Ответы на билеты по дисциплине Базы данных. Базы данных. Вопросы к экзамену по дисциплине Базы данных
 Скачать 0.68 Mb. Скачать 0.68 Mb.
|

|
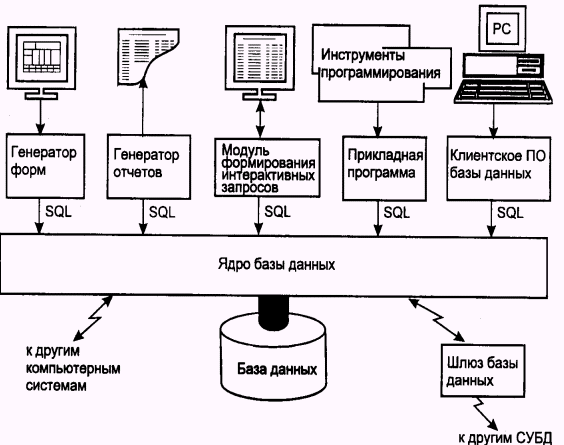
Физическое проектирование базы данных - процесс подготовки описания реализации базы данных на вторичных запоминающих устройствах; на этом этапе рассматриваются основные отношения, организация файлов и индексов, предназначенных для обеспечения эффективного доступа к данным, а также все связанные с этим ограничения целостности и средства защиты. Физическое проектирование является третьим и последним этапом создания проекта базы данных, при выполнении которого проектировщик принимает решения о способах реализации разрабатываемой базы данных. Во время предыдущего этапа проектирования была определена логическая структура базы данных (которая описывает отношения и ограничения в рассматриваемой прикладной области). Хотя эта структура не зависит от конкретной целевой СУБД, она создается с учетом выбранной модели хранения данных, например реляционной, сетевой или иерархической. Однако, приступая к физическому проектированию базы данных, прежде всего необходимо выбрать конкретную целевую СУБД. Поэтому физическое проектирование неразрывно связано с конкретной СУБД. Между логическим и физическим проектированием существует постоянная обратная связь, так как решения, принимаемые на этапе физического проектирования с целью повышения производительности системы, способны повлиять на структуру логической модели данных. Как правило, основной целью физического проектирования базы данных является описание способа физической реализации логического проекта базы данных. В случае реляционной модели данных под этим подразумевается следующее: создание набора реляционных таблиц и ограничений для них на основе информации, представленной в глобальной логической модели данных; определение конкретных структур хранения данных и методов доступа к ним, обеспечивающих оптимальную производительность СУБД; разработка средств защиты создаваемой системы. Этапы концептуального и логического проектирования больших систем следует отделять от этапов физического проектирования. На это есть несколько причин. Они связаны с совершенно разными аспектами системы, поскольку отвечают на вопрос, что делать, а не как делать. Они выполняются в разное время, поскольку понять, что надо сделать, следует прежде, чем решить, как это сделать. Они требуют совершенно разных навыков и опыта, поэтому требуют привлечения специалистов различного профиля. Проектирование базы данных — это итерационный процесс, который имеет свое начало, но не имеет конца и состоит из бесконечного ряда уточнений. Его следует рассматривать прежде всего как процесс познания. Как только проектировщик приходит к пониманию работы предприятия и смысла обрабатываемых данных, а также выражает это понимание средствами выбранной модели данных, приобретенные знания могут показать, что требуется уточнение и в других частях проекта. Особо важную роль в общем процессе успешного создания системы играет концептуальное и логическое проектирование базы данных. Если на этих этапах не удастся получить полное представление о деятельности предприятия, то задача определения всех необходимых пользовательских представлений или обеспечения защиты базы данных становится чрезмерно сложной или даже неосуществимой. К тому же может оказаться затруднительным определение способов физической реализации или достижения приемлемой производительности системы. С другой стороны, способность адаптироваться к изменениям является одним из признаков удачного проекта базы данных. Поэтому вполне имеет смысл затратить время и энергию, необходимые для подготовки наилучшего возможного проекта. Разработка приложений. Тестирование. Главные составляющие разработки приложений – это проектирование транзакций и пользовательского интерфейса. Транзакции представляют собой некоторые события реального мира. Все транзакции должны обращаться к базе данных с той целью, чтобы хранимые в ней данные всегда гарантированно соответствовали текущей ситуации в реальном мире. Проектирование транзакций заключается в определении: Данные, которые используются транзакцией Функциональные характеристики транзакций Выходных данных, формируемых транзакцией Степени важности и интенсивности использования транзакций Транзакции могут представлять собой сложные операции, которые раскладываются на несколько более простых операций, каждая из которых представляет собой отдельную транзакцию. Пользовательский интерфейс приложений БД является одним из важнейших компонентов системы. Интерфейс должен быть удобным и обеспечивать все функциональные возможности, предусмотренные в спецификациях требований пользователей. Специалисты рекомендуют при проектировании пользовательского интерфейса использовать следующие элементы и их характеристики: Содержательное название Ясные и понятные инструкции Логически обоснованные группировки и последовательности полей Визуально привлекательный вид окна формы или поля отчета Легкоузнаваемые названия полей Согласованную терминологию и сокращения Согласованное использование цветов Визуальное выделение пространства и границ полей ввода данных Удобные средства перемещения курсора Средства исправления отдельных ошибочных символов и целых полей Средства вывода сообщений об ошибках при вводе недопустимых значений Особое выделение необязательных для ввода полей Средства вывода сообщения об окончании заполнения формы. Обязательное тестирование должен проходить любой программный продукт, тем более такой, как прикладные программы ИС. Стратегия тестирования должна предполагать использование реальных данных и должна быть построена таким образом, чтобы весь выполнялся строго последовательно и методически правильно. Пользователи новой системы должны принимать в процессе ее тестирования самое активное участие с целью выяснения их неучтенных информационных потребностей. Если такие обнаружатся, в случае необходимости осуществляется откат назад в процессе проектирования на те стадии, где возможно внести необходимые изменения. Для оценки законченности и корректности выполнения приложения БД может использоваться несколько различных стратегий тестирования: Нисходящее тестирование Восходящее тестирование Тестирование потоков Интенсивное тестирование. Оценка работы и поддержка базы данных, эксплуатация и сопровождение. Оценка работы включает опрос пользователя с целью выяснение какие информационные потребности остались неучтенными. В случае необходимости вносится изменение в БД. Поддержка БД предполагает разрешение проблем, возникающих в процессе эксплуатации БД и связанных как с ошибками реализации БД, так и с изменением в самой предметной области, создание дополнительных программных компонент или модернизаций самой БД. Реляционная модель данных. Реляционной называется БД в которой все данные, доступные пользователю организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Основными элементами реляционной БД являются таблицы и связи между ними. Таблица – некоторая регулярная структура, состоящая из конечного набора однотипных записей. Таблица отображает тип объекта реального мира, который называют еще сущностью. Строки соответствуют экземпляру объекта, конкретному событию или явлению. Столбцы соответствуют атрибуту, признакам, характеристикам, параметрам. У каждой таблицы имеется уникальное имя внутри БД, каждый столбец обладает именем, которое служит заголовком столбца. Все столбцы одной таблицы уникальны, но их имена могут повторяться в разных таблицах. В реляционной таблице данных атрибуты отношений неупорядочены, т.е. обращены к полям всегда происходит по имени, а не по расположению. Таблицы всегда содержат минимум один столбец. В реляционной модели данных для обозначения строки отношения используется понятие кортеж. Представление кортежа на физическом уровне является строка таблицы БД. Строки таблицы не имеют определенного порядка, в таблице может содержаться любое количество строк, допустимо существование таблицы с нулевым количеством строк. Поскольку строки не упорядочены нельзя выбрать строку по ее номеру в таблице, в таблице нет первой или последней строки, для идентификации строки в таблице используется понятие ключевого атрибута. Ключевым элементом данных называется такой элемент по значению которого можно однозначно идентифицировать строку таблицы. Первичный ключ – атрибут или группа атрибутов, который единственным образом идентифицирует каждую строку в таблице. Если в таблице нет полей значения которых уникальны, то для создания первичного ключа в ней вводят дополнительное поле, необходимое для корректной работы самой СУБД, если первичный ключ представляет собой несколько столбцов, то такой ключ называют составным. Вторичный ключ устанавливается над полями, которые часто используются при поиске и сортировке данных, в отличие от первичного ключа, поле для вторичного ключа могут содержать не уникальные таблицы. Столбец одной таблицы, значения которого совпадают со значениями столбца – первичного ключа, называют внешнем ключом. В качестве первичного и внешнего ключи используется столбцы значения которых одинаковы для двух различных таблиц. Внешний и первичный ключ могут представлять собой комбинацию столбцов. 12 правил реляционного подхода. 1 Правило информации. Вся информация в базе данных должна быть представлена исключительно на логическом уровне и только одним способом - в виде значений, содержащихся в таблицах. 2 Правило гарантированного доступа. Логический доступ ко всем и к каждому элементу данных (атомарному значению) в реляционной базе данных должен обеспечиваться путём использования комбинации имени таблицы, первичного ключа и имени столбца. 3 Правило поддержки недействительных значений. В настоящей реляционной базе данных должна быть реализована поддержка недействительных значений, которые отличаются от строки символов нулевой длины, строки пробельных символов и от нуля или любого другого числа и используются для представления отсутствующих данных независимо от типа этих данных. 4 Правило динамического каталога, основанного на реляционной модели. Описание базы данных на логическом уровне должно быть представлено в том же виде, что и основные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они применяют для работы с основными данными. 5 Правило исчерпывающего подъязыка данных. Реляционная система может поддерживать различные языки и режимы взаимодействия с пользователем (например, режим вопросов и ответов). Однако должен существовать, по крайней мере, один язык, операторы которого можно представить в виде строк символов, в соответствии с некоторым четко определенным синтаксисом и который в полной мере поддерживает следующие элементы: - определение данных; - определение представлений; - обработку данных (интерактивную и программную); - условия целостности; - идентификация прав доступа; - границы транзакций (начало, завершение и отмена). 6 Правило обновления представлений. Все представления, которые теоретически можно обновить, должны быть доступны для обновления. 7 Правило добавления, обновления и удаления. Возможность работать с отношением (таблицей) как с одним операндом должна существовать не только при чтении данных, но и при добавлении, обновлении и удалении данных. 8 Правило независимости физических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при любых изменениях способов хранения данных или методов доступа к ним. 9 Правило независимости логических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые теоретически позволяют сохранить нетронутыми содержащиеся в этих таблицах данные. 10 Правило независимости условий целостности. Должна существовать возможность определять условия целостности, специфические для конкретной реляционной базы данных, на подъязыке реляционной базы данных и хранить их в каталоге, а не в прикладной программе. 11 Правило независимости распространения. Реляционная СУБД не должна зависеть от потребностей конкретного пользователя. 12 Правило единственности. Если в реляционной системе есть низкоуровневый язык (обрабатывающий одну запись за один раз), то должна отсутствовать возможность использования его для того, чтобы обойти правила и условия целостности, выраженные на реляционном языке высокого уровня (обрабатывающем несколько записей за один раз). Функциональные зависимости и ключи. Поскольку строки в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру в таблице. Ключевым элементом данных называется такой элемент, по которому можно определить значения других элементов данных. В реляционной базе данных в каждой таблице есть один или несколько столбцов, значения в которых во всех строках разные. Этот столбец (столбцы) называется первичным ключом таблицы. Первичный ключ – это атрибут или группа атрибутов, которые единственным образом идентифицируют каждую строку в таблице. Если в таблице нет полей, значения в которых уникальны, для создания первичного ключа в нее обычно вводят дополнительное поле, значениями которого СУБД может распоряжаться по своему усмотрению. Если первичный ключ представляет собой комбинацию столбцов, то такой первичный ключ называется составным. Вторичныеключиустанавливаются по полям, которые часто используются при поиске или сортировке данных. В отличие от первичных ключей, поля для вторичных ключей могут содержать не уникальные значения. Внешние ключи. Столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом другой таблицы, называется внешним ключом. Обычно в качестве первичного и внешнего ключей используются столбцы с одинаковыми именами из двух различных таблиц. Внешний ключ, как и первичный ключ, тоже может представлять собой комбинацию столбцов. Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей. Внешние ключи являются неотъемлемой частью реляционной модели, поскольку реализуют отношения между таблицами базы данных. По определению «функциональная зависимость – это такая связь между атрибутами В и А одного и того же отношения, когда каждому значению А соответствует только одно значение В». Атрибут А называют детерминантом. Детерминанты могут быть составными, т.е. представлять собой не единичные атрибуты, а группы, состоящие из двух и более атрибутов. Функциональные зависимости являются ограничениями целостности и определяют семантику хранящихся в БД данных. При каждом обновлении СУБД должна проверять их соблюдение. Следовательно, наличие большого количества функциональных зависимостей нежелательно, иначе происходит замедление работы. Для упрощения задачи необходимо сократить набор функциональных зависимостей до минимально необходимого. Нормализация отношений и аномалии модификации. Под нормализацией отношения подразумевается процесс приведения отношения к одной из так называемых нормальных форм (или в дальнейшем НФ). При проектировании баз данных упор в первую очередь делается на достоверность и непротиворечивость хранимых данных, причем эти свойства не должны утрачиваться в процессе работы с данными, т.е. после многочисленных изменений, удалений и дополнений данных по отношению к первоначальному состоянию БД. Для поддержания БД в устойчивом состоянии используется ряд механизмов, которые получили обобщенное название средств поддержки целостности. Эти механизмы применяются как статически (на этапе проектирования БД), так и динамически (в процессе работы с БД). БД должна удовлетворять некоторым ограничениям в процессе создания, независимо от ее наполнения данными. Приведение структуры БД в соответствие этим ограничениям - это и есть нормализация. В целом суть этих ограничений весьма проста: каждый факт, хранимый в БД, должен храниться один-единственный раз, поскольку дублирование может привести к несогласованности между копиями одной и той же информации. Следует избегать любых неоднозначностей, а также избыточности хранимой информации. Важным критерием качества разрабатываемой схемы БД является скорость выполнения операций обновления данных (вставки, модификации, удаления записей). Выбор схемы БД определяет возникновение в процессе ее эксплуатации тех или иных аномалий обновления. Аномалия обновления – появление в базе данных несогласованности данных при выполнении операций вставки, удаления, модификации записей. Аномалии модификации – появление записей с противоречащими значениями в некоторых столбцах при изменении значений соответствующих полей одной записи. Пример. Для отношения Студент (ФИО, Группа, Староста), где в столбце Группа хранится полное название группы, а столбец Староста содержит ФИО старосты группы, изменение значения Староста (например, для устранения ошибки) может привести к существованию более одного старосты одной и той же группы. Аномалии удаления – удаление лишней информации при удалении записи. Пример. Для отношения Студент (ФИО, Группа, Староста), удаление студента может привести к удалению из БД и ФИО старосты группы (в том случае, если для данной группы запись – единственная). Аномалии вставки – добавление лишней информации или возникновение противоречащих значений в некоторых столбцах при вставке новой записи. Пример. Для отношения Студент (ФИО, Группа, Староста), где в столбце Группа хранится полное название группы, а столбец Староста содержит ФИО старосты группы, добавление названия новой группы повлечет обязательное определение ФИО студента и старосты, в то время как эти данные могут быть пока не известны. В то же время, при добавлении нового студента значение поля Староста в новой записи может не совпадать со значением данного поля для другого студента этой же группы. Для сохранения корректности БД необходимо устранять данные аномалии, выполняя дополнительные операции по просмотру и модификации данных. Потери в производительности, вызванные выполнением действий по устранению аномалий, могут быть весьма существенными, при этом данные потери, в большинстве случаев, не являются неизбежными, а определяются неудачным выбором схемы БД. Указанные аномалии связаны с избыточностью данных в БД. Следует различать избыточное и неизбыточное дублирование данных. Неизбыточное дублирование возникает из необходимости хранить идентичные данные, поскольку важен сам факт их идентичности, и удаление хотя бы одного представителя идентичных данных приведет к невосполнимой потере информации. Избыточное дублирование (избыточность) обычно связано с необходимостью задания значения всех атрибутов отношения, при этом дублируемые данные не являются необходимыми, и в случае потери (удаления) могут быть восстановлены по данным одного или нескольких отношений БД. Определить дублирование данных в БД, а значит и предсказать возможность возникновения аномалий обновления можно на этапе проектирования структуры базы данных. Одним из наиболее алгоритмически и понятийно простых методов устранения избыточности хранения данных является метод нормальных форм, который основан на анализе функциональных зависимостей (ФЗ) атрибутов отношений. Свойства отношений. Обновления отношений. Свойства: 1. В отношении нет одинаковых кортежей. Действительно, тело отношения есть множество кортежей и, как всякое множество, не может содержать неразличимые элементы. Таблицы в отличие от отношений могут содержать одинаковые строки. 2. Кортежи не упорядочены (сверху вниз). Тело отношения есть множество, а множество не упорядочено. Это вторая причина, по которой нельзя отождествить отношения и таблицы - строки в таблицах упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых строки идут в различном порядке. 3. Атрибуты не упорядочены (слева направо). Т.к. каждый атрибут имеет уникальное имя в пределах отношения, то порядок атрибутов не имеет значения. Это свойство несколько отличает отношение от математического определения отношения. Это также третья причина, по которой нельзя отождествить отношения и таблицы - столбцы в таблице упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке. 4. Все значения атрибутов атомарны. Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что угодно - массивы, структуры, и даже другие таблицы. Проектирование нормализованной БД. Процесс в ходе, которого решается, какой вид будет иметь созданная база данных, называется проектированием базы данных. Работа по проектированию базы данных включает реализацию следующих структур: Базы данных; Таблиц, которые будут входить в базу данных; Столбцов, принадлежащих каждой таблице; Взаимосвязей между таблицами и столбцами. Процесс преобразования отношений базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную логическую избыточность, и не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение физического объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации. Как отмечает К. Дейт, общее назначение процесса нормализации заключается в следующем: исключение некоторых типов избыточности; устранение некоторых аномалий обновления; разработка проекта базы данных, который является достаточно «качественным» представлением реального мира, интуитивно понятен и может служить хорошей основой для последующего расширения; упрощение процедуры применения необходимых ограничений целостности. Процесс проектирования базы данных принято разделять на три основные фазы: - концептуальное проектирование — построение модели на основе информации, полученной при изучении анализируемой области независимо от ее реализации. Основой модели является определение типов важнейших сущностей и существующих между ними связей. - логическое проектирование — преобразование концептуального представления в логическую структуру базы данных, включая проектирование отношений; - физическое проектирование — создание описания конкретной реализации базы данных (с помощью выбранной СУБД): описание структуры хранения данных и методов доступа. Первая нормальная форма. Отношение находится в первой нормальной форме тогда и только тогда, когда в любом допустимом значении отношения каждый его кортеж содержит только одно значение для каждого из атрибутов. В реляционной модели отношение всегда находится в первой нормальной форме по определению понятия отношение. Что же касается различных таблиц, то они могут не быть правильными представлениями отношений и, соответственно, могут не находиться в 1NF. В соответствии с определением К. Дж. Дейта для такого случая, таблица нормализована (эквивалентно — находится в первой нормальной форме) тогда и только тогда, когда она является прямым и верным представлением некоторого отношения. Конкретнее, рассматриваемая таблица должна удовлетворять следующим пяти условиям: Нет упорядочивания строк сверху-вниз. Нет упорядочивания столбцов слева-направо. Нет повторяющихся строк. Каждое пересечение строки и столбца содержит ровно одно значение из соответствующего домена (и больше ничего). Все столбцы являются обычными. «Обычность» всех столбцов таблицы означает, что в таблице нет «скрытых» компонентов, которые могут быть доступны только в вызове некоторого специального оператора взамен ссылок на имена регулярных столбцов, или которые приводят к побочным эффектам для строк или таблиц при вызове стандартных операторов. Таким образом, например, строки не имеют идентификаторов кроме обычных значений потенциальных ключей (без скрытых «идентификаторов строк» или «идентификаторов объектов»). Они также не имеют скрытых временных меток. Вторая нормальная форма. Вторая нормальная форма основана на понятии полной функциональной зависимости. Атрибут В называется полностью функционально зависимым от атрибута А, если атрибут В функционально зависит от полного значения атрибута А и не зависит от какого-либо подмножества атрибута А. Отношение находится во 2НФ, если оно находится в 1НФ и каждый его атрибут, не входящий в состав первичного ключа, функционально полно зависит от первичного ключа. Другими словами, второе правило нормализации требует, чтобы любой неключевой столбец зависел от всего первичного ключа, а не от его отдельных компонентов. Это правило относится к случаю, когда первичный ключ образован из нескольких столбцов. Первичные ключи всех таблиц из учебной базы данных являются простыми (состоят из одного столбца), поэтому все таблицы находятся не только в 1НФ, но и однозначно во 2НФ. Третья нормальная форма. Третья нормальная форма основана на понятии транзитивной зависимости. Если для атрибутов А, В и С некоторого отношения существуют зависимости С от В и В от А, то говорят, что атрибут С транзитивно зависит от атрибута А через атрибут В. Отношение находится в 3НФ, если оно находится в 1НФ и 2НФ, и в нем не существует транзитивных зависимостей неключевых атрибутов от первичного ключа. Другими словами, третья нормальная форма требует, чтобы ни один неключевой столбец не зависел бы от другого неключевого столбца. Любой неключевой столбец должен зависеть только от столбца первичного ключа. Нормализация на основе декомпозиции. Нормальная форма Бойса - Кодда. Нормальная форма Бойса-Кодда учитывает функциональные зависимости, в которых участвуют все потенциальные ключи отношения, а не только его первичный ключ. Для отношения с единственным потенциальным ключом 3НФ и НФБК эквивалентны. Отношение находится в НФБК тогда и только тогда, когда каждый его детерминант является потенциальным ключом. Четвертая нормальная форма. Пятая нормальная форма. Четвертая нормальная форма связана с понятием многозначной зависимости. В случае многозначной зависимости, существующей между атрибутами А, В и С некоторого отношения, для каждого значения А имеется набор значений атрибута В и набор значений атрибута С. Однако входящие в эти наборы значения атрибутов В и С не зависят друг от друга. Отношение находится в 4НФ, если оно находится в НФБК и не содержит многозначных зависимостей. Пятой нормальной формой называется отношение, которое не содержит зависимостей соединения. Зависимость соединения – это такая ситуация, при которой декомпозиция отношения может сопровождаться генерацией ложных строк при обратном соединении декомпозированных отношений с помощью операции естественного соединения. Представление связей. Рекурсивная связь. Модель Сущность-Связь (ER-модель)— модель данных, позволяющая описывать концептуальные схемы. Представляет собой графическую нотацию, основанную на блоках и соединяющих их линиях, с помощью которых можно описывать объекты и отношения между ними какой-либо другой модели данных. В этом смысле ER-модель является мета-моделью данных, то есть средством описания моделей данных. ER-модель удобна при прототипировании (проектировании) информационных систем, баз данных, архитектур компьютерных приложений, и других систем (далее, моделей). С её помощью можно выделить ключевые сущности, присутствующие в модели, и обозначить отношения, которые могут устанавливаться между этими сущностями. ER-модель является одной из самых простых визуальных моделей данных (графических нотаций). Она позволяет обозначить структуру «крупными мазками», в общих чертах. Рекурсия (или рекурсивная связь) – это связь класса сущностей с самим собой. Иерархической рекурсивной связью (или просто иерархической рекурсией) называется любая рекурсивная связь типа «не более одного ко многим». Иерархическая рекурсия чаще всего используется для того, чтобы хранить данные древовидной структуры. При задании иерархической рекурсивной связи первичный ключ родительского класса сущностей должен мигрировать в качестве внешнего ключа в состав обязательно неключевых атрибутов того же класса сущностей. Все это необходимо для поддержания логической целостности самого понятия «иерархическая рекурсия». Таким образом, с учетом всего вышесказанного, можно сделать вывод, что иерархическая рекурсивная связь может быть только не обязательно не идентифицирующей и никакой другой, потому что в случае использования любого другого вида связи, Null-значения для внешнего ключа были бы недопустимы, и рекурсия была бы бесконечной. Важно также помнить, что атрибуты не могут появляться дважды в одном и том же классе сущностей под одним и тем же именем. Поэтому атрибуты мигрировавшего ключа обязательно должны получить так называемое имя роли. Таким образом, в иерархической рекурсивной связи атрибуты узла расширяются внешним ключом, представляющим необязательную ссылку на первичный ключ узла, являющийся его непосредственным предком. Сетевая рекурсивная связь классов сущностей между собой является как бы многомерным аналогом иерархической рекурсивной связи. Только если иерархическая рекурсия определялась как рекурсивная связь типа «не более одного ко многим», то сетевая рекурсия представляет собой такую же рекурсивную связь, только уже типа «многие ко многим». Связи вида сетевой рекурсии предназначены для представления графовых структур данных (тогда как иерархические связи применяются, как мы помним, исключительно для реализации древовидных структур). Но, так как в связи вида сетевой рекурсии заданы связи типа именно «многие ко многим», без их дополнительной детализации не обойтись. Поэтому для уточнения всех имеющихся в схеме связей типа «многие ко многим» становится необходимым создать новый самостоятельный класс сущностей, содержащий все ссылки на предка или потомка связи «Предок – Потомок». Такой класс в общем случае называется классом ассоциативных сущностей. Таким образом, первичный ключ класса сущностей, представляющего узлы сети, должен дважды мигрировать в классы ассоциативных сущностей. В этом классе мигрировавшие ключи в совокупности должны образовывать составной первичный ключ. Из всего вышесказанного можно сделать вывод, что устанавливающие связи при использовании сетевой рекурсии должны быть не полностью идентифицирующими и никакими другими. Так же как и при использовании иерархической рекурсивной связи, при применении в качестве связи сетевой рекурсии ни один атрибут не может появляться дважды в одном классе сущностей под одним и тем же именем. Поэтому, как и в прошлый раз, специально оговаривается, что все атрибуты мигрирующего ключа обязательно должны получить имя роли. Преобразование концептуальной модели в реляционную модель. Концептуальная модель данных состоит из связанных между собой сущностей. Основными характеристиками сущности является атрибут и ПК сущности. Связь характеризуется степенью и классом принадлежности. Существует алгоритм, по которому концептуальная модель может быть переведена в реляционную, причем гарантирована по крайней мере 3НФ. Преобразование сущностей 1. Каждой сущности ставится в соответствие отношение. 2. Каждый атрибут сущности становится атрибутом отношения, которому приписывают тип данных и свойство допустимости/недопустимости для него значения NULL (не определен). 3. Первичный ключ сущности становится ПК отношения (PRIMARY KEY). Атрибуты, входящие в ПК, получают свойство обязательности (NOT NULL) и уникальности (UNIQUE). Преобразование связей Преобразование связи производится согласно значениям ее характеристик: 1:1, КЛАСС ПРИНАДЛЕЖНОСТИ (КП) ОБЕИХ СУЩНОСТЕЙ ОБЯЗАТЕЛЬНЫЙ. Требуется одно отношение, его первичным ключом может стать ключ любой из сущностей. 1:1, КП ОДНОЙ СУЩНОСТИ ОБЯЗАТЕЛЬНЫЙ, ДРУГОЙ - НЕОБЯЗАТЕЛЬНЫЙ. Требуется два отношения, по одному на каждую сущность. Ключ каждой сущности становится ПК соответствующих отношений. Кроме того, ключ сущности, у которой КП необязательный, добавляется в качестве атрибута (FOREING KEY) в отношение, выделенное для сущности с обязательным КП. В отношение, выделенное для сущности с обязательным КП, включаются также атрибуты, принадлежащие связи (если они есть). 1:1, КП ОБЕИХ СУЩНОСТЕЙ НЕОБЯЗАТЕЛЬНЫЙ. Требуется три отношения, по одному на каждую сущность, и отношение связи. Ключ каждой сущности становится ПК соответствующих отношений. Отношение связи содержит в качестве ключевых атрибутов (FOREINGKEYS) ключи обеих сущностей. В отношение связи включаются также атрибуты, принадлежащие связи (если они есть). 1:*, КП МНОГОСВЯЗНОЙ СУЩНОСТИ ЯВЛЯЕТСЯ ОБЯЗАТЕЛЬНЫМ. Требуется два отношения, по одному на каждую сущность. Ключ каждой сущности становится ПК соответствующих отношений. Кроме того, ключ односвязной сущности добавляется в качестве атрибута (FOREINGKEY) в отношение, выделенное для многосвязной сущности. Атрибуты связи (если они есть) добавляются в таблицу для многосвязной сущности. 1:*, КП МНОГОСВЯЗНОЙ СУЩНОСТИ ЯВЛЯЕТСЯ НЕОБЯЗАТЕЛЬНЫМ. Требуется три отношения, по одному на каждую сущность, и отношение связи. Ключ каждой сущности становится ПК соответствующих отношений. Отношение связи содержит в качестве ключевых атрибутов (FOREING KEYS) ключи обеих сущностей. В отношение связи включаются также атрибуты, принадлежащие связи (если они есть). *:*, КП ОБЕИХ СУЩНОСТЕЙ НЕ ИМЕЕТ ЗНАЧЕНИЯ. Требуется три отношения, по одному на каждую сущность, и отношение связи. Ключ каждой сущности становится ПК соответствующих отношений. Отношение связи содержит в качестве ключевых атрибутов (FOREING KEYS) ключи обеих сущностей. В отношение связи включаются также атрибуты, принадлежащие связи (если они есть). ПРЕОБРАЗОВАНИЕ РЕКУРСИВНЫХ СВЯЗЕЙ. Отношение, имеющее рекурсивную связь, в качестве ПК имеет ключ сущности, а также включает в себя этот же ключ сущности в качестве неключевого атрибута (FOREING KEY). Целостность данных. Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности. Для того чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются ограничения, называющиеся ограничениями целостности. Ограничения целостности (целостная составляющая) реляционной модели можно разделить на две группы – требование целостности сущностей и требование целостности ссылок. Первое из требований — требование целостности сущности — означает, что первичный ключ должен полностью идентифицировать каждую сущность, а поэтому не допускается наличие неопределенных (null) значений в составе первичного ключа. Требование целостности сущностей также подразумевает отсутствие полей с множественным характером значений атрибута, что обеспечивается нормализацией таблиц-отношений. Требование целостности ссылок заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице, т.е. для любой записи с конкретным значением внешнего ключа должна обязательно существовать связанная запись в родительской таблице с соответствующим значением первичного ключа. Архитектура клиент – сервер. Архитектура «клиент-сервер» была разработана с целью устранения недостатков, имеющихся в модели файлового сервера. «Клиент-сервер» – это модель взаимодействия компьютеров в сети. В зависимости от того, как распределены логические компоненты приложения между клиентами и серверами, различают четыре модели архитектуры клиент-сервер: |