Ерл. 1 Пул вопросов Иерархические базы данных
 Скачать 0.66 Mb. Скачать 0.66 Mb.
|

|
Ответ: Индекс – это средство, обеспечивающее быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов. В индексе хранятся значения данных и указатели на строки, где эти данные встречаются. Данные в индексе располагаются в убывающем или возрастающем порядке, чтобы СУБД могла быстро найти требуемое значение. Структура хранения на основе индексирования предполагает использовать двух хранимых файлов. 1. Файл таблицы с данными (например, поставщиков деталей), его условно называют последовательный файл. 2. Файл с индексами (например, данные о городах проживания поставщиков). Как называется количество данных, передаваемых из вторичной памяти (памяти накопителя) в главную (оперативную) память за одно обращение? Ответ: Запоминающие устройства компьютера разделяют, как минимум, на два уровня: основную (главную, оперативную, физическую) и вторичную (внешнюю) память. Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Процессор извлекает команду из основной памяти, декодирует и выполняет ее. Для выполнения команды могут потребоваться обращения еще к нескольким ячейкам основной памяти. Обычно основная память изготавливается с применением полупроводниковых технологий и теряет свое содержимое при отключении питания. Вторичную память (это главным образом диски) также можно рассматривать как одномерное линейное адресное пространство, состоящее из последовательности байтов. В отличие от оперативной памяти, она является энергонезависимой, имеет существенно большую емкость и используется в качестве расширения основной памяти. Как называется процесс как можно более близкого физического размещения на диске логически связанных между собой и часто используемых данных? Ответ: Кластеризацией называется процесс как можно более близкого физического размещения на диске логически связанных между собой и часто используемых данных. Физическая кластеризация данных чрезвычайно важное условие высокой производительности. Например, если при работе с базой данных при вызове некоторой записи часто требуется также вызывать некоторую другую запись, то кластеризация приведет к сокращению времени такой выборки. Это достигается за счет того, что в результате кластеризации обе записи будут находиться либо на одной странице, и тогда потребуется одна физическая операция ввода/вывода; либо на двух физически близко расположенных страницах, в результате чего время поиска при чтении второй записи будет очень малым (или нулевым, если страницы находятся на одном цилиндре), поскольку головка чтения/записи уже находится в непосредственной близости от нужного положения. Различают внутрифайловую и межфайловую кластеризацию. Разницу между ними поясним на примере. Пусть в базе данных содержится информация о поставщиках и товарах, поставляемых этими поставщиками. Информация о поставщиках и товарах хранится в двух различных файлах. Если системе часто требуется осуществлять доступ к данным о поставщиках согласно их порядковым номерам, то все записи о поставщиках следует физически размещать по порядку их номеров. Это пример внутрифайловой кластеризации, осуществляемой в пределах одного хранимого файла. Если же часто требуется одновременно получать информацию о поставщике и его товарах, то записи о поставщике и его товарах должны располагаться рядом. Это пример межфайловой кластеризации, когда охвачено сразу несколько файлов. Кластеризацию СУБД может осуществлять, размещая логически связанные записи на одной странице или на смежных страницах. В совершенных СУБД часто предусмотрено задание нескольких различных типов кластеризации данных из разных файлов. Какую функцию при работе СУБД выполняет диспетчер дисков? Ответ: Для хранения данных могут быть использованы различные структуры, обладающие разной производительностью. Идеального способа хранения данных не существует. Основные этапы процесса доступа к базе данных следующие: СУБД определяет искомую запись в БД, для чего в оперативную память помещается набор записей, в котором ищется запрашиваемая, а для извлечения записи запрашивается так называемый Диспетчер файлов; Диспетчер файлов определяет страницу, на которой находится искомая запись, а затем для извлечения этой страницы запрашивается диспетчер дисков; Диспетчер дисков определяет физическое расположение страницы на устройстве хранения информации и посылает запрос на ввод-вывод данных. Таким образом, СУБД рассматривает базу данных как множество записей, просматриваемых при помощи Диспетчера файлов. Диспетчер файлов рассматривает базу данных как набор страниц, просматриваемых с помощью диспетчера дисков, который непосредственно работает с устройствами хранения информации. Диспетчер дисков является частью операционной системы, с помощью которого выполняются все дисковые операции ввода-вывода. Для выполнения этих операций, диспетчеру необходимо обладать информацией о значениях физических адресов на диске, где располагаются данные. Диспетчеру файлов такая информация не нужна, ему достаточно рассматривать диск как набор страниц строго фиксированного размера с уникальным идентификационным номером набора страниц. Каждая страница, обладает уникальным внутри данного набора идентификационным номером страницы, причем наборы не имеют общих страниц. Соответствие физических адресов на диске и номеров страниц достигается с помощью диспетчера дисков. Преимуществом такой организации хранения данных является изоляция программного кода внутри диспетчера дисков, зависящего от конкретного устройства диска, за счет чего многие компоненты системы могут быть аппаратно независимыми. Что означает обеспечение целостности данных? Ответ: Термин целостность относится к правильности и полноте информации, содержащейся в базе данных. При изменении содержимого базы данных с помощью инструкций INSERT, DELETE или UPDATE может произойти нарушение целостности содержащихся в ней данных: – в базу могут быть внесены неправильные данные, например, заказ, в котором указан не существующий товар; – в результате изменения имеющихся данных им могут быть присвоены некорректные значения, например, назначение служащего в несуществующий офис; – изменения, внесенные в базу данных, могут быть утеряны из-за системной ошибки или сбоя в электропитании; – изменения, внесенные в базу данных, могут быть внесены лишь частично, например, заказ может быть добавлен без учета изменения количества товара, имеющегося на складе. Для сохранения непротиворечивости и правильности хранимой информации в реляционных СУБД устанавливается одно или несколько условий целостности данных. Эти условия определяют, какие значения могут быть записаны в базу данных в результате добавления или обновления данных. Как правило, в реляционной базе данных можно использовать следующие условия целостности данных: – Обязательное наличие данных. Некоторые столбцы в базе данных должны содержать значения в каждой строке; строки в таких столбцах не могут включать псевдозначения NULL или не содержать никакого значения. Например, в учебной базе данных для каждого заказа должен обязательно существовать клиент, сделавший этот заказ. Поэтому столбец ID_CLN в таблице ZAKAZY является обязательным. Для реализации этого условия необходимо указать СУБД, что запись значения NULL в такие столбцы недопустима; – Условие на значение. У каждого столбца в базе данных есть свой домен, т. е. набор значений, которые допускается хранить в данном столбце. В учебной базе данных заказы нумеруются, начиная с числа 100001, поэтому доменом столбца ID_ORD являются положительные целые числа, больше 100000. Аналогично, идентификаторы служащих в столбце ID_SLZH должны находиться в диапазоне от 101 до 999. Для реализации этого условия необходимо указать СУБД, что запись значений, не входящих в заданный диапазон, недопустима; – Целостность таблицы. Первичный ключ таблицы должен в каждой строке иметь уникальное значение, отличное от значений во всех остальных строках. Например, каждая строка таблицы TOVARY имеет уникальную комбинацию значений в столбцах ID_MFR и ID_PRD, которая однозначно идентифицирует товар, представляемый данной строкой. Повторяющиеся значения в этих строках недопустимы, поскольку тогда база данных не сможет отличать один товар от другого. Современные СУБД автоматически обеспечивают это условие для столбцов, объявленных первичными ключами; – Ссылочная целостность. В реляционной базе данных каждая строка таблицы-потомка с помощью внешнего ключа связана со строкой таблицы-предка, содержащей первичный ключ, значение которого равно значению внешнего ключа. Если это условие не соблюдается, то речь идет о нарушении ссылочной целостности. Современные СУБД поддерживают ссылочную целостность автоматически. Какое из действий занимает в среднем наибольшее время при операциях чтения/записи на диск? Возможный ответ: Запись будет разной, так как данные могут быть разными, индексы увеличивают время записи. Чтение, если запись индексированная, будет быстрее. Ответ: При выполнении обмена с диском аппаратура выполняет три основных действия: подвод головок к нужному цилиндру обозначим время выполнения этого действия как Tпг, поиск на дорожке нужного блока время выполнения — Tпб и собственно обмен с этим блоком время выполнения — Tоб. Тогда, как правило, Tпг Tпб Tоб , потому что подвод головок — это механическое действие, причем в среднем нужно переместить головки на расстояние, равное половине радиуса поверхности, а скорость передвижения головок не может быть слишком большой по физическим соображениям. Поиск блока на дорожке требует прокручивания пакета магнитных дисков в среднем на половину длины внешней окружности; скорость вращения диска может быть существенно больше скорости движения головок, но она тоже ограничена законами физики. Для выполнения же собственно чтения или записи нужно прокрутить пакет дисков всего лишь на угловое расстояние, соответствующее размеру блока. Таким образом, из всех этих действий в среднем наибольшее время занимает первое, и поэтому существенный выигрыш в суммарном времени обмена при считывании или записи только части блока получить практически невозможно. С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной и внешней памятью с помощью программно-аппаратных средств низкого уровня машинных команд или вызовов соответствующих программ операционной системы. Такой режим работы не позволял или очень затруднял поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти. Что является синонимом термина "атрибут" в реляционных системах? Ответ: Поля – это компоненты, представляющие структуру таблицы. У вас не может быть таблицы без полей. Например, вы можете создать пустую таблицу, в которой будут определены поля, но в ней не будет строк (записей). В базах данных поля также используются для поддержки отношений между таблицами. Это выполняется путем установки соответствий между полями двух и более таблиц. Например, если в базе данных хранится таблица с именем toy_store, а также таблица staff, которая предназначена для ведения учета сотрудников в каждом магазине, то можно создать поле, общее для обеих таблиц, которое могло бы быть заполнено, например, значениями идентификаторов магазинов (store ID). Значение поля store ID для конкретного магазина игрушек будет одинаковым в обеих таблицах. Что такое Б-дерево? Для ответа вполне достаточно: Понятие, структура, чем отличается от бинарного дерева. Ответ: Структура Б-дерева удобнее для хранения, чем у бин. Дерева. Деревом называют структуру данных, которая имеет древовидный вид, то есть характеризуется наличием набора связанных узлов. Бинарное дерево — это конечное множество элементов, связанных с двумя разными бинарными деревьями — правым и левым поддеревьями. В бинарном дереве поиска каждый узел содержит лишь одно значение (ключ) и не более 2-х потомков. Но существует особый вид древа поиска, называемый B-дерево (Би-дерево). Здесь узел содержит больше одного значения и больше 2-х потомков. Также его называют сбалансированным по высоте деревом поиска порядка m (Height Balanced m-way Search Tree). B-дерево представляет собой сбалансированное дерево поиска, где каждый узел содержит много ключей и имеет больше 2-х потомков. Возможные операции: 1. Поиск. 2. Вставка (вставляем новый элемент). 3. Удаление. 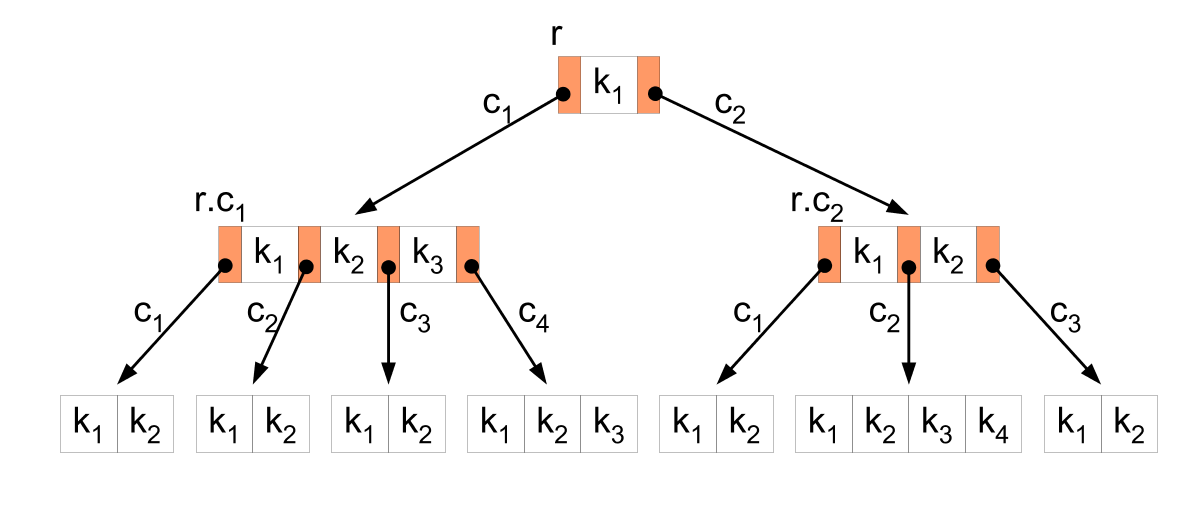 B-дерево (читается как Би-дерево) — это особый тип сбалансированного дерева поиска, в котором каждый узел может содержать более одного ключа и иметь более двух дочерних элементов. Из-за этого свойства B-дерево называют сильноветвящимся. Вторичные запоминающие устройства (жесткие диски, SSD) медленно работают с большим объемом данных. Людям захотелось сократить время доступа к физическим носителям информации, поэтому возникла потребность в таких структурах данных, которые способны это сделать. Двоичное дерево поиска, АВЛ-дерево, красно-черное дерево и т. д. могут хранить только один ключ в одном узле. Если нужно хранить больше, высота деревьев резко начинает расти, из-за этого время доступа сильно увеличивается. С B-деревом все не так. Оно позволяет хранить много ключей в одном узле и при этом может ссылаться на несколько дочерних узлов. Это значительно уменьшает высоту дерева и, соответственно, обеспечивает более быстрый доступ к диску. Свойства: Ключи в каждом узле x упорядочены по неубыванию. В каждом узле есть логическое значение x.leaf. Оно истинно, если x — лист. Каждый узел, кроме корня, содержит не менее t-1 ключей, а каждый внутренний узел имеет как минимум t дочерних узлов, где t — минимальная степень B-дерева. Все листья находятся на одном уровне, т. е. обладают одинаковой глубиной, равной высоте дерева. Корень имеет не менее 2 дочерних элементов и содержит не менее 1 ключа. Что является синонимом термина "кортеж" в реляционных системах? Ответ: Кортеж — это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж - это набор именованных значений заданного типа. Что является синонимом термина "отношение" в реляционных системах? Ответ: Отношение R представляет собой двумерную таблицу, содержащую некоторые данные. Математически любое подмножество n-арных кортежей декартова произведения, является отношением n множеств. Отношением R, определенным на множествах D1, D2, …, Dn называется подмножество декартова произведения D1 x D2 x…xDn . При этом: – множества D1, D2, …, Dn называются доменами отношения; – элементы декартова произведения {d1, d2, ..., dn} называются кортежами; – число n определяет степень отношения; – количество кортежей называется мощностью отношения Атрибут - это поименованный столбец отношения. Домен - это набор допустимых значений для одного или нескольких атрибутов. Кортеж - это строка отношения. Кардинальность - это количество кортежей, которое содержит отношение. Первичный ключ - это уникальный идентификатор для таблицы. Соответствие между формальными терминами реляционной модели данных и неформальными: отношение (формальный термин) - таблица (неформальный термин); атрибут - столбец; кортеж - строка или запись; степень - количество столбцов; кардинальное число - количество строк; первичный ключ - уникальный идентификатор; домен - общая совокупность допустимых значений. Что справедливо для многоуровневого индекса? Ответ: Индекс – это средство, обеспечивающее быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов. В индексе хранятся значения данных и указатели на строки, где эти данные встречаются. Данные в индексе располагаются в убывающем или возрастающем порядке, чтобы СУБД могла быстро найти требуемое значение. Многоуровневый индексы представляет собой индексы для уже существующих индексов. При возрастании размера индексного файла и расширении его содержимого на большое количество страниц время поиска нужного индекса также значительно возрастает. Обратившись к многоуровневому индексу, можно решить эту проблему путем сокращения диапазона поиска. Данная операция выполняется над индексом аналогично тому, как это делается в случае файлов другого типа, т.е. посредством расщепления индекса на несколько субиндексов меньшего размера и создания индекса для этих субиндексов. На каждой странице файла данных могут храниться две записи. Что является аналогом "инвертированного списка"? |