Базовые информационные технологии. Тема Информатизация общества Вопрос Цели и задачи информатизации общества
 Скачать 4.13 Mb. Скачать 4.13 Mb.
|

Тема 7. Фактографические системыВопрос 1. Обзор основных видов фактографических ИС. Фактографические информационные системы – это самый большой класс автоматизированных информационных систем. Фактографические информационные системы работают с данными (фактическими сведениями), представленными специальным образом, в виде организованных совокупностей формализованных записей данных. Центральное звено фактографических информационных систем – база данных и система управления базами данных. Фактографические информационные системы подразделяются на следующие классы: 1. Фактографические информационно-поисковые системы используются для реализации справочных функций. 2. Фактографические системы обработки данных используются для специального класса задач, связанных с вводом, хранением, сортировкой, отбором и группировкой записей данных однородной структуры. Задачи этого класса решаются при учете товаров в магазинах и на складах, начислении зарплаты, управлении производством, финансами, телекоммуникациями. Фактографические информационно-поисковые системы используются для реализации поиска информации в системах структурированных данных. В фактографических информационно-поисковых системах хранятся не документы, а собственно сведения (факты) об объектах предметной области. Подобные ИПС реализуются, в частности, на основе реляционных баз данных. Методы информационного поиска в данных системах находятся по набору признаков, например, заданному SQL-выражением. С точки зрения обеспечения релевантности результатов поиска (выборки данных) запросу, фактографический поиск в отличие от документального является точным и полным. Фактографические системы обработки данных бывают двух типов: 1. Системы оперативной обработки транзакций (англ. On-Line Transaction Processing, OLTP) подразумевают быстрое обслуживание большого числа достаточно простых запросов. Системы используются для повседневной работы с данными, например, продажа товаров и выписка счетов и т.д. Эти системы подвержены постоянным изменениям в процессе работы пользователей, являются источником данных для систем аналитической обработки данных. 2. Системы аналитической обработки данных (англ. On-Line Analytical Processing, OLAP) ориентированы на выполнение сложных запросов, требующих предварительной аналитической обработки данных. Для хранения предварительно обработанных данных используются специальные хранилища данных (англ. Data Warehouse). Хранилище данных относительно стабильно, данные в нем обычно пополняются по расписанию, например, в зависимости от потребностей еженедельно, ежедневно, ежечасно. Использование хранилищ данных позволяет в дальнейшем достаточно быстро (обычно не более 5 секунд) извлекать данные для последующей аналитической обработки. Данные системы часто используются как системы поддержки принятия решений для обеспечения аналитиков информацией, для проведения статистической обработки исторических (накопленных за некоторый промежуток времени) данных, моделирования процессов предметной области, прогнозирования развития этих процессов. Вопрос 2. Предметная область. Каждая информационная система в зависимости от назначения имеет дело с той или иной частью конкретного мира, которую принято называть предметной областью. Предметная область – это часть реального мира, представляющая интерес для данного исследования. Анализ предметной области является начальным необходимым этапом разработки любой информационной системы. Именно на этом этапе определяются информационные потребности всей совокупности пользователей будущей системы, которые, в свою очередь, предопределяют содержание ее базы данных. Предметная область конкретной информационной системы рассматривается, прежде всего, как некоторая совокупность реальных объектов, которые представляют интерес для пользователей. Объектом называется явление, предмет, на который направлена чья-нибудь деятельность, чьё-нибудь внимание. Это либо нечто реально существующее, например, фирма, товар, изделие и др., либо процесс, например, учет платежей, получение товаров, выпуск изделий. Информационный объект – это описание некоторой сущности предметной области, т.е. реального объекта, процесса, явления или события. Каждый объект обладает набором свойств (атрибутов). Так, например, объект «фирма» обладает свойствами: название, номер государственной налоговой инспекции, адрес, руководитель; объект «товар» обладает свойствами: категория товара, наименование товара, дата поставки. Информационный объект (сущность) образуется совокупностью логически взаимосвязанных атрибутов (свойств), представляющих собой качественные и количественные характеристики объекта (сущности). Между объектами существуют многочисленные связи. Например, фирма покупает (продает) товар. Товар покупается (продается) фирмой. Совокупность объектов предметной области и связей между ними характеризует структуру предметной области. Множество объектов предметной области, значения атрибутов объектов и связи между ними могут изменяться во времени. Зафиксированные во времени цепочки этих изменений называются траекториями предметной области, а совокупность общих свойств траекторий – семантикой предметной области. Для описания предметной области могут быть использованы следующие основные подходы: 1. Функциональный подход – он реализует принцип движения «от задач» и применяется тогда, когда заранее известны функции некоторой группы лиц и комплексов задач, для обслуживания информационных потребностей которых создается рассматриваемая БД. В этом случае мы можем четко выделить минимальный необходимый набор объектов предметной области, которые должны быть описаны. 2. Предметный подход – когда информационные потребности будущих пользователей БД жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными. Мы не можем точно выделить минимальный набор объектов предметной области, которые необходимо описывать. В описание предметной области в этом случае включаются такие объекты и взаимосвязи, которые наиболее характерны и наиболее существенны для нее. БД, конструируемая при этом, называется предметной, то есть она может быть использована при решении множества разнообразных, заранее не определенных задач. Конструирование предметной БД в некотором смысле кажется гораздо более заманчивым, однако трудность всеобщего охвата предметной области с невозможностью конкретизации потребностей пользователей может привести к избыточно сложной схеме БД, которая для конкретных задач будет неэффективной. 3. Смешанный (предметно-функциональный) подход – используется чаще всего на практике. С одной стороны, он ориентирован на конкретные задачи или функциональные потребности пользователей, а с другой стороны, учитывает возможность наращивания новых приложений. Вопрос 3. Концептуальные средства описания. Для описания предметной области в принципе можно использовать и естественный язык, но к сожалению, это приводит к громоздкости описания и неоднозначности словесной трактовки. Для того чтобы этого избежать, для описания предметной области используют средства концептуального моделирования. Концептуальное моделирование – это переход от неформализованного описания предметной области к ее формальному изложению с помощью специальных языковых средств. Цель процесса концептуального моделирования состоит в том, чтобы разработчики информационной системы могли получить от специалистов по проблемной области информацию о рассматриваемой предметной области до такой степени детализации, чтобы иметь возможность спроектировать информационную систему и базу данных. Основными компонентами концептуальной модели предметной области являются: 1) описание объектов предметной области и связей между ними; 2) описание информационных потребностей пользователей; 3) описание существующей информационной системы (документы, документооборот), при наличии автоматизированной информационной системы, ее описание; 4) описание алгоритмических зависимостей показателей; 5) описание ограничений целостности; 6) описание функциональной структуры системы, для которой создается информационная система; 7) требования к информационной системе и существующие ограничения; 8) лингвистические отношения. Имеется целый ряд методик создания концептуальных моделей. Чаще всего для описания концептуальных моделей описания объектов предметной области и связей между ними представляется в виде так называемой ER-модели. При разработке концептуальной модели основные усилия разработчиков должны быть направлены на структуризацию данных будущей информационной системы и выявление взаимосвязей между ними. Основные требования, предъявляемые к концептуальной модели: · адекватное отображение предметной области (модель должна содержать всю необходимую информацию для дальнейшего проектирования системы); · непротиворечивость; · однозначная трактовка модели всеми ее пользователями; · легкость восприятия разными категориями пользователей; · конечность модели (четкое ограничение предметной области); · легкость модификации; · возможность композиции и декомпозиции модели. К языковым средствам предъявляются следующие требования: · универсальность – язык для представления модели должен обладать достаточными выразительными возможностями для отображения явлений, имеющих место в предметной области (адекватное отображение предметной области); · точность и структурированность языковых средств – обеспечивается формализованностью языка; · однозначность трактовки – четкое понимание всеми участниками информационного процесса создания информационной системы; · легкость восприятия – язык должен достаточно просто интерпретироваться людьми; · обеспечивать возможность применения ЭВМ – язык спецификации концептуальной модели должен быть одинаковым как при ручном, так и при автоматизированном проектировании информационных систем; · быть вычисляемыми, т.е. восприниматься и обрабатываться на ЭВМ; · интерфейсы должны быть «дружелюбными» пользователю, например, графические; · быть независимым от оборудования и других ресурсов, которые подвержены частым изменениям; · использовать средства тестирования концептуального моделирования, а также иметь аппарат для указания того, что спецификация завершена и может быть выполнена генерация структуры базы данных. Концептуальная модель является средством коммуникации разнообразных коллективов как конечных пользователей, так и разработчиков. Вопрос 4. Модель сущность – связь. Одна из наиболее популярных в настоящее время методик, используемая при разработке концептуальной модели, – это ER-модель или ER-диаграмма (англ. Entity-Relationship Diagrams). В русскоязычной литературе эти диаграммы называют «объект – отношение» либо «сущность – связь». ER-модель была предложена Питером Пин Шен Ченом в 1976 г. К настоящему времени разработано несколько ее разновидностей, но все они базируются на графических диаграммах, предложенных Ченом. Диаграммы конструируются из небольшого числа компонентов. Благодаря наглядности представления они широко используются в CASE-средствах (англ. Computer Aided Software Engineering). Сущность (англ. Entity) – реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению. Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа (сущности). Каждая сущность должна обладать некоторыми свойствами: · Иметь уникальное имя; причем к этому имени должна всегда применяться одна и та же интерпретация (определение сущности). И наоборот: одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами. · Обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются ею через связь. · Обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности. Сущность может быть независимой либо зависимой (рис. 10). Признаком зависимой сущности служит наличие у нее наследуемых через связь атрибутов. 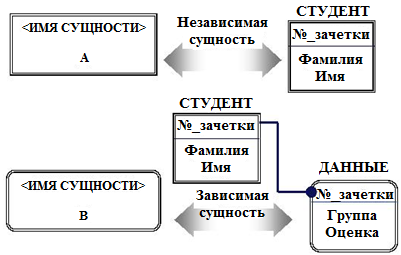 Рис. 10. Графическое обозначение сущностей: A – независимая сущность, B – зависимая Каждая сущность может обладать любым количеством связей с другими сущностями модели. Связь (англ. Relationship) – поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Одна из участвующих в связи сущностей – независимая, называется родительской сущностью, другая – зависимая, называется дочерней, или сущностью-потомком. Как правило, каждый экземпляр родительской сущности ассоциирован с произвольным (в том числе нулевым) количеством экземпляров дочерней сущности. Каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя. Связи дается имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Каждая связь имеет определение. Определение связи образуют соединением имени сущности-родителя, имени связи, выражения степени связи и имени сущности-потомка. Например, связь продавца с контрактом может быть определена следующим образом: · Продавец может получить вознаграждение за 1 или более Контрактов. · Контракт должен быть инициирован ровно одним Продавцом. На диаграмме связь изображается отрезком (ломаной). Концы отрезка с помощью специальных обозначений указывают степень связи. Кроме того, характер линии (штриховая или сплошная линия), указывает обязательность связи (рис. 11). 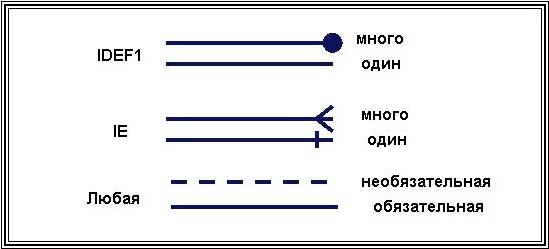 Рис. 11. Графическое изображение связей Атрибут – любая характеристика сущности, значимая для рассматриваемой предметной области. Он предназначен для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик (свойств), ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута – это определенная характеристика конкретного экземпляра сущности. Экземпляр атрибута определяется типом характеристики (например, «Цвет») и ее значением (например, «лиловый»), называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Каждый экземпляр сущности должен обладать одним конкретным значением для каждого своего атрибута. Атрибут может быть либо обязательным, либо необязательным. Обязательность означает, что атрибут не может принимать неопределенных значений (англ. null values). Графическое представление атрибутов представлено на рис. 12. 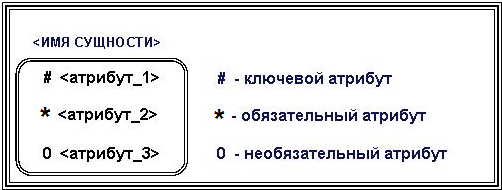 Рис. 12. Графическое отображение характеристики атрибута Атрибут может либо быть описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа). Правила атрибутов. · Каждый атрибут должен иметь уникальное имя, одному и тому же имени должно соответствовать одно и то же значение. Одно и то же значение не может соответствовать различным именам. · Сущность может обладать любым количеством атрибутов. Каждый атрибут принадлежит в точности одной сущности. · Сущность может обладать любым количеством наследуемых атрибутов, но наследуемый атрибут должен быть частью первичного ключа, соответствующей сущности-родителя или общей сущности. · Для каждого экземпляра сущности должно существовать значение каждого его атрибута (правило не обращения в нуль). · Ни один из экземпляров сущности не может обладать более чем одним значением для связанного с ней атрибута (правило неповторения). Так как некоторые реально существующие объекты являются категориями других реально существующих объектов, то некоторые сущности должны, в некотором смысле, быть категориями других сущностей. Уникальный идентификатор – это атрибут или совокупность атрибутов и/или связей, однозначно характеризующая каждый экземпляр данного типа сущности. В случае полной идентификации экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в идентификации участвуют также атрибуты другой сущности-родителя. Характер идентификации отображается в диаграмме на линии связи (рис. 13). 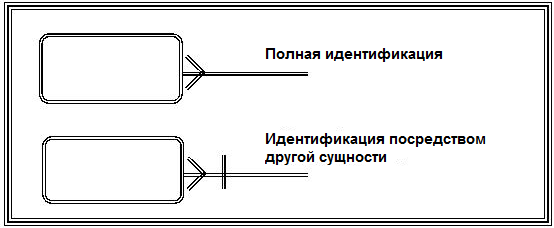 Рис. 13. Графическое отображение характера идентификации Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком «#». Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности – это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные – как альтернативные ключи. Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то отношение называется «идентифицирующим отношением». В противном случае отношение называется неидентифицирующим (рис. 14). Отношение связи изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Идентифицирующее отношение изображается сплошной линией, пунктирная линия изображает неидентифицирующее отношение. 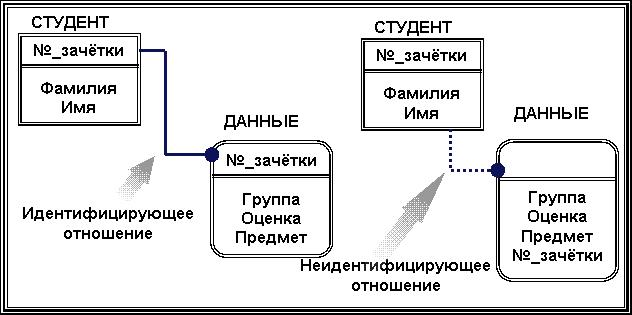 Рис. 14. Графическое отображение идентифицирующих и неидентифицирующих отношений Отношению дается имя, выражаемое грамматическим оборотом глагола. Имя отношения всегда формируется с точки зрения родителя, так что может быть образовано предложение, если соединить имя сущности-родителя, имя отношения, выражение мощности и имя сущности-потомка. Связь может дополнительно определяться степенью или мощностью (число экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). Возможны следующие мощности связей: · Каждый экземпляр сущности-родителя может иметь нуль, один или более связанных с ним экземпляров сущности-потомка. · Каждый экземпляр сущности-родителя может иметь не менее одного связанного с ним экземпляра сущности-потомка. · Каждый экземпляр сущности-родителя может иметь не более одного связанного с ним экземпляра сущности-потомка. · Каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка. Вопрос 5. Представление данных в памяти ЭВМ. Для представления данных в памяти ЭВМ в фактографических информационных системах используется база данных (БД). Ядром любой базы данных является модель данных. Модель данных – это совокупность структур данных и операций их обработки. По способу установления связей между данными наибольшее распространение получили следующие модели данных: · иерархическая; · сетевая; · реляционные; · объектно-ориентированные. Иерархическая модель данных. Иерархическая модель данных была исторически первой структурой БД. Иерархическая модель позволяет строить базы данных с древовидной структурой, где каждый узел содержит свой тип данных (сущность). На верхнем уровне дерева в этой модели имеется один узел – корень, на следующем уровне располагаются узлы, связанные с этим корнем, затем узлы, связанные с узлами предыдущих, и т.д. При этом каждый узел может иметь только одного предка. В иерархической структуре подчиненный элемент данных всегда связан только с одним исходным (рис. 15). 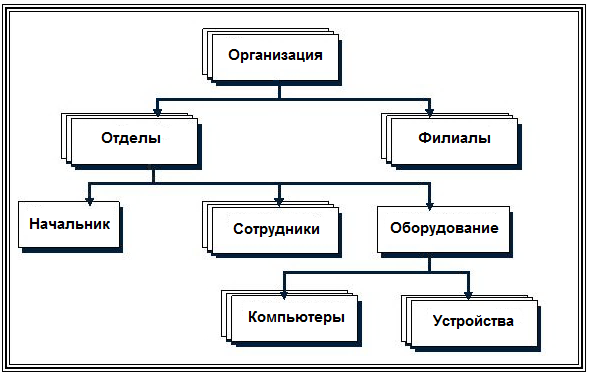 Рис. 15. Иерархическая древовидная структура модели БД Поиск данных в иерархической системе всегда начинается с корня. Затем производится спуск с одного уровня дерева на другой, пока не будет достигнут искомый уровень. Перемещения по системе от одной записи к другой осуществляются с помощью ссылок. Если структура запроса совпадает со структурой иерархической БД, то такая модель обладает самым высоким быстродействием и потому чаще всего применяется в супер ЭВМ. В противном случае, быстродействие может резко снизиться, т.к. не удобно всегда начинать поиск нужных данных с корня, а другого способа перемещения по базе в иерархических структурах нет. Достоинства и недостатки иерархической модели представлены в таблице 2. Таблица 2.
Базы данных с иерархической моделью одни из самых старых. Они стали первыми системами управления базами данных для мейнфреймов. Разрабатывались в 1950-х и 1960-х, например, Information Management System (IMS) фирмы IBM (создана в 1968 г. в рамках проекта высадки на Луну – «Аполлон»). Сетевая модель данных. В 1963 году С. Бахман построил первую промышленную базу данных IDS с сетевой моделью данных. В 1969 г. сформировалась группа, создавшая набор стандартов CODASYL (КОДАСИЛ) для сетевой модели данных. Сетевая модель данных основана на представлении информации в виде орграфа, в котором в каждую вершину может входить произвольное число дуг. Вершинам графа сопоставлены типы записей, дугам – связи между ними. В сетевой модели (по крайней мере, теоретически) возможны связи всех информационных объектов со всеми. На рис. 16, 17. представлены примеры структуры сетевой модели данных. 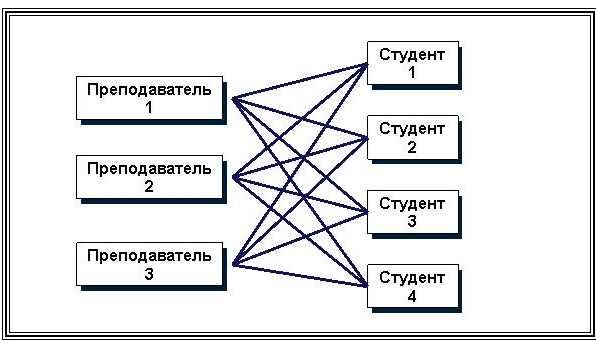 Рис. 16. Сетевая структура модели БД 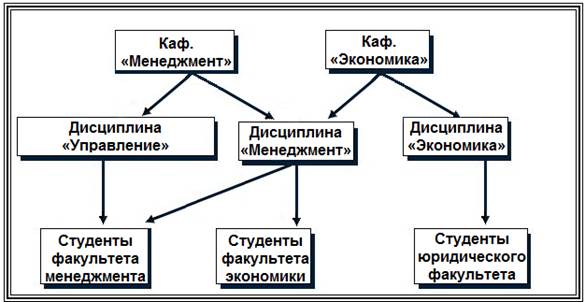 Рис. 17. Фрагмент сетевой модели данных По сравнению с иерархическими сетевые модели обладают рядом существенных преимуществ: · возможность отображения практически всего многообразия взаимоотношений объектов предметной области; · непосредственный доступ к любой вершине сети (без указания других вершин); · малая информационная избыточность. Вместе с тем, в сетевой модели невозможно достичь полной независимости данных, поскольку с ростом объема информации сетевая структура становится весьма сложной для описания и анализа. Использование иерархической и сетевой моделей ускоряет доступ к информации в базе данных. Однако, поскольку каждый элемент данных должен содержать ссылки на некоторые другие элементы, требуются значительные ресурсы как дисковой, так и основной памяти ЭВМ. Недостаточность основной памяти, конечно, снижает скорость обработки данных. Кроме того, для таких моделей характерна сложность реализации системы управления базами данных. Реляционная модель данных. Реляционная модель (от англ. relation – отношение) была разработана в начале 70-х годов XX в. Коддом. Простота и гибкость этой модели привлекли к ней внимание разработчиков, и уже в 80-х годах XX в. она получила широкое распространение. Таким образом, реляционные СУБД оказались промышленным стандартом. В основе реляционной модели данных лежат не графические, а табличные методы и средства представления данных и манипулирования ими (рис. 18). 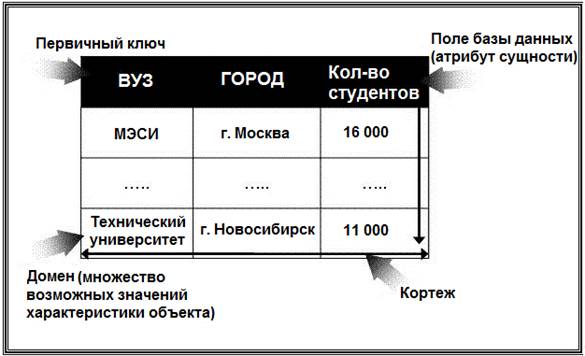 Рис. 18. Фрагмент реляционной модели данных Реляционная модель опирается на систему понятий реляционной алгебры, важнейшими из которых являются таблица, строка, столбец, отношение и первичный ключ. Следовательно, все операции сводятся к манипуляциям с таблицами. Строка такой таблицы называется кортежем, столбец – атрибутом. Каждый атрибут может принимать некоторое подмножество значений из определенной области – домена. Таблица отражает объект реального мира – сущность, а каждая ее строка (запись) отражает один конкретный экземпляр объекта – экземпляр сущности. Каждый столбец таблицы имеет уникальное для данной таблицы имя. Располагаются столбцы в соответствии с порядком следования их имен, принятом при создании таблицы. Реляционные системы исключили необходимость сложной навигации, поскольку данные представлены в них не в виде одного файла, а независимыми наборами, и для отбора данных используются операции реляционной алгебры: прикладной теории множеств. В каждой таблице реляционной модели должен быть столбец (или совокупность столбцов), значение которого однозначно идентифицирует каждую ее строку. Этот столбец (или совокупность столбцов) и называется первичным ключом таблицы (рис. 19). 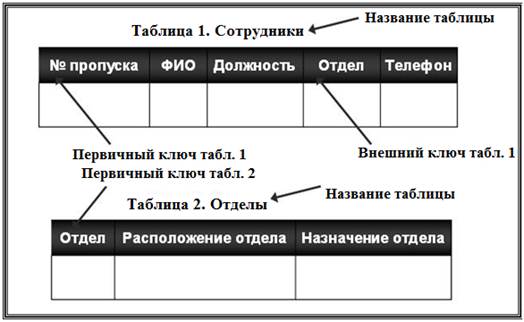 Рис. 19. Организация ссылки от одной таблицы к другой Если таблица удовлетворяет требованию уникальности первичного ключа, она называется отношением. В реляционной модели все таблицы должны быть преобразованы в отношения. Отношения реляционной модели связаны между собой. Связи поддерживаются внешними ключами. Внешний ключ – это столбец (совокупность столбцов), значение которого однозначно характеризует значения первичного ключа другого отношения (таблицы). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором та же совокупность столбцов является первичным ключом. Схема реляционной таблицы (отношения) представляет собой совокупность имен полей, образующих ее запись: НАЗВАНИЕ ТАБЛИЦЫ (Поле 1, Поле 2, ..., Поле n). Например, для таблиц, показанных на рис. 19, имеем следующие схемы: СОТРУДНИК (Номер пропуска, ФИО, Должность, Название отдела, Телефон). ОТДЕЛ (Название отдела, Расположение отдела, Назначение отдела). Подавляющее большинство СУБД, ориентированных на персональные ЭВМ, являются системами, построенными на основе реляционной модели данных, так называемыми «реляционными» СУБД. Доминирование реляционной модели в современных СУБД определяется наличием: · развитой теории (реляционной алгебры); · аппарата сведения других моделей данных к реляционной модели; · специальных средств ускоренного доступа к информации; · стандартизированного высокоуровневого языка запросов к БД, позволяющего манипулировать ими без знания конкретной физической организации БД во внешней памяти. Объектно-ориентированная модель. Объектно-ориентированная модель баз данных начала разрабатываться в связи с появлением объектно-ориентированных языков программирования в 90-е годы XX в. Это одна из самых перспективных и прогрессивных моделей баз данных, существующих в настоящее время. В этой модели база данных, интерфейс пользователя и алгоритм приложения построены с использованием объектно-ориентированного подхода. Объектно-ориентированная СУБД должна поддерживать объекты с нелинейной структурой (сложные объекты, в том числе с иерархией объектов), что достигается инкапсуляцией и наследованием. Такого рода базы хранят методы классов, а иногда и постоянные объекты классов, что позволяет осуществлять беспрепятственную интеграцию между данными и их обработкой в приложениях. Легко поддерживается расширяемость, вычислительная полнота, языки запроса. В 1991 г. была сформирована группа Object Database Management Group (ODMG), целью которой было – построить стандарты для объектно-ориентированной базы данных (ООБД). В 1993 г. был предложен стандарт ODMG-3 для ООБД, который включает: 1) объектную модель Object Data Model (ODM); 2) язык определения объектов Object Definition Language (ODL); 3) объектный язык запроса Object Query Language (OQL); 4) интерфейсы языков программирования (С++ и др.). Суть ООБД определяется объектно-ориентированным подходом, который включает объектно-ориентированное проектирование и объектно-ориентированное программирование. Чтобы построить ООБД, нужно, чтобы все структурные элементы реализации были спроектированы с использованием объектно-ориентированного подхода. Для этого необходимо: · провести инкапсуляцию данных, т.е. выделить классы и объекты; · определить возможные виды структуры реализуемых таблиц; · создать наследование классов данных; · обеспечить полиморфизм. Базовым языком ООБД чаще всего является С++. Для работы с такими ООБД разрабатывается новый вариант языка программирования SQL, получивший название SQL3, содержащий внутри себя в качестве частного случая SQL2. В настоящее время насчитывается несколько сотен объектно-ориентированных СУБД. Наиболее широкое применение объектно-ориентированные базы данных нашли в таких областях, как системы автоматизированного конструирования/производства (CAD/CAM), системы автоматизированной разработки программного обеспечения (CASE), системы управления составными документами. Так, например, компания Enterprise Integration Tecnologies предлагает продукт MKS (Manufacturing Knowledge System – система знаний о производстве). В рамках этого продукта возможно интегрировать разработку технологических процессов, разработку оборудования, управление предприятием, проектирование производственных помещений, диагностику, мониторинг, моделирование и планирование. В России получила широкое распространение СУБД Cashe фирмы InterSystems, апробированная и хорошо проявившая себя в банках. В данной СУБД предусмотрен объектный доступ (объектно-ориентированная модель) и SQL-доступ (реляционная модель с использованием языка SQL2). Хранение данных осуществляется с помощью многомерной модели данных, позволяющей уменьшить объем потребной памяти при одновременном увеличении скорости доступа к данным. В последнее время объектно-ориентированные СУБД все чаще применяют как составную часть другого приложения. Например, компания Computervision, производящая программное обеспечение CAD, интегрировало в свой продукт СУБД ObjectStory. Американские фирмы Aotorol Technology, Step Tools, Dec используют ООСУБД ObjectStory для работы со слабо структурированными данными в стандарте обмена данными STEP (Standard of Exchange of Product model data). Вопрос 6. Программные средства реализации фактографических ИС. Подавляющее большинство фактографических информационных систем, ориентированных на персональные ЭВМ, построены на основе реляционной модели данных, так называемых «реляционных» СУБД. Группа реляционных СУБД представлена на рынке программных продуктов очень широко. Например, системы dBase, Paradox, FoxPro, Access. dBase – семейство широко распространённых систем управления базами данных, а также язык программирования, используемый в них. В настоящее время используется версия dBase IV. Хранение данных в dBase основано на принципе «одна таблица – один файл» (эти файлы обычно имеют расширение *.dbf). МЕМО-поля и BLOB-поля (доступные в поздних версиях dBase) хранятся в отдельных файлах (обычно с расширением *.dbt). Индексы для таблиц также хранятся в отдельных файлах. При этом в ранних версиях этой СУБД требовалась специальная операция реиндексирования для приведения индексов в соответствие с текущим состоянием таблицы. dBase является родоначальником и некогда популярного семейства языков программирования, получившего называние xBase. Обладавшие немалым сходством в синтаксисе и поддерживаемом наборе команд во времена широкого применения DOS, языки семейства xBase, тем не менее, имели немало различий, особенно в поздних версиях «наследников», использовавших их СУБД. Как правило, все они обладали собственными объектными расширениями, поэтому совместимость между ними практически отсутствовала. Однако, что для работы с данными в формате dBase (или иных dBase-подобных СУБД) совершенно необязательно пользоваться диалектами xBase. Доступ к этим данным возможен с помощью Microsoft ODBC API (при наличии соответствующих драйверов) и некоторых других механизмов доступа к данным, например, Borland Database Engine, и некоторых библиотек других производителей типа CodeBase фирмы Sequenter, что позволяет создавать приложения, использующие формат данных dBase, с помощью практически любого средства разработки, поддерживающего один из этих механизмов доступа к данным. Paradox был разработан компанией Ansa Software, первая его версия увидела свет в 1985 г. Этот продукт был впоследствии приобретен компанией Borland International. В настоящее время он принадлежит компании Corel и является составной частью офисного пакета Corel Office Professional. Принцип хранения данных в Paradox сходен с принципами хранения данных в dBase: каждая таблица хранится в своем файле (расширение *.db), MEMO- и BLOB-поля хранятся в отдельном файле (расширение *.md) так же, как и индексы (расширение *.рх). Однако, в отличие от dBase, формат данных Paradox не является открытым, поэтому для доступа к данным в этом формате требуются специальные библиотеки. Отсутствие «открытости» формата данных имеет свои достоинства. Так как доступ к данным осуществляется только с помощью «знающих» этот формат библиотек (или средств, включенных в саму СУБД), простое редактирование подобных данных, по сравнению с данными открытых форматов типа dBase, существенно затруднено. В этом случае возможны такие недоступные при использовании «открытых» форматов данных сервисов, как защита таблиц и отдельных полей паролем, хранение некоторых правил ссылочной целостности в самих таблицах. Эти сервисы предоставляются Paradox начиная с первых версий продукта. По сравнению с аналогичными версиями dBase ранние версии Paradox обычно предоставляли разработчикам баз данных существенно более широкие возможности, например: · использование деловой графики в DOS-приложениях; · обновление данных в приложениях при многопользовательской работе; · визуальные средства построения запросов на основе интерфейса QBE; · средства статистического анализа данных; · средства визуального построения интерфейсов пользовательских приложений с автоматической генерацией кода на языке программирования PAL (Paradox Application Language). Текущие версии данной СУБД – Paradox 9 и 10 выпущены фирмой Corel. СУБД поставляется в двух вариантах: 1) Paradox 9 Standalone Edition предназначен для использования в качестве настольной СУБД и входит в пакет Corel Office Professional. 2) Paradox 9 Developer's Edition используют в качестве как настольной СУБД, так и средства разработки приложений и манипуляции данными в серверных СУБД. Обе версии содержат: · средства манипуляции данными Paradox и dBase; · средства создания форм, отчетов и приложений; · средства визуального построения запросов; · средства публикации данных и отчетов в Интернет и создания Web-клиентов; · Corel Web-сервер; · ODBC-драйвер для доступа к данным формата Paradox из Windows-приложений; · средства для доступа к данным формата Paradox из Java-приложений (JDBC-драйвер). Популярность этого продукта, как средства разработки, в последнее время заметно снизилась. Тем не менее, в мире эксплуатируется еще немало информационных систем, созданных с его помощью. Microsoft FoxPro и Visual FoxPro. FoxPro ведет свое происхождение от настольной СУБД FoxBase фирмы Fox Software. Разрабатывая FoxBase в конце 80-х годов, эта компания преследовала цель создать СУБД, функционально совместимую с dBase с точки зрения организации файлов и языка программирования, но существенно превосходящую ее по производительности. Одним из способов для достижения этой цели стала более эффективная организация индексных файлов, нежели в dBase, но по формату индексных файлов эти две СУБД несовместимы между собой. По сравнению с аналогичными версиями dBase, FoxBase и более поздняя версия этого продукта, получившая название FoxPro, предоставляли своим пользователям более широкие возможности такие, как использование деловой графики, генерация кода приложений, автоматическая генерация документации к приложениям и т.п. Впоследствии этот продукт был приобретен компанией Microsoft. Его последующие версии получили название Visual FoxPro. С каждой новой версией этот продукт оказывался все более и более интегрированным с другими продуктами Microsoft, в частности с Microsoft SQL Server. В состав Visual FoxPro в течение нескольких последних лет входят средства переноса данных FoxPro в Microsoft SQL Server и средства доступа к данным этого сервера из Visual FoxPro и созданных с его помощью приложений. Текущая версии Visual FoxPro 9.0 доступна в составе пакета Microsoft Visual Studio 2017. Отличительной особенностью этой настольной СУБД является интеграция этого продукта с технологиями Microsoft, в частности поддержка технологии COM (англ. Component Object Model – модель компонентного объекта) – это технологический стандарт от компании Microsoft, предназначенный для создания программного обеспечения на основе взаимодействующих компонентов объекта, каждый из которых может использоваться во многих программах одновременно. Visual FoxPro 9.0 предоставляет следующие возможности: · средства публикации данных в Интернет и создания Web-клиентов; · средства создания ASP-компонентов и Web-приложений; · средства разработки СОМ-объектов, позволяющих создавать масштабируемые многозвенные приложения для обработки данных; · средства доступа к данным серверных СУБД, базирующиеся на использовании OLE DB (набор СОМ-интерфейсов, позволяющий осуществить унифицированный доступ к данным из разнообразных источников); · средства доступа к данным Microsoft SQL Server и Oracle, включая возможность создания и редактирования таблиц, триггеров, хранимых процедур; · средства отладки хранимых процедур Microsoft SQL Server; · средство визуального моделирования компонентов и объектов, являющихся составными частями приложения, – Visual Modeler; · средство для управления компонентами приложений, позволяющее осуществлять их повторное использование. Microsoft Access. Первая версия СУБД Access появилась в начале 90-х годов. Это была первая настольная реляционная СУБД для 16-разрядной версии Windows. Популярность Access значительно возросла после включения этой СУБД в состав пакета Microsoft Office. В отличие от Visual FoxPro, фактически превратившейся в средство разработки приложений, СУБД Access ориентирована в первую очередь на пользователей Microsoft Office, не знакомых с программированием. В этой СУБД вся информация, относящаяся к конкретной базе данных, а именно таблицы, индексы (естественно, поддерживаемые), правила ссылочной целостности, бизнес-правила, а также формы и отчеты хранится в одном файле. Последняя версия этой СУБД – Access 2018, входит в состав пакета Microsoft Office 2018, a также доступна как отдельный продукт. В состав Access 2018 входят средства: · манипуляции данными Access и данными, доступными через интерфейс ODBC (последние могут быть «присоединены» к базе данных Access); · создания форм, отчетов и приложений; при этом отчеты могут быть экспортированы в формат Microsoft Word или Microsoft Excel, а для создания приложений используется Visual Basic for Applications, общий для всех составных частей Microsoft Office; · публикации отчетов в Web; · создания интерактивных Web-приложений для работы с данными (Data Access Pages); · доступа к данным серверных СУБД; · создания клиентских приложений для Microsoft SQL Server; · администрирования Microsoft SQL Server. Поддержка COM в Microsoft Access выражается в возможности использовать элементы управления ActiveX в формах и Web-страницах, созданных с помощью Access. В отличие от Visual FoxPro создание СОМ-серверов с помощью Microsoft Access не предполагается. Иными словами, Microsoft Access может быть использован, с одной стороны, в качестве настольной СУБД и составной части офисного пакета, а с другой – в качестве клиента Microsoft SQL Server, позволяющего осуществлять его администрирование, манипуляцию его данными и создание приложений для этого сервера. Помимо манипуляции данными Microsoft SQL Server, Access 2018 позволяет также в качестве хранилища данных использовать Microsoft Data Engine (MSDE), представляющий собой по существу настольный сервер баз данных, совместимый с Microsoft SQL Server. Несмотря на то, что Access является настольной СУБД, он содержит в себе многие возможности СУДБ архитектуры клиент/сервер, называемых также SQL базами данных. При этом использование Access не сложно, поскольку имеется достаточно большой набор мастеров и надстроек. Access специально спроектирован для создания многопользовательских приложений, где файлы баз данных являются разделяемыми ресурсами сети. В нем реализована надежная защита от несанкционированного доступа к файлам баз данных. Access имеет собственную уникальную структуру для хранения всех своих объектов в одном файле. Имеет возможность импорта и экспорта данных во многие широко распространенные форматы баз данных (dBASE, FoxPro, Paradox), электронных таблиц и текстовых файлов. Кроме того, Access поддерживает стандарт открытого доступа к данным (Open Database Connectivity) Oracle, Microsoft SQL Server, DB2, Sybase SQL Server. |