Учебник для вузов Общие сведения Аппаратное обеспечение
 Скачать 5.31 Mb. Скачать 5.31 Mb.
|

| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 |
| Рис. 1.13 Диаграмма стереозвука в музыкальном редакторе (верхняя ось – время от 20,854 до 20,856 сек., т. е. 0,002 сек.) |
Каждому измерению присваивается числовое значение амплитуды. Количество измерений в секунду называется частотой выборки (sampling rate). Количество возможных значений амплитуды называется точностьювыборки (sampling size). Таким образом, звуковая волна представляется в виде ступенчатой кривой. Ширина ступеньки тем меньше, чем больше ча- стота выборки, а высота ступеньки тем меньше, чем больше точность вы- борки.
Возможности наиболее распространённой современной аппаратуры предусматривают работу с частотой выборки до 48 кГц (48 тысяч раз в се- кунду!), что позволяет правильно описывать звук частотой до 22,05 кГц.
Непрерывная звуковая волна разбивается на отдельные участки по времени, для каждого устанавливается своя величина амплитуды. Каждой
ступеньке присваивается свой уровень громкости звука, который можно рассматривать как набор возможных состояний.
Характеристикикачествазвука
Точность выборки или глубина кодирования звука – количество бит на одно измерение величины звукового сигнала.
Современные звуковые карты обеспечивают 16-битную глубину ко- дирования звука. Количество уровней (градаций амплитуды) можно рас- считать по формуле:
N = 2I = 216 = 65 536 уровней сигнала (градаций амплитуды)
Частота выборки или частота дискретизации – это количе- ство измерений уровня звукового сигнала за 1 секунду.
Одно измерение в 1 секунду соответствует частоте 1 Гц. 1000 измерений в 1 секунду - 1 кГц.
Количество измерений может лежать в диапазоне от 8000 до 48 000
(8 кГц – 48 кГц).
8 кГц соответствует частоте радиотрансляции, 48 кГц – качеству звучания аудио-CD.
Опыт показывает, что точное соответствие цифрового сигнала анало- говому достигается, если частота дискретизации будет вдвое выше макси- мальной звуковой частоты, то есть составит не менее 40 кГц.
На практике значения частоты дискретизации, применяемые в звуко- вых системах, равны 44,1 кГц или 48 кГц.
Чем больше частота дискретизации, тем качественнее звук.
Для характеристики сжатого звука и видео используется понятие битрейт – количество единиц информации, необходимых для хранения или передачи одной секунды потока данных. Величина измеряется в кило- битах в секунду (kbps). Битрейт характеризует как плотность упаковки ин- формации, так и её качество. Например, из двух MP3 файлов сжатых с раз- ным битрейтом, более качественный (близкий к оригиналу) звук будет у файла с большим битрейтом. В тоже время, файл другого формата, при равном битрейте, может дать как лучшее, так и худшее качество звука. Стандартов кодирования двухканальной и многоканальной (5.1 и 7.1) аудиоинформации насчитывается несколько десятков, наименования неко- торых из них, используемых в современных методах записи мультимедиа- информации, приведены далее в таблице 1.4.
Кодирование видеоинформации
Видеоинформация – наиболее сложный вид для хранения, обработки и воспроизведения. Впервые движущиеся изображения были сохранены на кинопленке в виде большого количества отдельных кадров изображения, заснятых через небольшие промежутки времени (24 кадра в секунду). Позднее на ту же пленку стала записываться и звуковая дорожка (в после- дующем несколько дорожек для многоканального звука). Далее появилось телевидение с аналоговой записью движущегося изображения на магнит- ные ленты (системы телевидения PAL и SECAM используют 25 кадров в секунду, система NTSC – 29,97 кадров в секунду). С появлением компью- теров широкое распространение получили цифровые методы записи и ко- дирования видеоинформации, которые постоянно совершенствуются. В настоящее время каждый может записать видео с использованием мобиль- ных телефонов, цифровых фото- и видеокамер и выполнить монтаж ви- деофильма на персональных компьютерах, производительности которых достаточно для перекодирования видео высокого разрешения объемом в несколько гигабайт (но продолжительность кодирования может составлять несколько часов).
Компьютерные цифровые методы кодирования видео могут исполь- зовать частоту телевизионных стандартов PAL/SECAM или NTSC, т. к. видеозаписи многих цифровых форматов могут воспроизводиться как спе- циальными компьютерными программами, так и бытовыми DVD- плеерами, а также путем подключения телевизора к компьютеру (для пе- редачи видео и звука следует использовать порт HDMI).
Качество видеоизображения в цифровых методах постоянно улучша- ется. Широкое распространение цифрового видео было связано с появле- ние вначале CD-дисков, затем DVD, далее Blu-Ray дисков, на которых, в основном, и распространялись кинофильмы, и емкостью которых ограни- чивались качественные возможности. В таблице 1.4 приведены характери- стики некоторых видеоформатов.
Стандарты кодирования видео разрабатываются группой экспертов в области цифрового видео MPEG (Moving Picture Experts Group) Междуна- родной Организацией по Стандартизации (ISO). Первый стандарт MPEG-1 был представлен в 1992 г., последние стандарты в этой области – MPEG-7 и MPEG-21.
Алгоритмы кодирования видео очень сложны, их описания можно найти в специальной литературе или на сайте http://www.mpeg.org.
Таблица 1.4. Сравнение форматов записи видео на диски
| Формат | Разрешение, PAL / NTSC | Стандарт кодирования | Совместимость с DVD-плеером | ||
| видео | аудио | ||||
| VCD | 352×288 352×240 | MPEG-1 | MPEG-1 | всегда | |
| SVCD | 480×576 480×480 | MPEG-2 | MPEG-1 | иногда | |
| DVD | 720×576 720×480 | MPEG-2 | MPEG-1, AC3 | всегда | |
| XVCD | 720×576 720×480 | MPEG-1 или MPEG-2 | MPEG-1 | иногда | |
| DivX | 640×480 | MPEG-4 | MP3, WMA | иногда | |
| HD 720p | 1280×720 | MPEG-4 H.264 | MP3, WMA, AC3 или др. | BD-плеер | |
| HD 1080i | 1920×1080 (i – чересстрочная развертка) | MPEG-4 H.264 | MP3, WMA, AC3 или др. | BD-плеер | |
| AVCHD 720p | 1280×720 (p – прогрессивная развертка) | MPEG-4 v.10 (AVC/H.264) | PCM (7.1) или AC3 (5.1) | нет | |
| AVCHD 1080i | 1920×1080 | MPEG-4 v.10 (AVC/H.264) | PCM (7.1) или AC3 (5.1) | нет | |
| UHD-1 4K (2160p) | 3840×2160 | H.264/ H.265 (HEVC) | AC3 (5.1) или стандарт 22.2 | нет | |
| UHD-2 8K (4320p) | 7680×4320 | H.264/ H.265 (HEVC) | AC3 (5.1) или стандарт 22.2 | нет | |
Все форматы сжатия семейства MPEG (MPEG-1, MPEG-2, MPEG-4, MPEG-7) используют высокую избыточность информации в изображени- ях, разделенных малым интервалом времени. Между двумя соседними кадрами обычно изменяется только малая часть сцены – например, проис- ходит плавное смещение небольшого объекта на фоне фиксированного заднего плана. В этом случае полная информация о сцене сохраняется вы- борочно – только для опорных кадров. Для остальных кадров достаточно передавать разностную информацию: о положении объекта, направлении и величине его смещения, о новых элементах фона, открывающихся за объ- ектом по мере его движения. Причем эти разности можно формировать не только по сравнению с предыдущими изображениями, но и с последую-
щими (поскольку именно в них по мере движения объекта открывается ра- нее скрытая часть фона).
Алгоритмы MPEG сжимают только опорные кадры – I-кадры (Intra frame – внутренний кадр). В промежутки между ними включаются кадры, содержащие только изменения между двумя соседними I-кадрами – P- кадры (Predicted frame – прогнозируемый кадр). Для того чтобы сократить потери информации между I-кадром и P-кадром, используются B-кадры (Bidirectional frame – двунаправленный кадр). В них содержится информа- ция, которая берется из предшествующего и последующего кадров.
MPEG-4 использует технологию фрактального сжатия изображений. Фрактальное (контурно-основанное) сжатие подразумевает выделение из изображения контуров и текстур объектов. Контуры представляются в ви- де сплайнов (полиномиальных функций) и кодируются опорными точками. Текстуры могут быть представлены в качестве коэффициентов простран- ственного частотного преобразования (например, дискретного косинусно- го или вейвлет-преобразования).
Новые версии MPEG-4 – AVC/H.264 (Advanced Video Codec, назы- ваемый также H.264) – стандарт, предназначенный для значительного сжа- тия видеопотока при сохранении высокого качества и AVCHD (Advanced Video Codec High Definition – улучшенный видеокодек для видео высокого разрешения) – цифровой формат записи видеоданных в форматах 720p или 1080i и многоканального звука. Стандарт AVCHD был разработан сов- местно компаниями Sony и Panasonic в 2006 году. За основу был взят кодек AVC/H.264.
В октябре 1996 года группа MPEG приступила к разработке формата сжатия MPEG-7, призванным определить универсальные механизмы опи- сания аудио и видео информации. Этот формат получил название «Муль- тимедиа-интерфейс для описания содержимого» (Multimedia Content Description Interface). В отличие от предыдущих форматов сжатия семей- ства MPEG, MPEG-7 описывает информацию, представленную в любой форме (в том числе в аналоговой) и не зависит от среды передачи данных.
Формат сжатия MPEG-7 использует развитую многоуровневую структуру описаний аудио и видео информации га основе языка этих опи- саний. Существуют различные типы информации, для которых разработа- ны схемы описания базовых структур: низкоуровневые аудио-визуальные характеристики, такие как цвет, текстура, движение, уровень звука и т.д.; высокоуровневые семантические объекты, события и абстрактные прин- ципы; описание содержимого, навигации и доступа к аудио-визуальному материалу и т. д. Одной из отличительных особенностей MPEG-7 являет-
ся его способность к определению типа сжимаемой информации. Если это аудио или видео файл, то он сначала сжимается с помощью алгоритмов MPEG-1, MPEG-2, MPEG-4, а затем описывается при помощи MPEG-7.
Разработка формата MPEG-21 – долговременный проект, который называется «Система мультимедийных средств» (Multimedia Framework). Над разработкой этого формата эксперты начали работать в 2000 г. Задача разработки MPEG-21 может быть сформулирована следующим образом: определение технологии, необходимой для поддержки пользователей при обмене, доступе, продаже и других манипуляциях цифровыми объектами. При этом предполагается обеспечить максимальную эффективность и про- зрачность этих операций.
Форматы файлов Microsoft AVI и MKV – контейнеры, предназна- ченные для хранения видеоинформации, синхронизованной с аудиоин- формацией. AVI может содержать в себе потоки 4 типов – Video, Audio, MIDI, Text. Причем видеопоток может быть только один, тогда как аудио – несколько.
Контейнер MKV (Matroska, матрёшка) разрабатывался с учётом со- временных тенденций и возможных тенденций будущего. Он универсален, так как построен на принципе EBML (то же самое, что и XML, но для дво- ичных данных). В MKV можно поместить любое количество аудио- видеорядов, меню, как на DVD, главы, субтитры, шрифты, постеры, тек- сты, комментарии, описания, фотоальбомы и проч. Ограничений практиче- ски нет. Максимальная совместимость со всеми возможными требования- ми к видеоконтейнеру на данный момент и на ближайшее будущее. Ис- пользуется в настоящее время для переноса информации DVD и Blu-Ray дисков в один файл *.mkv с сохранением меню, выбора языка воспроизве- дения, показа субтитров на выбранном языке, показа сцен-фрагментов ос- новного фильма, рекламных роликов диска и пр.
Сжатие (архивация) различных видов информации
Дискретное двоичное представление информации обычно имеет не- которую избыточность. Часто в информации присутствуют последователь- ности одинаковых битов или их групп. Объём информации имеет большое значение не только для хранения, но также непосредственно влияет на скорость передачи информации по компьютерным сетям. Поэтому были разработаны специальные методы (алгоритмы) сжатия информации (data compression), с помощью которых можно существенно уменьшить ее объ- ём. Существуют как универсальные алгоритмы, которые рассматривают информацию, как простую последовательность битов, так и специализиро-
ванные, которые предназначены для сжатия информации определённого типа (изображений, текста, звука и видео).
Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является, бит, а максимальной – несколь- ко бит, байт или несколько байт.
Основными техническими характеристиками процессов сжатия и ре- зультатов их работы являются:
степень сжатия (compress rating) или отношение (ratio) объемов исходного и результирующего потоков;
скорость сжатия – время, затрачиваемое на сжатие некоторого объ- ема информации входного потока, до получения из него эквивалентного выходного потока;
качество сжатия – величина, показывающая, насколько сильно упа- кован выходной поток, при помощи применения к нему повторного сжатия по этому же или иному алгоритму.
Все способы сжатия можно разделить на две категории: обратимое и
необратимое сжатие.
Необратимое сжатие – такое преобразование входного потока ин- формации, при котором выходной поток, основанный на определенном формате информации, представляет собой объект, достаточно похожий по внешним характеристикам на входной поток, однако отличается от него объемом.
Степень сходства входного и выходного потоков определяется сте- пенью соответствия некоторых свойств объекта (до сжатия и после), пред- ставляемого данным потоком информации. Такие подходы и алгоритмы используются для сжатия информации растровых графических файлов, ви- део и звука. При таком подходе используется свойство структуры данного формата файла и возможность представить информацию приблизительно схожую по качеству для восприятия человеком. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходная информация в процессе сжатия изменяется. Под качеством мож- но понимать степень соответствия исходной и результирующей информа- ции, оцениваемое субъективно, исходя из формата информации. Для гра- фических файлов такое соответствие определяется визуально, хотя имеют- ся и соответствующие интеллектуальные алгоритмы и программы. Необ- ратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выход- ного потоков. Данный подход реализован в популярных форматах пред-
ставления фотоинформации – JPEG, TIFF, GIF, PNG и др., аудио инфор- мации – MP3, видео информации – MPEG-4.
Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. без потери информационной структуры.
Из выходного потока, при помощи восстанавливающего или деком- прессирующего алгоритма, можно получить входной, а процесс восстанов- ления называется декомпрессией или распаковкой и только после процесса распаковки информация пригодна для использования в соответствии с их внутренним форматом.
Способыобратимогосжатияинформации
Сжатие способом кодирования серий (RLE)
Наиболее известный простой подход и алгоритм сжатия информации обратимым путем – это кодирование серий последовательностей (Run Length Encoding – RLE).
Суть методов данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений.
Например:
44 44 44 11 11 11 11 11 01 33 FF 22 22 – исходная последовательность
03 44 04 11 00 03 01 33 FF 02 22 – сжатая последовательность.
Первый байт во второй последовательности указывает, сколько раз нужно повторить следующий байт.
Если первый байт равен 00, то затем идет счетчик, показывающий, сколько за ним следует неповторяющихся байт информации (00 03).
Данные методы, как правило, достаточно эффективны для сжатия растровых графических изображений (BMP, PCX, TIF, GIF), т.к. последние содержат достаточно много длинных серий повторяющихся последова- тельностей байтов. Недостатком метода RLE является достаточно низкая степень сжатия.
Алгоритм Хаффмана
Сжимая файл по алгоритму Хаффмана, первое, что необходимо сде- лать – прочитать файл полностью и подсчитать сколько раз встречается каждый символ из расширенного набора ASCII.
Если учитывать все 256 символов, то не будет разницы в сжатии тек- стового и EXE файла.
После подсчета частоты вхождения каждого символа, необходимо сформировать бинарное дерево для кодирования с учетом частоты вхож- дения символов.
Пример сжатия по алгоритму Хаффмана приведен ниже.
Пусть файл имеет длину 100 байт и в нем присутствуют 6 различных символов. Подсчитаем вхождение каждого из символов в файл и получим следующую таблицу:
| Символ | A | B | C | D | E | F |
| Число вхождений | 10 | 20 | 30 | 5 | 25 | 10 |
Отсортируем символы по частоте вхождения:
| Символ | C | E | B | F | A | D |
| Число вхождений | 30 | 25 | 20 | 10 | 10 | 5 |
Далее возьмем из последней таблицы 2 символа с наименьшей ча- стотой. В нашем случае это D (5) и F (10) или A (10), можно взять любой из них, например A.
Сформируем из «узлов» D и A новый «узел», частота вхождения для которого будет равна сумме частот D и A:

Номер в рамке – сумма частот символов A и D. Теперь мы снова ищем два символа с самыми низкими частотами вхождения. Исключая из просмотра D и A и рассматривая вместо них новый «узел» с суммарной ча- стотой вхождения. Самая низкая частота теперь у F и нового «узла». Снова сделаем операцию слияния узлов:
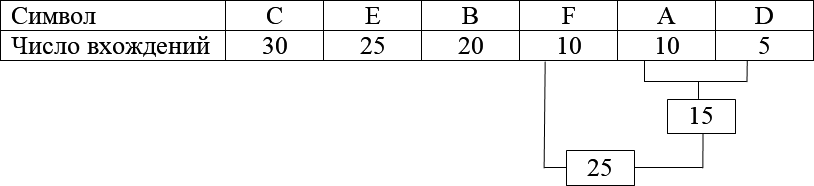
Просматриваем таблицу снова для следующих двух символов (B и E). Продолжаем этот режим пока все «дерево» не сформировано, т.е. пока все не сведется к одному узлу.
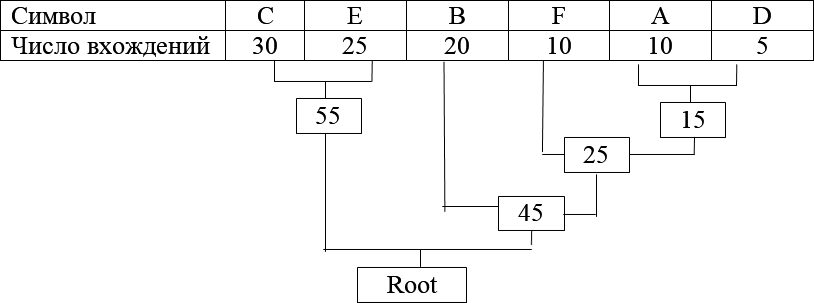
Теперь, когда наше дерево создано, можно кодировать файл. Мы должны всегда начинать из корня (Root). Кодируя первый символ (лист дерева С с наибольшей частотой), прослеживаем вверх по дереву все пово- роты ветвей и если делаем левый поворот, то запоминаем бит = 0, и анало- гично бит = 1 для правого поворота. Так для C, мы будем идти влево к 55 (и запомним 0), затем снова влево (0) к самому символу. Код Хаффмана для нашего символа C – 00. Для следующего символа (E) получается – ле- во, право, что выливается в последовательность 01. Выполнив эту проце- дуру для всех символов, получим:
C = 00 ( 2 бита) E = 01 ( 2 бита ) B = 10 ( 2 бита ) F = 110 ( 3 бита )
A = 1101 ( 4 бита ) D = 1111 ( 4 бита )
При кодировании заменяем символы на новые коды, при этом те символы, которые встречаются наиболее часто, имеют самые короткие ко- ды. Таблицу кодирования запоминаем в том же архивном файле для по- следующей разархивации.
Арифметическое кодирование
Совершенно иное решение предлагает так называемое арифметиче- ское кодирование. Арифметическое кодирование является методом, позво- ляющим упаковывать символы входного алфавита без потерь при условии, что известно распределение частот этих символов и является наиболее оп- тимальным, т.к. достигается теоретическая граница степени сжатия.
Каждый символ после кодирования представляется как некоторое дробное число из интервала [0, 1) с весом, пропорциональным вероятности его появления.
Алгоритм Лемпеля-Зива-Велча (Lempel-Ziv-Welch – LZW)
Данный алгоритм отличают высокая скорость работы как при упа- ковке, так и при распаковке, достаточно скромные требования к памяти и простая аппаратная реализация.
Недостаток – низкая степень сжатия по сравнению со схемой двух- ступенчатого кодирования.
Двухступенчатое кодирование. Алгоритм Лемпеля-Зива
Гораздо большей степени сжатия можно добиться при выделении из входного потока повторяющихся цепочек – блоков, и кодирования ссылок на эти цепочки с построением хеш-таблиц от первого до n-го уровня с по- следующим кодированием Хаффмена или арифметическим кодированием.
Метод принадлежит Лемпелю и Зиву и обычно называется LZ- compression.
Переченьпрограммсжатияскраткимуказаниемалгоритмовихработы
PKPAK:
Метод Packed – алгоритм RLE. Метод Crunched – алгоритм LZW.
Метод Squashed – двухпроходное статическое кодирование Хаффмена.
ZIP:
Метод Shrinked – модифицированный алгоритм LZW с частичной очист- кой словаря и переменной длиной кода.
Метод Imploded – модифицированный алгоритм Лемпеля-Зива и статиче- ское кодирование Хаффмена.
LHArc:
Алгоритм Лемпедя-Зива и динамическое кодирование Хаффмена.
LHA:
Алгоритм Лемпедя-Зива и статическое кодирование Хаффмена.
ARJ:
Алгоритм Лемпеля-Зива и оригинальный метод кодирования
WinRar:
Использование высокоэффективного оригинального алгоритма автора (А. П. Рошал).