Ответы на билеты по дисциплине Базы данных. Базы данных. Вопросы к экзамену по дисциплине Базы данных
 Скачать 0.68 Mb. Скачать 0.68 Mb.
|

|
SELECT FROM [ON Чем отличаются результаты выполнения соединений конструкций JOIN и INNERJOIN? Во время работы с данными, хранящимися в нормализованной базе данных, часто приходится сталкиваться с ситуациями, в которых всю необходимую информацию невозможно получить только из одной таблицы. В других случаях вся информация, которая должна быть получена, находится в одной таблице, но выборка этих данных должна осуществляться по условиям, подлежащим проверке по другой таблице. Конструкция JOIN предназначена для использования именно в таких ситуациях. Конструкция JOIN выполняет именно ту задачу, на которую указывает смысл соответствующего английского глагола, — соединяет информацию из двух таблиц в один результирующий набор. Результирующий набор можно рассматривать как «виртуальную» таблицу. В него входят и столбцы, и строки, а сами столбцы характеризуются определенными типами данных. Результирующий набор можно использовать так, как если бы это была таблица, и обращаться к нему для выполнения других запросов. Конкретные способы, применяемые в конструкции JOIN для соединения информации из двух таблиц в один результирующий набор, зависят от того, какие указания предусмотрены в этой конструкции, касающиеся сбора данных из разных таблиц, поэтому и предусмотрены четыре разных типа конструкции JOIN. Но все разности конструкций JOIN имеют одну общую отличительную особенность в том, что в них одна строка согласуется с одной или несколькими другими строками для получения результирующей строки, представляющей собой надмножество, созданное путем соединения нолей из нескольких записей. Например, предположим, что строки с данными о кинофильмах берутся из таблицы Films Таблица 1. Одна строка с данными из таблицы Films
Теперь перейдем к рассмотрению строки из таблицы с данными об актерах, называемой Actors (таблица 2). Таблица 2. Одна строка с данными из таблицы Actors
Конструкция JOIN позволяет создать одну строку из двух строк, находящихся в полностью отдельных таблицах (таблица 3). Таблица 3. Строка, полученная в результате соединения строк с данными из таблиц Films и Actors
С помощью этой конструкции JOIN строки соединяются на основании СВЯЗИ "один к одному" (по крайней мере такое впечатление складывается на основании приведениях данных). Одна строка из таблицы Films соединяется с одной строкой из таблицы Actors. Немного дополним условия этого примера и рассмотрим, что при этом произойдет. Введем еще одну строку в таблицу Actors (таблица 4). Таблица 4. Две строки с данными из таблицы Actors
Теперь рассмотрим, что произойдет после соединения дополненной таблицы Actors с той же таблицей Films (содержащей только одну строку) (таблица 5). Таблица 5. Результаты соединения дополненной таблицы Actors с таблицей Films
Вполне очевидно, что полученные данные существенно изменились, поскольку больше нельзя утверждать, что между таблицами наблюдается связь «один к одному»; скорее, здесь присутствует связь «один ко многим». О 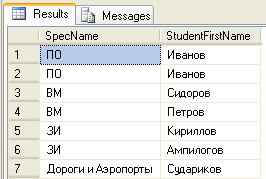 тличительная особенность INNER JOIN состоит в том, что она возвращает только те строки, которые были согласованны по всем полям. тличительная особенность INNER JOIN состоит в том, что она возвращает только те строки, которые были согласованны по всем полям. Отметим, что ее помощью можно создавать исключительное соединение, т.е. соединение, в котором исключены все строки, не имеющие определенного значения в обеих таблицах Пример: USE Universitet Select sp.SpecName, stud.StudentFirstName FROM Spec AS sp INNER JOIN Students AS stud ON stud.IdSpec = sp.IdSpec GO Перечислите общие свойства конструкции INNERJOINи конструкции WHERE. До сих пор при описании особенностей конструкции INNER JOIN фактически затрагивались только те концепции, которые применимы к соединениям любых других типов, поскольку принципы определения порядка расположения столбцов в результирующем наборе и применения псевдонимов являются полностью одинаковыми для конструкций JOIN любых типов. А то, в чем конструкция INNER JOIN отличается от конструкций JOIN других типов осталось не рассмотренным. Отметим, что ее помощью можно создавать исключительное соединение, т.е. соединение, в котором исключены все строки, не имеющие определенного значения в обеих таблицах (в левой таблице, как называют таблицу, указанную в первую очередь, и в правой таблице, заданной во вторую очередь). Рассмотрим несколько примеров того, как проявляется это свойство. Допустим, что имеется таблица Customers, в которой собраны все данные об именах и адресах заказчиков. Но наличие большого списка заказчиков компании отнюдь не означает, что в текущий момент компанией действительно выполняются заказы, полученные от всех заказчиков. Фактически можно смело предположить, что в текущий момент имеются такие заказчики, которые не разместили в компании ни одного заказа. Например, требуется выполнить запрос, позволяющий отобрать информацию обо всех заказчиках, заказы которых выполняются в настоящее время. SELECT DISTINCT с.CustomerID, с.CompanyName FROM Customers с INNER JOIN Orders о ON c.CustomerID = o.CustomerlD Обратите внимание на то, что в запросе используется ключевое слово DISTINCT, поскольку достаточно знать только количество заказчиков, сделавших заказы (причем достаточно только одного упоминания каждого заказчика), а не количество заказов. Если бы в этом запросе отсутствовало ключевое слово DISTINCT, то была бы возвращена отдельная строка, относящаяся к каждому заказчику для каждой строки из таблицы Orders, в которой имеется информация об этом заказчике. Теперь попытаемся получить информацию об общем количестве заказчиков и для этого вызовем на выполнение следующий простой запрос с агрегирующей функцией COUNT: SELECT COUNT (*) AS "No. Of Records" FROM Customers Применение конструкции INNER JOIN приводит к исключению строк в связи с тем, что не обнаруживаются соответствующие им строки в другой таблице, а использование конструкции WHERE приводит к исключению строк из возвращаемого набора, поскольку эти строки не соответствуют сданным критериям. Дайте определение связующей таблице? Для чего и в каком случае используются связующие таблицы? Связующей таблицей (иногда называемой также таблицей ассоциации, или таблицей слияния) называют любую таблицу, основным назначением которой является не хранение собственных данных, а создание связей между данными, хранимыми в других таблицах. Такие таблицы можно рассматривать как средства "обеспечения взаимодействие", или "создания связей" между двумя или несколькими таблицами. В частности, связующие таблицы позволяют найти выход в такой часто складывающейся ситуации, когда имеет место так называемая связь "многие ко многим" между таблицами. В такой ситуации две таблицы содержат связанные друг с другом данные, причем и в той и s другой таблице может находиться большое количество строк, которые согласуются со многими строками в другой таблице. СУБД SQL Server не позволяет непосредственно реализовывать подобные связи, поэтому применяются связующие таблицы, позволяющие разделить связь "многие ко многим" на две связи "один ко многим", а последние поддерживаются СУБД SQL Server.
|