления базы документов характеризуется двумя недостатками: 1) неэффективностью использования дискового пространства; 2) низкой скоростью доступа при большом количестве файлов. Поэтому для хранения документов применяют средства сжатия и быстрого поиска информации. В этом случае подсистема хранения представляет собой совокупность стандартных или специализированных средств архивации, управления данными, обеспечивающих возможность доступа к данным по предъявляемому идентификатору. На следующем этапе документы поступают на вход подсистемы обработки. Задачей этой подсистемы является формирование для каждого документа поискового образа документа (ПОД), в который заносится информация, необходимая для последующего поиска документа. ПОД сохраняется в индексе. При поступлении на вход системы запроса индекс преобразуется в поисковое предписание и передается в подсистему поиска, задачей которой является отыскание в индексе ПОД, удовлетворяющих ПП с точки зрения критерия смыслового соответствия. Критерий смыслового соответствия (КСС) – это набор правил, по которым данная документальная ИПС определяет степень смысловой близости между поисковым образом документа (ПОД) и поисковым предписанием (ПП). Идентификаторы релевантных документов подаются с выхода подсистемы поиска на вход подсистемы хранения, которая осуществляет выдачу пользователю самих релевантных документов. Вопрос 2. Информационно-поисковый язык. Автоматизация процесса информационного поиска потребовала создания информационно-поисковых языков. Информационно-поисковый язык (ИПЯ) – это специально созданный искусственный язык, предназначенный для выражения содержания документов и запросов или описания фактов с целью их последующего поиска. ИПЯ создается на базе естественного языка, однако отличается от него компактностью, наличием четких грамматических правил и отсутствием семантической неоднозначности. Каждый информационно-поисковый язык состоит из: · лексики (словарного состава); · базисных (аналитических) отношений; · грамматики; · системы обозначений (алфавита); · системы ведения (изменения и дополнения); · правил образования и интерпретации. Алфавит ИПЯ – это система знаков, используемых для записи слов и выражений ИПЯ. Лексика, или словарный состав ИПЯ, – совокупность слов, словосочетаний и выражений, используемых для построения текстов ИПЯ. Грамматика ИПЯ – совокупность средств и способов построения, изменения и сочетания лексических единиц. Грамматика включает морфологию и синтаксис. Морфология – совокупность средств и способов построения и изменения слов. Синтаксис– совокупность средств и способов соединения слов в выражения и фразы. Естественный язык (ЕЯ) обладает высокой многозначностью. Это создает богатство его форм и содержания. В ИПЯ недопустима многозначность. Основными требованиями, предъявляемыми к ИПЯ: · однозначность: каждая запись на ИПЯ должна иметь только один смысл, одно толкование, а любое понятие, смысл должны получить единообразную запись средствами ИПЯ; · достаточная семантическая сила: способность отражать с необходимой полнотой и точностью смысловое содержание документов и запросов определенной предметной области; · открытость: обеспечение возможности корректировки языка. Поэтому необходимо учитывать отношения синонимии и омонимии слов ЕЯ, используемых в ИПЯ. Омонимия –это совпадение слов по написанию или звучанию и несовпадение по смыслу. Полисемия слова состоит в том, что одно и то же слово выражает пучок родственных понятий. Например, знак «соль» обозначает вещество, а также понятие смысла. Оба значения близки по смыслу. Синонимия – это совпадение слов по значению и несовпадение по написанию. Наиболее часто в качестве основания деления при классификации ИПЯ используют способ организации понятий. Поспособу организации понятий ИПЯ различают: · предкоординируемые (классификационные); · посткоординируемые (дескрипторные). Предкоординация– предварительное (до использования при индексировании) построение сложных классов путем логического умножения (координации) простых классов. Словарный состав задается в виде фиксированного списка слов, словосочетаний и фраз. При индексировании документов или запросов можно пользоваться только словами, словосочетаниями и фразами, содержащимися в фиксированном списке. Введение в язык новых лексических единиц строго ограничено и возможно лишь до индексирования документов, т.е. при создании языка. Словарный состав предкоординируемых языков напоминает двуязычный разговорник, в котором заранее зафиксированы наиболее употребительные фразы. При помощи предкоординируемого языка происходит отнесение документа к классу, обозначенному лексическими единицами этого языка, т.е. классификация документа. Посткоординируемые(дескрипторные языки) основаны на методе координатного индексирования. Координатное индексирование – индексирование, при котором основное смысловое содержание текста (документа) или информационного запроса представляется в виде сочетания ключевых слов или дескрипторов. В посткоординируемых ИПЯ лексические единицы объединяются в поисковом образе лишь во время индексирования документа. Словарь дескрипторного ИПЯ состоит из специальным образом выбранных отдельных слов или словосочетаний ЕЯ:ключевых слов и дескрипторов. Вопрос 3. Система индексирования. В зависимости от особенностей реализации хранилища документов и механизмов поиска документальные информационно-поисковые системы можно разделить на две группы: 1) системы на основе индексирования; 2) семантически-навигационные системы. В системах на основе индексированияисходные документы помещаются в базу без какого-либо дополнительного преобразования, но при этом смысловое содержание каждого документа – аннотация (реферат) – отображается в некоторое поисковое пространство. При вводе в ИПС нового объекта (реферата) его дескрипторы автоматически включаются в словарь дескрипторов. Каждому дескриптору присваивается номер, называемый индексом дескриптора. Совокупность индексов, соответствующих полному набору дескрипторов реферата, составляет его поисковый образ. Новый поисковый образ снабжается уникальным идентификатором и включается в массив поисковых образов. Тем же идентификатором помечается новый реферат, заносимый в массив рефератов. Поиск в дескрипторной ИПС организуется следующим образом. Пользователь выражает свои информационные потребности средствами и языком поискового пространства, формируя поисковый образ запроса(ПОЗ) к базе документов. Запрос подвергается анализу, в рамках которого выделяются дескрипторы, входящие в словарь дескрипторов. Их совокупность образует поисковое предписание, соответствующее запросу. Оно сопоставляется с поисковыми образами, в результате чего определяется их релевантность. Ответом на запрос является множество рефератов, соответствующих отобранным в процессе поиска идентификаторам. Схематично общий принцип устройства и функционирования документальных ИПС на основе индексирования представлен на рис. 9. 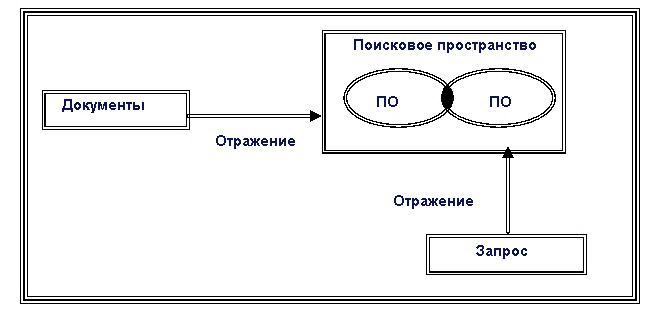 Рис. 9. Общий принцип функционирования документальных ИПС на основе индексирования В целях ускорения поиска для каждого дескриптора в словаре дескрипторов указывается список идентификаторов рефератов, в которых он встречается. Такая информационная структура ИПС называется индексом. Заметим, что с помощью дескрипторов можно лишь приблизительно отразить смысл документов. Таким образом, поисковая система может выдать документы, не относящие к данному поисковому запросу и не найти нужные. Развитием поиска по дескрипторам являются информационно-поисковые системы с полнотекстовым поиском. В системах, использующих данный вид поиска, индекс формируется на основе всех слов и словосочетаний, содержащихся в документах, за исключением служебных слов (союзов, предлогов и др.). При индексировании слова приводятся к базовой грамматической форме (именительный падеж единственного числа и др.). В семантически-навигационных системах документы, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую (смысловую) сеть в базе документов. Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС. Вопрос 4. Технология обработки запросов. При вводе документа в систему осуществляется его индексирование и строится его представление, которое будет далее представлять этот документ в процессе функционирования системы и обработки запросов. Когда поступает пользовательский запрос, для него также строится соответствующее представление. Наконец, собственно поиск заключается в том, что каким-либо эффективным образом (не прямым перебором, а обычно с помощью рациональным образом организованного индекса) сопоставляется представление запроса с представлениями хранимых в системе документов по принятому в ней критерию близости. В некоторых случаях для этих целей вводится специальная метрика. Результаты обработки запроса представляются в виде множества найденных релевантных документов. Хотя на практике используются различного рода представления документов и пользовательских запросов, указанные общие принципы поиска остаются неизменными. Тезаурусы –специальные словари, которые играют важную роль в анализе и формировании формализованного представления текстовых документов. Это словари основных понятий языка, обозначаемых отдельными словами или словосочетаниями, с определенными семантическими отношениями между ними. В настоящее время существует два способа создания тезаурусов: вручную и автоматически. Тезаурус, созданный вручную, может быть универсальным, независимым от конкретной коллекции документов. Он может быть общеязыковым (например, тезаурус русского языка) или ориентированным на какую-либо предметную область. Лексика тезауруса может включать множество слов и/или фраз. В нем могут поддерживаться различные типы семантических связей между лексическими единицами: синонимы, антонимы, связи типа: «целое-часть», «род-вид», «используется для», «работает в» и т.д. Набор связей может быть зависимым или независимым от конкретной предметной области. К сожалению, разработка тезауруса вручную является весьма дорогостоящим, кропотливым и трудоемким делом, требующим значительных временных затрат. Поэтому на практике часто используют автоматическое создание тезаурусов. Методы решения этой задачи начали исследоваться еще в 60-х гг. XX в. Создание тезаурусов в автоматическом режимеосуществляется обычно на основе заданных коллекций текстовых документов. Поэтому такие тезаурусы предназначены для работы именно с этими коллекциями. Для создания тезауруса используется статистическая обработка текстов документов, входящих в данные коллекции. Автоматически построенный тезаурус поддерживает обычно простейший вид связей между лексическими термами, который может быть выявлен статистически, – ассоциативные связи, характеризующие совместное вхождение сочетания этих термов в текст документа. В системах, использующих тезаурус, можно, например, при поиске по ключевым словам расширять запрос, включая в него синонимы первоначально заданных пользователем ключевых слов и обеспечивая тем самым более полный поиск. Тезаурусы также часто используются для индексирования документов в ручном или автоматическом режиме. Вопрос 5. Поисковый аппарат. Существуют различные подходы к построению систем полнотекстового поиска. Это связано, главным образом, с разнообразием информационных потребностей пользователей, которое приводит к необходимости применения различных способов формулировки запросов, а также с различием возможных способов представления содержания текстовых документов в поисковых системах. Определение модели поиска. В литературе, посвященной текстовому поиску, одним из ключевых понятий, характеризующих технологию поиска в той или иной конкретной системе, является модельпоиска. Под моделью поиска понимается сочетание: · способа представления документов; · способа представления поисковых запросов; · вида критерия релевантности документов. Разнообразие функциональных возможностей различных систем текстового поиска связано именно с различием реализованных в них моделей поиска. Простейшие модели поиска– это модели, в которых документ представляется в виде набора ассоциированных с ним внешних атрибутов. К числу таких моделей принадлежит модель дескрипторного поиска, а также модель поиска, основанная на «Дублинском ядре». Модель дескрипторного поиска описана в предыдущих разделах. Модель поиска, основанная на «Дублинском ядре», основана на хранении метаданных о документе. Метаданные (англ. metadata) – это информация о документе, понимаемая ЭВМ, т.е. обладающая свойством внутренней интерпретируемости. Экземпляр метаданных для информационного ресурса выступает в качестве описания данного информационного ресурса. По назначению выделяют четыре основных вида метаданных: 1) описательные – библиографические описания информационных ресурсов и описания их семантики в виде рефератов и аннотаций; 2) структурные – формат, объем и структура информационного ресурса; 3) административные – правообладатели, права на доступ и коррекцию информационного ресурса, сведения о пользователях, платежах и др.; 4) идентифицирующие – служат для однозначного представления описываемых объектов для внешнего мира и приложений. Наиболее распространенной системой метаданных является «Дублинское ядро». «Дублинское ядро» включает два уровня: 1. Простое «Дублинское ядро». 2. «Дублинское ядро» с квалификаторами. Состав элементов простого «Дублинского ядра» определен в стандарте ISO 15836:2003.[2] Первый уровень содержит 15 элементов данных, образующих три группы: 1) содержание (англ. Content); 2) интеллектуальная собственность (англ. Intellectual Property); 3) характеристики данного экземпляра информационного ресурса (англ. Instantiation). На втором уровне к 15 элементам добавлены два дополнительных элемента: 1) целевая аудитория – категория пользователей (англ. Audience); 2) правообладатель (англ. Rights). Кроме того, для повышения детальности и выразительности описаний на этом уровне вводятся и используются квалификаторы, уточняющие семантику элементов данных и способы представления их значений. Так, например, даты рекомендуется представлять в формате ISO 8601:2004. Все элементы «Дублинского ядра» являются необязательными и могут повторяться. Порядок их следования в описании информационного ресурса значения не имеет. Модели, основанные на классификаторах, представляют собой одну из разновидностей простейших моделей, в которых документ выглядит в виде совокупности ассоциированных с ним атрибутов. В модели, основанной на классификаторах, документы представляются идентификаторами классов в иерархической структуре классификатора, к которым относится данный документ. Представление запроса в простейшем случае – также идентификатор какого-либо класса из заданного классификатора. Критерием релевантности документа является условие, что класс документа совпадает с классом в представлении запроса или является его подклассом. В более сложном случае в модели поиска, основанной на классификаторах, допускается указание в запросе нескольких классов классификатора. При этом релевантными считаются документы, принадлежащие какому-либо из указанных в запросе классов. Такая модель поиска близка к рассматриваемой далее булевской модели. Булевские модели – модель поиска,особенность которой заключается в том, что пользователь может формулировать запрос в виде булевского выражения с использованием операторов И, ИЛИ, НЕТ. Термы такого выражения могут быть различными в разных вариациях модели поиска. Это может быть, например, условие вхождения данного слова или словосочетания (с точностью до грамматических форм) в текст документа в булевской модели, ориентированной на контекстный поиск. В булевской модели, ориентированной на поиск по классификаторам, термами выражения могут быть условия принадлежности документа данному классу классификатора. В булевской модели поиска с использованием Дублинского ядра термом может быть равенство, описывающее тот факт, что некоторый элемент метаданных имя рассматриваемого документа имеет заданное в запросе значение. Критерием релевантности данного документа запросу в булевских моделях поиска является истинность булевского выражения, заданного в запросе. Векторные модели – это более продвинутые модели поиска, различные вариации которых в настоящее время широко применяются на практике. Вероятно, самыми распространенными из них являются векторные модели поиска, называемые иногда также векторными пространствами. В векторных моделях предполагается, что документы и запросы представляются векторами. В простейшем случае координаты вектора соответствуют термам текста – словам или словосочетаниям, принадлежащим словарю системы, который представляет общеязыковую лексику или лексику предметной области. Каждому терму из такого словаря сопоставляется свое измерение в векторном пространстве. Размерность векторов, представляющих документы и пользовательские запросы, в точности равна количеству измерений в этом пространстве. Координате вектора присваивается некоторое ненулевое значение в том и только в том случае, когда соответствующий ей терм принадлежит данному документу или запросу. Поскольку размер словаря может быть очень большим, а документы или тексты запросов состоят из существенно меньшего количества содержащихся в нем термов, такие векторы оказываются очень разреженными. Поэтому нужно использовать какую-либо технику сжатого их представления. Вероятностные модели,в отличие от векторных, имеют более строгую математическую основу. Идеи таких моделей были предложены еще в 1960 г. Ключевая из них называется принципом вероятностного ранжирования (англ. Probabilistic Ranking Principle, PRP). Суть этого принципа состоит в том, что наивысшая общая эффективность поиска достигается в случае, если результирующие документы ранжируются по убыванию вероятности их релевантности запросу. Для каждого документа оценивается вероятность того, что он релевантен запросу, и по этим оценкам выполняется ранжирование документов. Именно используемыми способами получения таких оценок и некоторыми дополнительными предположениями различаются конкретные вероятностные модели поиска. В частности, указанная оценка может быть получена в соответствии с теоремой Байеса, как некоторая функция от вероятностей вхождения термов данного документа в релевантные и нерелевантные документы. С помощью запроса определяется вероятность вхождения заданного терма в релевантные документы, а по полной коллекции документов может быть определена вероятность вхождения этого терма в нерелевантные документы. Сети вывода– это еще один популярный класс моделей поиска. Сети вывода,как и вероятностные модели поиска, основаны на принципе вероятностного ранжирования результирующих документов поиска. Однако, в отличие от вероятностных моделей, в моделях сетей вывода рассматривается оценка невероятности релевантности документа запросу, а вероятности того, что он удовлетворяет информационным потребностям пользователя. Модели этого семейства описывают процесс поиска документов как процесс рассуждений в условиях неопределенности, в котором оценивается вероятность того, что выраженные с помощью одного или нескольких запросов информационные потребности пользователя удовлетворяются. Основой моделей рассматриваемого класса является Байесовская сеть, включающая узлы нескольких видов. Узлы первого вида представляют конкретные документы коллекции, в которой осуществляется поиск, и соответствуют событию изучения этого документа для целей поиска. Узлы второго вида представляют понятия, в терминах которых описывается содержание документов. Узлы третьего вида – это узлы запросов. Они соответствуют тем понятиям, в терминах которых описываются информационные потребности пользователей. Единственный узел четвертого типа в сети соответствует информационным потребностям пользователя, которые системе неизвестны. Все узлы первого и второго вида в сети могут быть построены заранее для заданной коллекции. Что же касается узлов третьего вида, то эти узлы и их связи с узлами понятий и узлом информационных потребностей формируются для каждого конкретного запроса. Эвристические подходы и эмпирика в моделях поиска. В продвинутых моделях поиска существенную роль играют элементы эмпирики и эвристики. Эвристические подходы и формализующие их эмпирические математические зависимости используются как в функциях оценки релевантности документов, так и в построении представлений документов и запросов. Поэтому таким моделям поиска свойственна некоторая неустойчивость поведения. При использовании конкретной модели поиска наряду с высокими оценками качества поиска на одной коллекции документов можно получить отнюдь не столь высокие оценки на другой коллекции. Правдоподобные общие оценки качества поиска для модели можно получать лишь усреднено на множестве разнообразных коллекций. Существенное значение имеют и оценки результатов поиска, полученные на больших коллекциях. Вопрос 6. Критерии оценки документальных систем. Поисковое предписание и поисковый образ документа отражают лишь основное смысловое содержание поступающих сообщений в сокращенном виде. Поэтому метод информационного поиска, основанный на сопоставлении поискового предписания с поисковым образом документа, не в состоянии полностью обеспечить отыскания всех документов, отвечающих информационному запросу. Это приводит к тому, что часть документов, отвечающих запросу, т.е. релевантных ему, остается не выданной потребителю. В то же время во множестве выданных ему документов присутствуют и такие, которые не отвечают запросу, т.е. не являются релевантными. Таким образом, практически в любой документальной ИПС могут быть два типа ошибок: 1) ошибки 1-го рода (или пропуски цели): невыдача потребителю фактически релевантных его запросу документов; 2) ошибки 2-го рода (или ложная тревога, иначе шум): выдача потребителю нерелевантных документов, которые не отвечают поставленному запросу. Наличие ошибок 1-го и 2-го рода в реальной системе обуславливает разбиение всего массива документов системы по отношению к запросу на 4 подмассива:
a – количество выданных релевантных документов; b – количество выданных нерелевантных документов; c – количество не выданных релевантных документов; d – количество не выданных нерелевантных документов. Приведем основные показатели эффективности документальных ИПС. Такими показателями являются полнота и точность информационного поиска. Коэффициент полноты p, характеризующий долю выданных релевантных документов во всем массиве релевантных документов: p = a / (a + c). Коэффициент точности n, характеризующий долю выданных релевантных документов во всем массиве выданных документов: n = a / (a + b). Часто для удобства эти показатели измеряют в процентах. На практике часто используют лишь коэффициенты полноты и точности. Очевидно, что обе эти характеристики зависят как от свойств поисковой системы, так и от правильности построения конкретного запроса и от субъективного представления пользователя о том, что такое нужная ему информация. ИСП тем лучше, чем больше полнота и точность, т.е. находит все нужные документы и ни одного лишнего. Однако улучшение одного из этих параметров приводит к ухудшению другого. В идеале полнота информационного поиска и точность информационного поиска должны приближаться к единице, хотя на практике их значения колеблются в пределах от 60 до 90 %. Другими показателями, характеризующими качество отобранных документов, являются: Коэффициент шума e, характеризующий долю выданных нерелевантных документов во всем массиве выданных документов: e = b / (a + b) = 1 - n. Коэффициент осадка q, характеризующий долю выданных нерелевантных документов во всем массиве нерелевантных документов: q = b / (b + d). Коэффициент специфичности k, характеризующих долю не выданных нерелевантных документов во всем массиве нерелевантных документов: k = d / (b + d). Наряду с этими показателями, основанными на сопряжении релевантности и выдачи, могут быть использованы следующие: · быстродействие документальной ИПС – интервал времени между моментом формулировки запроса и получением ответа на него; · пропускная способность– оценивается количеством вводимых документов и количеством ответов в единицу времени при заданных значениях коэффициента полноты и точности; · производительность– оценивается количеством пользователей системы и частотой обращения с их стороны; · надежность работы– оценивается вероятность того, что система будет выполнять свои функции при заданных условиях в течение требуемого времени; · типы запросов, обслуживаемых системой. Вопрос 7. Программные средства реализации документальных ИС. Информационно-поисковые системы Интернета. Для того чтобы искать информацию в глобальной сети, кратко остановимся на ИПС Интернета, предназначенных для поиска и выдачи пользователю необходимой информации. На сегодняшний день все крупные ИПС имеют как минимум два поисковых интерфейса: 1) простой поиск (англ. simple search); 2) расширенный поиск (англ. advanced search). Основное различие между ними заключается в возможности составления запросов и поисковых предписаний различной степени сложности. Оба интерфейса относятся к графическому типу и реализованы в виде Web-страниц. В качестве параметров поиска используются ключевые слова, с помощью которых создаются поисковые запросы (поисковые предписания). Поле для ввода ключевых слов и кнопка отправки запроса являются обязательными для любого типа интерфейса. Основными видами поиска являются: любое из слов, все слова, точно по фразе. Для большинства поисковых систем можно комбинировать ключевые слова, используя логические операторы: AND, OR, NOT, NEAR. Это создает возможность конкретизировать запрос, получать более точную информацию. Каждая поисковая система имеет свой синтаксис запросов, с которым можно ознакомиться на ее сайте. Яndex – самая популярная в настоящее время отечественная поисковая система (http://www.yandex.ru). Она является четвёртой среди поисковых систем мира по количеству обрабатываемых поисковых запросов. По этому показателю он отстаёт лишь от Google, Baidu и Yahoo! По состоянию на сентябрь 2018 г., согласно рейтингу Alexa.com, сайт yandex.ru по популярности занимает 21-е место в мире и 1-е в России. Яndex поддерживает собственный каталог Интернет-ресурсов, имеет возможность простого и расширенного поиска. Google (www.google.com, www.google.ru) – крупнейшая в мире поисковая система интернета, принадлежащая корпорации Google Inc. Основана в 1998 г. Ларри Пейджем и Сергеем Брином. Первая по популярности система (77,05 %), обрабатывает 41 млрд 345 млн запросов в месяц (доля рынка 62,4%). Поддерживает поиск в документах форматов PDF, RTF, PostScript, Microsoft Word, Microsoft Excel, Microsoft PowerPoint и других. Yahoo – это система появилась в сети одной из первых, и сегодня Yahoo (http://www.yahoo.com) сотрудничает со многими производителями средств информационного поиска, а на различных ее серверах используется различное программное обеспечение. ИПЯ Yahoo достаточно прост: все слова следует вводить через пробел, они соединяются связкой AND либо OR. Ранжирование производится по числу терминов запроса в документе. Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска. В последние годы в связи с изменением общей структуры мирового информационного потока наметился ряд тенденций в развитии классических информационно-поисковых систем. К этим тенденциям можно отнести следующие: · быстрое развитие связей как между отдельными информационными элементами, так и внутри самих элементов (гипертекстовые связи, межсетевые связи и т.п.); · усложнение структуры информационных объектов (внедренная графика, мультимедиа, Java-приложения, OLE объекты); · резкое нарастание объемов обрабатываемой документальной информации и ее динамическое изменение, например, реализация Oracle Text Server с количеством документов общего типа до нескольких миллиардов с объемом несколько терабайт с непрерывным изменением да 10 % документов; · слияние различных информационных систем в гетерогенные сети с унифицированным пользовательским интерфейсом при базировании на технологии «клиент-сервер». В России исторически сложились и развиваются два направления развития ИПС: 1. Классические ИПС, ориентированные на обработку больших массивов текстовой и фактографической документальной информации. К этому типу относятся: · проект «Разработка комплекса информационных услуг на основе банка данных отечественных и зарубежных публикаций по науке и технике»; · полнотекстовая документальная информационная система «ODB-TEXT» и др. 2. Прикладные ИПС, ориентированные на обработку экспериментальных данных в той или иной области знаний. Среди них: · гипермедийная ИС общего пользования с автоматическим накоплением данных, поступающих с метеорологических спутников; · экспертная система поддержки экспериментов в области физико-химической кинетики; · компьютерная база геополей Урала; · виртуальные энциклопедические и справочные издания и др. |