Ерл. 1 Пул вопросов Иерархические базы данных
 Скачать 0.66 Mb. Скачать 0.66 Mb.
|

|
1 Пул вопросов Иерархические базы данных База данных – это упорядоченное хранение какой-либо информации. Модель данных – это совокупность структур данных и операций их обработки. С ее помощью могут быть представлены информационные объекты и их взаимосвязи. Выделяют три основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархические базы данных — самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок-потомок». Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных — невозможность реализовать отношения «много-ко-многим», а также ситуации, когда запись имеет несколько предков. Графически такую структуру можно изобразить в виде дерева, состоящего из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и так далее. Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможно, чтобы объект-предок не имел потомков или имел их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами. 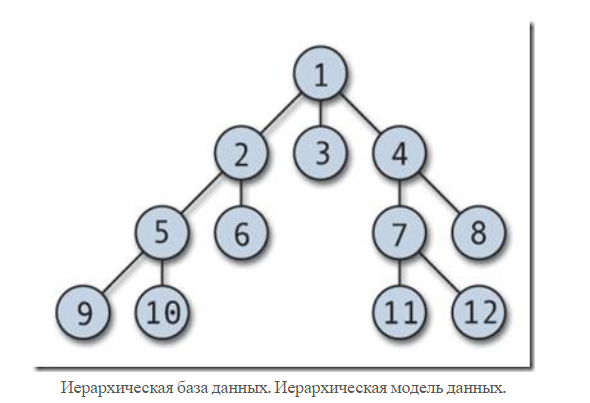 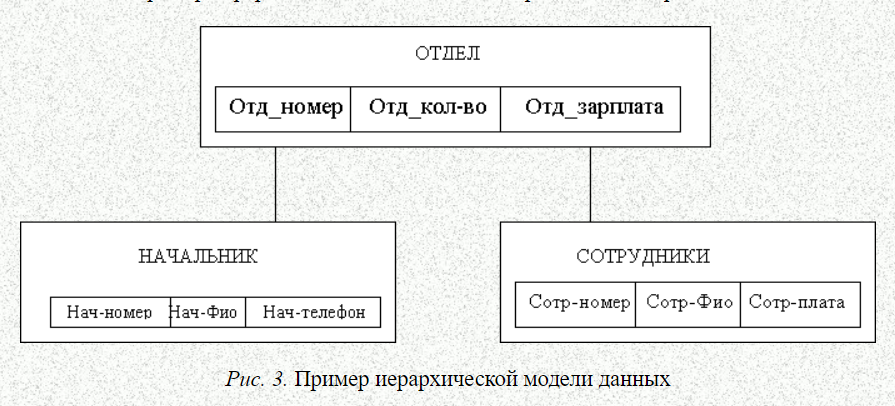 НЕДОСТАТКИ: –требуется создание сложной надстройки для многоключевого доступа к файлам; –возникает существенная избыточность данных; -требуется выполнение массовой выборки и вычислений для получения суммарной информации (например об отделах). Сетевые базы данных Сетевые базы данных, являются своеобразной модификацией иерархических баз данных. Отличаются от иерархических лишь тем, что у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него 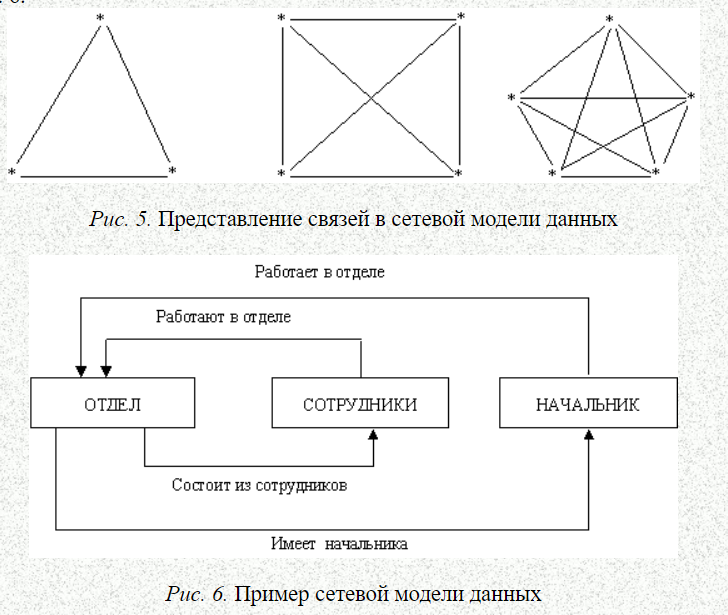 Сетевая модель данных - это логическая модель данных, представляющая их сетевыми структурами типов записей и связанные отношениями мощности один-к-одному или один-ко-многим. Сетевые базы данных имеют достаточно простую структуру. Структура состоит из четырех компонентов, то есть в сетевой модели используют четыре типа структур данных. Два из которых являются главными и два, если можно так сказать, не главными. Главные типы структур сетевых данных – это запись и набор [6]. Вспомогательные типы структур сетевой модели данных, которые используются для построения главных структур – это элемент данных и агрегат данных. Элемент данных – это наименьшая информационная именованная единица данных, доступная пользователю, если провести аналогию с файловой системой, то это поле в файловой системе. Агрегат данных – это именованная совокупность данных внутри одной записи. Имя агрегата используется для его идентификации в схеме структуры данного более высокого уровня. Агрегат данных может быть простым, если состоит только из элементов данных, и составным, если включает в свой состав другие агрегаты.  На данном рисунке видно, что дата – это агрегат данных структуры сетевой модели, а день, месяц и год – это элемент данных сетевой БД. Запись - это конечный уровень обобщения данных. Иными словами, запись - это агрегат, который не входит в состав никакого другого агрегата и может иметь сложную иерархическую структуру, поскольку допускается многократное применение агрегации. Имя записи используется для идентификации типа записи в схемах типов структур более высокого уровня. Тип записей – это совокупность логически связанных экземпляров записей. Тип записей представляет некоторый класс реального мира. Набор - именованная двухуровневая иерархическая структура, которая содержит запись владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к одному» между двумя типами записей. Операции с сетевыми данными можно разделить на две группы: навигационные операции с данными и операции модификации данных. Навигационные операции с данными Навигационные операции сетевых баз данных осуществляют переход по связям, определенных в схеме баз данных, в результате таких переходов определяется запись, которую называют текущей. Найти конкретную запись в наборе однотипных записей и сделать ее текущей; Перейти от записи-владельца к записи-члену в некотором наборе; Перейти к следующей записи в некоторой связи; Перейти от записи-члена к владельцу по некоторой связи. Операции модификации данных Операций модификации сетевых баз данных осуществляют добавление новых записей данных, добавление новых наборов данных, удаление записей данных и наборов записей, модификация агрегатов и элементов данных. извлечь текущую запись в буфер прикладной программы для обработки; заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения; запомнить запись из буфера в БД; создать новую запись; уничтожить запись; включить текущую запись в текущий экземпляр набора; исключить текущую запись из текущего экземпляра набора. Что будет нарушать ссылочную целостность базы данных? Существует четыре типа изменений в базах данных, которые могут изменить ссылочную целостность отношений «предок – потомок»: – Добавление новой строки потомка. Когда происходит добавление новой строки в таблицу-потомок SLUZHASCHIE, значение ее внешнего ключа «ID_OFC» должно быть равно одному из значений первичного ключа «ID_OFC» в таблице-предке OFFISY. Если значение внешнего ключа не равно ни одному из значений первичного ключа, то добавление такой строки разрушит базу данных, поскольку появится потомок без предка («сирота»); – Обновление внешнего ключа в строке-потомке. Это та же проблема, что и в предыдущей ситуации, но выраженная в иной форме. Если внешний ключ «ID_OFC» обновляется инструкцией UPDATE, то его новое значение должно быть равно одному из значений первичного ключа «ID_OFC» в таблице-предке OFFISY. В противном случае обновленная строка окажется сиротой; – Удаление строки-предка. Если из таблицы-предка OFFISY будет удалена строка, у которой есть хотя бы один потомок (в таблице SLUZHASCHIE), то строки-потомки останутся сиротами. Значения внешних ключей «ID_OFC» в этих строках не будут равны ни одному из значений первичного ключа таблицы-предка OFFISY; – Обновление внешнего ключа в строке-предке. Если в таблице-предке OFFISY будет обновлено значение внешнего ключа для отдела, у которого есть хотя бы один потомок (в таблице SLUZHASCHIE), то строки-потомки останутся сиротами. Для решения перечисленных проблем, возникающих при вставке, обновлении и удалении строк связанных таблиц, предусмотрены правила ссылочной целостности (referential integrity, RI). Правила ссылочной целостности – это логические конструкции, которые выражают бизнес-правила использования данных и представляют собой правила вставки, замены и удаления. При генерации схемы базы данных эти логические конструкции будут реализованы в виде правил декларативной ссылочной целостности, которые должны быть предписаны для каждой связи, и триггеры, обеспечивающие ссылочную целостность. Триггеры представляют собой программы, выполняемые всякий раз при выполнении команд вставки, замены или удаления (INSERT, UPDATE или DELETE). Правило RESTRICT: – запрещает удаление строки из таблицы-предка, если строка имеет потомков. Инструкция DELETE, пытающаяся удалить такую строку, отбрасывается, и выдается сообщение об ошибке; – запрещает обновление первичного ключа в строке таблицы-предка, если у строки есть потомки. Инструкция UPDATE, пытающаяся изменить значение первичного ключа в строке-предке, отбрасывается, и выдается сообщение об ошибке; Правило CASCADE: – определяет, что при удалении строки-предка все строки-потомки также автоматически удаляются из таблицы-потомка; – определяет, что при изменении значения первичного ключа в строке-предке соответствующее значение внешнего ключа в таблице-потомке также автоматически изменяется во всех строках-потомках таким образом, чтобы соответствовать новому значению первичного ключа. Правило SET NULL: – определяет, что при удалении строки-предка внешним ключам во всех ее строках-потомках автоматически присваивается значение NULL; – определяет, что при обновлении значения первичного ключа в строке-предке внешним ключам во всех ее строках-потомках автоматически присваивается значение NULL. Правило SET DEFAULT: – определяет, что при удалении строки-предка внешним ключам во всех ее строках-потомках автоматически присваивается определенное значение, по умолчанию установленное для данного столбца; – определяет, что при обновлении значения первичного ключа в строке-предке внешним ключам во всех ее строках-потомках автоматически присваивается определенное значение, по умолчанию установленное для данного столбца. Правило NONE: – определяет, что при удалении строки-предка значения внешних ключей во всех ее строках-потомках не меняются; – определяет, что при обновлении значения первичного ключа в строке-предке значения внешних ключей во всех ее строках-потомках не меняются. Обычно правило NONE используется в «плоских» таблицах, так как в настольных или файл-серверных системах функциональность, обеспечивающая правила ссылочной целостности, реализуется в клиентском приложении Таблица заказов имеет поле с именем customer_id. Данный клиент может в течение времени сделать любое число заказов, каждый из которых вводится как строка в таблицу заказов. Каждое значение customer_id в таблице заказов отвечает одному значению customer_id в таблице клиентов. Какой тип связи описывает эту ситуацию? Существует три разновидности связи между таблицами базы данных: "один-ко-многим"; "один-к-одному"; "многие-ко-многим". Отношение "один-ко-многим" имеет место, когда одной записи родительской таблицы может соответствовать несколько записей дочерней. Отношение "один-к-одному" имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней. Использование связи "один-к-одному" приводит к тому, что для чтения связанной информации в нескольких таблицах приходится производить несколько операций чтения вместо одной, когда данные хранятся в одной таблице. Отношение "многие-ко-многим" имеет место в следующих случаях: одной записи в родительской таблице соответствует более одной записи в дочерней таблице ; одной записи в дочерней таблице соответствует более одной записи в родительской таблице. Ответ на вопрос: Один ко многим (Лида сказала) Какой тип целостности данных гарантирует, чтобы данные, вводимые в некоторый столбец, принадлежали заданному набору или диапазону значений? Термин целостность относится к правильности и полноте информации, содержащейся в базе данных. При изменении содержимого базы данных с помощью инструкций INSERT, DELETE или UPDATE может произойти нарушение целостности содержащихся в ней данных: – в базу могут быть внесены неправильные данные, например, заказ, в котором указан не существующий товар; – в результате изменения имеющихся данных им могут быть присвоены некорректные значения, например, назначение служащего в несуществующий офис; – изменения, внесенные в базу данных, могут быть утеряны из-за системной ошибки или сбоя в электропитании; – изменения, внесенные в базу данных, могут быть внесены лишь частично, например, заказ может быть добавлен без учета изменения количества товара, имеющегося на складе. Для сохранения непротиворечивости и правильности хранимой информации в реляционных СУБД устанавливается одно или несколько условий целостности данных. Эти условия определяют, какие значения могут быть записаны в базу данных в результате добавления или обновления данных. Ограничения целостности баз данных — это специальные средства в базах данных, главное назначение которых — не допустить попадания в базу ошибочных данных. Все ограничения целостности можно разделить на категории: Ссылочная целостность Условие на значение (Доменная целостность) Целостность таблицы(Целостность сущностей) Обязательное наличие данных. Обязательное наличие данных. Некоторые столбцы в базе данных должны содержать значения в каждой строке; строки в таких столбцах не могут включать псевдозначения NULL или не содержать никакого значения. Целостность таблицы. Первичный ключ таблицы должен в каждой строке иметь уникальное значение, отличное от значений во всех остальных строках. Целостность сущностей – это первое ограничение для обеспечения целостности базы данных. При этом проверяют таблицу, с которой администратор хочет работать и смотрит на имена строк. Если строки в одной таблице имеют одинаковые имена, то это может создать избыточную информацию, которая сбивает с толку во всей базе данных. Главная задача целостности сущностей — сделать так, чтобы данные об одном объекте (сущности) не попали в базу данных дважды, так как при несоблюдении данного ограничения в базе данных может храниться противоречивая информация об одном объекте. Поддержание целостности сущностей осуществляется системой управления базой данных (СУБД). Условие на значение (целостность домена). У каждого столбца в базе данных есть свой домен, т. е. набор значений, которые допускается хранить в данном столбце. Это проверяет тип данных которые были последовательно добавлены в раздел таблицы или обеспечивает новые данные соответствующие этому типу данных. Например, если в таблице указана только дата и кто-то пытается ввести слово, процесс целостности домена будет предупреждать администратора об ошибке согласованности. Это происходит потому, что это предназначено только для обработки дат, так что слово может испортить регулярную обработку и может привести к ошибкам в будущем. Третье ограничение целостности базы данных – ссылочная целостность. В реляционной базе данных каждая строка таблицы-потомка с помощью внешнего ключа связана со строкой таблицы-предка, содержащей первичный ключ, значение которого равно значению внешнего ключа. Если это условие не соблюдается, то речь идет о нарушении ссылочной целостности. Современные СУБД поддерживают ссылочную целостность автоматически. Таблицы в базе данных редко бывают одни — другие таблицы часто ссылаются на них, и они ссылаются на другие таблицы. Если администратор ввёл команды для одной таблицы ссылаясь на другую, но во второй таблице данные указаны неправильно или не существуют, то это приводит к ошибкам обработки. Ссылочная целостность проверяет все ссылки действительны они или нет. Ссылочная целостность обеспечивается системой первичных и внешних ключей. Этими средствами можно гарантировать, что у нас не будет ссылок на несуществующие объекты таблицы. Ответ на вопрос: доменный тип целостности гарантирует, чтобы данные, вводимые в некоторый столбец, принадлежали заданному набору или диапазону значений. Какой тип целостности данных обеспечивается уникальным индексом и недопустимостью NULL-значений для поля первичного ключа? Целостность таблицы(или по другому сущностей) Это ограничение целостности касается первичных ключей базовых таблиц. По определению, первичный ключ – минимальный идентификатор (одно или несколько полей), который используется для уникальной идентификации записей в таблице. Таким образом, никакое подмножество первичного ключа не может быть достаточным для уникальной идентификации записей. Целостность сущностей определяет, что в базовой таблице ни одно поле первичного ключа не может содержать отсутствующих значений, обозначенных NULL. Если допустить присутствие определителя NULL в любой части первичного ключа, это равносильно утверждению, что не все его поля необходимы для уникальной идентификации записей, и противоречит определению первичного ключа. Какое из утверждений справедливо относительно первичного и внешнего ключей? (уникально) идентифицирующих запись. Первичный ключ должен быть минимально достаточным: в нем не должно быть полей, удаление которых из первичного ключа не отразится на его уникальности. Пример из учебника: 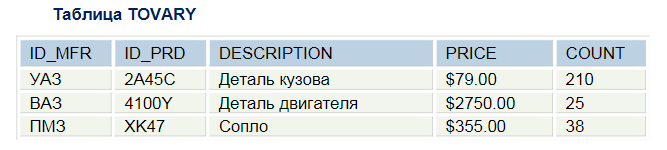 Таблица TOVARY является примером таблицы, в которой первичный ключ представляет собой комбинацию столбцов. Такой первичный ключ называется составным. Столбец ID_MFR содержит идентификаторы производителей всех товаров, перечисленных в таблице, а столбец ID_PRD содержит номера, присвоенные товарам производителями. Может показаться, что столбец ID_PRD мог бы и один исполнять роль первичного ключа, однако ничто не мешает двум разным производителям присвоить своим изделиям одинаковые номера. Таким образом, в качестве первичного ключа таблицы TOVARY необходимо использовать комбинацию столбцов ID_MFR и ID_PRD. Для каждого из товаров, содержащихся в таблице, комбинация значений в этих столбцах будет уникальной. Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. |