Курсова робота_СТАРАЯ. Зміст
 Скачать 1.63 Mb. Скачать 1.63 Mb.
|

CNTKCNTK – це бібліотека для опису навчальних машин. Хоча це призначено для нейронних мереж, навчальні машини є довільними, оскільки логіка машини описується серією обчислювальних кроків в обчислювальній мережі. Обчислювальна мережа визначає функцію, яку слід навчати, як орієнтований граф, де кожен кінцевий вузол складається з вхідного значення або параметра, а кожен незалежний вузол представляє матрицю або тензорну операцію для своїх дітей. Перевага CNTK полягає в тому, що, як тільки була описана обчислювальна мережа, всі розрахунки, необхідні для вивчення параметрів мережі, обробляються автоматично. Немає необхідності аналітично виводити градієнти або кодування взаємодій між змінних для зворотного розповсюдження. Без CNTK необхідно самому обирати процедуру оптимізації та розв’язувати похідні від функції витрат по відношенню до параметрів, які ми хочемо вивчити. Виходячи з логістичної регресії як імовірнісної моделі, ми можемо максимально збільшити ймовірність отримання даних. Це виявляється таким самим, як мінімізація функції перехресної ентропії, яка для логістичної регресії також відома як «функція логістичної втрати». Загалом, це не може бути зроблено аналітично, але можливо визначити аналітичні рішення для градієнтів, а потім використовувати градієнтне сходження, щоб сходити до правильних параметрів. CNTK використовує загальний алгоритм стохастичного градієнтного спуску (SGD) для вивчення параметрів в обчислювальній мережі. Градієнти визначаються шляхом автоматичної диференціації. Щоб налаштувати та навчити Комп'ютерну мережу, CNTK використовує файл конфігурації .cntk, який: описує мережу; вказує команди, які ми хочемо виконати в мережі (тренування, тест, отримання вихідних значень і т. д.); встановлює, як ми хочемо вивчити параметри мережі (SGD та її параметри); встановлює, як CNTK слід читати та записувати дані. Для опису нашої обчислювальної мережі використовується мова опису мережі CNTK BrainScript. Потрібно визначити: вхідні функції позначення параметри для навчання обчислювальні операції кореневі вузли (виходи) Припустимо, що необхідно визначити обчислювальну мережу, яка виглядає так, як представлено на рисунку 2.5. 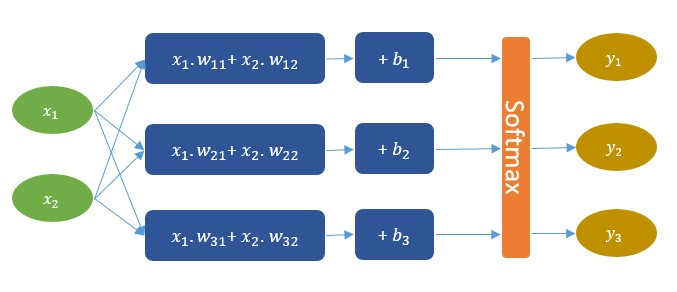 Рисунок 2.5 – Обчислювальна мережа Реалізація мережі, зображеної вище, за допомогою CNTK представлена на рисунку 2.6:  Рисунок 2.6 – Реалізація нейронної мережі за допомогою CNTK Цю мережу можна зрозуміти як комбінацію трьох лінійних моделей, кожна з яких буде навчена відокремлювати один з трьох класів від двох інших. Потім, на виході, є шар softmax, який розподіляє лінійні моделі на за розподілом імовірності. Таким чином, для кожного входу мережа виводить три значення вірогідності, що в сумі дає 1. Наприклад, якщо даний екземпляр складається з класу (1), модель може виводити наступні ймовірності (95%, 3%, 2%), що в принципі означає, що ймовірність екземпляру, що відноситься до класу (1), становить 95%. CNTK також дозволяє працювати із CNN. CNN має більш складну структуру, ніж звичайні нейронні мережі. Кожен вхід тут є матрицею, а не вектором. Це відбувається тому, що CNN використовує локальні кореляції на зображенні. Таким чином, ми повинні зберегти цю інформацію. Шар згортки можна визначити як каскад шарів згортки та max-pooling. Реалізація у CNTK представлена на рисунку 2.7:  Рисунок 2.7 – Реалізація згорткового шару на CNTK CaffeCaffe – бібліотека глибокого машинного навчання. Розроблений Berkeley AI Research (BAIR). Основними особливостями Caffe є: Зрозуміла архітектура заохочує застосування та інновації. Моделі та оптимізація визначаються конфігурацією без жорсткого кодування. Є можливість переключатись між процесором і графічним процесором, встановивши єдиний прапорець для тренувань на машині графічного процесора, а потім розгорнути на кластерах чи мобільних пристрої. Розширюваний код сприяє активному розвитку. У перший рік Caffe він був розкритий більш ніж 1000 розробниками і багато істотних змін застосовано. Завдяки цим авторам система підтримує найсучасніші технології в коді та моделях. Швидкість робить Caffe ідеальним для дослідницьких експериментів та розгортання. Caffe може обробляти понад 60 М зображення на день за допомогою одного NVIDIA K40 GPU *. Це 1 мс / зображення для виводу та 4 мс / зображення для навчання. Співтовариство: Caffe вже володіє академічними дослідницькими проектами, прототипами запуску та навіть великомасштабними промисловими програмами у сфері зору, мовлення та мультимедіа. Основні складові Caffe Глибокі мережі - це композиційні моделі, які природно представлені як сукупність взаємопов'язаних шарів, які працюють над частинами даних. Caffe визначає мережу шар за шароми у власній схемі моделей. Мережа визначає всю модель знизу вгору від вхідних даних до втрат. Оскільки дані та похідні потоку через мережу відбуваються в прямому і зворотньому напрямі, Caffe зберігає, передає та управляє інформацією як blob-ами: blob - це стандартний масив і уніфікований інтерфейс пам'яті для цієї системи. Наступний шар стає основою як для моделі, так і для обчислень. Мережа представляється як колекція і зв’язки між шарами. Деталі blob-ів описують, яким чином інформація зберігається та передається у шарах і мережах. Рішення налаштовується окремо для відокремлення моделювання та оптимізації. Blob - обгортка фактичних даних, що обробляються і передаються Caffe, а також під капотом забезпечують можливість синхронізації між процесором і графічним процесором. Математично, blob - це N-розмірний масив. Caffe зберігає та передає дані, використовуючи blob-и. Blob-и забезпечують єдиний інтерфейс пам'яті, що містить дані; наприклад, наборів зображень, параметри моделі та похідні для оптимізації. Blob-и приховують обчислювальні витрати змішаних операцій на CPU чи GPU, синхронізуючи їх із хоста процесора на пристрій GPU, коли це необхідно. Пам'ять на хості та пристрої виділяється на вимогу для ефективного використання пам'яті. Звичайні розміри blob-ів для наборів даних зображення - це число N * канал K * висота H * ширина W. Кількість/ N - розмір набору даних. Пакетна обробка забезпечує кращу пропускну спроможність для обробки повідомлень та пристроїв. Для тренування ImageNet набір 256 зображень N = 256. Канал / K - це вимірність ознак, наприклад для RGB зображень K = 3. Багато прикладів Caffe є чотиривимірними з осями для прикладних програм для зображень, але цілком правильно використовувати blob-и для програм, які не використовують зображення. Наприклад, якщо потрібні повнозв’язні мережі, як-от звичайний багатошаровий персептрон, можна використовувати 2D-blob (sahpe(N, D)) і викликати InnerProductLayer. Розміри параметра blob залежать від типу та конфігурації шару. Для згорткового шару з 96 фільтрами розміром 11 х 11 та 3 входами розмір блоку становить 96 х 3 х 11 х 11. Для внутрішнього множення/ повнозв’язного шару з 1000 вихідними каналами та 1024 вхідними каналами параметр блоку становить 1000 х 1024. Обчислення шару та зв'язків. Шар є сутністю моделі та фундаментальної одиниці обчислень. Шари згорта.ть фільтри, pool, беруть внутрішні результати множення, застосовують нелінійності, такі як ReLU та Sigmoid та інші елементні перетворення, нормалізують, завантажують дані та обчислюють втрати, такі як softmax. Шар приймає вхід через нижні з'єднання і робить вихід через верхні з'єднання (рисунок 2.8). 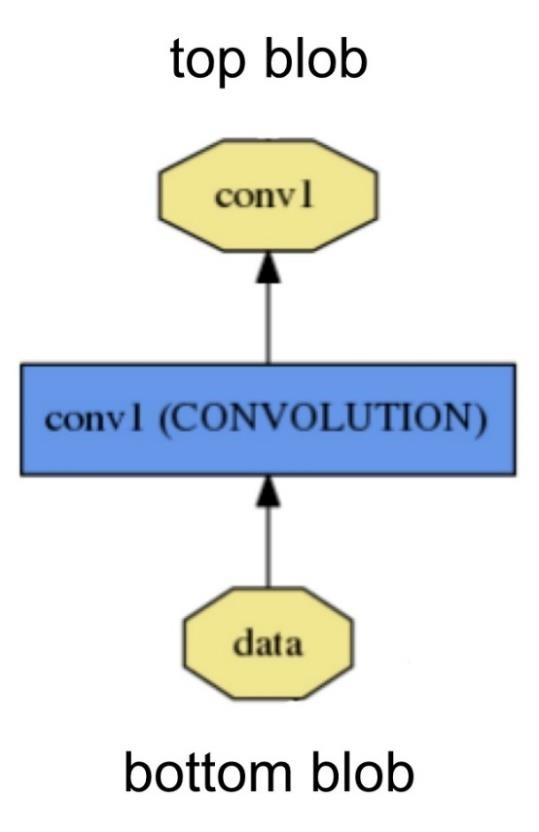 Рисунок 2.8 – Шар нейронної мережі у Caffe Кожен тип шару визначає три критичні обчислення: налаштування, пряме і зворотне проходження. Налаштування: ініціалізація шару та його зв’язків проводиться один раз при ініціалізації моделі. Пряме проходження: при заданому вході знизу обчислюється вихід і надсилається наверх. Зворотне проходження: з урахуванням градієнта w.r.t. верхній вихід обчислює градієнт w.r.t. на вхід і відправляє вниз. Шар з параметрами обчислює градієнт w.r.t. до його параметрів і зберігає його всередині. Шари мають дві основні функції для роботи в мережі в цілому: прямий прохід, який приймає входи і виробляє виходи, і зворотний прохід, який приймає градієнт щодо виходу, і обчислює градієнти щодо параметрів і на входи, які в свою чергу поширюються назад до попередніх шарів. Розробка користувацьких шарів вимагає мінімальних зусиль шляхом композиційної структури мережі та модульності коду. Визначте налаштування, пряме і зворотне проходження і цей шар готовий до включення в мережу. Мережа спільно визначає функцію та її градієнт за композицією та автоматичною диференціацією. Композиція виводу кожного шару обчислює функцію для виконання заданого завдання, а композиція кожного шару зворотний обчислює градієнт з втрат для вивчення завдання. Моделі Caffe - це повноціннй движок для машинного навчання. Мережа визначається набором шарів та їх зв'язків на мові моделювання відкритого тексту. Простий логістичний регресійний класифікатор зображено на рисунках 2.9, 2.10. 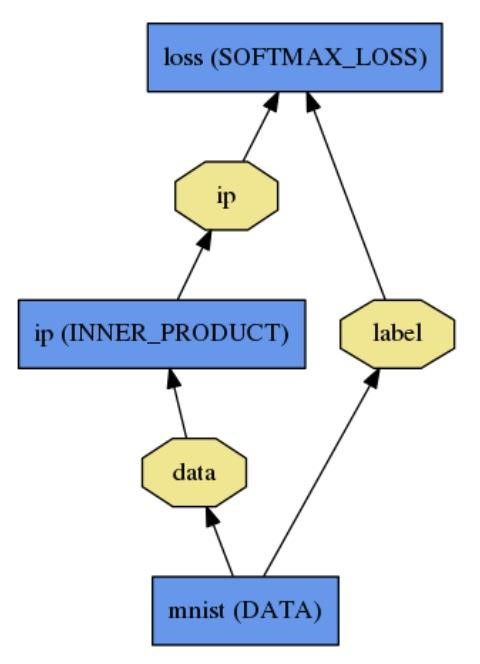 Рисунок 2.9 – Схема логістичного регресійного класифікатора Мережа являє собою набір шарів, з'єднаних в обчислювальний граф – орієнтований ациклічний графік (DAG). Caffe виконує всю перевірку будь-якого DAG шарів, щоб забезпечити правильність прямого і зворотного проходження. Типова мережа починається з рівня даних, який завантажується з диска, і закінчується шаром втрат, який обчислює ціль для задачі, такої як класифікація або реконструкція.  Рисунок 2.10 – Реалізація логістичного регресійного класифікатора за допомогою Caffe Ініціалізація моделі обробляється Net :: Init (). Ініціалізація переважно полягає в двох аспектах: складанні загальної DAG, створюючи blob-и та шари і викликає функцію SetUp () шарів. Він виконує перевірку правильності загальної архітектури мережі. Побудова мережі є незалежною від машини, де вона буде використовуватись, - blob-и та шари приховують деталі виконання з визначенням моделі. Після побудови мережа запускається на центральному або графічному процесорі, встановлюючи один перемикач, визначений у Caffe :: mode() і встановлений Caffe :: set_mode (). Шари поставляються з відповідними процедурами процесора та графічного процесора, які виробляють однакові результати (аж до числових помилок і з тестами для його захисту). Перемикач CPU / GPU є незалежним від визначення моделі. Як для дослідження, так і для розгортання найкраще поділити модель та реалізацію. Моделі визначаються в схемі буферів протоколу відкритого тексту (prototxt), тоді як навчені моделі серіалізуються за домогою бінарного протоколу буферу (binaryproto) у файлах .caffemodel. Формат моделі визначається схемою protobuf у caffe.proto. Caffe проводить комунікацію з Google Protocol Buffer для наступних сильних сторін: мінімальні розміри двійкових рядків під час серіалізації, ефективної серіалізації, текстового формату, який може читає людина, сумісного з бінарною версією, а також ефективні реалізації інтерфейсів на багатьох мовах, зокрема C ++ та Python. Це все сприяє гнучкості та розширюваності моделювання в Caffe. |