Поиск слов в текстовом документе
 Скачать 394.5 Kb. Скачать 394.5 Kb.
|

|
© К. Поляков, 2020-2021 10 (базовый уровень, время – 3 мин)Тема: Поиск слов в текстовом документе Что проверяется: Информационный поиск средствами операционной системы или текстового процессора 3.5.2. Использование инструментов поисковых систем (формирование запросов) 2.1. Умение осуществлять поиск и отбор информации Что нужно знать: текстовые редакторы и текстовые процессоры имеют встроенную функцию поиска; большинство программ (Блокнот, OpenOffice, LibreOffice) просто ищут цепочку символов, то есть находят все формы данного слова в наиболее совершенных редакторах (MicrosoftOffice) есть возможность отметить режим Только слово целиком, при этом программа ищет только заданное слово именно в этой форме если нужно найти слова, начинающиеся только со строчной или только с заглавной буквы, нужно включить флажок С учётом регистра Пример задания:Р-00 (демо-2021). С помощью текстового редактора определите, сколько раз, не считая сносок, встречается слово «долг» или «Долг» в тексте романа в стихах А.С. Пушкина «Евгений Онегин» (файлы 10-0.docx, 10-0.txt). Другие формы слова «долг», такие как «долги», «долгами» и т.д., учитывать не следует. В ответе укажите только число. Решение (простейшие текстовые редакторы): Решение этой задачи существенно зависит от возможностей программы, которую вы используете. Рассмотрим сначала самый худший вариант, когда в вашем распоряжении только простейший текстовый редактор типа Блокнота. Загрузите файл 10-0.txt в редактор. С помощью комбинации клавиш Ctrl+F (или верхнего меню Правка – Найти) нужно вызвать окно поиска и ввести нужное слово: 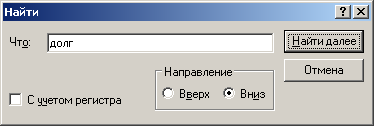 Важно! Поскольку нас интересует слово «долг», которое может начитаться как с заглавной, так и со строчной буквы, НЕ нужно включать флажок «С учетом регистра» далее щелкаем по кнопке Найти далее (можно также щёлкнуть мышью на тексте и нажимать клавишу F3) к сожалению, простые программы ищут только заданную цепочку символов и не умеют искать слово в одной заданной форме (то есть будут найдены также слова «долго», «долги», «долгий» и т.п., которые нас не интересуют); поэтому приходится просматривать все найденные слова и вручную считать, сколько раз встретится именно слово «долг», а не другие слова, содержащие эту цепочку символов Ответ: 2. Решение (LibreOffice, А.Т. Фомин, г. Ейск): «Быстрый» поиск: Нажмите на клавиатуре сочетание клавиш Ctrl + F. В нижней части окна появляется панель поиска: В  «Расширенный» поиск Перейдите в меню программы Правка → Найти и заменить (сочетание клавиш Ctrl + H). Появится диалоговое окно: 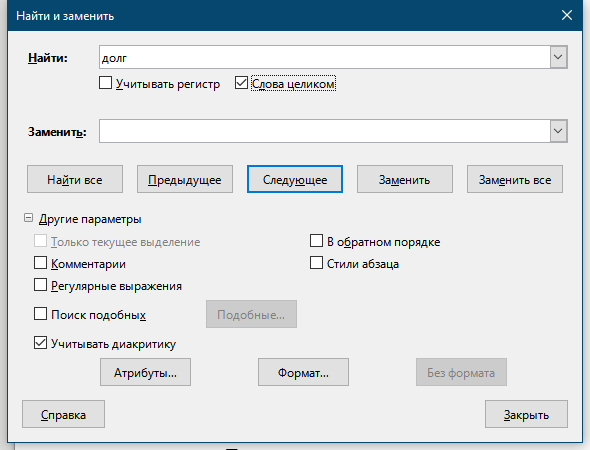 Установите флажок «Слова целиком» и нажмите на кнопку «Найти все». Числовой результат поиска появится в статус-баре, в нижней части окна программы. Для перемещения в документе, по найденным словам, нажимайте кнопки «Предыдущее» (Alt + П) или «Следующее» (Alt + Ю). «Сложный» поиск Для поиска подстроки по определенным («сложным») критериям используйте «Регулярные выражения». Установите флажок «Регулярные выражения» в диалоговом окне «Найти и заменить». Теперь в строке поиска можно использовать регулярные выражения. Например, давайте найдем в тексте все слова, которые начинаются на долг, а заканчиваются любым одним алфавитным символом (от «а» до «я»). Для этого введите следующее регулярное выражение: [:space:]долг[а-я][:space:] Количество таких слов в романе будет 14 («долго» и «долги»). Некоторые регулярные выражения:
Более подробную информацию по использованию регулярных выражений см. на сайте справки к программе LibreOffice Writer: https://help.libreoffice.org/3.5/Common/List_of_Regular_Expressions/ru (С. Кабанов) можно использовать и такой приём: заменить искомое слово любым символом; при этом будет выдано количество замен, которое является ответом Решение (Microsoft Word): в программе Word открываем окно поиска (Ctrl+F) и вводим нужное слово; получаем те же результаты, что и в Блокноте: 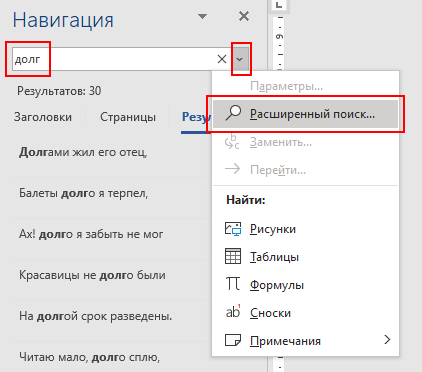 справа от поля ввода открываем список стрелкой, выбираем Расширенный поиск 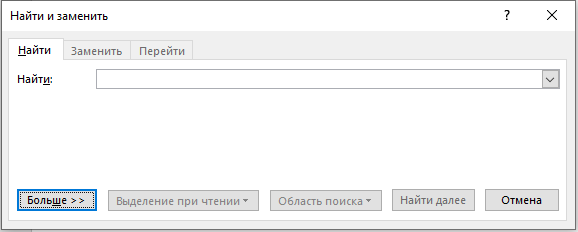 и нажимаем кнопку Больше >>. тут есть возможность выбрать режим поиска «Только слово целиком»: 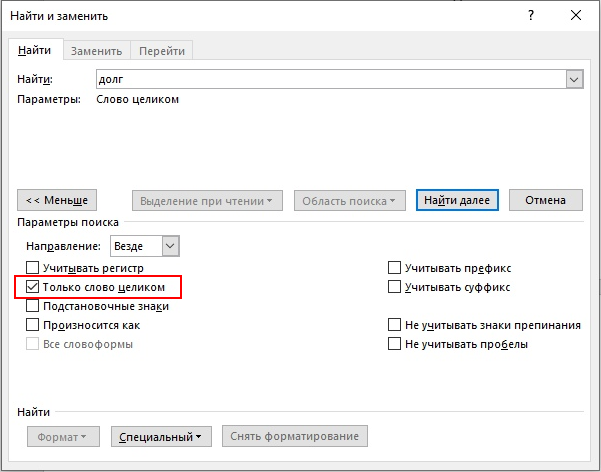 после этого программа будет искать только то, что нам нужно, причём в современных версиях Word на панели Навигация слева от документа сразу видно, сколько слов найдено и в каких предложениях: 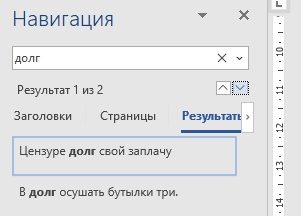 Ответ: 2. Решение (с помощью программы, С.С. Поляков): можно использовать программу на Python, которая читает в память файл целиком, разбивает его на слова, переводит все символы в нижний регистр (к строчным буквам) и считает, сколько заданных слов оказалось в этом списке: import re n = 0 for x in re.split('\W+',open('10-0.txt', 'r').read().lower()): if x == 'долг': n += 1 print(n) возможно также решение без использования модуля re: s = open('10-0.txt', 'r').read().lower().split() L = [x for x in s if x == 'долг' or (x.startswith('долг') and notx[4].isalpha())] print(len(L)) Ответ: 2. Решение (с помощью программы, Б.С. Михлин): Замечание. (С.С. Поляков) Этот вариант не сработает, если после слова «долг» в тексте стоит точка, запятая или другой знак препинания. в некоторых случаях можно решить задачу и не используя модуль re: with open('10-0.txt') as Fin: n = 0 for s in Fin: # построчное чтение файла в s s = s.lower() # привести к нижнему регистру # перебор элементов списка, полученного разрезанием # s попробелам for x in s.split(): if x == 'долг': n += 1 print(n) вариант без использования метода lower (нужно включить в условие слова «долг» и «Долг»): with open('10-0.txt') as Fin: n = 0 for s in Fin: # построчное чтение файла в s for x in s.split(): if x == 'долг' or x=='Долг': n += 1 print(n) вариант без разрезания строки с помощью метода split (считаем, сколько есть слов «долг», после которых стоит пробел или символ перехода на новую строку) with open('10-0.txt') as Fin: n = 0 for s in Fin: # построчное чтение файла в s s = s.upper() n += s.count('ДОЛГ ') + s.count('ДОЛГ\n') print(n) Этот алгоритм сработает только тогда, когда у корня не может быть приставок. Ответ: 2. |