Второй вопрос Explain gradient descent method for linear regression
 Скачать 0.96 Mb. Скачать 0.96 Mb.
|

|
Второй вопрос Explain gradient descent method for linear regression. Метод градиентного спуска для обучения модели линейной регрессии Наиболее простой и понятный, вместе с тем часто используемый метод математического программирования для решения задач такого рода — метод градиентного спуска (gradient descent). Это итерационный алгоритм, на каждом шаге которого вектор весов w меняется в направлении наибольшего убывания целевого функционала[1] [2], т.е. в направлении антиградиента: 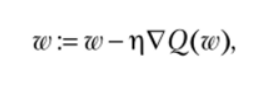 Для реализации алгоритма обучения возможны два подхода: 1)пакетный {batch) — на каждой итерации алгоритма обучающая выборка просматривается целиком и после этого рассчитывается новое значение вектора w; 2) стохастический (stochastic)[3] — на каждой итерации алгоритма случайным образом выбирается только один объект из обучающей выборки. Первый метод вычислительно более сложен, однако он быстрее сходится к минимуму благодаря просмотру всей выборки. Второй метод предполагает менее трудоемкие вычисления, но требует разработки алгоритма выбора следующего элемента для обучения. Пакетный метод реализовать очень просто — необходимо выполнять обновление весов при помощи усредненного значения антиградиента на всех примерах из обучающей выборки до тех пор, пока не стабилизируется оценка функционала Q, т.е. пока его значение на станет изменяться слишком медленно или не перестанет меняться вообще, или до тех пор, пока изменяются веса тю. Сам метод обновления весов для линейной регрессии можно представить следующим образом: 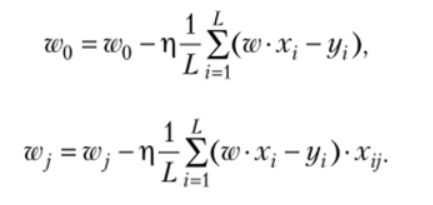 С точки зрения оптимального использования вычислительных ресурсов более интересен алгоритм стохастического градиента. Ниже представлен его псевдокод. Третий вопрос Tell about the method of linear regression with multiple variables. Features and polynomial regression. Множественная линейная регрессия (Multiple Linear Regression) Множественной называют линейную регрессию, в модели которой число независимых переменных две или более. Уравнение множественной линейной регрессии имеет вид: Как и в простой линейной регрессии, параметры модели b n вычисляются при помощи метода наименьших квадратов. Отличие между простой и множественной линейной регрессией заключается в том, что вместо линии регрессии в ней используется гиперплоскость. Преимущество множественной линейной регрессии по сравнению с простой заключается в том, что использование в модели нескольких входных переменных позволяет увеличить долю объяснённой дисперсии выходной переменной, и таким образом улучшить соответствие модели данным. Т.е. при добавлении в модель каждой новой переменной коэффициент детерминации растёт. Линейная регрессия. Сначала предположим, что данные являются линейными с определенными ограничениями, поскольку в действительности многие данные являются нелинейными. Полиномиальная регрессия: данные не предполагаются, что больше соответствует нелинейным характеристикам фактических данных. 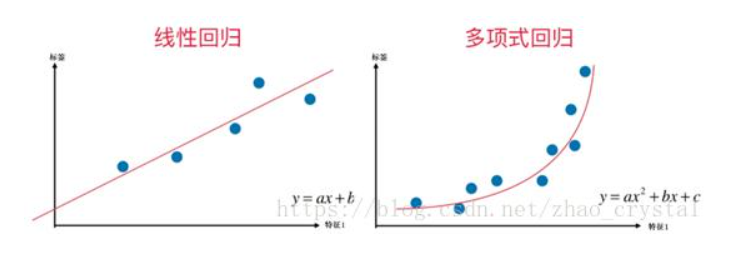 Полиномиальная регрессия может рассматриваться как добавление дополнительных функций на основе линейной регрессии.: Как показано выше, степень = 2, больше добавленоx^{2}Эта особенность.  Четвертый вопрос Tell about multiclass classification: one-vs-all, give examples. Multiclass классификация Multiclass classification (многоклассовая классификация) - частный случай задачи классификации при которой требуется классифицировать объекты в более чем один из двух классов. Когда число классов достигает многих тысяч задача существенно вырастает в сложности. В то время как некоторые алгоритмы классификации по определению допускают использования нескольких классов другие могут не иметь такой возможности, в то же время они могут быть использованы в задачах многоклассовой классификации с помощью различных стратегий. Классической считается стратегия One-vs.-rest (один-против-всех, OvA или OvR). Стратегия One-vs.-rest включает в себя тренировку одного классификатора для каждого класса, при котором мы считаем примеры с нужным классом позитивными примерами, а все остальные примеры - негативными. Стратегия требует чтобы базовые классификаторы возвращали меру уверенности (confidence score) своего решения, а не просто метку класса. Дискретные метки класса могут привести к двусмысленности, так как несколько классов могут быть предсказаны для одного примера. Пятый вопрос Tell about deep L-layer neural network. Explain backpropagation method and backpropagation intuition. Backpropagation in practice. Нейронная сеть — это группа подключенных модулей ввода / вывода, где каждое соединение имеет вес, связанный с его компьютерными программами. Это помогает вам строить прогностические модели из больших баз данных. Эта модель основана на нервной системе человека. Это помогает вам проводить понимание изображения, обучение человека, компьютерную речь и т. Д. 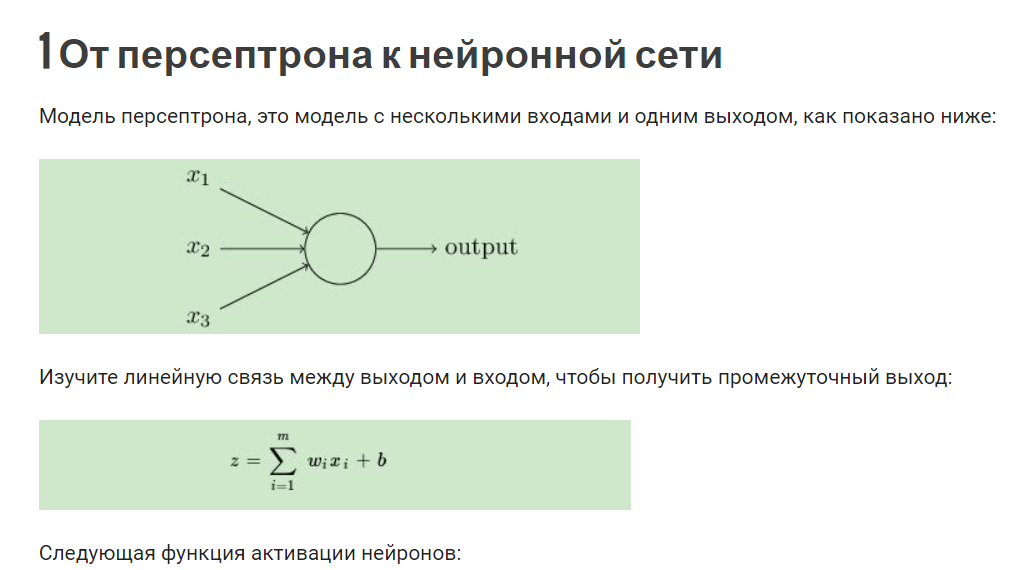 Обратное распространение — это сущность обучения нейронной сети. Это метод точной настройки весов нейронной сети на основе частоты ошибок, полученных в предыдущую эпоху (т. Е. Итерации). Правильная настройка весов позволяет снизить частоту появления ошибок и повысить надежность модели за счет увеличения ее обобщения. Обратное распространение — это краткая форма «обратного распространения ошибок». Это стандартный метод обучения искусственных нейронных сетей. Этот метод помогает рассчитать градиент функции потерь по отношению ко всем весам в сети. Similar to the forward propagation module, we will be implementing three functions in this module too. linear_backward (для вычисления линейного выхода Z для любого слоя) linear_activation_backward, где активация будет либо tanh, либо Sigmoid. L_model_backward [LINEAR -> tanh] (L-1 раз) -> LINEAR -> SIGMOID (обратное распространение всей модели) Шестой вопрос Give the concepts of evaluation of the learning algorithm. Model selection and train/validation and test sets. В машинном обучении общей задачей является изучение и построение алгоритмов, которые могут учиться и делать прогнозы на данных. Такие algorithms функционируют путем прогнозирования или принятия решений, основанных на данных, путем построения модели на основе входных данных. Модель первоначально вписывается в обучающий набор данных, который представляет собой набор примеров, используемых для соответствия параметрам Последовательно подогнанная модель используется для прогнозирования ответов на наблюдения во втором наборе данных, называемом набором данных проверки. Набор данных проверки обеспечивает беспристрастную оценку соответствия модели набору данных обучения при настройке модели. Наборы данных валидации могут быть использованы для регуляризации с помощью раннего обучения (обучение, когда ошибка в наборе данных валидации увеличивается, так как это признак подгонки к набору данных тренинга). Наконец, тестовый набор данных является набором данных, используемым для обеспечения беспристрастной оценки окончательного соответствия модели обучающему набору данных. Седьмой вопрос Explain SVM method and give example. Large margin classification. Машина опорных векторов или же метод опорных векторов - это еще один простой алгоритм, который должен быть в арсенале каждого специалиста по машинному обучению. Многие очень предпочитают машину опорных векторов, поскольку она обеспечивает значительную точность при меньшей вычислительной мощности. Support Vector Machine, сокращенно SVM, может использоваться как для задач регрессии, так и для классификации. Но он широко используется именно в целях классификации. Задача алгоритма метода опорных векторов - найти гиперплоскость в N-мерном пространстве (N - количество классов), которая четко классифицирует точки данных. 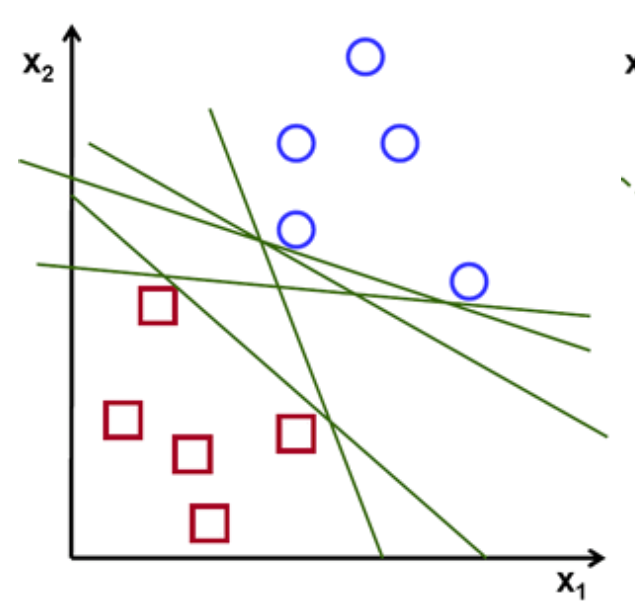 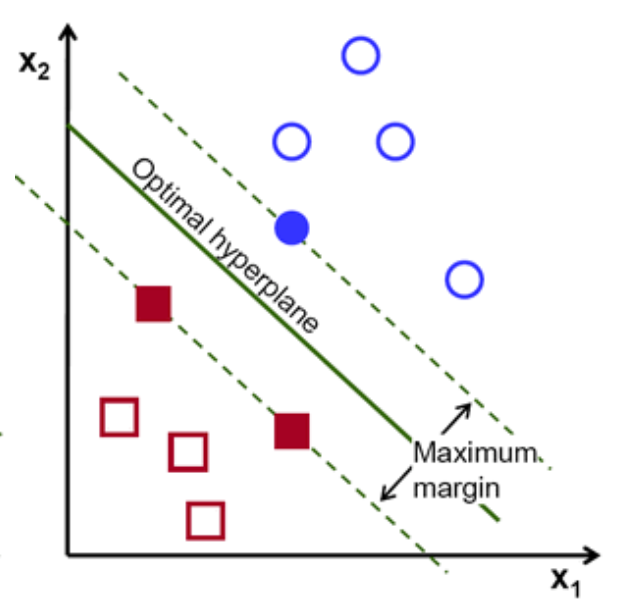 Идею метода удобно проиллюстрировать на следующем простом примере: даны точки на плоскости, разбитые на два класса. Проведем линию, разделяющую эти два класса Далее, все новые точки (не из обучающей выборки) автоматически классифицируются следующим образом: точка выше прямой попадает в класс A, точка ниже прямой — в класс B. Такую прямую назовем разделяющей прямой. Однако, в пространствах высоких размерностей прямая уже не будет разделять наши классы, так как понятие «ниже прямой» или «выше прямой» теряет всякий смысл. Поэтому вместо прямых необходимо рассматривать гиперплоскости — пространства, размерность которых на единицу меньше, чем размерность исходного пространства. Гиперплоскость — это обычная двумерная плоскость 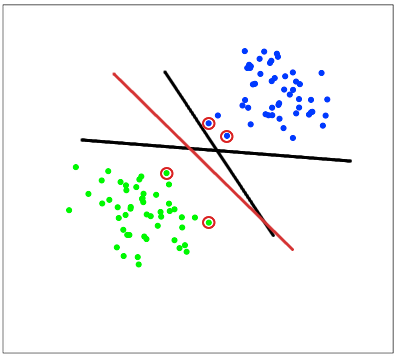 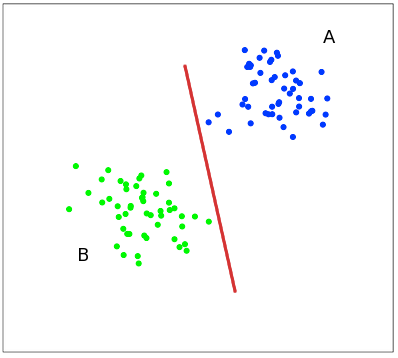 С точки зрения точности классификации лучше всего выбрать прямую, расстояние от которой до каждого класса максимально. Другими словами, выберем ту прямую, которая разделяет классы наилучшим образом. Такая прямая, а в общем случае — гиперплоскость, называется оптимальной разделяющей гиперплоскостью. Вектора, лежащие ближе всех к разделяющей гиперплоскости, называются опорными векторами. На практике случаи, когда данные можно разделить гиперплоскостью, или, как еще говорят, линейно, довольно редки.В этом случае поступают так: все элементы обучающей выборки вкладываются в пространство X более высокой размерности Восьмой вопрос Explain building data engineering pipelines. Serverless concepts: service model, functions, ecosystems. Give examples. What data engineering is, is the ability to build pipelines that transport data or transform data at a periodic basis, and it's the software engineering around that data. A data engineer could be doing big data operations with Spark, they could be building event-driven infrastructures with AdaBoost lambda, or they could be handling jobs, like nightly jobs that collect analytics and create sales forecast for the executive team. A data engineer is focused exclusively on the software engineering best practices around the movement and transport of data. Что такое инженерия данных, - это возможность создавать конвейеры, которые передают или преобразовывать данные на периодической основе, и это разработка программного обеспечения на основе этих данных. Инженер по обработке данных может выполнять операции с большими данными с помощью Spark, он может создавать инфраструктуру, управляемую событиями, с помощью лямбда-выражения AdaBoost или обрабатывать рабочие места, такие как ночные задания, которые собирают аналитические данные и создают прогноз продаж для исполнительной команды. Специалист по обработке данных специализируется исключительно на передовых методах разработки программного обеспечения, связанных с перемещением и транспортировкой данных.  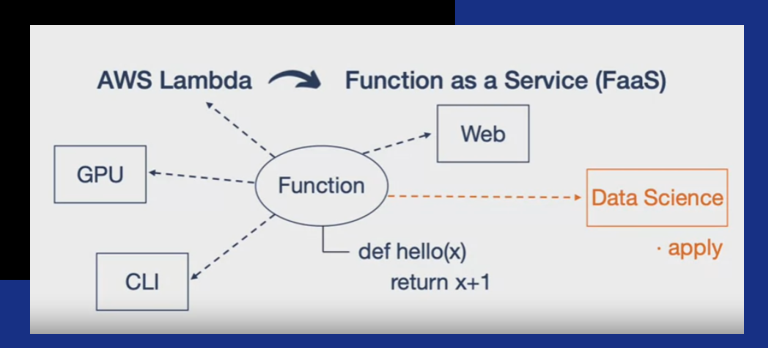  Девятый вопрос Explain cloud storage, cloud storage solutions and cloud storage deep dive. Так зачем использовать облачное хранилище? Что ж, одним из наиболее важных аспектов облачного хранилища является идея экономии от масштаба. Так что если вы пойдете в Costco, зайдете, скажем, в цветочный отдел и получите мешок муки за 50 фунтов стерлингов, что ж, это отличный пример экономии за счет масштаба. Они оба могут купить для вас более дешевую цветочную сумку, а вы можете купить ее дешевле из-за размера, который они продают. Так что вы действительно получаете двойную победу. То же самое и с облаком. Если вы приобретаете вещи оптом в качестве облачного провайдера, вы можете продавать их гораздо дешевле. А затем, если вам, как клиенту, нужно иметь доступ к большим объемам данных или хранить большие объемы данных, вы действительно получаете доступ к вещам по гораздо более низкой цене. Так что на самом деле идея облачных вычислений Облачное хранилище заключается в том, что вы используете эффект масштаба, а затем можете делать то, что обычно вы не могли бы сделать, если бы у вас не было предложения облачных услуг. Десятый вопрос. Tell about ETL. Real-world problems in ETL. Explain cloud databases and give examples. Что такое ETL? Ну, это означает извлечение, преобразование и загрузка, и это обычная операция в конвейере разработки данных. Причина этого в том, что часто, когда вы получаете данные из источника, это не совсем чистая форма. И вам придется извлечь данные, потенциально распаковать их или изменить из одного формата в другой. Может быть, избавиться от испорченных или недостающих значений, вместе трансформировать вещи. А затем загружается в новую систему, например, в базу данных бизнес-аналитики. Итак, в целом, когда вы создаете конвейеры данных, важно думать об этих трех терминах. Извлечение, преобразование и загрузка, и большинство операций по повреждению данных связаны с этими вещами. Один размер не подходит для всех в облаке? Технический директор Amazon Вернер Фогель несколько лет назад упомянул, что универсальная база данных никому не подходит. Под этим он подразумевает, что базы данных имеют несколько различных характеристик в зависимости от того, какую проблему вы решаете, скажем, для банковской операции. Может быть, транзакционная база данных, традиционная реляционная база данных отлично подошла бы, потому что все согласовано. Но с веб-приложением, которое, возможно, в конечном итоге будет согласованной системой управления контентом, будет намного лучше для этой конкретной базы данных. В других сценариях база данных графа, у которой была возможность просматривать различные отношения между социальными сетями, могла быть другим типом базы данных. Итак, на самом деле, когда вы создаете что-то в облаке, на AWS есть, скажем, до дюжины различных баз данных. Выбор подходящей базы данных для решения конкретной задачи - это ваш выбор, и только одна база данных сама по себе может не быть подходящим решением. Random Forest Classifier. A random forest classifier. Случайный лес - это метаоценка, которая соответствует ряду классификаторов дерева решений на различных подвыборках набора данных и использует усреднение для повышения точности прогнозирования и контроля избыточной подгонки. Размер подвыборки контролируется параметром max_samples, если bootstrap = True (по умолчанию), в противном случае для построения каждого дерева используется весь набор данных. n_estimatorsint, default=100 The number of trees in the forest. criterion{“gini”, “entropy”}, default=”gini” The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain. Note: this parameter is tree-specific. max_depthint, default=None The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples. min_samples_splitint or float, default=2 The minimum number of samples required to split an internal node: If int, then consider min_samples_split as the minimum number. If float, then min_samples_split is a fraction and ceil(min_samples_split * n_samples) are the minimum number of samples for each split. min_samples_leafint or float, default=1 The minimum number of samples required to be at a leaf node. A split point at any depth will only be considered if it leaves at least min_samples_leaf training samples in each of the left and right branches. This may have the effect of smoothing the model, especially in regression. If int, then consider min_samples_leaf as the minimum number. If float, then min_samples_leaf is a fraction and ceil(min_samples_leaf * n_samples) are the minimum number of samples for each node. min_weight_fraction_leaffloat, default=0.0 The minimum weighted fraction of the sum total of weights (of all the input samples) required to be at a leaf node. Samples have equal weight when sample_weight is not provided. |