ПЛЕЩ. Учебное пособие содержит
 Скачать 3.78 Mb. Скачать 3.78 Mb.
|

1.5.3. Правила формирования взаимосвязанных таблицРассмотрим шесть правил формирования таблиц на примере двух максимально упрощенных таблиц с различными типами связей (п. 1.3.3): ПРЕПОДАВАТЕЛИ (Табельный номер преподавателя, ФИО) ПРЕДМЕТЫ (Код предмета, наименование предмета, часы) Тип связи “Один к одному” Правило 1. Класс принадлежностей обоих объектов обязательный. Все атрибуты обоих объектов объединяются в одну таблицу: ПРЕПОДАВАТЕЛИ_ПРЕДМЕТЫ (Табельный номер преподавателя, ФИО, код предмета, наименование предмета, часы). Правило 2. Класс принадлежностей обоих объектов различный. Формируются две таблицы: ПРЕПОДАВАТЕЛИ (Табельный номер преподавателя, код предмета,ФИО) ПРЕДМЕТЫ (Код предмета, наименование предмета, часы). Таблица “ПРЕПОДАВАТЕЛИ” формируется из атрибутов объекта (“ПРЕПОДАВАТЕЛИ”) с обязательным КП (для каждого пре подавателя имеется один предмет) и дополняется ключом “Код пред ме та” объекта (“ПРЕД МЕТЫ”) с необя за тель ным КП (есть предметы, для ко то рых отсут ствуют преподаватели). Таблицы связываются по атрибуту “Код пред мета”. Это позволит избежать пустых зна че ний атрибутов. Правило 3. Класс принадлежностей обоих объектов необязательный Формируются три таблицы: ПРЕПОДАВАТЕЛИ (Табельный номер преподавателя, ФИО). ПРЕПОДАЮТ (Табельный номер преподавателя, код предмета). ПРЕДМЕТЫ (Код предмета, наименование предмета, часы). Создается таблица (“ПРЕПОДАЮТ) с ключами исход ных объектов (“Табельный номер преподавателя” и “Код предмета”) для связывания таб лиц “ПРЕПОДАВАТЕЛИ” и “ПРЕДМЕТЫ”. Связь типа “Один-ко-многим” (1:М) Допускается преподавание одним преподавателем несколь ких пред метов, но один предмет не может преподаваться несколькими пре по да ва те ля ми. Правило 4. Класс принадлежностей обоих объектов обязательный. Формируются таблицы: ПРЕПОДАВАТЕЛИ (Табельный номер преподавателя, ФИО). ПРЕДМЕТЫ (Код предмета, табельный номер преподавателя, наименова ние предмета, часы). Ключ (“Табельный номер преподавателя”) односвязанного объекта (“ПРЕ ПО ДАВАТЕЛИ”) добавляется как атрибут (внешний ключ) в много свя занный объект (“ПРЕД МЕ ТЫ”). Правило 5. Класс принадлежности многосвязанного объекта не обя за тельный, односвязанного обязательный. Формируются три таблицы: ПРЕПОДАВАТЕЛИ (Табельный номер преподавателя, ФИО). ПРЕПОДАЮТ (Табельный номер преподавателя, код предмета). ПРЕДМЕТЫ (Код предмета, наименование предмета, часы). Вводится новая таблица (“ПРЕПОДАЮТ”) с ключами исход ных объек тов (“Табельный номер преподавателя” и “Код предмета”) для свя зыва ния этих таблиц. Связь типа “Многие-к-одному” (М:1) Допускается преподавание одним преподавателем не более одного предмета, но один предмет может преподаваться несколькими пре по дава телями. Правила для этого случая аналогичны правилам 4 и 5. Связь типа “Многие-ко-многим” (М:М) Допускается преподавание одним преподавателем несколь ких пред ме тов, и один предмет может преподаваться несколькими пре по да ва те лями. Правило 6. Независимо от класса принадлежностей обоих объектов формируются три таблицы: ПРЕПОДАВАТЕЛИ (Табельный номер преподавателя, ФИО). ПРЕПОДАЮТ (Табельный номер преподавателя, код предмета). ПРЕДМЕТЫ (Код предмета, наименование предмета, часы). Вводится новая таблица (“ПРЕПОДАЮТ”) с ключами исход ных объ ек тов (“Табельный номер преподавателя” и “Код предмета”) для свя зыв ания этих таблиц. Надо отметить, что при объединении таблиц средствами языка SQL указывается тип объединения: полное/внутреннее (Full/Inner), лево/право сто роннее (Left/Right). Это позволяет не учитывать ряд соответствующих правил. 1.5.4. Модели жизненного цикла и проектирование баз данных1.5.4.1. Модели жизненного циклаЖизненный цикл базы данных (ЖЦ БД) представляет со бой непрерывный процесс с момента начала разработки базы данных до завершения её эксплуатации. Модель ЖЦПО структура, задающая последовательность выпол не ния и взаимосвязи процессов, задач и действий, выполняемых при соз да нии базы данных. Типы моделей Каскадная модель предполагает последовательное выполнение эта пов: анализ (определение требований и анализ), проектирование, реа ли за ция, внедрение и сопровождение (моди фи ка ция базы данных при изменении предметной области)*. Дос тоинства: формирование на каждом этапе тех ни чес кой до ку ментации, возможность планирования сроков и затрат. Не дос таток: от сутствие возможности пересмотра отдельных этапов. Эволюционная модель. Разрабатывается первоначальная версия БД, которая затем сразу же передается на испытание пользователю, затем она дорабатывается с учетом мнения пользователя. Удобно применять, когда заказчик четко не может сформулировать свои требования или меняет их в процессе создания БД. Достоинство - спецификация может разрабатываться постепенно, по мере того, как заказчик осознает, что ему нужно. Недостатки – плохая документированность и структурируемость БД; перепроектирование БД. Используется при разработки небольших БД. Пошаговая модель занимает промежуточное положение между каскадной и эволюционной моделями. В её рамках разработчик вначале определяет функции БД в самых общих чертах, устанавливают приоритеты и определяют количество этапов (очередей или версий). Каждый этап должен быть результирующим. Достоинства - заказчику не нужно ждать полного завершения разработки; заказчик может использовать компоненты системы, которые получены на первых шагах как прототипы; уменьшение риска общих системных ошибок; наиболее важные подсистемы подвергаются более тщательному тестированию и проверке. Недостатки - сложность отображения системных требований и компонентов больших размеров и распределения общих системных функций по компонентам Спиральная модель устраняет недостатки предыдущих моделей. На каждом витке ее этапы могут уточ нять ся или дополняться новыми рабо та ми (рисунок 1.5.4.1). Каждый виток дает уточненный работоспособный вари ант базы данных, который можно предъявлять пользователю для оценки. Анализ Определение Проектирование требований 1 2 3 Реализация Внедрение и тестирование версий Интеграция Рисунок 1.5.4.1. Этапы спиральной модели ЖЦПО 1.5.4.2. Обследование, системный анализ и постановка задачиНеобходимо провести подробное словесное описание объектов предметной области и реальных связей, которые присутствуют между описываемыми объектами (содержание данного пункта скопировано из работы [19]). Желательно, чтобы данное описание позволяло корректно определить все взаимосвязи между объектами предметной области. В общем случае существуют два подхода к выбору состава и структуры предметной области: Функциональный подход — он реализует принцип движения «от задач» и применяется тогда, когда заранее известны функции некоторой группы лиц и комплексов задач, для обслуживания информационных потребностей которых создается рассматриваемая БД. В этом случае мы можем четко выделить минимальный необходимый набор объектов предметной области, которые должны быть описаны. Предметный подход — когда информационные потребности будущих пользователей БД жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными. Мы не можем точно выделить минимальный набор объектов предметной области, которые необходимо описывать. В описание предметной области в этом случае включаются такие объекты и взаимосвязи, которые наиболее характерны и наиболее существенны для нее. БД, конструируемая при этом, называется предметной, то есть она может быть использована при решении множества разнообразных, заранее не определенных задач. Конструирование предметной БД в некотором смысле кажется гораздо более заманчивым, однако трудность всеобщего охвата предметной области с невозможностью конкретизации потребностей пользователей может привести к избыточно сложной схеме БД, которая для конкретных задач будет неэффективной. Чаще всего па практике рекомендуется использовать некоторый компромиссный вариант, который, с одной стороны, ориентирован на конкретные задачи или функциональные потребности пользователей, а с другой стороны, учитывает возможность наращивания новых приложений. Анализ должен заканчиваться подробным описанием информации об объектах предметной области, которая требуется для решения конкретных задач и которая должна храниться в БД, формулировкой конкретных задач, которые будут решаться с использованием данной БД с кратким описанием алгоритмов их решения, описанием выходных документов, которые должны генерироваться в системе, описанием входных документов, которые служат основанием для заполнения данными БД. При проектировании баз данных следует учитывать следующие общие требования: многократное использование данных; простота, легкость ис поль зования; гибкость; обработка незапла ни ро ван ных запросов; простота корректировки; небольшие затраты на экс плуата цию; минимальная избы точ ность; производительность; секрет ность; дос то верность; защита от ис ка жений и сбоев; состояние готовности; фи зи чес кая и логическая не за ви си мость; требуемая скорость доступа и поиска; стан дар тизация данных; наличие словаря базы, интерфейса связи с про грам мным комплексом и язы ка взаимодействия с конечным поль зо ва те лем; конт роль за целост ностью данных в базе; восстановление и реорга ни зация данных в базе. Организуется обследование предметной области: оценка объема и цели проекта, определение требований, объектов и функций на высоком уровне. Сбор информации начинается с изучения существующих форм доку мен тов, отчетов, имеющихся файлов, баз данных, программ. Исходная информация для анализа берется из индивидуальных бесед с заказ чи ками, на семинарах, при изучении документации, инструкций, анкети ро ва нии и др. Примерное содержание исходной информации (анкет):
Результаты фиксируются в документе типа технического задания (ТЗ), который содержит: назначение, требования, ограничения, возмож нос ти, бизнес процессы (функции), объ ем, смету затрат, сроки, показатели эконо ми ческой эффективности, испол нители. Производится исследование информационных потоков, до кументооборота (схемы движения данных от источника к пользовате лю), функций и информации для их вы пол не ния (объектов, атрибутов и таблиц) без учета конкретных прог рам мных средств. Формулируются биз нес правила (факты, которым дол жна подчи нять ся система). Проектирование – поиск способа удовлетворения фун к циональных по треб ностей пользователей средствами имеющихся тех нологий с учетом заданных ограничений. Проектирование охватывает три области: таб ли цы, запросы, пред став ления, хранимые процедуры и функции; формы, от че ты и программы; топологию сети, модели использования таблицы. Формализация объектов и связей между ними, построение концептуальной модели, формирование набора таблиц с указанием пер вичных клю чей для каждой таблицы, добавление неключевых атри бутов в таб ли цы, нормализация таблиц. Изучаются существующие СУБД и выбирается нужная (п. 1.5.6). Далее разрабатывается логическая и физическая модели БД в тер ми нах выбранной СУБД. Проектируются программы, хранимые процедуры, триггеры. В целом можно выделить отдельные этапы инфологического (концептуального), даталогического (логического) и физического проектирования, которые буду рассмотрены ниже. 1.5.4.3. Инфологическое проектированиеИнфологическое проектированиеформирует формализованное описание предметной области, которое будет «читабельно» не только для специалистов по базам данных, но и сторонних людей (содержание данного пункта скопировано из работы [19]). И это описание должно быть настолько емким, чтобы можно было оценить глубину и корректность проработки проекта БД, и конечно, как говорилось раньше, оно не должно быть привязано к конкретной СУБД. Инфологическое проектирование прежде всего связано с попыткой представления смыслового содержания, предметной области в модели БД. В настоящий момент модель Чена «сущность—связь», или «Entity Relationship», стала фактическим стандартом при инфологическом моделировании баз данных. Общепринятым стало сокращенное название ER-модель, большинство современных CASE-средств содержат инструментальные средства для описания данных в формализме этой модели. Кроме того, разработаны методы автоматического преобразования проекта БД из ER-модели в реляционную, при этом преобразование выполняется в даталогическую модель, соответствующую конкретной СУБД. Все CASE-системы имеют развитые средства документирования процесса разработки БД, автоматические генераторы отчетов позволяют подготовить отчет о текущем состоянии проекта БД с подробным описанием объектов БД и их отношений как в графическом виде, так и в виде готовых стандартных печатных отчетов, что существенно облегчает ведение проекта. В настоящий момент не существует единой общепринятой системы обозначений для ER-модели и разные CASE-системы используют разные графические нотации, но разобравшись в одной, можно легко понять и другие нотации. Модель «сущность—связь» имеет несколько базовых понятий, которые образуют исходные кирпичики, из которых строятся уже более сложные объекты по заранее определенным правилам. Эта модель в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования, которая в настоящий момент несомненно является базовой для разработки сложных программных систем, поэтому многие понятия вам могут показаться знакомыми, и если это действительно так, то тем проще вам будет освоить технологию проектирования баз данных, основанную на ER-модели. В основе ER-модели лежат следующие базовые понятия: Сущность, с помощью которой моделируется класс однотипных объектов. Сущность имеет имя, уникальное в пределах моделируемой системы. Так как сущность соответствует некоторому классу однотипных объектов, то предполагается, что в системе существует множество экземпляров данной сущности. Объект, которому соответствует понятие сущности, имеет свой набор атрибутов — характеристик, определяющих свойства данного представителя класса. При этом набор атрибутов должен быть таким, чтобы можно было различать конкретные экземпляры сущности. Например, у сущности Сотрудник может быть следующий набор атрибутов: Табельный номер, Фамилия, Имя, Отчество, Дата рождения, Количество детей, Наличие родственников за границей. Набор атрибутов, однозначно идентифицирующий конкретный экземпляр сущности, называют ключевым. Для сущности Сотрудник ключевым будет атрибут Табельный номер, поскольку для всех сотрудников данного предприятия табельные номера будут различны. Экземпляром сущности Сотрудник будет описание конкретного сотрудника предприятия. Одно из общепринятых графических обозначений сущности — прямоугольник, в верхней части которого записано имя сущности, а ниже перечисляются атрибуты, причем ключевые атрибуты помечаются, например, подчеркиванием или специальным шрифтом. Между сущностями могут быть установлены связи — бинарные ассоциации, показывающие, каким образом сущности соотносятся или взаимодействуют между собой. Связь может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). Она показывает, как связаны экземпляры сущностей между собой. Если связь устанавливается между двумя сущностями, то она определяет взаимосвязь между экземплярами одной и другой сущности. Например, если у нас есть связь между сущностью «Студент» и сущностью «Преподаватель» и эта связь — руководство дипломными проектами, то каждый студент имеет только одного руководителя, но один и тот же преподаватель может руководить множеством .студентов-дипломников. Поэтому это будет связь «один-ко-многим» (1:М), один со стороны «Преподаватель» и многие со стороны «Студент» (см. рис. 7.2). Связи делятся на три типа по множественности: один-к-одному (1:1), од и и-ко-многим (1:М), многие-ко-многим (М:М). Связь один-к-одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности. Связь 1: М означает, что один экземпляр сущности, расположенный слева по связи, может быть связан с несколькими экземплярами сущности, расположенными справа по связи. Связь «один-к-одному» (1:1) означает, что один экземпляр одной сущности связан только с одним экземпляром другой сущности, а связь «многие-ко-многим» (М:М) означает, что один экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот, один экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Например, если мы рассмотрим связь типа «Изучает» между сущностями «Студент» и «Дисциплина», то это связь типа «многие-ко-многим» (М:М), потому что каждый студент может изучать несколько дисциплин, но и каждая дисциплина изучается множеством студентов. Связь любого из этих типов может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. Обязательность связи тоже по-разному обозначается в разных нотациях, например, обозначается пустым кружочком на конце связи, а обязательность перпендикулярной линией, перечеркивающей связь. И эта нотация имеет простую интерпретацию. Кружочек означает, что ни один экземпляр не может участвовать в этой связи. А перпендикуляр интерпретируется как то, что по крайней мере один экземпляр сущности участвует в этой связи. Кроме того, в ER-модели допускается принцип категоризации сущностей. Это значит, что, как и в объектно-ориентированных языках программирования, вводится понятие подтипа сущности, то«есть сущность может быть представлена в виде двух или более своих подтипов — сущностей, каждая из которых может иметь общие атрибуты и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются как взаимоисключающие, и при разделении сущности па подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Если на уровне анализа не удается выявить полный Перечень подтипов, то вводится специальный подтип, называемый условно ПРОЧИЕ, который в дальнейшем может быть уточнен. В реальных системах бывает достаточно ввести подтипизацпю на двух-трех уровнях. Сущность, на основе которой строятся подтипы, называется супертипом. Любой экземпляр супертипа должен относиться к конкретному подтипу. Для графического изображения принципа категоризации или типизации сущности вводится специальный графический элемент, называемый узел-дискриминатор, в нотации POWER DESIGNER он изображается в виде полукруга, выпуклой стороной обращенного к суперсущности. Эта сторона соединяется направленной стрелкой с суперсущностью, а к диаметру этого круга стрелками подсоединяются подтипы данной сущности. В результате построения модели предметной области в виде набора сущностей и связей получаем связный граф. В полученном графе необходимо избегать циклических связей — они выявляют некорректность модели. В качестве примера спроектируем инфологическую модель системы, предназначенной для хранения информации о книгах ц областях знаний, представленных в библиотеке. Прежде всего, существует сущность «Книги», каждая книга имеет уникальный шифр, который является ее ключом, и ряд атрибутов, которые взяты из описания предметной области. Множество экземпляров сущности определяет множество книг, которые хранятся в библиотеке. Каждый экземпляр сущности «Книги» соответствует не конкретной книге, стоящей на полке, а описанию некоторой книги, которое дается обычно в предметном каталоге библиотеке. Каждая книга может присутствовать в нескольких экземплярах, и это как раз те конкретные книги, которые стоят на полках библиотеки. Для того чтобы отразить это, мы должны ввести сущность «Экземпляры», которая будет содержать описания всех экземпляров книг, которые хранятся в библиотеке. Каждый экземпляр сущности «Экземпляры» соответствует конкретной книге на полке. Каждый экземпляр имеет уникальный инвентарный номер, однозначно определяющий конкретную книгу. Кроме того, каждый экземпляр книги может находиться либо в библиотеке, либо на руках у некоторого читателя, и в последнем случае для данного экземпляра указываются дополнительно дата взятия книги читателем и дата предполагаемого возврата книги. Между сущностями «Книги» и «Экземпляры» существует связь «один-ко-многим» (1:М), обязательная с двух сторон. Чем определяется данный тип связи? Мы можем предположить, что каждая книга может присутствовать в библиотеке в нескольких экземплярах, поэтому связь «один-ко-многим». При этом если в библиотеке нет ни одного экземпляра дайной книги, то мы не будем хранить ее описание, поэтому если книга описана в сущности «Книги», то по крайней мере один экземпляр этой книги присутствует в библиотеке. Это означает, что со стороны книги связь обязательная. Что касается сущности «Экземпляры», то не может существовать в библиотеке ни одного экземпляра, который бы не относился к конкретной книге, поэтому и со стороны «Экземпляры» связь тоже обязательная. Теперь нам необходимо определить, как в нашей системе будет представлен читатель. Естественно предложить ввести для этого сущность «Читатели», каждый экземпляр которой будет соответствовать конкретному читателю. В библиотеке каждому читателю присваивается уникальный номер читательского билета, который будет однозначно идентифицировать нашего читателя. Номер читательского билета будет ключевым атрибутом сущности «Читатели». Кроме того, в сущности «Читатели» должны присутствовать дополнительные атрибуты, которые требуются для решения поставленных задач, этими атрибутами будут: «Фамилия Имя Отчество», «Адрес читателя», «Телефон домашний» и «Телефон рабочий». Почему мы ввели два отдельных атрибута под телефоны? Потому что надо в разное время звонить по этим телефонам, чтобы застать читателя, поэтому администрации библиотеки будет важно знать, к какому типу относится данный телефон. В описании нашей предметной области существует ограничение на возраст наших читателей, поэтому в сущности «Читатели» надо ввести обязательный атрибут «Дата рождения», который позволит нам контролировать возраст наших читателей. Каждый читатель может держать на руках несколько экземпляров книг. Для отражения этой ситуации нам надо провести связь между сущностями «Читатели» и «Экземпляры». А почему не между сущностями «Читатели» и «Книги»? Потому что читатель берет из библиотеки конкретный экземпляр конкретной книги, а не просто книгу. А как же узнать, какая книга у данного читателя? А это можно будет узнать по дополнительной связи между сущностями «Экземпляры» и «Книги», и эта связь каждому экземпляру ставит в соответствие одну книгу, поэтому мы в любой момент можем однозначно определить, какие книги находятся на руках у читателя, хотя связываем с читателем только инвентарные номера взятых книг. Между сущностями «Читатели» и «Экземпляры» установлена связь «один-ко-многим», и при этом она не обязательная с двух сторон. Читатель в данный момент может не держать ни одной книги на руках, а с другой стороны, данный экземпляр книги может не находиться ни у одного читателя, а просто стоять на полке в библиотеке. Теперь нам надо отразить последнюю сущность, которая связана с системным каталогом. Системный каталог содержит перечень всех областей знаний, сведения по которым содержатся в библиотечных книгах. Мы можем вспомнить системный каталог в библиотеке, с которого мы обычно начинаем поиск нужных нам книг, если мы не знаем их авторов и названий. Название области знаний может быть длинным и состоять из нескольких слов, поэтому для моделирования системного каталога мы введем сущность «Системный каталог» с двумя атрибутами: «Код области знаний» и «Название области знаний». Атрибут «Код области знаний» будет ключевым атрибутом сущности. Каждая книга может содержать сведения из нескольких областей знаний, а с другой стороны, из практики известно, что в библиотеке может присутствовать множество книг, относящихся к одной и той же области знаний, поэтому нам необходимо установить между сущностями «Системный каталог» и «Книги» связь «многие-ко-многим», обязательную с двух сторон. Действительно, в системном1 каталоге не должно присутствовать такой области знаний, сведения по которой не представлены ни в одной книге нашей библиотеки, противное было бы бессмысленно. И обратно, каждая книга должна быть отнесена к одной или нескольким областям знаний для того, чтобы читатель мог ее быстрее найти. Инфологическая модель предметной области «Библиотека» представлена на рисунке 1.5.4.3.1. 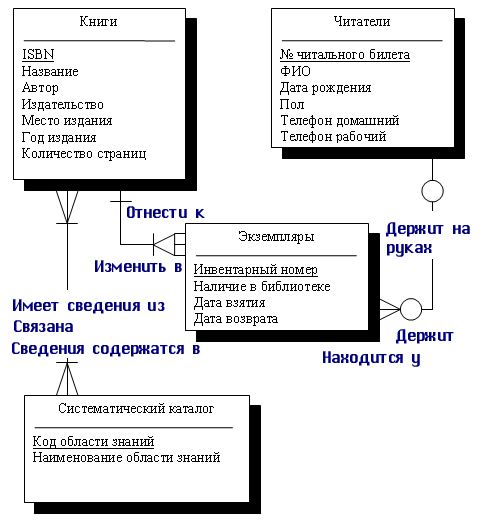 Рисунок 1.5.4.3.1. Инфологическая модель «Библиотека» Общепринятым языком описания базы данных и стал язык ER-модели со следующими правилами преобразования ER-модели в реляционную. 1. Каждой сущности ставится в соответствие отношение реляционной модели данных. При этом имена сущности и отношения могут быть различными, потому что на имена сущностей могут не накладываться дополнительные синтаксические ограничения, кроме уникальности имени в рамках модели. Имена отношений могут быть ограничены требованиями конкретной СУБД. 2. Каждый атрибут сущности становится атрибутом соответствующего отношения. Переименование атрибутов должно происходить в соответствии с теми же правилами, что и переименование отношений. Для каждого атрибута задается конкретный допустимый в СУБД тип данных и обязательность или необязательность данного атрибута (то есть допустимость или недопустимость MULL значений для него). 3. Первичный ключ сущности становится PRIMARY KEY соответствующего отношения. Атрибуты, входящие в первичный ключ отношения, автоматически получают свойство обязательности (NOT NULL). 4. В каждое отношение, соответствующее подчиненной сущности, добавляется набор атрибутов основной сущности, являющейся первичным ключом основной сущности. В отношении, соответствующем подчиненной сущности, этот набор атрибутов становится внешним ключом (FOREING KEY). 5. Для моделирования необязательного типа связи на физическом уровне у атрибутов, соответствующих внешнему ключу, устанавливается свойство допустимости неопределенных значений (признак NULL). При обязательном типе связи атрибуты получают свойство отсутствия неопределенных значений (признак NOT NULL). 6. Для отражения категоризации сущностей при переходе к реляционной модели возможны несколько вариантов представления. Возможно создать только одно отношение для всех подтипов одного супертипа. В него включают все атрибуты всех подтипов. 7. При втором способе для каждого подтипа и для супертипа создаются свои отдельные отношения. 8. Дополнительно при описании отношения между типом и подтипами необходимо указать тип дискриминатора. Дискриминатор может быть взаимоисключающим (М/Е, mutually exclusive ) или нет. Если установлен данный тип дискриминатора, то это значит, что один экземпляр сущности супертипа связан только с одним экземпляром сущности подтипа и для каждого экземпляра сущности супертипа существует потомок. Кроме того, необходимо указать для второго способа, наследуется ли только идентификатор супертипа в подтипы или наследуются все атрибуты супертипа. Разрешение связей типа «многие-ко-многим». Так как в реляционной модели данных поддерживаются между отношениями только связи типа «один-ко-мно-гим», а в ER-модели допустимы связи «многие-ко-многим», то необходим специальный механизм преобразования, который позволит отразить множественные связи, неспецифические для реляционной модели, с помощью допустимых для нее категорий. Это делается введением специального дополнительного связующего отношения, которое связано с каждым исходным связью «один-ко-мно-гим», атрибутами этого отношения являются первичные ключи связываемых отношений. Так, например, в схеме «Библиотека» присутствует связь такого типа между сущностью «Книги» и «Системный каталог». Для разрешения этой неспецифической связи при переходе к реляционной модели должно быть введено специальное дополнительное отношение, которое имеет всего два атрибута: ISBN (шифр книги) и KOD (код области знаний). При этом каждый из атрибутов нового отношения является внешним ключом (FORKING KEY), а вместе они образуют первичный ключ (PRIMARY KEY) новой связующей сущности. На рис. 1.5.4.3.2 представлена реляционная модель «Библиотека». Нормализацию можно проводить и на уровне инфологической (семантической) модели и смысл ее аналогичен нормализации реляционной модели. Алгоритм приведения. Шаг 1. Проанализировать схему на присутствие сущностей, которые скрыто моделируют несколько разных взаимосвязанных классов объектов реального мира (именно это соответствует ненормализованным отношениям). Если такое выявлено, то разделить каждую из этих сущностей на несколько новых сущностей и установить между ними соответствующие связи, полученная схема будет находиться в первой нормальной форме. Перейти к шагу 2. Шаг 2. Проанализировать все сущности, имеющие составные первичные ключи, на наличие неполных функциональных зависимостей непервичных атрибутов от атрибутов возможного ключа. Если такие зависимости обнаружены, то разделить данные сущности на 2, определить для каждой сущности первичные ключи и установить между ними соответствующие связи. Полученная схема будет находиться во второй нормальной форме. Перейти к шагу 3. Шаг 3. Проанализировать неключевые атрибуты всех сущностей на наличие транзитивных функциональных зависимостей. При обнаружении таковых расщепить каждую сущность на несколько таким образом, чтобы ликвидировать транзитивные зависимости. Схема находится в третьей нормальной форме. Перейти к шагу 4. Шаг 4. Проанализировать все сущности на наличие детерминантов, которые не являются возможными ключами. При обнаружении подобных расщепить сущность на две, установив между ними соответствующие связи. Полученная схема соответствует нормальной форме Бойса—Кодда. Перейти к шагу 5. Шаг 5. Проанализировать все сущности на наличие многозначных зависимостей. Если обнаружатся сущности, у которых имеется более одной многозначной зависимости, то расщепить такие сущности на две, установив между ними соответствующие связи. Полученная схема будет находиться в четвертой нормальной форме. Перейти к шагу 6. 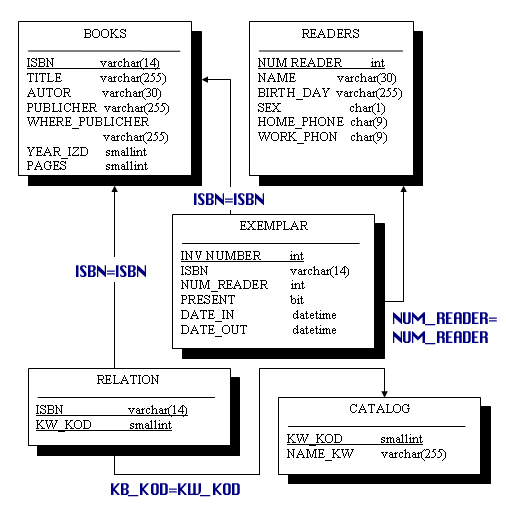 Рисунок 1.5.4.3.2. Реляционная схема «Библиотека» Шаг 6. Проанализировать сущности на наличие в них зависимостей проекции-соединения. При обнаружении таковых расщепить сущность на требуемое число взаимосвязанных сущностей и установить между ними требуемые связи. Полученная таким образом схема будет находиться в пятой нормальной форме и, будучи формально преобразованной к реляционной схеме по указанным выше принципам, даст реляционную схему также в пятой нормальной форме. 1.5.4.4. Датологическое проектированиеДаталогическое (логическое) проектирование приводит к разработке схемы БД, то есть совокупности схем отношений, которые адекватно моделируют абстрактные объекты предметной области и семантические связи между этими объектами (содержание данного пункта скопировано из работы [19]). Основой анализа корректности схемы являются так называемые функциональные зависимости между атрибутами БД. Некоторые зависимости между атрибутами отношений являются нежелательными из-за побочных эффектов и аномалий, которые они вызывают при модификации БД. При этом под процессом модификации БД мы понимаем внесение новых данных в БД или удаление некоторых данных из БД, а также обновление значений некоторых атрибутов. Результате выполнения этого этапа должны быть получены следующие результирующие документы: описание концептуальной схемы БД в терминах выбранной СУБД; описание внешних моделей в терминах выбранной СУБД; описание декларативных правил поддержки целостности базы данных. Следует построить корректную (которой отсутствуют нежелательные зависимости между атрибутами отношении) схему БД, ориентируясь на реляционную модель данных. Проектирование схемы БД может быть выполнено двумя путями: путем декомпозиции (разбиения), когда исходное множество отношений, входящих в схему БД заменяется другим множеством отношений (число их при этом возрастает), являющихся проекциями исходных отношений; путем синтеза, то есть путем компоновки из заданных исходных элементарных зависимостей между объектами предметной области схемы БД. Классическая технология проектирования реляционных баз данных связана с теорией нормализации, основанной на анализе функциональных зависимостей между атрибутами отношений. Функциональные зависимости определяют устойчивые отношения между объектами и их свойствами в рассматриваемой предметной области. Именно поэтому процесс поддержки функциональных зависимостей, характерных для данной предметной области, является базовым для процесса проектирования. Процесс проектирования с использованием декомпозиции представляет собой процесс последовательной нормализации схем отношений, при этом каждая последующая итерация соответствует нормальной форме более высокого уровня и обладает лучшими свойствами по сравнению с предыдущей. 1.5.4.5. Проектирование физической моделиФизическое проектирование базы данных - процесс подготовки описания реализации базы данных на внешних запоминающих устройствах (содержание данного пункта скопировано из работы [19]). На этом этапе рассматриваются основные отношения, организация файлов и индексов, предназначенных для обеспечения эффективного доступа к данным и средства защиты. Не все СУБД имеет средства физического проектирования, например, СУБД Access (все таблицы хранятся в одном файле). Физическое проектирование является последним этапом создания проекта базы данных, при выполнении которого проектировщик принимает решения о способах реализации разрабатываемой базы данных. Основной целью физического проектирования базы данных является описание способа физической реализации логического проекта базы данных. Этапы физического проектирования баз данных:
1.5.4.6. Реализация, интеграция и внедрениеРеализация и тестирование.Создаются приклад ные программы, хра нимые процедуры, триггеры (содержание данного пункта скопировано из работы [19]). Производится автономное тестирование прог рамм на отдельных тестах, тестируются связи между программами. Интеграция.Для существующей устаревшей системы, которая бу дет заменена новой разрабатываемой системой, можно конвертировать программы, файлы или таблицы этой системы в программы и файлы для загрузки данных в создаваемую БД. Создается системный тест (или загру жаются реальные данные) и производится комплексное тестирование на системном тесте (реальных данных). Внедрение версий. Производятся обучение пользователей, загрузка базы данных реальной инфор ма цией, проведение опытной эксплуатации, уст ранение обнаруженных ошибок, приемо сдаточные испытания. 1.5.5. Выбор СУБД1.5.5.1. Сравнение Visual FoxPro, Access, SQL Server, Oracle и ExcelПриведем краткий сравнительный анализ популярных СУБД и электронной таблицы Excel. Основные общие черты Access и VisualFoxPro
Основные отличия Access от VisualFoxPro
Основные общие черты SQLServer и Oracle
Основные отличия SQLServer от Oracle
Основные отличия SQLServer от VisualFoxPro и Access
Основные отличия Oracle от VisualFoxPro и Access
Основные отличия СУБД от Excel
Достоинства FoxPro. Наличие собственного развитого, простого и удобного языка программирования, мастеров, конструкторов, обработка несколькихбаз данных с различными СУБД, возможность создания исполняемых EXE файлов. Недостатки FoxPro. Сложность написания программ, отсутствие средств защиты и восстановления информации, ограничения на объем информации, наличие ошибок при установке связей между таблицами в запросах, формируемых визуальными средствами (ошибки обходятся путем установки связей средствами фильтрации). FoxPro рекомендуется использовать для разработки достаточно сложных приложений с ограниченным объемом (не более миллиона запи сей) обрабатываемой информации для небольших и средних предприятий. Достоинства Access. Простота, гибкость, русификация, наличие раз нообразных масте ров, конструкторов, надежная работа. Недостатки Access. Слабые средства защиты и восстановления ин фор мации, огра ни че ния на объем информации, отсутствие собственного языка програм миро вания, низкая скорость при работе с большими объемами информации. Access рекомендуется использовать для разработки простых прило же ний и персональных баз данных с ограниченным объемом (несколько сотен тысяч записей) информации для неболь ших предприятий. Достоинства SQLServer. Имеются гибкие и мощные средста администрирования и языка запросов Transact-SQL, надежность, эффективная работа, ориентация на коллективное использование. Недостатки SQLServer. Отсутствуют средства визуальной раз ра ботки приложений. SQLServer рекомендуется использовать для создания очень больших централизованных или распределенных баз данных (хранилищ данных) коллективного использования для средних и крупных предприятий. Достоинства Oracle. Достоинства аналогичны достоинствам SQL Server плюс наличие развитых средств загрузки/разгрузки данных, раз работ ки приложений и оперативного анализа данных. Недостатки Oracle. Сложность и высокая стоимость приобретения. Oracle рекомендуется использовать для очень больших центра ли зованных или распределенных баз данных (хранилищ данных) коллектив ного использования для крупных предприятий. Общие рекомендации. Для организации хранилища данных боль ших объемов рекомендуется использовать SQL Server или Oracle, а в клиентском приложении доступ к данным этого хранилища осуществить средствами СУБД Access (через проект), FoxPro (через удаленные представления) или средствами языков программирования Visual Basic, Visual C++, Delphi, C++ Builder (через ADO), или инструментальными средствами обработки данных Oracle. 1.5.5.2. Методика балловой оценки программных средствДля выбора СУБД можно использовать методику балловой оценки программных средств:
В оценке ПС могут участвовать несколько независимых экспертов. Приведем основные показатели СУБД.
1.5.6. CASE средства автоматизации проектированияТермин CASE (Computer Aided Software Engineering) переводится как разработка программного обеспечения с помощью компьютера. CASE средства представляют собой программы, авто ма ти зирующие процессы создания и сопровождения (этапы ЖЦПО, генерация программ и документации, управления проектом) информацион ных сис тем. CASE системой является набор CASE средств, выполненных в рам ках единого программного продукта. Классификация CASE средств 1. Ориентация на этапы жизненного цикла
2. Функциональнаяполнота
3. Степень зависимости от СУБД
4. Тип используемой модели
|