|
|
Ответы на билеты по дисциплине Базы данных. Базы данных. Вопросы к экзамену по дисциплине Базы данных
Вопросы к экзамену по дисциплине «Базы данных»
История развития баз данных.
До 1968 года была только обработка файлов, она предшествовала обработке баз данных. Данные хранились в виде списков. Характер обработки определялся всеобщим использованием в качестве носителя магнитной ленты.
В 1968-1980 используются иерархические и сетевые модели. Это эра обработки нереаляционных баз данных. Выдающейся иерархической моделью данных была DL/I фирмы IBM.Первая СУБД называлась IMS.
С коммерческим успехом хранилищ на дисках в середине 1960-х стало возможным получение непоследовательного, или прямого, доступа к записям.
Реляционная модель впервые была предложена Е. Ф. Коддом в 1970 году. Наиболее известным из этих продуктов является DB2 — СУБД, которая активно используется и поныне.
SQL Server был разработан в Sybase и в конце восьмидесятых годов продан Microsoft. Сегодня DB2, Oracle и SQL Server являются наиболее выдающимися коммерческими СУБД.
В 1982 году стали применяться первые СУБД для микропроцессоров. Фирма Ashton-Tate разработала dBase, Microrim – R:Base, a Borland – Paradox.
С 1985 года начинает развиваться интерес к объектно-ориентированным СУБД (ООСУБД). С развитием объектно-ориентированного программирования были предложены ООСУБД.
В 1991 году компания Microsoft выпустила Access. Персональная СУБД. Созданная как элемент Windows постепенно вытеснила с рынка все другие персональные СУБД.
В 1995 году выпускаются первые приложения баз данных для Интернета. Базы данных стали ключевыми компонентами Интернет-приложений. Популярность Интернета существенно повысила необходимость в базах данных и требования к ним.
С 1997 года началось применение XML к обработке баз данных. Использование XML решило проблемы, которые долго стояли перед базами данных. Ведущие производители стали интегрировать XML в свои СУБД.
Основные понятия теории баз данных.
Данные – информационное представление в виде, позволяющем автоматизировать ее сбор, хранение, обработку человеком или информационным средством.
База данных (БД) – именованная совокупность данных отражающая состояние объекта и их отношение в рассматриваемой предметной области. Это взаимосвязанные данные, при такой минимальной избыточности, которая допускает и использование оптимальным образом для одного или нескольких приложений.
Автоматизированная информационная система – система реализующая автоматический сбор, обработку и манипулирование данными, функционирующая на основе ЭВМ и других технических средств, и включающее соответствующее ПО и персонал.
Под задачами обработки данных обычно понимается специальный класс решаемых с помощью компьютера задач, связанных с видом, хранением, сортировкой, отбором по заданному условию и группировкой записей однородной структуры.
Каждая информационная структура(БД) в зависимости от ее предназначения имеют дело с той или иной частью реального мира, которую принято называть предметной областью БД.
Под БД возможно понимать совместно использованный набор логически связанных данных, обеспечивающий выполнение информационных потребностей пользователя.
СУБД(система управления БД) – ПО с помощью которого пользователи могут определять, создавать и поддерживать БД, а так же получать к ней контролируемый доступ.
Ключевую роль при обеспечении эффективного хранения данных имеют методы поддержания логических связей между данными.
В зависимости от способов организации связей выделяют различные модели данных: иерархическую, сетевую, реляционную.
Программы с помощью которых пользователи работают с БД называют приложениями.
Развитие систем обработки данных. Современные тенденции в обработке данных.
Первый этап развития СУБД связан с организацией баз данных на больших машинах.
Базы данных хранились во внешней памяти центральной ЭВМ, пользователями этих баз данных были задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках и запускались как обычные числовые программы. Мощные операционные системы обеспечивали возможность условно параллельного выполнения всего множества задач.
Особенности этого этапа развития выражаются в следующем:
Все СУБД базируются на мощных мультипрограммных операционных системах (MVS, SVM, RTE, OSRV, RSX, UNIX), поэтому в основном поддерживается работа с централизованной базой данных в режиме распределенного доступа.
Функции управления распределением ресурсов в основном осуществляются операционной системой (ОС).
Поддерживаются языки низкого уровня манипулирования данными, ориентированные на навигационные методы доступа к данным.
Значительная роль отводится администрированию данных.
Проводятся серьезные работы по обоснованию и формализации реляционной модели данных, и была создана первая система (System R), реализующая идеологию реляционной модели данных.
Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
Результаты научных исследований открыто обсуждаются в печати, идет мощный поток общедоступных публикаций, касающихся всех аспектов теории и практики баз данных, и результаты теоретических исследований активно внедряются в коммерческие СУБД.
Появляются первые языки высокого уровня для работы с реляционной моделью данных. Однако отсутствуют стандарты для этих первых языков.
Особенности этапа персональных компьютеров:
Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. И это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
Большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с БД как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования. Инструментальная среда состояла из готовых элементов приложения в виде шаблонов экранных форм, отчетов, этикеток (Labels), графических конструкторов запросов, которые достаточно просто могли быть собраны в единый комплекс.
Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц.
В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД и в связи с этим — к отсутствию инструментальных средств администрирования БД.
И, наконец, последняя и в настоящий момент весьма положительная особенность — это сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286.
В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства — очень широко использовавшиеся до недавнего времени СУБД Dbase (DbaseIII+, DbaseIV), FoxPro, Clipper, Paradox.
Особенности этапа распределенных БД:
Практически все современные СУБД обеспечивают поддержку полной реляционной модели, а именно:
О структурной целостности — допустимыми являются только данные, представленные в виде отношений реляционной модели;
О языковой целостности, то есть языков манипулирования данными высокого уровня (в основном SQL);
О ссылочной целостности, контроля за соблюдением ссылочной целостности в течение всего времени функционирования системы, и гарантий невозможности со стороны СУБД нарушить эти ограничения.
Большинство современных СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД на разных платформах, практически неразличим.
Необходимость поддержки многопользовательской работы с базой данных и возможность децентрализованного хранения данных потребовали развития средств администрирования БД с реализацией общей концепции средств защиты данных.
Потребность в новых реализациях вызвала создание серьезных теоретических трудов по оптимизации реализаций распределенных БД и работе с распределенными транзакциями и запросами с внедрением полученных результатов в коммерческие СУБД.
Для того чтобы не потерять клиентов, которые ранее работали на настольных СУБД, практически все современные СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития.
Именно к этому этапу можно отнести разработку ряда стандартов в рамках языков описания и манипулирования данными начиная с SQL89, SQL92, SQL99 и технологий по обмену данными между различными СУБД, к которым можно отнести и протокол ODBC (Open DataBase Connectivity), предложенный фирмой Microsoft.
Именно к этому этапу можно отнести начало работ, связанных с концепцией объектно-ориентированных БД — ООБД. Представителями СУБД, относящимся к второму этапу, можно считать MS Access 97 и все современные серверы баз данных Oracle7.3,Oracle 8.4 MS SQL6.5, MS SQL7.0, System 10, System 11, Informix, DB2, SQL Base и другие современные серверы баз данных, которых в настоящий момент насчитывается несколько десятков.
Перспективы развития СУБД. Этот этап характеризуется появлением новой технологии доступа к данным — интранет. Основное отличие этого подхода от технологии клиент-сервер состоит в том, что отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной базой данных используется стандартный браузер Интернета, например Microsoft Internet Explorer или Netscape Navigator, и для конечного пользователя процесс обращения к данным происходит аналогично скольжению по Всемирной Паутине. При этом встроенный в загружаемые пользователем HTML-страницы код, написанный обычно на языке Java, Java-script, Perl и других, отслеживает все действия пользователя и транслирует их в низкоуровневые SQL-запросы к базе данных, выполняя, таким образом, ту работу, которой в технологии клиент-сервер занимается клиентская программа. Удобство данного подхода привело к тому, что он стал использоваться не только для удаленного доступа к базам данных, но и для пользователей локальной сети предприятия. Простые задачи обработки данных, не связанные со сложными алгоритмами, требующими согласованного изменения данных во многих взаимосвязанных объектах, достаточно просто и эффективно могут быть построены по данной архитектуре. В этом случае для подключения нового пользователя к возможности использовать данную задачу не требуется установка дополнительного клиентского программного обеспечения. Однако алгоритмически сложные задачи рекомендуется реализовывать в архитектуре "клиент-сервер" с разработкой специального клиентского программного обеспечения.
Типовая организация современной СУБД.
Логически в современной СУБД можно выделить:
Ядро СУБД
Компилятор языка БД
Подсистему поддержки времени выполнения
Набор утилит
Ядро СУБД отвечает за (функции):
Управление данными во внешней памяти (выгрузка загрузка файлов)
Управление буферами оперативной памяти
Управление транзакциями и журнализацией
Транзакция – последовательность операций над БД рассматриваемое СУБД как
единое целое.
Журнал – особая часть БД, недоступная пользователю и отображающая все изменения основной части БД.
Ядро СУБД содержит 4 менеджера:
Менеджер данных
Менеджер буфера
Менеджер транзакции
Менеджер журнала
Компилятор языка БД. Основная функция компилятора языка БД является компиляция операторов языка БД в некоторую выполненную программу.
Языки БД являются непроцедурными, т.е. оператор языка определяет некоторые действия к БД, но при этом не является процедурой. Поэтому именно компилятор языка должен решить каким образом выполняется команда.
Результатом компиляции в любом случает должно выполненная программа представленная в машинном коде.
Операция компиляции производится с помощью подсистемы поддержки времени выполнения представляют собой интерпретатор внутреннего языка.
Модели данных. Классификация моделей данных.
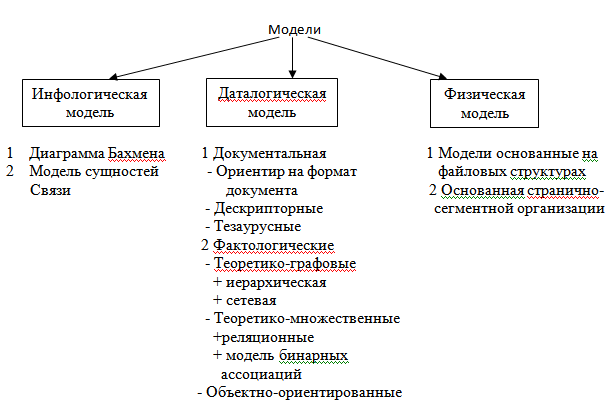
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом.
Диаграмма Бахмена – ориентированный граф, предназначающийся для того чтобы отображать отношения к БД и состоящий из вершин соответствующих типов записи и дуг соответствующих отношениям.
Чаще всего концептуальная модель базы данных включает в себя:
описание информационных объектов, или понятий предметной области и связей между ними.
описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель как правило осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т.д.
Теоретико – множественные модели данных.
Появление теоретико-множественных моделей в системах баз данных было предопределено настоятельной потребностью пользователей в переходе от работы с
элементами данных, как это делается и графовых моделях, к работе с некоторыми макрообъсктамн. Основной моделью в этом классе является реляционная модель данных. Простота и наглядность модели для пользователей-непрограммистов, с одной стороны, и серьезное теоретическое обоснование, с другой стороны, определили большую популярность этой модели. Кроме того, развитие формального аппарата представления и манипулирования данными в рамках реляционной модели сделали се наиболее перспективной для использования в системах представления знаний, что обеспечивает качественно иной подход к обработке данных в больших информационных системах.
Теоретико – графовые модели данных.
Эти модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов, В зависимости от типа графа выделяют иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной.
Сетевая модель. Сетевой граф базы данных. Достоинства и недостатки.
Стандарт сетевой модели впервые был определен в 1975 году организацией
CODASYL (Conference of Data System Languages), которая определила базовые
понятия модели и формальный язык описания.
Базовыми объектами модели являются:
элемент данных;
агрегат данных;
запись;
набор данных.
Элемент данных — то же, что и в иерархической модели, то есть минимальная
информационная единица, доступная пользователю с использованием СУБД.
Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа' вектор соответствует линейному набору элементов данных.
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию ≪сегмент≫ в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи.
Следующим базовым понятием в сетевой модели является понятие ≪Набор≫.
Набором называется двухуровневый граф, связывающий отношением ≪один-ко-многим≫ два типа записи.
Набор фактически отражает иерархическую связь между двумя типами записей.
Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора.
Иерархическая модель данных. Достоинства и недостатки.
Иерархическая модель данных является наиболее простой среди всех даталогических моделей. Исторически она появилась первой среди всех диалогических моделей: именно эту модель поддерживает первая из зарегистрированных промышленных СУБД IMS фирмы IBM.
Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов. Иерархия проста и естественна в отображении взаимосвязи между классами объектов.
Основными информационными единицами в иерархической модели являются: база данных (БД), Сегмент и поле, Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД.
Сегмент называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента — это поименованная совокупность типов элементов данных, в него
входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента.
Тип сегмента, находящийся на более высоком уровне иерархии, называется логически исходным по отношению к типам сегментов, соединенным с данным направленными иерархическими ребрами, которые в свою очередь называются логически подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-предками, а подчиненные сегменты называют сегментами-потомками.
Схема иерархической БД представляет собой совокупность отдельных деревьев,
каждое дерево в рамках модели называется физической базой данных. Каждая
физическая БД удовлетворяет следующим иерархическим ограничениям:
в каждой физической БД существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента;
каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов;
каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским ) сегментом.
Очень важно понимать различие между сегментом и типом сегмента — оно такое же, как между типом переменной и самой переменной: сегмент является экземпляром типа сегмента.
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи.
Трехуровневая архитектура базы данных.
В основу СУБД была положена:
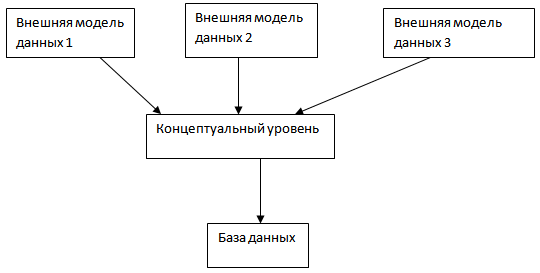
Уровень внешних моделей – самый верхний уровень, где каждая модель имеет свое видение данных. На внешнем уровне каждое приложение обрабатывает необходимые только ему данные.
Концептуальный уровень – логическая организация всех имеющихся на внешнем уровне моделей, в единую обобщенную модель предметной области.
Физический уровень – данные (БД) в виде файлов и т.д. на внешних носителях информации.
Свойства проектируемой СУБД.
СУБД для хранилищ данных представляет собой целостную систему, которая обеспечивает поддержку и управление одной или несколькими логическими БД. В дополнение к поддержке реляционной модели данных, СУБД должны обеспечивать доступ к данным со стороны внешних независимых приложений и включать механизмы контроля различных параметров доступа пользователей. Важным также является тот факт, что сама СУБД не является хранилищем данных, а только предоставляет платформу для его развертывания.
В свою очередь, хранилище данных представляет собой информационную базу, объединяющую в единое целое несколько разнородных источников данных. Структура хранилища позволяет добавлять дополнительные источники данных без необходимости перепроектирования. Хранилище данных может быть любого размера.
В первую очередь, важно грамотно оценить основные технические характеристики СУБД, такие как масштабируемость, управляемость, безопасность, высокий уровень доступности и послеаварийного восстановления, поддержка смешанных нагрузок, дополнительных структур данных и возможностей по их загрузке. Подобный продукт должен обладать рядом свойств, позволяющих управлять значительными объемами разнородных данных, поддерживать сложные модели данных, быть независимым от конкретных приложений и иметь очень высокую надежность.
Одним из основных критериев при выборе СУБД является полнота и завершенность продукта. Необходимо, чтобы система отвечала фундаментальным требованиям масштабируемости и управления рабочими нагрузками. Очень важным фактором является возможность СУБД работать на нескольких платформах при поддержке различных операционных систем и масштабироваться в соответствии с используемыми инструментальными средствами. Необходимо определить, способна ли система эффективно использовать мощности операционной платформы, чтобы обеспечить оптимальную производительность сложного хранилища данных.
Функции СУБД.
Управление данными во внешней памяти:
Транзакция успешно выполняет в СУБД фиксированные изменения БД
Если какое-либо из изменений не состоялось, то эта транзакция не отображается на БД.
Механизм транзакций является обязательным условием работы любой СУБД.
Управление буферами оперативными памяти.
СУБД работает с БД значительного объема, поэтому все классические СУБД имеют свои собственные буферы оперативной памяти, в которые и выполняют подгрузку данных.
Управление транзакциями
Функции включают в себя обеспечение необходимой структур внешней памяти как для хранения данных, непосредственно входящих в БД.
Пользователь не обязан знать, какую файловую систему использует СУБД.
Журнализация
Журнал – особая часть СУБД, которая фиксирует все изменения БД, надежность хранения БД, СУБД должно восстановить последнее согласованное состояние рабочей БД после аппаратного или программного сбоя.
Аппаратные сбои:
Мягкие сбои (внезапная остановка работоспособности)
Жесткие сбои (потеря информации на носителе)
Программные сбои:
Аварийное выключение СУБД
Завершение работы приложения (аварийное)
Жизненный цикл баз данных. Этап анализа и проектирования.
Как и любой программный продукт БД создаются, функционируют и устаревают. Поэтому в любом жизненном цикле БД можно выделить 3 основных этапа:
Анализ и проектирование БД
Формулирование задачи и анализ требований
Концептуальное проектирование
Проектирование реализаций
Реализация БД
Непосредственная реализация
Физическое проектирование
Тестирование
Поддержка БД
Анализ функционирования и поддержка исходного варианта БД
Адаптация, модернизация и поддержка переработанных вариантов БД.
На первом этапе осуществляется предварительное планирование системы Бд. Строится общая информационная модель, осуществляется сбор информации по предметной области для которой разрабатывается БД. Важной частью данного этапа является проверка осуществимости проекта:
Технологическая осуществимость. Выясняется существует ли оборудование или ПО, необходимое для проектирования БД, наличие необходимых ресурсов.
Операционная осуществимость. Выясняется наличие экспертов и персонала, необходимое для работы БД, анализируются требования к квалификации и опыту специалистов.
Проверка экономической целесообразности.
Влияние БД на стратегию
Результат работы данного этапа заключается в выполнении следующих 4 задач:
Определить цели системы БД путем анализа информации потребности пользователя(с привлечением знаний эксперта)
Определение пользовательских требований и построение концептуальной модели
Определение общих требований к оборудованию и ПО
Разработка поэтапного плана создания системы.
Логическое проектирование базы данных.
Логическое проектирование базы данных. Процесс создания модели используемой на предприятии информации на основе выбранной модели организации данных, но без учета типа целевой СУБД и других физических аспектов реализации.
Второй этап проектирования базы данных называется логическим проектированием базы данных. Его цель состоит в создании логической модели данных для исследуемой части предприятия. Концептуальная модель данных, созданная на предыдущем этапе, уточняется и преобразуется в логическую модель данных.Логическая модель данных учитывает особенности выбранной модели организации данных в целевой СУБД (например, реляционная модель).
Если концептуальная модель данных не зависит от любых физических аспектов реализации, то логическая модель данных создается на основе выбранной модели организации данных целевой СУБД. Иначе говоря, на этом этапе уже должно быть известно, какая СУБД будет использоваться в качестве целевой - реляционная, сетевая, иерархическая или объектно-ориентированная. Однако на этом этапе игнорируются все остальные характеристики выбранной СУБД, например, любые особенности физической организации ее структур хранения данных и построения индексов.
В процессе разработки логическая модель данных постоянно тестируется и проверяется на соответствие требованиям пользователей. Для проверки правильносги логической модели данных используется метод нормализации. Нормализация гарантирует, что отношения, выведенные из существующей модели данных, не будут обладать избыточностью данных, способной вызвать нарушения в процессе обновления данных после их физической реализации. Помимо всего прочего, логическая модель данных должна обеспечивать поддержку всех необходимых пользователям транзакций.
Созданная логическая модель данных является источником информации для этапа физического проектирования и обеспечивает разработчика физической базы данных средствами поиска компромиссов, необходимых для достижения поставленных целей, что очень важно для эффективного проектирования. Логическая модель данных играет также важную роль на этапе эксплуатации и сопровождения уже готовой системы. При правильно организованном сопровождении поддерживаемая в актуальном состоянии модель данных позволяет точно и наглядно представить любые вносимые в базу данных изменения, а также оценить их влияние на прикладные программы и использование данных, уже имеющихся в базе.
Жизненный цикл баз данных. Концептуальное проектирование базы данных.
Как и любой программный продукт БД создаются, функционируют и устаревают. Поэтому в любом жизненном цикле БД можно выделить 3 основных этапа:
Анализ и проектирование БД
Формулирование задачи и анализ требований
Концептуальное проектирование
Проектирование реализаций
Реализация БД
Непосредственная реализация
Физическое проектирование
Тестирование
Поддержка БД
Анализ функционирования и поддержка исходного варианта БД
Адаптация, модернизация и поддержка переработанных вариантов БД.
В процессе концептуального проектирования строится концептуальная схема БД. Построение:
Выделение локальных представлений, соответствие относительно независимых данных.
Формулирование объектов, описывающих локальную предметную область проектируемой БД, описание атрибутов составляющих каждый объект
Выделение ключевых атрибутов
Спецификация связей между объектами
Анализ и добавление не ключевых атрибутов
Объединение локальных представлений
Концептуальное проектирование базы данных. Объекты. Атрибуты. Конкретизация и обобщение.
В процессе концептуального проектирования предметная область рассматривается как объектная система, состоящая из объектного множества, объектов, атрибутов объектов, и связи между ними.
Объект – это то, о чем накапливается информация в любой информационной системе. Каждый объект в определенный момент времени может характеризоваться своим состоянием. Фактические объекты – предметы и вещи, которые пользователь считает наиболее важными в моделированной области.
Объектное множество – используется для обозначения множества вещей одного типа, объект-элемент – обозначает один элемент объектного множества. На концептуальной схеме обозначается прямоугольником объектного множества.
Объект-элемент соответствует записи объектного множества средствами конкретной СУБД. Два объектных множества могут быть связанны между собой.
Атрибут – именованная характеристика объекта, с помощью которой моделируются его свойства. Атрибуты одинаковы для объектного множества, но имеют разное значение для объектов объектного множества. Значение атрибутов могут меняться в процессе эксплуатации БД. Атрибут обозначается овалом на концептуальной схеме. Помимо описания свойств объекта, выделяют один атрибут с помощью которого можно однозначно идентифицировать объект. Данный атрибут будет являться ключевым.
Концептуальное проектирование базы данных. Связи между объектами. Мощность связи.
Между сущностями могут быть установлены связи
бинарные ассоциации, показывающие, каким образом сущности соотносятся или взаимодействуют между
собой. Связь может существовать между двумя разными сущностями пли между
сущностью и ей же самой (рекурсивная связь). Она показывает, как связаны экземпляры сущностей между собой. Если связь устанавливается между двумя сущностями, то она определяет взаимосвязь между экземплярами одной и другой сущности.
Связи делятся на три типа по множественности: одип-к-одному (1:1), один-ко-многим (1:М), многие-ко
миогим (М:М). Связь один-к-одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности. Связь 1: М означает, что один экземпляр сущности, расположенный слева по связи, может быть связан с несколькими экземплярами сущности, расположенными справа по связи. Связь ≪один-к-одному≫ (1:1) означает, что один экземпляр одной сущности связан только с одним экземпляром другой сущности, а связь ≪многие-ко-многим≫ (М:М) означает, что один экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот, один экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности.
Между двумя сущностями может быть задано сколько угодно связей с раз-
ными смысловыми нагрузками
Связь любого из этих типов может быть обязательной, если в данной связи
должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в дайной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. Обязательность связи тоже по-разному обозначается в разных нотациях.
Концептуальное проектирование базы данных. Моделирование предметной области.
Основные цели моделирования данных состоят в изучении значения (семантики) данных и упрощении процедур описания требований к данным. При создании модели данных необходимо получить ответы на определенные вопросы об отдельных сущностях, связях и атрибутах. Полученные дополнительные сведения помогут разработчикам раскрыть особенности семантики корпоративных данных, которые существуют независимо от того, отмечены они в формальной модели данных или нет. Сущности, связи и атрибуты являются фундаментальными информационными объектами любого предприятия. Однако их реальный смысл будет оставаться не вполне понятным до тех пор, пока они не будут должным образом описаны в документации. Моделирование данных упрощает понимание смысла элементов данных, поэтому создание модели необходимо для того, чтобы гарантировать понимание следующих аспектов данных:
требования к данным отдельных пользователей;
характер самих данных независимо от их физического представления;
использование данных в пределах области применения приложения.
Модели данных могут использоваться для демонстрации понимания разработчиком тех требований к данным, которые существуют на предприятии. Если обе стороны знакомы с системой обозначений, используемой для создания модели, то наличие модели данных будет способствовать более плодотворному общению пользователей и разработчиков. На предприятиях все шире применяются средства стандартизации для моделирования данных путем выбора определенного метода моделирования и использования его во всех проектах разработки базы данных. Самая популярная технология высокоуровневого моделирования данных, чаще всего используемая при разработке реальных баз данных, построена на концепции модели "сущность-связь" (Entity-Relationship model — ER-модель).
Концептуальное проектирование базы данных. Составные объекты.
В процессе концептуального проектирования предметная область рассматривается как объектная система, состоящая из объектного множества, объектов, атрибутов объектов, и связи между ними.
Объекты представляются в виде существительных. Отношения в виде глаголов. Объекты – это то, что пользователь считает важными.
Составное объектное множество – это объекты, связанные отношениями.
Жизненный цикл баз данных. Этап реализации.
На этапе реализации инфологическая модель БД описывается с помощью средств выбранной СУБД. Специфицируются форматы представления данных, ограничение целостности, создается физическая модель БД, с помощью среды программирования создается приложение, позволяющее пользователю формулировать требуемые запросы к БД и манипулировать данными.
Готовая БД тестируется на соответствие предъявленным пользователем требовании и имеющимся спецификациям.
Поэтапно этап реализации можно представить следующим образом:
Выбор и приобретение СУБД
Преобразование концептуальной модели в физическую
Заполнение БД
Создание прикладных программ
Тестирование
Физическое проектирование базы данных.
|
|
|
 Скачать 0.68 Mb.
Скачать 0.68 Mb.