ПЛЕЩ. Учебное пособие содержит
 Скачать 3.78 Mb. Скачать 3.78 Mb.
|

1.4. Модели использования баз данных в сети1.4.1. СетьСетью называют множество компьютеров и рабочих станций (РС), соединенных средствами передачи данных. Сети бывают локальные или корпоративные (ЛВС функционирует в пределах одной организации) и глобальные (в пределах города, региона, страны или нескольких стран). Управление сетью осуществляется пакетами сетевых программ или сете вой операционной системой (СОС). Стандартизация взаимодействия лю бых вычислительных систем обеспечивается протоколом OSI (X25), разра ботанным Междуна род ной ор га низацией по стандартизации ISO (International Organization for Stan dar dization). Этот протокол состоит из семи уровней: прикладной, пред ставительный, сеансовый, транспортный, сетевой, канальный и физи ческий. Любой уровень протокола может взаи модействовать только с со сед ними уровнями. Основные аппаратные компоненты ЛВС: рабочие станции (обычно персональные компьютеры), серверы (компьютеры, выполняющие функ ции распределения ресурсов и управления подключенных к ним PC), ин терфейсные платы (сетевые адаптеры) и кабели (коаксиальный кабель, “витая пара”, оптоволокно, беспроводные радиосети), источники бес пе ре бой ного питания, модемы, трансиверы, повторители, разъемы (коннек то ры, терминаторы и др.). Сетевые адаптеры имеют характеристики: тип ши ны подключаемого компьютера (ISA, EISA, Micro Channel и др.), разряд ность (8, 16, 32, 64, 128) и метод доступа к сетевому каналу данных (Ethernet линейная топология, Arcnet звездная, Token Ring (кольцевая)). Выделяются два основных класса топологий сети: широкове ща тель ный (каждый компьютер передает сигналы, восприни мае мы е другими ком пь ютерами) и последовательный (каждый физический подуровень пе ре дает данные одному компьютеру). Существуют два принципа управления в ЛВС: централизованный и децентрализованный. В централизованной сети несколько ПЭВМ яв ляют ся центральными (KC компьютер сервер), а остальные рабочими стан ция ми (РС). Наз на че ние KC: управление передачей и хранением дан ных. Сетевыми ОС, реа лизующими централизованное управление являются: Microsoft Windows NT Server, Microsoft Lan Manager, Novell NetWare, OS/2 Warp Server Advan ce, VINES 6.0 и др. Достоинства: защита от несанкционированного дос ту па, удобство уп равления сетью. Недостатки: низкая надежность и эффективность. В децентрализованной (линейной, одноранговой) сети нет КС. Функ ции управления сетью поочередно передаются от одного компьютера к другому. Основные программные средства управления такими сетями: Novel NetWare Lite, Windows for Workgroups, Windows 95/98, Artisoft LANtastic, LANsmart. Достоинства: надежность, простота, более низкая стоимость. Не достатки: слабая защита и плохое управление сетью. При работе в сети используются понятия “сервер” (компонент сети, предоставляющий пользователю-клиенту ресурсы сети: компьютер, фай лы, таблицы, печать и др.) и “клиент” (потре би тель ресурсов). 1.4.2. Модели использования баз данныхВообще существует несколько основных моделей использования баз данных (рисунок 1.4.2.1, содержание данного пункта скопировано из работы [19]). 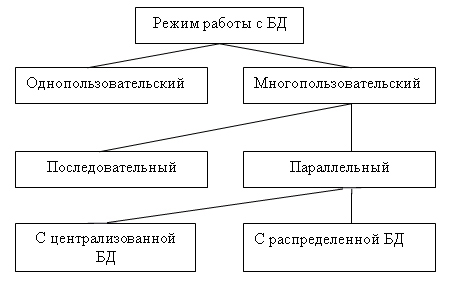 Рисунок 1.4.2.1 - Модели работы с базой данных 1.4.2.1. Локальная однопользовательская модельПри размещении БД на персональном компьютере, который не находится в сети, БД всегда используется в локальном режиме. Однако даже в некоторых настольных БД требуется учитывать последовательность изменения данных при обработке, чтобы получить корректный результат: так, например, при запуске программы балансного бухгалтерского отчета все бухгалтерские проводки — финансовые операции должны быть решены заранее до запуска конечного приложения. Дос тоинства: наличие большого числа готовых СУБД, простота. Не дос та ток: отсутствие возможности эффективной работы в многополь зо ва тель ском режиме. Рассмотрим далее многопользовательские модели 1.4.2.2. Файл-серверная модельБаза данных находится на другом компьютере, ко то рый называется файл сервером, и приложение обращается за информацией к файлу серверу (содержание данного пункта скопировано из работы [19]). В этой модели презентационная логика и бизнес-логика располагаются на клиенте (приложение). На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиенте. Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на клиенте. Запрос клиента формулируется в командах SQL. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации и т. д. Перекачка информации с сервера на клиент производится до тех пор, пока не будет получен ответ на запрос клиента. Достоинство: наличие большого числа СУБД и програм мных средств, работающих в этом режиме. Недостатки: высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению (пере груз ка каналов связи, так как большой объем не нужной информации копируется по каналам на клиентскую машину). Например, при выполнении запроса на поиск договора по его номеру, на клиентскую машину будут пересланы все записи таблицы с договорами; узкий спектр операций манипулирования с данными, который определяется только файловыми командами; отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы). Однако работа на изолированном компьютере с небольшой базой данных в настоящий момент становится уже нехарактерной для большинства приложений. БД отражает информационную модель реальной предметной области, она растет по объему и резко увеличивается количество задач, решаемых с ее использованием, и в соответствии с этим увеличивается количество приложений, работающих с единой базой данных. Компьютеры объединяются в локальные сети, и необходимость распределения приложений, работающих с единой базой данных по сети, является несомненной. Действительно, даже когда вы строите БД для небольшой торговой фирмы, у вас появляется ряд специфических пользователей БД, которые имеют свои бизнес-функции и территориально могут находиться в разных помещениях, но все они должны работать с единой информационной моделью организации, то есть с единой базой данных. Параллельный доступ к одной БД нескольких пользователей, в том случае если БД расположена на одной машине, соответствует режиму распределенного доступа к централизованной БД. (Такие системы называются системами распределенной обработки данных.) Если же БД распределена по нескольким компьютерам, расположенным в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенной БД. Подобные системы называются системами распределенных баз данных. Рассмотрим основные виды таких баз данных. 1.4.2.3. Клиент-серверная модельКлиент серверная(модель сервера БД, DBS Da taBase Server) от ли ча ет ся от предыдущей модели тем, что запросы в виде хранимых про цедур хранятся и выполняются на сер вере (СУБД Oracle, Ingress, Sybase. Содержание данного пункта скопировано из работы [19])). Основной принцип технологии «клиент–сервер» заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу: функции ввода и отображения данных (Presentation Logic); прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic); функции обработки данных внутри приложения (Database Logic); функции управления информационными ресурсами (Database Manager System – СУБД) ; служебные функции, играющие роль связок между функциями первых четырех групп. Структура типового приложения, работающего с базой данных приведена на рисунке 1.4.2.3.1. 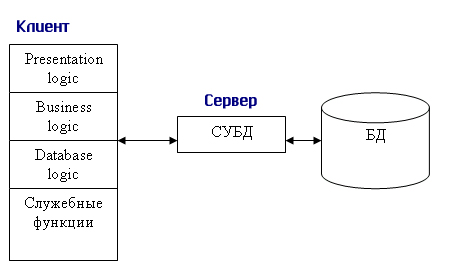 Рисунок 1.4.2.3.1 - Структура типового интерактивного приложения, работающего с базой данных Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, к этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация. Поэтому основными задачами презентационной логики являются: формирование экранных изображений; чтение и запись в экранные формы информации; управление экраном; обработка движений мыши и нажатие клавиш клавиатуры. Некоторые возможности для организации презентационной логики приложений предоставляет знако-ориентированный пользовательский интерфейс, задаваемый моделями CICS (Customer Control Information System ) и IMS/DC фирмы IBM и моделью TSO (Time Sharing Option) для централизованной main-фреймовой архитектуры. Модель GUI — графического пользовательского интерфейса, поддерживается в операционных средах Microsoft's Windows, Windows NT, в OS/2 Presentation Manager, X-Windows и OSF/Motif. Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как С, C++, C#, Сobol, SmallTalk, Visual Basic, Delphi. Логика обработки данных (Data manipulation Logic) – это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД (DBMS). Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL Обычно операторы языка SQL встраиваются в языки 3-го или 4-го поколения (3GL, 4GL), которые используются для написания кода приложения. СУБД обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения. В централизованной архитектуре (Host-based processing) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы. В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений (см. рис. 1.4.2.3.2): распределенная презентация (Distribution presentation, DP); удаленная презентация (Remote Presentation, RP); распределенная бизнес-логика (Remote business logic, RBL); распределенное управление данными (Distributed data management, DDM); удаленное управление данными (Remote data management, RDA). 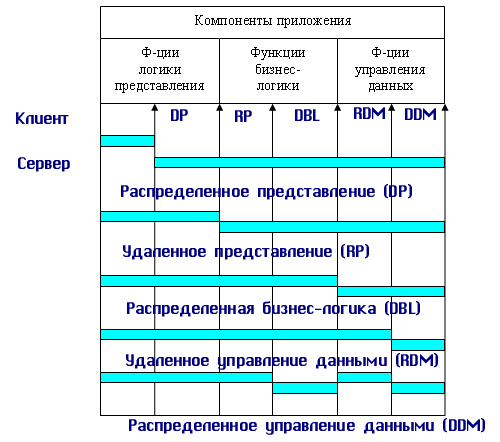 Рисунок 1.4.2.3.2 - Распределение функций приложения в моделях «клиент–сервер» 1.4.2.4. Модель удаленного доступа (RDA)В этой модели база данных хранится на сервере (содержание данного пункта скопировано из работы [19]). На сервере же находится ядро СУБД. На клиенте располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на рисунок 1.4.2.4.1. 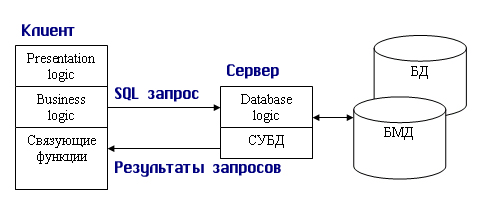 Рисунок 1.4.2.4.1 - Модель удаленного доступа (RDA) Преимущества данной модели. Перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД, сводя к минимуму общее число процессов в операционной системе. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным, если отказаться от терминалов, не располагающих ресурсами, и заменить их компьютерами, выполняющими роль клиентских станций, которые обладают собственными локальными вычислительными ресурсами. Резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, релевантные запросу, а не блоки файлов, как в файл–серверной модели. Централизованное управление разра боткой и вы пол нением приложения, уменьшение объемов пересылаемой инфор ма ции по сети. Основное достоинство RDA-модели – унификация интерфейса «клиент-сервер», стандартом при общении приложения-клиента и сервера становится язык SQL. Недостатки. Все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть. Так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование кода приложений; Сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте. Действительно, например, если нам необходимо выполнять контроль страховых запасов товаров на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаление товара со склада, должно выполнять проверку на объем остатка, и в случае, если он меньше страхового запаса, формировать соответствующую заявку на поставку требуемого товара. Это усложняет клиентское приложение, с одной стороны, а с другой — может вызвать необоснованный заказ дополнительных товаров несколькими приложениями. Ограниченные возможности храни мых про це дур, кото рые обычно разрабатываются на SQL. 1.4.2.5. Модель сервера данныхДля того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия (содержание данного пункта скопировано из работы [19]). 1. Необходимо, чтобы БД в каждый момент отражала текущее состояние предметной области, которое определяется не только собственно данными, но и связями между объектами данных. То есть данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми. 2. БД должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Например, завод может нормально работать только в том случае, если на складе имеется некоторый достаточный запас (страховой запас) деталей определенной номенклатуры, деталь может быть запущена в производство только в том случае, если на складе имеется в наличии достаточно материала для ее изготовления, и т. д. 3. Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них: например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры, при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара. 4. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи. 5. Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, то есть такие, которые определены в DDL (data definition language) — языке описания данных, который является частью SQL. Однако в реальных предметных областях у нас действуют данные, которые несут в себе еще и семантическую составляющую, например, это координаты объектов или единицы различных метрик, например рабочая неделя в отличие от реальной имеет сразу после пятницы понедельник. Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры. Модель сервера баз данных представлена на рис. 1.4.2.5.1. 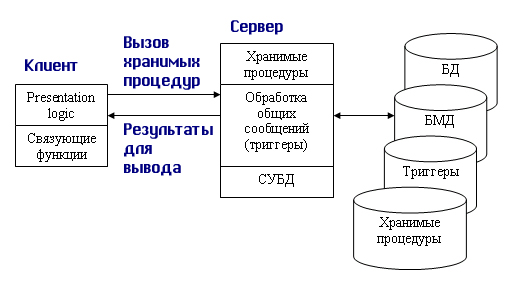 Рисунок 1.4.2.5.1 - Модель активного сервера БД В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается. Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД. Термин «триггер» характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры. Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров. В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что. существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так, называемый встроенный SQL (п. 1.8). Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции:
На сервер переложена часть бизнес-логики приложений и требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом», в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом». 1.4.2.6. Трехзвенная распределенная модельТрехзвенная распределенная модель(компонентная или AS модель сервера приложений Application Server) к серверам баз добавляются сер ве ры приложений, на которых выполняются приложения клиентов (содержание данного пункта скопировано из работы [19]). Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Архитектура трехуровневой модели приведена на рис. 1.4.2.6.1. Этот промежуточный уровень содержит один или несколько серверов приложений. 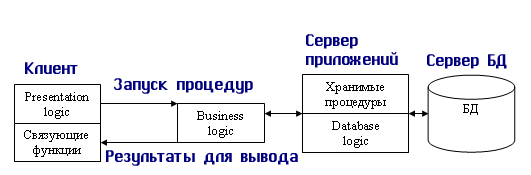 Рисунок 1.4.2.6.1 - Модель сервера приложений В этой модели компоненты приложения делятся между тремя исполнителями: Клиент обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, расположенной на компьютере-клиенте. Клиент исполняет коммуникационные функции front-end части приложения, которые обеспечивают доступ клиенту в локальную или глобальную сеть. Дополнительно реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует тем случаям, когда клиент также является клиентом менеджера распределенных транзакций. Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения общих незагружаемых функций для клиентов. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, поддерживают сетевую доменную операционную среду, хранят и исполняют наиболее общие правила бизнес-логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях. Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application). Эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-прнложений. (On-line analytical processing.) В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного SQL, реализованного в конкретной СУБД, и может быть выполнена на стандартных языках программирования, таких как С, C++, С#, Delphi, SmallTalk, Cobol. Это повышает переносимость системы, ее масштабируемость. Функции промежуточных серверов могут быть в этой модели распределены в рамках глобальных транзакций путем поддержки ХА-протокола (X/Open transaction interface protocol), который поддерживается большинством поставщиков СУБД. Дос тоин ст ва: гибкость и универсаль ность. Недостаток: более вы со кие затраты. 1.4.2.7. Модели серверов баз данныхВ период создания первых СУБД технология «клиент-сервер» только зарождалась (содержание данного пункта скопировано из работы [19]). Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия процессов типа «клиент» и процессов типа «сервер». В современных же СУБД он является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом. Рассмотрим эволюцию типов организации подобных механизмов. В основном этот механизм определяется структурой реализации серверных процессов, и часто он называется архитектурой сервера баз данных. Первоначально, как мы уже отмечали, существовала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Это можно назвать нулевым этапом развития серверов БД. Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один-к-одному» (рис. 1.4.2.7.1), то есть сервер обслуживал запросы только одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу было революционным шагом, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети. Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы. Для обслуживания большого числа клиентов на сервере должно быть запущено большое количество одновременно работающих серверных процессов, а это резко повышало требования к ресурсам ЭВМ, на которой запускались все серверные процессы. Кроме того, каждый серверный процесс в этой модели запускался как независимый, поэтому если один клиент сформировал запрос, который был только что выполнен другим серверным процессом для другого клиента, то запрос тем не менее выполнялся повторно. В такой модели весьма сложно обеспечить взаимодействие серверных процессов. Эта модель самая простая, и исторически она появилась первой. 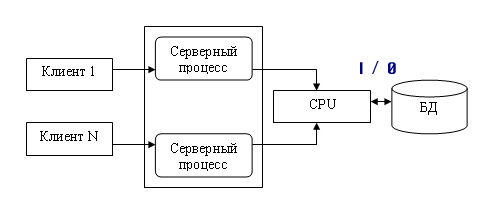 Рисунок 1.4.2.7.1 - Взаимодействие пользовательских и клиентских процессов в модели «один-к-одному» Проблемы, возникающие в модели «один-к-одному», решаются в архитектуре «систем с выделенным сервером», который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис. 1.4.2.7.2). Логически каждый клиент связан с сервером отдельной нитью («thread»), или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной («multi-threaded»). Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей («trashing»). 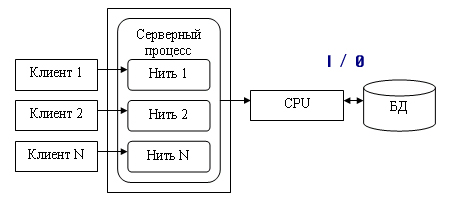 Рисунок 1.4.2.7.2 - Многопотоковая односерверная архитектура Кроме того, возможность взаимодействия с одним сервером многих клиентов позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один-к-одному» будет создано 100 копий процессов СУБД для 100 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один серверный процесс. Однако такое решение имеет свои недостатки. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три. В некоторых системах эта проблема решается вводом промежуточного диспетчера. Подобная архитектура называется архитектурой виртуального сервера («virtual server») (рисунок 1.4.2.7.3). В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к актуальным серверам. В этом случае нет ограничений на использование многопроцессорных платформ. Количество актуальных серверов может быть согласовано с количеством процессоров в системе. Однако и эта архитектура не лишена недостатков, потому что здесь в систему добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки актуальных серверов («load balancing») и ограничивает возможности управления взаимодействием «клиент—сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов. 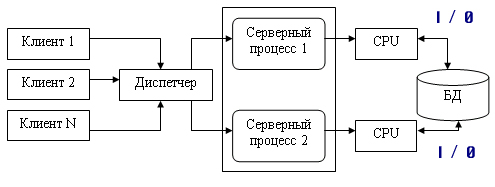 Рисунок 1.4.2.7.3 - Архитектура с виртуальным сервером Подобная организация взаимодействия клиент-сервер может рассматриваться как аналог банка, где имеется несколько окон кассиров, и специальный банковский служащий – администратор зала (диспетчер) направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако стоит лишь появиться посетителям с высшим приоритетом, которые должны обслуживаться в специальном окне, как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией. Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основания говорить о многопотоковой архитектуре с несколькими серверами, представленной на рис. 14.2.7.4. Она также может быть названа многонитевой мультисерверной архитектурой. Эта архитектура связана с вопросами распараллеливания выполнения одного пользовательского запроса несколькими серверными процессами. 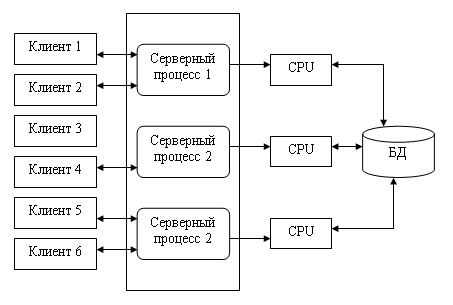 Рисунок 1.4.2.7.4 - Многопотоковая мультисерверная архитектура Существует несколько возможностей распараллеливания выполнения запроса. В этом случае пользовательский запрос разбивается на ряд подзапросов, которые могут выполняться параллельно, а результаты их выполнения потом объединяются в общий результат выполнения запроса. Тогда для обеспечения оперативности выполнения запросов их подзапросы могут быть направлены отдельным серверным процессам, а потом полученные результаты объединены в общий результат (см. рисунок 1.4.2.7.5). В данном случае серверные процессы не являются независимыми процессами, такими, как рассматривались ранее. Эти серверные процессы принято называть нитями (treads), и управление нитями множества запросов пользователей требует дополнительных расходов от СУБД, однако при оперативной обработке информации в хранилищах данных такой подход наиболее перспективен.  Рисунок 1.4.2.7.5 - Многонитевая мультисерверная архитектура 1.4.2.8. Клиент-ИнтернетДоступ к базе данных реа ли зуется из браузера Интернет. Это снижает требования к клиентской ма ши не, при этом не требуется разработка специальных программ и про то колов об мена. Доступ к базе данных может быть как на стороне клиента, так и на стороне сервера. Внешние программы (CGI сценарии, CGI ск рип тами, ASP страницы) взаимодействуют с сер ве ром БД на языке SQL или на командном языке работы с базой (Visual Basic [5], Delphi, C++ Builder, Visual C++ [6]) через драйверы ODBC или языки прог рам ми ро ва ния, обес пе чи вающие уни фи ци ро ван ный доступ к базам данных с раз лич ными СУБД. Внешние программы пишутся на языках C++, Delphi, Perl. 1.4.2.9. Интерфейс ODBCИнтерфейс ODBC (Open Database Connectivity совместимость от крытых баз данных) является посредником между приложением и СУБД; обеспечивает доступ из приложения к базам с различными СУБД. В состав ODBC входят драйверы (для каждой СУБД один драйвер, который преоб разует форматы данных и команды приложения в форматы и ко ман ды СУБД и обратно) и диспетчер драйверов, который подключает нуж ный драйвер. Схема доступа к БД на стороне сервера Создается Web страница, ко то рая содержит форму с полями для корректировки базы или для отображения значений из базы. Запрос пользователем Web страницы с формой общения с БД. Заполнение пользователем формы, ее контроль средствами языков VBScript или JavaScript и отправка ее Web серверу. Web сервер получает эту форму и запускает программу (ASP стра ницу) ее обработки (имя ее указано в атрибуте ACTION тега |