Шпора БД. 1. Основні поняття. Бази даних, банк даних, інформаційна система. Традиційні файлові системи. Бази даних. Системи управління базами даних (субд). Компоненти банку даних. Основні поннятя
 Скачать 299.76 Kb. Скачать 299.76 Kb.
|

|
Хешовані файли У хешрованому файлі записи не обов'язково повинні вводитися у файл послідовно. Замість цього для обчислення адреси сторінки, на якій повинен знаходитися запис, використовується хеш-функція (hash function), параметрами якої є значення одного або декількох полів цього запису. Подібне поле називається полем хешування (hash field), а якщо поле є також ключовим полем файлу, то воно називається хеш-ключем (hash key). Записи в хешуванням файлі розподілені довільним чином по всьому доступному для файлу просторові. З цієї причини хешовані файли інколи називають файлами з довільним або прямим доступом (random file або direct file). Хеш-функція вибирається так, щоб записи усередині файлу були розподілені найбільш рівномірно. Один з методів створення хеш-функції називають згорткою (folding) і заснований на виконанні деяких арифметичних дій над різними частинами поля хешування. При цьому символьні рядки перетворяться в цілі числа з використанням деякого кодування (на основі розташування букв в алфавіті або код символів ASCII). Наприклад, можна перетворити в ціле число перші два символи поля табельного номера співробітника (атрибут staffNo), а потім скласти набутого значення з останніми цифрами цього номера. Обчислена сума використовується як адреса дискової сторінки, на якій зберігатиметься даний запис. Популярніший альтернативний метод заснований на хешуванні із застосуванням залишку від ділення. У цьому методі використовується функція MOD, якою передається значення поля. Функція ділить набутого значення на деяке заздалегідь задане ціле число, після чого залишок від ділення використовується як адреса на диску. Недоліком більшості хеш-функцій є те, що вони не гарантують здобуття унікальної адреси, оскільки кількість можливих значень поля хешування може бути значно більше кількості адрес, доступних для запису. Кожна обчислена хеш-функцією адреса відповідає деякій сторінці, або сегменту (bucket), з декількома вічками (слотами), призначенмими для декількох записів. В межах одного сегменту запису разміщаютсья в слотах в порядку надходження. Той випадок, коли одна і та ж адреса генерується для двох або більше записів, називається конфліктом (collision), а подібні записи –синонімами. У цій ситуації новий запис необхідно вставити в іншу позицію, оскільки місце з обчисленою для неї хеш-адресою вже зайняте. Вирішення конфліктів ускладнює супровід хешованих файлів і знижує загальну продуктивність їх роботи. Для вирішення конфліктів можна використовувати наступні методи: ‒ відкрита адресація; ‒ незв'язана область переповнення; ‒ зв'язана область переповнення; ‒ багатократне хешування. Відкрита адресація При виникненні конфлікту система виконує лінійний пошук першого доступного слота для вставки в нього нового запису. Після невдалого пошуку порожнього слота в останньому сегменті пошук продовжується з першого сегменту. При вибірці запису використовується той же метод, який застосовувався при збереженні запису, за винятком того, що запис в даному випадку розглядається як неіснуючий, якщо до виявлення шуканого запису буде виявлений порожній слот. Наприклад, розглянемо просту хеш-функцію на основі залишку від ділення цифр табельного номера співробітника по модулю 3 (MOD 3). Незв'язана область переповнення Замість пошуку порожнього слота для вирішення конфліктів можна використовувати область переповнення, призначену для розміщення записів, які не можуть бути вставлені за обчисленою для них адресою хешування. В даному випадку замість пошуку вільного слота для нового запису він відразу ж поміщується в область переповнення. На перший погляд може здатися, що цей підхід не дає великого виграшу в продуктивності. Проте при уважнішому аналізі виявляється, що при використанні відкритої адресації конфлікти, усунені за допомогою першого вільного слота, можуть викликати додаткові конфлікти із записами, які матимуть хеш-значення, рівне адресі цього раніше вільного слота. Таким чином, кількість конфліктів зростатиме, а продуктивність – падати. З іншого боку, якщо кількість конфліктів вдасться звести до мінімуму, то лінійний пошук в малій області переповнення виконуватиметься досить швидко. Зв'язана область переповнення Як і в попередньому методі, в цьому методі для вирішення конфліктів із записами, які не можуть бути розміщені в слоті з їх адресою хешування, використовується область переповнення. Проте в даному методі кожному сегменту виділяється додаткове поле, яке інколи називається покажчиком сино німа. Воно визначає наявність конфлікту і вказує сторінку в області переповнення, використану для розрішення конфлікту. Якщо покажчик дорівнює нулю, то жодних конфліктів немає. Для швидшого доступу до запису переповнення можна використовувати вказівник синоніма, який показує на адресу слота усередині області переповнення, а не на адресу сегменту. Записи всередині області переповнення також мають покажчики синоніма, які містять в області переповнювання адресу наступного синоніма для такої ж адреси, тому всі синоніми однієї адреси можуть бути доступними за допомогою ланцюжка покажчиків. Багатократне хешування Альтернативний спосіб вирішення конфліктів полягає в прикладі другої хеш-функції, якщо перша функція призводить до виникнення конфлікту. Мета другої хеш-функції полягає в здобутті нової адреси хешування, яка дозволила б уникнути конфлікту. Друга хеш-функція зазвичай використовується для розміщення записів в області переповнення. При роботі з хешованими файлами запис може бути достатньо ефективно знайдений за допомогою першої хеш-функції, а в разі виникнення конфлікту для визначення його адреси слід застосувати один з перерахованих вище способів. Перш ніж редагувати хешований запис, його слід знайти. Якщо оновлюється значення поля, яке не є хеш-ключем, то таке обновлення може бути виконане досить просто, причому оновлений запис зберігається в тому ж слоті. Але якщо оновлюється значення хеш-ключа, то до розміщення оновленого запису потрібно буде обчислити хеш-функцію. Якщо при цьому буде отримано нове хеш-значення, то початковий запис має бути видалений з поточного слота і збережений за знову обчисленою адресою. Індексно-послідовні файли Відсортований файл даних з первинним індексом називається індексованим послідовним файлом, або індексно-послідовним файлом. Ця структура є компромісом між файлами з повністю послідовною і повністю довільною організацією. У такому файлі записи можуть оброблятися як послідовно, так і вибірково, з довільним доступом, здійснюваним на основі пошуку по заданому значенню ключа з використанням індексу. Індексований послідовний файл має більш універсальну структуру, яка зазвичай включає наступні компоненти: ‒ первинна область зберігання; ‒ окремий індекс або декілька індексів; ‒ область переповнення. Подібна організація файлів використовується в методі індексно-послідовного доступу (Indexed Sequential Access Method – ISAM), розробленому компанією IBM, який тісно пов'язаний з характеристиками використовуваного устаткування. Для підтримки високої ефективності роботи файлів такого типу їх слід періодично піддавати реорганізації. Пізніше на базі методу доступу ISAM був розроблений метод віртуального послідовного доступу (Virtual Sequential Access Method – VSAM), що володіє повною незалежністю від особливостей апаратного забезпечення. У ньому не передбачено використання спеціальної області переповнення, але в області даних виділений простір, призначений для розширення. У міру зростання або скорочення розміру файлу цей процес управляється динамічно, без необхідності періодичного виконання реорганізації. Зазвичай велика частина первинного індексу може зберігатися в оперативній пам'яті, що дозволяє обробляти його набагато швидше. Для прискорення пошуку можуть застосовуватися спеціальні методи доступу, наприклад метод бінарного пошуку. Основним недоліком використання первинного індексу (як і при роботі з будь-яким іншим відсортованим файлом) є необхідність дотримання послідовності сортування при вставці і видаленні записів. Ці проблеми ускладнюються тим, що потрібно підтримувати порядок сортування як у файлі даних, так і в індексному файлі. У подібному випадку може використовуватися метод, що полягає у вживанні області переповнення і ланцюжка зв'язаних покажчиків, аналогічно методу, використовуваному для вирішення конфліктів в хешованих файлах. 30. Щільні та нещільні індекси. Структури типу В-дерева. В+ - дерева. Вторинні індекси Вторинний індекс також є впорядкованим файлом, аналогічним первинному індексу. Проте пов'язаний з первинним індексом файл даних завжди відсортований по ключу цього індексу, тоді як файл даних, пов'язаний з вторинним індексом, не обов'язково має бути відсортований по ключу індексації. Крім того, ключ вторинного індексу може містити значення, що повторюються, що не допускається для значень ключа первинного індексу. Наприклад, для таблиці Staff можна створити вторинний індекс по полю номера відділення компанії branNo. Для роботи з такими значеннями ключа вторинного індексу, що повторюються, зазвичай використовуються перераховані нижче методи. ‒ Створення щільного вторинного індексу, який відповідає всім записам файлу даних, але при цьому в ньому допускається наявність дублікатів. ‒ Створення вторинного індексу із значеннями для всіх унікальних значень ключа. При цьому покажчики блоків є багатозначними, оскільки кожне його значення відповідає одному з дублікатів ключа у файлі даних. ‒ Створення вторинного індексу із значеннями для всіх унікальних значень ключа. Але при цьому покажчики блоків вказують не на файл даних, а на сегмент, який містить покажчики на відповідні записи файлу даних. Вторинні індекси підвищують продуктивність обробки запитів, в яких для пошуку використовуються атрибути, відмінні від атрибуту первинного ключа. Проте таке підвищення продуктивності запитів вимагає додаткової обробки, пов'язаної з супроводом індексів при оновленні індексу в базі даних. Це завдання вирішується на етапі фізичного проектування бази даних. Багаторівневі індекси При зростанні розміру індексного файлу і розширенні його вмісту на велику кількість сторінок час пошуку потрібного індексу також значно зростає. Наприклад, при використанні методу бінарного пошуку потрібно виконати приблизно log2(p) операцій доступу до індексу з p сторінками. Звернувшись до багаторівневого індексу, можна спробувати вирішити цю проблему шляхом скорочення діапазону пошуку. Дана операція виконується над індексом аналогічно тому, як це робиться в разі файлів іншого типe, за допомогою розщеплювання індексу надекілька субіндексів меншого розміру і створення індексу для цих субіндексів. Кожен індексний запис містить значення ключа доступу і адресу сторінки. Значення ключа доступу, що зберігається, є найбільшим на сторінці, що адресується. Пошук запису по заданому значенню атрибуту staffNo починається з індексу другого рівня, якому відшукується перша сторінка, в якої значення останнього ключа доступу більше або рівне шуканому. Знайдений запис містить адресу сторінки індексу першого рівня, в якій слід продовжити пошук. Метод ISAM компанії IBM побудований на використанні дворівневої індексної структури. Операції вставки в ньому обробляються за допомогою сторінок переповнення. Як правило, можна використовувати n-рівневу індексну структуру довільної глибини, але на практиці зазвичай обмежуються не більше ніж трьома рівнями, оскільки більша кількість рівнів потрібна лише для виключно великих файлів. Вдосконалені деревовидні індекси У багатьох СКБД для зберігання даних або індексів використовується структура даних, яка називається деревом. Дерево складається з ієрархії вузлів (node), в якій кожен вузол, за винятком кореня (root), має батьківський (parent) вузол, а також один, декілька або жодного дочірнього (child) вузла. Корінь не має батьківського вузла. Вузол, який не має дочірніх вузлів, називається лтстом (leaf). Глибиною дерева називається максимальна кількість рівнів між коренем і листом. Глибина дерева може бути різною для різних шляхів доступу до листів. Якщо ж вона однакова для всіх листів, то дерево називається збалансованим, або В-деревом. Мірою (degree) (або порядком) дерева називається максимально допустима кількість дочірніх вузлів для кожного батьківського вузла. Великі міри зазвичай використовуються для створення ширших і менш глибших дерев. Оскільки час доступу в деревовидній структурі залежить від глибини, а не від ширини, зазвичай прийнято використовувати більш "розгалужені" і менш глибокі дерева. Бінарним деревом (binary tree) називається дерево порядку 2, в якому кожен вузол має не більше двох дочірніх вузлів. Вдосконалені збалансовані деревовидні індекси B+-Tree визначаються за наступними правилами. ‒ Якщо корінь не є листом, то він повинен мати, принаймні, два дочірні вузли. ‒ У дереві порядку n кожен вузол (за винятком кореня і листів) повинен мати від n/2 до n покажчиків і дочірніх вузлів. Якщо число n/2 не є цілим, то воно округляється до найближчого більшого цілого. ‒ У дереві порядку n кількість значень ключа в листі повинна знаходитися в межах від (n-1)/2 до (n-1). Якщо число (n-1)/2 не є цілим, то воно округляється до найближчого більшого цілого. ‒ Кількість значень ключа в нелистовому вузлі на одиницю менше кількості покажчиків. ‒ Дерево завжди має бути збалансованим, тобто всі шляхи від кореня до кожного листа повинні мати однакову глибину. ‒ Листи дерева зв'язані в порядку зростання значень ключа. На практиці кожен вузол в дереві є сторінкою, тому в ньому може зберігатися більше трьох покажчиків і двох значень ключа. Якщо передбачити, що сторінка має розмір 4096 байтів, кожен покажчик – довжину 4 байти, розмір поля staffNo також дорівнює 4 байтам і кожна сторінка містить 4-байтовий покажчик на наступний вузол того ж рівня, то на одній сторінці може зберігатися (4096-4) / (4 + 4) =511 індексних записів. Таким чином, порядок даного В+-дерева дорівнює 512. Корінь дерева може містити до 511 записів і мати до 512 дочірніх вузлів. Кожен дочірній вузол також може містити до 511 записів, що в цілому дає структуру з 261632 записів. У свою чергу, кожен дочірній вузол також може мати до 512 дочірніх вузлів, що в сумі дає 262144 дочірніх вузли на рівні 2 цього дерева. Кожен із цих вузлів також може містити до 511 записів, що дає дворівневу структуру з 133955584 записів. Теоретичний максимум для кількості індексних записів в дворівневому дереві визначається таким чином.
Таким чином, описана вище структура дозволяє здійснювати довільний доступ до окремого запису файлу staff, що містить до 134217727 записів, з виконанням лише чотирьох операцій доступу до диска (насправді корінь зазвичай знаходиться в оперативній пам'яті, тому кількість операцій доступу на одиницю менша). Але на практиці кількість записів на одній сторінці зазвичай менше, оскільки не всі сторінки бувають повністю заповненими. У B+-дереві для доступу до будь-якого запису даних потрібний приблизно однаковий час, оскільки при пошуку є видимою однакова кількість вузлів, завдяки тому, що всі листи дерева мають однакову глибину. Оскільки цей індекс є щільним, кожен запис адресується індексом, тому сортувати файл даних не потрібно, тобто він може зберігатися у вигляді невпорядкованого файлу. Проте подібну збалансованість дерева досить складно підтримувати в ході постійного оновлення вмісту дерева. 31. Розподілені бази даних. Концепція розподілених баз даних. Розподілені транзакції. Реплікація даних. Розподілена оптимізація запитів. Розподілена база даних (РБД) — це множина логічно взаємозалежних баз даних, розподілених у комп'ютерній мережі. Розподілена система керування базами даних (РСКБД) — це програмне забез печення, яке керує РБД і надає такі механізми доступу до них, що їх застосування дає користувачу можливість працювати з РБД як з однією цілісною базою даних. Розподілена система баз даних (РСБД) — це РБД разом із РСКБД. Не слід плутати РСБД з централізованою базою даних, що використовується в мережі (рис. 10.1). У цьому випадку база даних розташована на одному з ком п'ютерів, а всі інші мають доступ до неї через комунікаційну мережу. Не є розпо діленою також база даних, що працює в середовищі багатопроцесорних комп'ю терів. У цьому випадку ми маємо справу з паралельною БД.
Архітектура розподіленої СКБД наведена нарис, 10.2. Кожний з вузлів мере жі містить свою базу даних, однак вони розглядаються як логічно єдина база, а не як сукупність розкиданих у мережі файлів. Усі дані є логічно взаємозалежними.
Залежно від типу програмного забезпечення розрізняють два типи РСКБД: ♦ Однорідні; ♦ Неоднорідні. Однорідні РСКБД В однорідних РСКБД передбачається, як мінімум, що на всіх вузлах використову ються однотипні СКБД (наприклад, реляційяі), які мають схожі функціональні можливості. Як максимум, припускається, що на всіх вузлах використовуються однакові технічні засоби, тобто однакові типи комп'ютерів і програмного забезпе чення Це стосується операційних систем, програмного забезпечення СКБД та моделей даних, що підтримуються. Неоднорідні РСКБД У неоднорідних РСКБД вузли базуються на різних програмно-технічних платфор мах, які можуть містити різні типи СКБД. Окрім того, такі СКБД можуть підтри мувати різні моделі даних. У цьому випадку ускладнюється вирішення проблеми їхньої взаємодії. Прозорість доступу до даних Однією з важливих проблем РСКБД є досягнення логічної незалежності даних від місця зберігання, тобто прозорість доступу до даних. Це означає, що користу вач повинен мати можливість сприймати всі необхідні йому дані як єдине ціле, не зважаючи на те, в який спосіб вони розподілені у мережі.
Розглянемо такий приклад. Нехай база даних містить відношення СЛУЖБОВЕЦЬ, ПРОЕКТ, РОБОТА з інформацією стосовно службовців, проектів, що розроблюються, та участі службовців у проектах компанії, яка має філії в Римі, Лондоні, Парижі й То кіо. Бази даних цих філій містять дані згідно зі схемою, зображеною на рис. 10.3. Будь-який користувач у кожному з вузлів цієї мережі має сприймати логічну Структуру бази даних так, ніби всі три відношення містяться в одній локальній базі даних. Розглянемо приклад. SELECT ПРОЕКТ.Назва, СЛУЖБОВЕЦЬ.шзщ FROH СЛУЖБОВЕЦЬ. ПРОЕКТ. РОБОТА WHERE СЛУЖБОВЕЦЬ.#Е = РОБОТА.#Е А® РОБОТА.#Р - ПРОЕКТ.#Р AND (ПРОЕКТ.Mlcue = 'Париж* OR ПРОЕКТ_Місце ='Токіо1) AND СЛУЖБОВЕЦЬ.Зарплата > 40000 AND СЛУЖБОВЕЦЬ.Зарплата < 6000Q Цей запит, згідно з яким вибираються назви проектів, що виконуються в Парижі чи Токіо, й імена службовців, які беруть у них участь, із зарплатою в діапазоні від 40 000 до 60 ÖÖÖ, буде виконано навіть тоді, коли його формулює користувач, що перебуває » Лондоні. З погляду користувача існує єдина розподілена СКБД і єдина база даних, у якій с всі дані, що визначені у віртуальній таблиці користувача 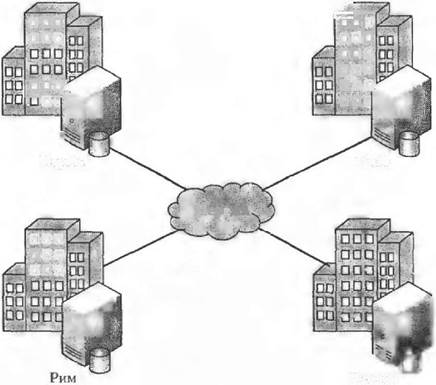 Париж Мережа □ OD □па UDQ Лондон |