Курсова робота_СТАРАЯ. Зміст
 Скачать 1.63 Mb. Скачать 1.63 Mb.
|

Глибинне навчанняГлиби́нне навча́ння (також відоме як глибинне структурне навчання, ієрархічне навчання, глибинне машинне навчання) — це галузь машинного навчання, що ґрунтується на наборі алгоритмів, які намагаються моделювати високорівневі абстракції в даних, застосовуючи глибинний граф із декількома обробними шарами, що побудовано з кількох лінійних або нелінійних перетворень. Глибинне навчання є частиною ширшого сімейства методів машинного навчання, що ґрунтуються на навчанні ознак даних. Спостереження (наприклад, зображення) може бути представлено багатьма способами, такими як вектор значень яскравості для пікселів, або абстрактнішим способом, як множина кромок, областей певної форми тощо. Деякі представлення є кращими за інші у спрощенні задачі навчання (наприклад, розпізнаванню облич, або виразів облич). Однією з обіцянок глибинного навчання є заміна ознак ручної роботи дієвими алгоритмами автоматичного або напівавтоматичного навчання ознак та ієрархічного виділяння ознак. Дослідження в цій області намагаються зробити кращі представлення та створити моделі для навчання цих представлень з великомасштабних немічених даних. Деякі з цих представлень було зроблено під натхненням досягнень в нейронауці та з мотивів схем обробки та передавання інформації в нервовій системі, таких як нервове кодування, що намагається визначити зв'язок між різноманітними стимулами та пов'язаними нейронними реакціями в мозку. Різні архітектури глибинного навчання, такі як глибинні нейронні мережі, згорткові глибинні нейронні мережі, глибинні мережі переконань та рекурентні нейронні мережі застосовувалися в таких областях, як комп'ютерне бачення, автоматичне розпізнавання мовлення, обробка природної мови, розпізнавання звуків та біоінформатика, де вони, як було показано, представляють передові результати в різноманітних задачах. Задача розпізнаванняЛюдина звичайно може легко розрізняти звук образи, звуки, аромати. Проте для комп'ютера важко вирішити такі проблеми сприйняття. Ці проблеми важкі, тому що кожен шаблон зазвичай містить велику кількість інформації, і проблеми розпізнавання зазвичай мають неясну, високовимірну структуру. Розпізнавання образів – це наука робити висновки з даних, що були отримані шляхом сприйняття, використовуючи інструменти зі статистики, ймовірності, обчислювальної геометрії, машинного навчання, обробки сигналів та алгоритмів. Таким чином, це має найважливіше значення для штучного інтелекту та комп'ютерного бачення, і має далекосяжні застосування в галузі машинобудування, науки, медицини та бізнесу. Зокрема, досягнення, досягнуті протягом останнього півстоліття, дозволяють комп'ютерам ефективніше взаємодіяти з людьми та природним світом (наприклад, програмне забезпечення для розпізнавання мовлення). Проте найважливіші проблеми розпізнавання образів ще не вирішені. Цілком природно, що ми повинні прагнути спроектувати і побудувати машини, здатні розпізнавати шаблони. Від автоматичного розпізнавання мови, ідентифікації відбитків пальців, оптичного розпізнавання символів, ідентифікації послідовності ДНК та багато іншого, зрозуміло, що надійне, точне розпізнавання образів за допомогою машини буде надзвичайно корисним. Більше того, при вирішенні невизначеного числа проблем, необхідних для побудови таких систем, ми отримуємо глибше розуміння та оцінку систем розпізнавання образів. Для деяких завдань, таких як мова та візуальне розпізнавання, на наші проектні зусилля насправді можуть впливати знання про те, як вони вирішуються в природі, як в алгоритмах, які ми використовуємо, так і в дизайні спеціального устаткування. 1.2.1 Основні поняття задачі розпізнаванняОзнаки (features) можна визначити як будь-який відмітний аспект, якість або характеристику, які можуть бути символічними (наприклад, колір) чи чисельними (наприклад, висота). Комбінація функцій d представляється як вектор d-розмірного стовпця, який називається вектором властивостей. D-мірний простір, визначений функцією вектора, називається простором ознак (feature space). Об'єкти представлені у вигляді точок у просторі ознак. Це подання називається графіком розсіювання (scatter plot). Шаблон (pattern) визначається як комбінація ознак, характерних для особи. У класифікації шаблон - це пара змінних {x, w}, де x - це сукупність спостережень або ознак (вектор ознак), а w - концепція, що лежить в основі спостереження (label). Якість вектора властивостей пов'язана з його здатністю відрізняти приклади з різних класів (рис. 1.1). Приклади з того ж класу повинні мати подібні значення ознак, а приклади з різних класів мають різні значення ознак: a - відмінність між хорошими (good) та поганими (bad) ознаками; b - властивості ознак за способом розділення: лінйні, нелінійні, мультимодальні, висококорельовані. 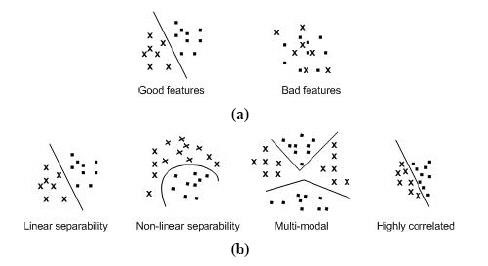 Рисунок 1.1 - Ознаки (характеристики) Метою класифікатора є розділення простору ознак на позначені класом області прийняття рішень. Межі між регіонами прийняття рішень називаються межами рішень (рис. 1.2). 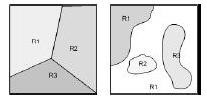 Рисунок 1.2 - Межі класифікатора та рішення. Якщо характеристики або атрибути класу відомі, окремі об'єкти можуть бути ідентифіковані як такі, що належать або не належать до цього класу. Об'єкти відносяться до класів, дотримуючись шаблонів відмінних характеристик і порівнюючи їх з типовими членами кожного класу. Розпізнавання образів передбачає виділення образів з даних, їх аналізу та, нарешті, ідентифікації категорії (класу), до якої належить кожний образ. Типова система розпізнавання образів містить датчик, механізм попередньої обробки (сегментація), механізм виділення ознак (ручний або автоматичний), алгоритм класифікації або опису та набір прикладів (тренувальний набір), які вже класифіковані або описані (після обробки) (рис. 1.3). 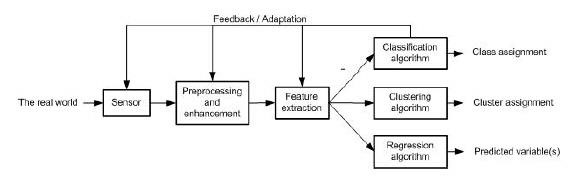 Рисунок 1.3 – Система розпізнавання образів 1.2.2 Підходи до розпізнавання образівІснує два фундаментальні підходи до впровадження системи розпізнавання образів: статистичний та структурний. Кожен підхід використовує різні методи для виконання описів та класифікації завдань. Гібридні підходи, іноді називаються уніфікованим підходом до розпізнавання образів, об'єднують як статистичні, так і структурні методики в рамках системи розпізнавання образів. Визнання статистичного моделювання спирається на встановлені поняття в теорії статистичних рішень для того, щоб виокремити дані різних груп на основі кількісних характеристик даних. Існує широкий спектр статистичних методів, які можуть використовуватися в рамках завдання з виділення ознак, починаючи від простої описової статистики до складних перетворень. Приклади статистичних методів виділення ознак включають в себе середнє та стандартне відхилення обчислень, підсумовування частотних значень, перетворення Кархунена-Лоуєва, перетворення Фур'є, вейвлет-перетворення та трансформації Хога. Кількісні характеристики, виділені з кожного об'єкта для статистичного розпізнавання образів, організовані у вектор-функцію з фіксованою довжиною, коли значення, пов'язане з кожною функцією, визначається його положенням у векторі (тобто перша ознака описує певну характеристику даних, друга ознака описує іншу характеристику тощо). Колекція векторів функцій, породжених завданням опису, передається до завдання класифікації. Статистичні методи, що використовуються в якості класифікаторів у межах задачі класифікації включають ті, які базуються на подібності (наприклад, відповідність шаблону, k-найближчого сусіда), ймовірність (наприклад, правило Байєса), межі (наприклад, дерева рішень, нейронні мережі) та кластеризація (наприклад, k-середні, ієрархічний). Кількісний характер статистичного розпізнавання образів ускладнює виділення різниці між групами на основі морфологічних (тобто форми або структурних) підшаблонів та їх взаємозв'язків, вбудованих в дані. Це обмеження дало імпульс розвитку структурного підходу до розпізнавання образів, який підтверджується психологічними свідченнями, що стосуються функціонування людського сприйняття та пізнання. Розпізнавання об'єктів в людях було продемонстровано для залучення психічних уявлень до явних, структурно-орієнтованих характеристик об'єктів, і було зроблено висновок, що рішення про класифікацію людини складаються з урахуванням ступеня подібності між витягнутими ознаками та прототипом, розробленим для кожної групи. Наприклад, визнання за теорією компонентів пояснює процес розпізнавання образів у людей: (1) об'єкт сегментований у окремі області за границями, визначеними різними поверхневими характеристиками (наприклад, яскравістю, текстурою та кольором); (2) кожна сегментована область апроксимується простою геометричною формою, і (3) об'єкт визначається на підставі подібності у складі між геометричним представленням об'єкта та центральною тенденцією кожної групи. Це теоретичне функціонування людського сприйняття та пізнання служить основою для структурного підходу до розпізнавання образів. Розпізнавання структурних образів, яке іноді називають розпізнаванням синтаксичних образів через його походження в формальній теорії мовлення, спирається на синтаксичні граматики, щоб розрізняти дані різних груп на основі морфологічних взаємозв'язків (або взаємозв'язків), що містяться в даних. Структурні ознаки, часто називаються примітивними, представляють собою підшаблони (або структурні блоки) та відносини між ними, які складають дані. Семантика, пов'язана з кожною функцією, визначається схемою кодування (тобто вибіркою морфології), що використовується для ідентифікації примітивів у даних. Вектори ознак, породжених структурними системами розпізнавання образів, містять змінюване число ознак (по одній для кожного примітиву, витягнутого з даних), щоб врахувати наявність надлишкових структур, які не впливають на класифікацію. Оскільки взаємовідносини між видобутими примітивами також повинні бути закодовані, векторний компонент повинен включати додаткові функції, що описують відносини між примітивами або приймають альтернативну форму, наприклад, реляційний граф, який може бути проаналізовано синтаксичною граматикою. Акцент на відносинах між даними робить структурний підхід до розпізнавання образів найбільш розумним для даних, які містять наслідувальну ідентифіковану організацію, таку як дані зображень (які організовуються за місцем розташування всередині візуального рендеринга) та дані про часові ряди (організовані за часом ); дані, що складаються з незалежних зразків кількісних вимірювань, не мають упорядкування і вимагають статистичного підходу. Методології, що використовуються для виділення структурних ознак з даних зображення, таких як технології обробки зображення, призводять до таких примітивів, як ребра, криві та регіони; Технологія вилучення функції для даних часової серії включає в себе ланцюгові коди, кусочно-лінійну регресію та фігуру кривої, які використовуються для генерації примітивів, які кодують послідовні, упорядковані за часом співвідношення. Завдання класифікації доходить до ідентифікації, використовуючи синтаксичний аналіз: вилучені структурні ознаки ідентифікуються як представники певної групи, якщо вони можуть бути успішно проаналізовані синтаксичною граматикою. При розрізненні більш ніж двох груп синтаксична граматика необхідна для кожної групи. 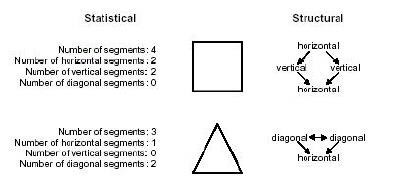 Рисунок 1.4 - Статистичні та структурні підходи до розпізнавання образів, що застосовуються до загальної проблеми ідентифікації На рисунку 1.4 зображено, як обидва підходи можуть бути застосовані до однієї проблеми ідентифікації. Мета полягає в тому, щоб диференціювати квадрат і трикутник. Статистичний підхід витягує кількісні характеристики, такі як кількість горизонтальних, вертикальних та діагональних сегментів, які потім передаються класифікатору, що вирішує, до якого класу віднести виділені ознаки. Структурний підхід виділяє морфологічні особливості та їх взаємозв'язки в межах кожної фігури. Використовуючи прямолінійний сегмент як елементарну морфологію, створюється реляційний граф і класифікується за допомогою визначення синтаксичної граматики, яка може успішно проаналізувати реляційний граф. У цьому прикладі як статистичні, так і структурні підходи зможуть точно розрізняти дві геометрії. Однак у більш складних даних дискримінаційність безпосередньо впливає на особливий підхід, використовуваний для розпізнавання образів, оскільки отримані ознаки представляють різні характеристики даних. Суттєвими відмінностями між статистичними та структурними підходами є: (1) опис, сформований статистичним підходом, є кількісним, тоді як структурний підхід створює опис, що складається з підшаблонів або будівельних блоків; і (2) статистичний підхід розрізняє, ґрунтуючись на численних відмінностях між ознаками різних груп, тоді як граматики використовуються структурним підходом для визначення мови, що охоплює прийнятні конфігурації примітивів для кожної групи. Гібридні системи можуть поєднувати два підходи як спосіб компенсувати недоліки кожного підходу, зберігаючи при цьому переваги кожного. Як система одного рівня, структурні ознаки можуть використовуватися як зі статистичними, так і з структурними класифікаторами. Статистичні ознаки не можуть бути використані з структурним класифікатором, оскільки вони не мають реляційної інформації, однак статистична інформація може бути пов'язана з структурними примітивами і використовується для вирішення невизначеностей під час класифікації (наприклад, як при розборі з приписаними граматиками) або безпосередньо вкладені безпосередньо в самий класифікатор (наприклад, як при розборі з стохастичними граматиками). Гібридні системи також можуть об'єднувати два підходи в багаторівневу систему, використовуючи паралельну або ієрархічну композицію. 1.2.3 Системи розпізнавання образівУ системі розпізнавання образів виділяють три різні операції: попередньої обробки, вилучення властивостей та класифікацію. Щоб зрозуміти проблему проектування такої системи, ми повинні розуміти проблеми, які необхідно вирішити кожному з цих компонентів. Датчик. Вхід системи розпізнавання образів часто є свого роду перетворювачем, таким як камера або мікрофон. Складність проблеми може цілком залежати від характеристик і обмежень датчика - її пропускної здатності, роздільної здатності, чутливості, спотворення, співвідношення сигнал / шум, затримки тощо. Сегментація та групування. На практиці предмети, які необхідно розпізнати, часто перетинаються, і система повинна буде визначити, де закінчується один предмет, а де наступний - індивідуальні зразки повинні бути сегментовані. Якщо ми вже виділили цей предмет, то було б простіше сегментувати його зображення. Як ми можемо сегментувати зображення, перш ніж вони будуть класифіковані, або класифікувати їх, перш ніж вони будуть сегментовані? Потрібен спосіб дізнатися, коли ми перейшли з однієї моделі в іншу, або знати, коли ми просто маємо фонову категорію або не маємо жодної категорії. Сегментація є однією з найглибших проблем розпізнавання образів. Трудно пов'язана з проблемою сегментації - це проблема розпізнавання або групування різних пасток композитного об'єкта. Виділення ознак. Концептуальна межа між виділенням ознак та правильною класифікацією є дещо умовною: ідеальна функція виділення ознак дає представлення, яке робить роботу класифікатора тривіальною; навпаки, всемогутній класифікатор не потребує допомоги витонченої функції виділення ознак. Різниця виникає з практичних, а не з теоретичних причин. Традиційна мета виділення ознак полягає в тому, щоб характеризувати об'єкт, який слід визнати вимірами, значення яких дуже схожі для об'єктів однієї категорії, і дуже різні для об'єктів у різних категоріях. Це призводить до ідеї пошуку відмінних функцій, інваріантних до несуттєвих перетворень входу. Загалом, функції, які описують такі властивості, як форма, колір та багато видів текстур, інваріантні для перекладу, обертання та масштабу. Більш загальна інваріантність буде для обертання щодо довільної лінії в трьох вимірах. Образ навіть такого простого об'єкта, як чашка для кави, зазнає кардинальної зміни, оскільки чашка повертається до довільного кута. Ручка може бути прихована іншою частиною. Крім того, якщо відстань між чашкою та камерою може змінюватися, зображення піддається проекційному спотворенню. Як ми можемо забезпечити, щоб функції були інваріантні для таких складних перетворень? З іншого боку, чи слід визначити різні підкатегорії для зображення чашки та досягти інваріантності обертання при більш високому рівні обробки? Як і в процесі сегментації, в завданні з вилучення ознак набагато більше проблем - це залежить від домену, ніж є належним класифікацією, і, отже, вимагає знання домену. Хороший класифікатор для сортування риби, ймовірно, буде мати мало користі для ідентифікації відбитків пальців або класифікації мікрофотографії з клітин крові. Проте деякі принципи класифікації моделей можуть бути використані при проектуванні екстрактора властивостей. Існує два види попереджувальних сигналів: «жорсткий» і «м'який», які залежать від загального самопочуття водія. Сигнали відрізняються один від одного тональністю і гучністю звуку. 1.2.4 КласифікаціяЗавдання відповідної компоненти класифікатора повної системи полягає в тому, щоб використовувати векторний функціонал, який забезпечує екстрактор функцій, для присвоєння об'єкту категорії. Оскільки досконала класифікація часто неможлива, більш загальним завданням є визначення імовірності кожної з можливих категорій. Абстракція, що забезпечується функціонально-векторним представленням вхідних даних, дозволяє розробляти в основному незалежну від домену теорію класифікації. Ступінь складності проблеми класифікації залежить від мінливості значень об'єктів для об'єктів у тій же категорії відносно різниці значень об'єктів для об'єктів у різних категоріях. Варіанти значень об'єктів для об'єктів у тій самій категорії можуть бути пов'язані із складністю і можуть бути пов'язані із шумом. Ми визначаємо шум у дуже загальних термінах: будь-яка властивість чутливого шаблону, який не пов'язаний з істинною базовою моделлю, а навпаки, випадковості в світі або сенсорами. Усі нетривіальні рішення та проблеми розпізнавання образів пов'язані з шумом у певній формі. Одна з проблем, яка виникає на практиці, полягає в тому, що не завжди можливо визначити значення всіх ознак для певних вхідних даних. 1.2.5 ПісляобробкаКласифікатор рідко існує у вакуумі. Замість цього він, як правило, повинен використовуватися для того, щоб рекомендувати дії, кожна дія має пов'язану вартість. Постпроцесор використовує вихід класифікатора, щоб прийняти рішення про рекомендовану дію. Концептуально, найпростішою мірою ефективності класифікатора є рівень помилки класифікації - відсоток нових шаблонів, які призначені до неправильної категорії. Таким чином, треба шукати класифікацію з мінімальною похибкою. Проте, може бути набагато краще рекомендувати дії, які мінімізують загальну очікувану вартість, яка називається ризиком. |