Лекция 1. Введение в БД и СУБД. Лекция Введение в бд и субд
 Скачать 306.5 Kb. Скачать 306.5 Kb.
|

|
Лекция 1. Введение в БД и СУБД 1.Основные термины и определения 1 2.Функции СУБД 2 3.Классификация СУБД [5] 4 4.Архитектура многопользовательских СУБД [2] 4 4.1.Централизованная архитектура 5 4.2.Технология с сетью и файловым сервером (архитектура «файл-сервер») 5 4.3.Технология «клиент-сервер» 6 4.4.Трехзвенная (трехуровневая) архитектура 9 4.5.Распределенные базы данных 10 4.Уровни представления БД [2] 10 Список литературы 12 Основные термины и определенияЕсли говорить об использовании вычислительной техники, то глобально можно выделить два основных направления ее применения. Первое направление – численные расчеты. Исторически оно появилось раньше и способствовало развитию методов численного решения сложных математических задач, развитию языков программирования, ориентированных на решение вычислительных задач. Второе направление – это хранение и обработка данных. Целью любой информационной системы является хранение и обработка данных о каких-либо объектах реального мира. Давайте рассмотрим такие важные для нас понятия как «данные» и «информация». Несмотря на огромное количество определений для этих понятий остановимся на следующих определениях. Информация представляет собой сведения об окружающих человека предметах, явлениях и процессах и является объектом таких операций как восприятие, передача, преобразование, хранение и использование. Когда используется термин «данные», то речь идет об информации, представленной в формализованном виде, пригодной для автоматической обработки при возможном участии человека. В широком смысле слова термин «база данных» (БД) – это совокупность сведений о конкретных объектах. При создании БД в основном преследуется цель упорядочить данные по различным признакам, чтобы иметь возможность извлекать из данных нужную информацию. Создание БД, ее поддержка, управление, а также доступ пользователей (прикладных программ) к самим данным осуществляется посредством специальных программных продуктов, называемых системами управления базами данных (СУБД). 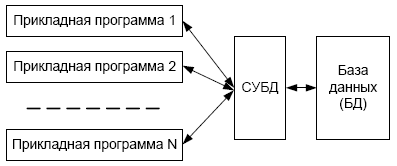 Рис. 1. Обеспечение независимости баз данных и прикладных программ Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры. Файлы, снабженные описанием хранимых в них данных и находящиеся под управлением СУБД, стали называть БД. Банк данных – система языковых, алгоритмических, программных, технических и организационных средств поддержки интегрированной совокупности данных, а также сами эти данные, представленные в виде баз данных. Функции СУБДС точки зрения пользователяСУБД реализует: определение структуры создаваемой БД, хранение данных, а также возможность изменения (добавления, редактирования и удаления) и обработки данных, возможность манипулирования данными (выборка необходимых данных, выполнение вычислений, разработка и получение различных выходных документов). Для работы с хранящейся в базе данных информацией СУБД предоставляет программам и пользователям следующие два типа языков: язык описания данных – высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных; язык манипулирования данными – совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам. Названные языки в различных СУБД могут иметь отличия. Наибольшее распространение получили два стандартных языка: QBE (Query By Example) – язык запросов по образцу и SQL (Structured Query Language) – структурированный язык запросов. QBE в основном обладает свойствами языка манипулирования данными, SQL сочетает в себе свойства языков обоих типов – описания и манипулирования данными. СУБД также выполняет функции, которые называют низкоуровневыми. 1. Обеспечение независимости прикладных программ и данных (логической и физической независимости). Важнейшим свойством СУБД является возможность поддерживать два независимых взгляда на базу данных – «взгляд пользователя», воплощаемый в логическом представлении данных, и его отражения в прикладных программах; и «взгляд системы» – физическое представление данных в памяти ЭВМ. Обеспечение логической независимости данных предоставляет возможность изменения (в определенных пределах) логического представления базы данных без необходимости изменения физических структур хранения данных. Таким образом, изменение логического представления данных в прикладных программах не приводит к изменению структур хранения данных. Обеспечение физической независимости данных предоставляет возможность изменять (в определенных пределах) способы организации базы данных в памяти ЭВМ не вызывая необходимости изменения «логического» представления данных. Таким образом, изменение способов организации базы данных не приводит к изменению прикладных программ. 2. Защита логической целостности. Обеспечение целостности базы данных составляет необходимое условие успешного функционирования базы данных, особенно для случая использования базы данных в сетях. Целостность базы данных есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Поддержание целостности базы данных включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние базы данных описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в базе данных, или отсутствие повторяющихся записей в таблицах реляционных баз данных. 3. Защита физической целостности. Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными базы данных, которая отслеживается СУБД от начала до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется. Примером транзакций является операция перевода денег с одного счета на другой в банковской системе. Здесь необходим, по крайней мере, двух шаговый процесс. Сначала снимают деньги с одного счета, затем добавляют их к другому счету. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс между счетами. Ведение журнала изменений в базе данных (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении. Журнал СУБД – это особая база данных или часть основной базы данных, непосредственно недоступная пользователю и используемая для записи информации обо всех изменениях базы данных. В различных СУБД в журнал могут заноситься записи, соответствующие изменениям в СУБД на разных уровнях: от минимальной внутренней операции модификации страницы внешней памяти до логической операции модификации базы данных (например, вставки записи, удаления столбца, изменения значения в поле) и даже транзакции. Для эффективной реализации функции ведения журнала изменений в базе данных необходимо обеспечить повышенную надежность хранения и поддержания в рабочем состоянии самого журнала. Иногда для этого в системе хранят несколько копий журнала. 4. Синхронизация работы нескольких пользователей. Достаточно часто может иметь место ситуация, когда несколько пользователей одновременно выполняют операцию обновления одних и тех же данных. Такие коллизии могут привести к нарушению логической целостности данных, поэтому система должна предусматривать меры, не допускающие обновление данных другим пользователям, пока работающий с этими данными пользователь полностью не закончит с ними работать. Основным используемым здесь понятием является понятие «блокировка». Блокировки необходимы для того, чтобы запретить различным пользователям возможность одновременно работать с базой данных, поскольку это может привести к ошибкам. Для реализации этого запрета СУБД устанавливает блокировку на объекты, которые использует транзакция. Существуют разные типы блокировок – табличные, страничные, строчные и другие, которые отличаются друг от друга количеством заблокированных записей. Чаще других используется строчная блокировка – при обращении транзакции к одной строке блокируется только эта строка, остальные строки остаются доступными для изменения. Таким образом, процесс внесения изменений в базу данных состоит из следующей последовательности действий: выдается оператор начала транзакции, выдается оператор изменения данных, СУБД анализирует оператор и пытается установить блокировки, необходимые для его выполнения, в случае успешной блокировки оператор выполняется, затем процесс повторяется для следующего оператора транзакции. После успешного выполнения всех операторов внутри транзакции выполняется оператор фиксации транзакции. СУБД фиксирует изменения, сделанные транзакцией, и снимает блокировки. В случае неуспеха выполнения какого-либо из операторов транзакция «откатывается», данные получают прежние значения, блокировки снимаются. 5. Управление ресурсами среды хранения. Методы и алгоритмы управления данными являются «внутренним делом» СУБД и прямого отношения к пользователю не имеют. Качество реализации этой функции наиболее сильно влияет на эффективность работы специфических информационных систем, например, работающих с огромными базами данных, со сложными запросами, осуществляющих большие объемы обработки данных. Буферизация данных и как следствие реализация функции управления буферами оперативной памяти обусловлена тем, что объем оперативной памяти меньше объема внешней памяти. Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена данными между внешней и оперативной памятью. В буферах временно хранятся фрагменты базы данных, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу данных после обработки. 6. Управление системой безопасности. Обеспечение безопасности достигается в СУБД шифрованием данных, защиты паролем, поддержкой уровней доступа к базе данных и к отдельным ее элементам (таблицам, формам, отчетам и т.д.). Классификация СУБД [5]По модели представления данных: иерархические, сетевые, реляционные, постреляционные, объектно-реляционные, объектно-ориентированные, многомерные, документно-ориентированные. По степени распределённости: локальные СУБД (все части локальной СУБД размещаются на одном компьютере), распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах). По способу доступа к БД (по архитектуре): централизованные, файл-серверные, клиент-серверные, трехзвенная архитектура, встраиваемые. Встраиваемая СУБД – библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных (например, геоинформационные системы). Примеры: OpenEdge, SQLite, BerkeleyDB, один из вариантов Firebird, MySQL, Sav Zigzag, Microsoft SQL Server Compact, ЛИНТЕР. Архитектура многопользовательских СУБД [2]Понятие базы данных изначально предполагало возможность решения многих задач несколькими пользователями. В связи с этим, важнейшей характеристикой современных СУБД является наличие многопользовательской технологии работы. Разная реализация таких технологий в разное время была связана как с основными свойствами вычислительной техники, так и с развитием программного обеспечения. Дадим краткую характеристику этих технологий в хронологическом порядке. Централизованная архитектураПри использовании этой технологии база данных, СУБД и прикладная программа (приложение) располагаются на одном компьютере (рис. 2). 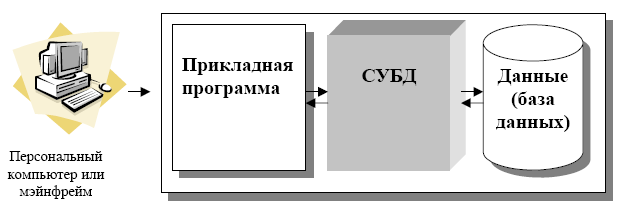 Рис. 2. Централизованная архитектура Для такого способа организации не требуется поддержки сети и все сводится к автономной работе. Работа построена следующим образом: База данных в виде набора файлов находится на жестком диске компьютера. На том же компьютере установлены СУБД и приложение для работы с БД. Пользователь запускает приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации. Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД. СУБД инициирует обращения к данным, обеспечивая выполнение запросов пользователя (осуществляя необходимые операции над данными). Результат СУБД возвращает в приложение. Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов. Подобная архитектура использовалась в первых версиях СУБД DB2, Oracle, Ingres. Многопользовательская технология работы обеспечивалась либо режимом мультипрограммирования (одновременно могли работать процессор и внешние устройства – например, пока в прикладной программе одного пользователя шло считывание данных из внешней памяти, программа другого пользователя обрабатывалась процессором), либо режимом разделения времени (пользователям по очереди выделялись кванты времени на выполнении их программ). Такая технология была распространена в период «господства» больших ЭВМ (IBM-370, ЕС-1045, ЕС-1060). Основным недостатком этой модели является резкое снижение производительности при увеличении числа пользователей. Технология с сетью и файловым сервером (архитектура «файл-сервер»)Увеличение сложности задач, появление персональных компьютеров и локальных вычислительных сетей явились предпосылками появления новой архитектуры «файл-сервер». Файл-серверная архитектура предполагает наличие в сети сервера, на котором хранятся файлы централизованной БД. В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных. После завершения работы пользователи копируют файлы с обработанными данными обратно на сервер, откуда их могут взять и обработать другие пользователи. Недостатки такой организации данных очевидны. При одновременном обращении множества пользователей к одним и тем же данным производительность работы резко падает, т.к. необходимо дождаться пока пользователь, работающий с данными завершит работу. В противном случае возможно затирание исправлений сделанных одним пользователем, изменениями других пользователей (рис. 3). 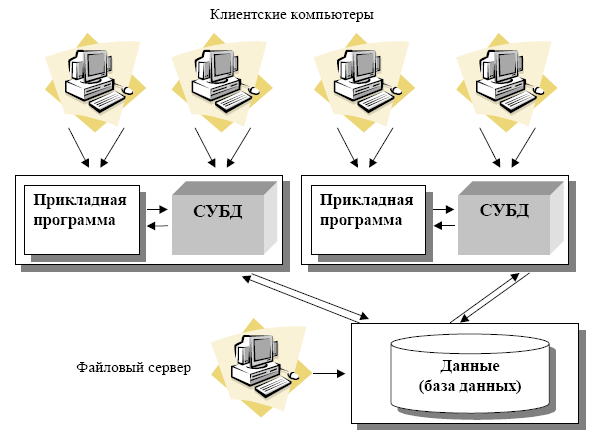 Рис. 3. Архитектура «файл-сервер» Работа построена следующим образом: База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (файлового сервера). Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлены СУБД и приложение для работы с БД. На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации. Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на файловом сервере. СУБД инициирует обращения к данным, находящимся на файловом сервере, в результате которых часть файлов БД копируется на клиентский компьютер и обрабатывается, что обеспечивает выполнение запросов пользователя (осуществляются необходимые операции над данными). При необходимости (в случае изменения данных) данные отправляются назад на файловый сервер с целью обновления БД. Результат СУБД возвращает в приложение. Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов. Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro. Технология «клиент-сервер»Использование технологии «клиент – сервер» предполагает наличие некоторого количества компьютеров, объединенных в сеть, один из которых выполняет особые управляющие функции (является сервером сети). Так, архитектура «клиент – сервер» разделяет функции приложения пользователя (называемого клиентом) и сервера. Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL (Structured Query Languague), являющемся промышленным стандартом в мире реляционных БД. Удаленный сервер принимает запрос и переадресует его SQL-серверу БД. SQL-сервер – специальная программа, управляющая удаленной базой данных. SQL-сервер обеспечивает интерпретацию запроса, его выполнение в базе данных, формирование результата выполнения запроса и выдачу его приложению-клиенту. При этом ресурсы клиентского компьютера не участвуют в физическом выполнении запроса; клиентский компьютер лишь отсылает запрос к серверной БД и получает результат, после чего интерпретирует его необходимым образом и представляет пользователю. Так как клиентскому приложению посылается результат выполнения запроса, по сети «путешествуют» только те данные, которые необходимы клиенту. В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там же, где хранятся данные (на сервере), нет необходимости в пересылке больших пакетов данных. Кроме того, SQL-сервер, если это возможно, оптимизирует полученный запрос таким образом, чтобы он был выполнен в минимальное время с наименьшими накладными расходами. Архитектура системы представлена на рис. 4. 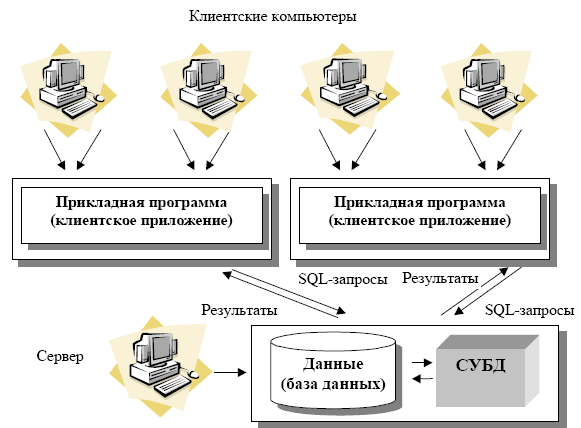 Рис. 4. Архитектура «клиент – сервер» Все это повышает быстродействие системы и снижает время ожидания результата запроса. При выполнении запросов сервером существенно повышается степень безопасности данных, поскольку правила целостности данных определяются в базе данных на сервере и являются едиными для всех приложений, использующих эту БД. Таким образом, исключается возможность определения противоречивых правил поддержания целостности. Мощный аппарат транзакций, поддерживаемый SQL-серверами, позволяет исключить одновременное изменение одних и тех же данных различными пользователями и предоставляет возможность откатов к первоначальным значениям при внесении в БД изменений, закончившихся аварийно. Итак, в результате работа построена следующим образом: База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети). СУБД располагается также на сервере сети. Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлено клиентское приложение для работы с БД. На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к СУБД, расположенной на сервере, на выборку/обновление информации. Для общения используется специальный язык запросов SQL, т.е. по сети от клиента к серверу передается лишь текст запроса. СУБД инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на сервере. СУБД инициирует обращения к данным, находящимся на сервере, в результате которых на сервере осуществляется вся обработка данных и лишь результат выполнения запроса копируется на клиентский компьютер. Таким образом, СУБД возвращает результат в приложение. Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов. Рассмотрим, как выглядит разграничение функций между сервером и клиентом. Функции приложения-клиента: Посылка запросов серверу. Интерпретация результатов запросов, полученных от сервера. Представление результатов пользователю в некоторой форме (интерфейс пользователя). Функции серверной части: Прием запросов от приложений-клиентов. Интерпретация запросов. Оптимизация и выполнение запросов к БД. Отправка результатов приложению-клиенту. Обеспечение системы безопасности и разграничение доступа. Управление целостностью БД. Реализация стабильности многопользовательского режима работы. В архитектуре «клиент–сервер» работают так называемые «промышленные» СУБД. Промышленными они называются из-за того, что именно СУБД этого класса могут обеспечить работу информационных систем масштаба среднего и крупного предприятия, организации, банка. К разряду промышленных СУБД принадлежат Oracle, MS SQL Server, IBM DB2, MySQL, Firebird, Interbase, Sybase, PostgreSQL, Caché, MDBS, Informix, InterBase и ряд других. Как правило, SQL-сервер обслуживается отдельным сотрудником или группой сотрудников (администраторы SQL-сервера). Они управляют физическими характеристиками баз данных, производят оптимизацию, настройку и переопределение различных компонентов БД, создают новые БД, изменяют существующие и т.д., а также выдают привилегии (разрешения на доступ определенного уровня к конкретным БД, SQL-серверу) различным пользователям. Рассмотрим основные достоинства данной архитектуры по сравнению с архитектурой «файл-сервер»: существенно уменьшается сетевой трафик; уменьшается сложность клиентских приложений (большая часть нагрузки ложится на серверную часть), а, следовательно, снижаются требования к аппаратным мощностям клиентских компьютеров; наличие специального программного средства – SQL-сервера – приводит к тому, что существенная часть проектных и программистских задач становится уже решенной; существенно повышается целостность и безопасность БД. К числу недостатков можно отнести более высокие финансовые затраты на аппаратное и программное обеспечение сервера, а также то, что большое количество клиентских компьютеров, расположенных в разных местах, вызывает определенные трудности со своевременным обновлением клиентских приложений на всех компьютерах-клиентах. Тем не менее, архитектура «клиент – сервер» хорошо зарекомендовала себя на практике, в настоящий момент существует и функционирует большое количество БД, построенных в соответствии с данной архитектурой. Трехзвенная (трехуровневая) архитектураТрехзвенная (в некоторых случаях многозвенная) архитектура представляет собой дальнейшее совершенствование технологии «клиент-сервер». Рассмотрев архитектуру «клиент-сервер», можно заключить, что она является 2-звенной: первое звено – клиентское приложение, второе звено – сервер БД + сама БД. В трехзвенной архитектуре вся бизнес-логика (деловая логика), ранее входившая в клиентские приложения, выделяется в отдельное звено, называемое сервером приложений. При этом клиентским приложениям остается лишь пользовательский интерфейс. Так, в качестве клиентского приложения может выступать Web-браузер (рис. 5). 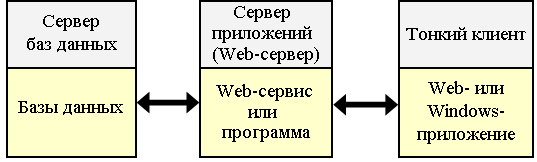 Рис. 5. Схема работы с БД в трехуровневой архитектуре Достоинства трехзвенной архитектуры. Теперь при изменении бизнес-логики более нет необходимости изменять клиентские приложения и обновлять их у всех пользователей. Кроме того, максимально снижаются требования к аппаратуре пользователей. Итак, в результате работа построена следующим образом: База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети). СУБД располагается также на сервере сети. Существует специально выделенный сервер приложений, на котором располагается программное обеспечение (ПО) делового анализа (бизнес-логика). Существует множество клиентских компьютеров, на каждом из которых установлен так называемый «тонкий клиент» – клиентское приложение, реализующее интерфейс пользователя. На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение – тонкий клиент. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к ПО делового анализа, расположенному на сервере приложений. Сервер приложений анализирует требования пользователя и формирует запросы к БД. Для общения используется специальный язык запросов SQL, т.е. по сети от сервера приложений к серверу БД передается лишь текст запроса. СУБД инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на сервере. СУБД инициирует обращения к данным, находящимся на сервере, в результате которых результат выполнения запроса копируется на сервер приложений. Сервер приложений возвращает результат в клиентское приложение (пользователю). Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов. Распределенные базы данныхРаспределенная БД располагается на нескольких компьютерах. Информация на этих компьютерах может пересекаться и даже дублироваться. Для управления такими БД предназначена система управления распределенными БД. Система скрывает от пользователей обращения к данным, расположенным на других компьютерах. Для пользователя все выглядит так, как будто вся информация находится на одном сервере. Уровни представления БД [2]Создание базы данных предполагает интеграцию данных, предназначенных для решения нескольких прикладных задач разных пользователей. Соответственно, при интеграции данных должны учитываться требования к данным каждого пользователя, основанные на его представлении о данных и связях между ними. Далее эти требования должны обобщаться в единое представление, которое и будет служить основой для построения единой базы данных (рис. 6). Обобщение представлений всех пользователей о данных называется концептуальной моделью (схемой) БД. Концептуальная модель представляет информационное описание предметной области с учетом логических взаимосвязей, поэтому её еще называют инфологической (информационно-логической) моделью. В модели отсутствуют какие-либо понятия, связанные с ЭВМ, памятью ЭВМ, способами размещения данных в памяти ЭВМ, и, по сути, это модель только предметной области. 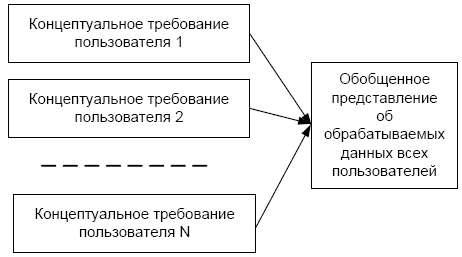 Рис. 6. Обобщение представления пользователей о данных Как уже отмечалось, для создания базы данных и работы с ней используется система управления базами данных. Каждая конкретная СУБД поддерживает определенный вид данных (форматов записей и отношений), называемый моделью данных СУБД. Следующий этап разработки базы данных предполагает выбор представления концептуальной модели с помощью модели данных конкретной СУБД. Полученное таким образом представление концептуальной модели называется логической моделью БД. Или другими словами, логическая модель – это концептуальная схема, специфицированная в языке конкретной СУБД. Логическая модель представляет данные и элементы данных вне зависимости от их содержания и среды хранения. Далее разработчик системы средствами СУБД отображает полученную логическую модель БД в память ЭВМ и определяет методы доступа. Полученное представление данных в памяти ЭВМ называется внутренним представлением или структурой хранения (также встречается термин физическая модель). Прикладные программы работают с логической моделью, причем каждому пользователю представляется подмножество этой логической модели (подсхема), отражающее его представление о предметной области. Каждая прикладная программа «видит» и обрабатывает только те данные, которые необходимы именно ей. Соответствующее «видение» данных прикладными программами (пользователями) представляет собой внешние представления. Взаимосвязь вышеуказанных моделей изображена на рис. 7.  Рис. 7. Различные представления о данных в БД На данной схеме выделены три различных уровня описания данных (внешний, концептуальный, внутренний). Эти уровни формируют так называемую трехуровневую архитектуру ANSI/SPARC, предложенную в 1975 г. Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального института стандартизации США (American National Standards Institute – ANSI). Основная цель этой архитектуры состоит в отделении пользовательского представления о данных в базе данных от их физического представления. Использование таких представлений о данных позволяет обеспечить выполнение основного требования к БД – независимости программ и данных. При изменении прикладных программ может измениться соответствующее внешнее представление, но логическая модель данных не изменяется и, соответственно, не будут изменяться другие прикладные программы. Использование соответствующих представлений также позволяет четко разграничить полномочия различных лиц, работающих с базой данных. Соответствующие представления позволяют описать «видение» базы данных разными лицами, работающими с ней: внешнее представление – представление специалиста предметной области (пользователя); внешнее представление и логическая модель – представление прикладного программиста, разрабатывающего конкретное приложение для пользователя; логическая модель и внутреннее представление – представление системного программиста, администрирующего базу данных. Список литературыВ.В. Кириллов Основы проектирования реляционных баз данных Учебное пособие Санкт-Петербургский Государственный институт точной механики и оптики Швецов, В. И. Базы данных: учебное пособие / В. И. Швецов; Нижегород. гос. ун-т [Электронный ресурс]. Режим доступа: http://window.edu.ru/window_catalog/redir?id=61460&file=shvetsov-lectures.pdf Е. Мамаев MS SQL Server 2000 Основы современных баз данных С.Д. Кузнецов, информационно-аналитические материалы Центра Информационных Технологий Системы управления базами данных [Электронный ресурс]. Режим доступа: http://ru.wikipedia.org/wiki/%D0%A1%D0%A3%D0%91%D0%94 |