распознанный текст 1. Теория баз данных Общие понятия
 Скачать 283.55 Kb. Скачать 283.55 Kb.
|

|
СОТРУДНИК АВТОМОБИЛЬ СЛУЖЕБНЫЙ-АВТОМОБИЛЬ ОБЩЕЖИТИЕ СТУДЕНТ ОБЩЕЖИТИЕ-СТУДЕНТ СТУДЕНТ  СТУДЕНТ-КЛУБ КЛУБ Рис. 6.12. Три типа бинарных связей В связи типа 1 :N (один к N, или один ко многим) экземпляр сущности одного типа связан со многими экземплярами сущности другого типа. В нашем примере таким типом связи является связь ОБЩЕЖИТИЕ-СТУДЕНТ, где единичный экземпляр сущности класса ОБЩЕЖИТИЕ связан со многими экземплярами сущности класса СТУДЕНТ, то есть в общежитии может проживать много студентов, но каждый студент живет только в одном общежитии. Позиции, в которой стоят символы 1 и N, имеют значение. Единица стоит на той стороне связи, где располагается ОБЩЕЖИТИЕ, a N— на той, где располагается СТУДЕНТ. Если бы символы 1 и N располагались наоборот (N: 1), получилось бы, что в общежитии живет один студент, причем каждый студент живет в нескольких общежитиях. Это, разумеется, не так. Третьем типом бинарной связи является связь N:M (читается N к М, или многие ко многим). В нашем примере это связь СТУДЕНТ-КЛУБ, связывающая экземпляры сущностей класса СТУДЕНТ с экземплярами сущностей класса КЛУБ. Один студент может быть членом нескольких клубов, а в одном клубе может состоять много студентов. Числа внутри ромба, символизирующего связь, обозначают максимальное количество сущностей на каждой стороне связи. Эти ограничения называются максимальными кардинальными числами, а совокупность из двух таких ограничений для обеих сторон связи называется максимальной кардинальностью связи. Преимущества ER-моделирования Исключительная концептуальная простота. ER-модель дает очень простое и наглядное представление об основных логических объектах БД и существующих между ними связях, поэтому использование такой модели значительно упрощает разработку и организацию сложных баз данных. Наглядное представление. ER-модель дает проектировщикам баз данных, программистам и конечным пользователям простое наглядное представление о данных и связях между ними. Поэтому ER-модель является чрезвычайно эффективным средством, интегрирующим различные представления о данных в единую рабочую среду. Хорошая интеграция с реляционной моделью данных. ER-модель хорошо интегрируется с реляционной моделью БД. Такая интеграция помогает эффективно структурировать процесс проектирования реляционных БД. Недостатки ER-моделирования Недостаточные возможности представления ограничений. С помощью ER-mo- дели легко изобразить ограничения, имеющие непосредственное отношение к связности. Например, ограничение «автор может работать над несколькими книгами, или более чем над одной книгой, но не более чем над тремя книгами» легко изображаются средствами ER-модели. Однако некоторые ограничения, например, «оплата автору может варьироваться в диапазоне от 4 до 25 %» или «автор не имеет права работать больше 10 часов подряд», в ER-модели представить невозможно, и они должны обрабатываться на уровне приложений. Ограниченные возможности представления отношений. Связи представляются как нечто, происходящее между сущностями. Поэтому связи между атрибутами внутри сущностей не могут быть представлены средствами ER-модели. Отсутствие языка манипулирования данными. Сторонники реляционной модели обычно указывают на отсутствие команд манипулирования данными в ER- модели. Отсутствие таких команд делает ER-модель «неполной». Утеря информационного наполнения. ER-модель сильно «переполнится», если в ней отобразить все ее атрибуты. Поэтому проектировщики баз данных обычно избегают полного отображения атрибутов, таким образом, сужая информационное наполнение ER-модели. ВНИМАНИЕ Все сказанное о недостатках ER-модели верно лишь в отношении теоретической модели. В современных средствах моделирования данных (таких как программа ErWin Data Modeler) применяется расширенная ER-модель, практически лишенная всех перечисленных недостатков. Реляционные базы данных 6.3.1. Реляционная модель данных Наиболее популярным сейчас типом баз данных являются так называемые реляционные базы данных. Реляционная модель данных была, предложена Е. Ф. Коддом (Е. F. Codd), известным исследователем в области баз данных, в 1969 г., когда он был сотрудником IBM. Реляционная база данных представляет собой хранилище данных, содержащее набор двухмерных таблиц. Набор средств для управления подобным хранилищем называется реляционной системой управления базами данных (РСУБД). РСУБД может содержать утилиты, приложения, сервисы, библиотеки, средства создания приложений, и др. Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями). В данном разделе используются обе пары терминов. Строки таблицы содержат сведения (факты) об однотипных объектах: документах, людях и пр. На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам: каждое значение в ячейке, находящейся на пересечении строки и столбца, должно быть атомарным, то есть не расчленяемым на несколько значений; значения данных в одном и том же столбце должны принадлежать одному и тому же типу, доступному для использования в данной СУБД; каждая запись в таблице уникальна, то есть в таблице не существует двух записей с полностью совпадающим набором значений ее полей; каждое поле имеет уникальное имя; последовательность полей в таблице несущественна; последовательность записей в таблице несущественна. Несмотря на то что строки таблиц считаются неупорядоченными, любая система управления базами данных позволяет сортировать строки и столбцы. Так как последовательность столбцов в таблице несущественна, обращение к ним производится по имени, и эти имена для данной таблицы уникальны. Для того чтобы база данных (или система управления базой данных) была полностью реляционной, она должна соответствовать 12 правилам Кодда. Правила Кодда Автор реляционной модели данных, Е. Ф. Кодд, в 1985 г. опубликовал статью, в которой сформулировал 12 правил реляционной базы данных. Правило информации. Вся информация реляционной базы данных на логическом уровне в полной мере представляется только одним способом — значениями в таблицах. ПОЯСНЕНИЕ Не только данные, но и отношения между таблицами или ограничения должны быть представлены в виде значений в таблицах. Правило гарантированного доступа. Гарантируется, что каждый элемент данных (атомарное значение) реляционной базы данных логически доступен через комбинацию из имени таблицы, значения первичного ключа и имени столбца. ПОЯСНЕНИЕ В наборе из 12 правил нет явного указания, что каждая строка в таблице должна иметь уникальный первичный ключ. Однако правило 2 неявным образом говорит об этом: ни одна таблица не может соответствовать правилу гарантированного доступа, если в ней нет первичного ключа. Правило систематической трактовки значений null. Значения null (заметим, что они отличаются как от пустой строки символов, так и от строки пробелов) поддерживаются в полностью реляционной СУБД для представления отсутствующей информации систематически и независимо от типа данных. ПОЯСНЕНИЕ Во-первых, база данных должна поддерживать значения null для обозначения того, что атомарные данные являются неизвестными (null — это не 0, не пустая строка и не пробел); во-вторых, в базе данных должно быть общее правило, определяющее, как обрабатывать значения null (например, каким образом трактовать их при выполнении запросов с выборкой по полю, содержащему такие значения). Правило наличия динамического оперативного каталога на основе реляционной модели. Описание базы данных представляется на логическом уровне так же, как обычные данные, значит, уполномоченные пользователи могут применять для обращения к этому описанию тот же самый реляционный язык, что и для работы с обычными данными. Правило наличия исчерпывающего подъязыка данных. Реляционная система может поддерживать несколько языков и различных режимов работы с устройствами ввода-вывода, однако должен существовать по меньшей мере один язык, операторы которого точно отражают реляционную модель с вполне определенными синтаксическими конструкциями в виде строк , символов и с исчерпывающей поддержкой следующего: О описания данных; О описания представлений; О манипуляций данными; О ограничений целостности; О границ транзакций (начала, завершения и отката). Правило обновления представлений. Все представления, обновляемые теоретически, должны обновляться практически. Правило ввода, обновления и удаления данных на высоком уровне. Возможность работы с базовым или производным отношением в качестве одного операнда применима не только к считыванию, но и к вводу, обновлению и удалению данных. ПОЯСНЕНИЕ Это правило определяет возможность в одной команде выполнить операцию сразу над несколькими строками данных. Правило физической независимости данных. Прикладные программы и терминальные операции остаются логически неповрежденными при любом изменении области хранения информации или механизма доступа. ПОЯСНЕНИЕ Это правило подразумевает возможность переноса физических данных из одного каталога (раздела, диска, компьютера) в другой без изменения способа взаимодействия пользователей и пользовательских приложений с таблицами базы данных. Правило логической независимости данных. Прикладные программы и терминальные операции остаются логически неповрежденными при внесении в базовые таблицы любого рода изменений, со- храняющих информацию и теоретически допускающих возможность оставить информацию неповрежденной. ПОЯСНЕНИЕ Добавление таблицы к схеме базы данных или столбца к схеме таблицы не должно оказать никакого влияния на уже работающие прикладные программы, поскольку такое действие не уничтожает (а сохраняет) информацию. В случае удаления таблицы или столбца сохранение информации, а значит, и работоспособность прикладных программ не гарантируется. Правило независимости целостности. При помощи подъязыка реляционных данных должна существовать возможность описания ограничений целостности, специфичных для конкретной реляционной базы данных, и сохранения их в каталоге, а не в прикладных программах. Для этого должны соблюдаться как минимум два ограничения: О сущностная целостность: ни один из компонентов первичного ключа не может принимать значения null; О ссылочная целостность: для каждого значения внешнего ключа, отличного от других и не являющегося значением null, в реляционной базе должно существовать соответствующее значение первичного ключа из того же домена. Правило независимости распределения. В реляционной СУБД распределение независимо. ПОЯСНЕНИЕ Распределенная база данных с точки зрения пользователя не должна отличаться от централизованной. Правило соблюдения правил {запрет обхода правил). Если в реляционной системе имеется язык низкого уровня («одна запись за раз»), его нельзя использовать для нарушения или пропуска правил или ограничений целостности, установленных в реляционном языке более высокого уровня («несколько записей за раз»). Ключи и связи Рассмотрим стандартную для современных информационных систем задачу построения базы данных, которая содержит в себе информацию о клиентах и сделанных ими заказах (покупках). Самое первое решение:, каждый раз, когда клиент делает заказ, делать об этом одну запись в базу данных. Схема этой записи могла бы выглядеть так, как показано на рис. 6.13. В  Номер заказа Имя клиента Адрес заказа Адрес отгрузки Контактный адрес Номер счета Дата заказа Дата отгрузки Дата оплаты Товар 1 Товар 2 Товар 3 Товар 4 Рис. 6.13. Схема таблицы Клиенты и заказы этой таблице будет множество записей. Все поля в записях могут принять одинаковые значения (даже номер счета, поскольку один и тот же клиент может сделать два идентичных заказа, и их впишут в один счет). Значит, для того чтобы обеспечить уникальность каждой записи в таблице, необходимо иметь поле, в котором значения никогда не повторяются. Если в данной фирме принята сквозная уникальная нумерация заказов, мы можем в качестве уникального идентификатора выбрать номер заказа. В случае, если это не так, мы можем в качестве уникальной метки для записи добавить еще одно поле, значения в котором будут уникальными. •  этотле, этотле,ния первичного т$>*ш щт&шы. Проведя моделирование процесса добавления заказов в таблицу, мы можем понять, что такая схема записей является несовершенной: сколько бы позиций товаров мы не внесли, клиент все равно может заказать их больше. Если же мы в схеме предусмотрим заведомо избыточное количество позиций товаров, то получим совершенно нечитабельную запись и такую таблицу, в которой при каждом добавлении заказа будет дублироваться большое количество незаполненных полей. Избавиться от такого рода несовершенства можно за счет создания связи между таблицами (в нашем случае — связи один ко многим). Произведя разделение схемы таблицы на две, одна из которых содержит сведения о сделанном заказе, а другая — о каждом заказанном товаре, мы свяжем эти таблицы между собой при помощи связи один ко многим (на рис. 6.14 это линия с цифрой 1 около одного конца и значком бесконечности около другого). С Номер заказа Имя клиента Адрес заказа Адрес отгрузки Контактный адрес Номер счета Дата заказа Дата отгрузки Дата оплаты  qq Номер позиции Номер заказа Описание Количество штук Цена за штуку Общая стоимость  Рис. 6.14. Связь один ко многим вязь один ко многим связывает один оформленный заказ с набором товаров, входящих в заказ, через поле Номер заказа. При этом в таблице Клиенты и заказы это поле является первичным ключом. В таблице же Заказанные товары это поле выступает в роли внешнего ключа, то есть ключа, через который осуществляется связь между набором товаров и конкретным заказом. Выбрав в таблице Заказанные товары все записи, в которых значения внешнего ключа совпадают, можно получить набор записей, относящихся к одному заказу. Первичным ключом таблицы Заказанные товары является поле Номер позиции. Ссылочная целостность Как уже отмечалось, первичный ключ любой таблицы должен содержать уникальные непустые значения для данной таблицы. Это утверждение является одним из правил ссылочной целостности (referential integrity). Практически все современные СУБД контролируют уникальность первичных ключей. При попытке присвоить первичному ключу значение, уже имеющееся в другой записи, СУБД генерирует диагностическое сообщение, обычно содержащее словосочетание primary key violation (нарушение первичного ключа). Если две таблицы связаны соотношением один ко многим, внешний ключ второй таблицы должен содержать только те значения, которые уже имеются среди значений первичного ключа первой таблицы. Современные СУБД отслеживают попытки удалить запись в первой таблице, если во второй таблице есть связанные с ней записи, препятствуя этому и генерируя диагностические сообщения. Если бы этого не происходило, со временем вторая таблица переполнилась бы записями, не связанными ни с одной записью в первой таблице (а значит, попросту бесполезными). Нормализация данных Нормализация представляет собой процесс приведения таблиц к виду, позволяющему осуществлять непротиворечивое и корректное редактирование данных. Первая нормальная форма Вернемся к таблице Клиенты и заказы. Структура этой таблицы показана на рис. 6.15. Номер заказа Имя клиента Адрес заказа Адрес отгрузки Контактный адрес Номер счета Дата заказа Дата отгрузки Дата оплаты Рис. 6.15. Таблица Клиенты и заказы в первой нормальной форме Чтобы таблица соответствовала первой нормальной форме, все значения ее полей должны быть атомарными и все записи — уникальными. Таблица Клиенты и заказы соответствует этим требованиям, как и любая другая реляционная таблица. Однако она, несмотря на выделение из нее таблицы с заказанными товарами, остается в значительной степени избыточной. На самом деле каждый раз, добавляя в таблицу очередной заказ от одного и того же клиента, мы многократно дублируем множество сведений. Это, в свою очередь, может привести к некоторым негативным последствиям: до тех пор, пока клиент не сделал хотя бы один заказ, сведения о нем не появятся в базе данных; при удалении последней записи о заказанном товаре из базы исчезают все сведения о клиенте; при изменении клиентом адреса в базе могут оказаться две записи с разными адресами одного и того же клиента. Некоторые из этих проблем могут быть решены путем приведения таблиц данных ко второй нормальной форме. Вторая нормальная форма Реляционная таблица находится во второй нормальной форме, если она находится в первой нормальной форме и ее неключевые поля полностью зависят от всего первичного ключа. Получить вторую нормальную форму можно, разделив таблицу Клиенты и заказы еще на несколько таблиц. При этом поля разносятся таким образом, чтобы полностью зависеть от первичного ключа соответствующей таблицы (рис. 6.16). 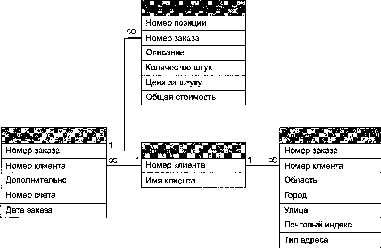 Рис. 6.16. Таблица Клиенты и заказы во второй нормальной форме Третья нормальная форма Итак, таблица Клиенты и заказы превратилась у нас в группу связанных таблиц. Благодаря упорядоченности связей в схеме появилась логика: в центре теперь клиент, с которым связаны его заказы и адреса. В свою очередь, с заказами связаны заказанные товары. Но и эта схема все еще не соответствует третьей нормальной форме. Происходит это потому, что в таблице Заказанные товары есть поле Общая стоимость. Это поле получено в результате произведения значений полей Количество штук и Цена за штуку. База данных находится в третьей нормальной форме, если она находится во второй нормальной форме и все поля ее сущностей не зависят друг от другаI. Таким образом, чтобы привести полученную группу объектов к третьей нормальной форме, нужно удалить из таблицы Заказанные товары поле Общая стоимость. Язык SQL Математическая реляционная модель данных предполагает, что для манипуляций с данными и сущностями должна использоваться одна из специальных алгебр — реляционная. Для реализации операций реляционной алгебры в СУБД был разработан специальный язык SQL (Structured Query Language — структурированный язык запросов). SQL является декларативным языком программирования. В отличие от процедурных языков программирования, SQL определяет не последовательность процедур, а условия выполнения запроса. При этом запросы могут быть объемом с простую программу на процедурном языке программирования (от одной строки до нескольких страниц). Язык SQL содержит несколько групп операторов. Операторы манипулирования данными Операторы манипулирования данными позволяют производить извлечение, добавление, изменение и удаление данных. В группу входят следующие операторы: SELECT — оператор извлечения данных. Пример: |