Алгоритм k средних. 1 Свойства и структура алгоритма
 Скачать 1.14 Mb. Скачать 1.14 Mb.
|

|
Алгоритм k средних (k-means) 1 Свойства и структура алгоритма1.1 Общее описание алгоритмаАлгоритм k средних (англ. k-means) - один из алгоритмов машинного обучения, решающий задачу кластеризации. Этот алгоритм является неиерархическим[1], итерационным методом кластеризации[2], он получил большую популярность благодаря своей простоте, наглядности реализации и достаточно высокому качеству работы. Был изобретен в 1950-х годах математиком Гуго Штейнгаузом[3] и почти одновременно Стюартом Ллойдом[4]. Особую популярность приобрел после публикации работы МакКуина[5] в 1967. Алгоритм представляет собой версию EM-алгоритма[6], применяемого также для разделения смеси гауссиан. Основная идея алгоритма k-means заключается в том, что данные произвольно разбиваются на кластеры, после чего итеративно перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике. Цель алгоритма заключается в разделении n наблюдений на k кластеров таким образом, чтобы каждое наблюдение принадлежало ровно одному кластеру, расположенному на наименьшем расстоянии от наблюдения. 1.2 Математическое описание алгоритмаДано: набор из n наблюдений X={x1,x2,...,xn},xi∈Rd, i=1,...,n; k - требуемое число кластеров, k∈N, k≤n. Требуется: Разделить множество наблюдений X на k кластеров S1,S2,...,Sk: Si∩Sj=∅,i≠j ⋃ki=1Si=X Действие алгоритма: Алгоритм k-means разбивает набор X на k наборов S1,S2,...,Sk, таким образом, чтобы минимизировать сумму квадратов расстояний от каждой точки кластера до его центра (центр масс кластера). Введем обозначение, S={S1,S2,...,Sk}. Тогда действие алгоритма k-means равносильно поиску:
где μi – центры кластеров, i=1,...,k,ρ(x,μi) – функция расстояния между x и μi Шаги алгоритма: Начальный шаг: инициализация кластеров Выбирается произвольное множество точек μi, i=1,...,k, рассматриваемых как начальные центры кластеров: μ(0)i=μi,i=1,...,k Распределение векторов по кластерам Шаг t:∀xi∈X, i=1,...,n:xi∈Sj⟺j=argminkρ(xi,μ(t−1)k)2 Пересчет центров кластеров Шаг t:∀i=1,...,k:μ(t)i=1|Si|∑x∈Six Проверка условия останова: if ∃i∈1,k¯¯¯¯¯¯¯:μ(t)i≠μ(t−1)i then t=t+1; goto 2; else stop 1.3 Вычислительное ядро алгоритмаВычислительным ядром являются шаги 2 и 3 приведенного выше алгоритма: распределение векторов по кластерам и пересчет центров кластеров. Распределение векторов по кластерам предполагает вычисление расстояний между каждым вектором xi∈X, i=1,...,n и центрами кластера μj, j=1,...,k. Таким образом, данный шаг предполагает kn вычислений расстояний между d-мерными векторами. Пересчет центров кластеров предполагает k вычислений центров масс μi множеств Si, i=1,...,k, представленных выражением в шаге 3 представленного выше алгоритма. 1.4 Макроструктура алгоритмаИнициализация центров масс μ1,...,μk. Наиболее распространенными являются следующие стратегии: Метод Forgy В качестве начальных значений μ1,...,μk берутся случайно выбранные векторы. Метод случайно разделения (Random Partitioning) Для каждого вектора xi∈X, i=1,...,n, выбирается случайным образом кластер S1,...,Sk, после чего для каждого полученного кластера вычисляются значения μ1,...,μk. Распределение векторов по кластерам Для этого шага алгоритма между векторами xi∈X, i=1,...,n, и центрами кластеров μ1,...,μk вычисляются расстояния по формуле (как правило, используется Евлидово расстояние):
Пересчет центров кластеров Для этого шага алгоритма производится пересчет центров кластера по формуле вычисления центра масс:
1.5 Схема реализации последовательного алгоритма1. Инициализировать центры кластеров μ(1)i, i=1,...,k 2. t←1 3. Распределение по кластерам S(t)i={xp:∥xp−μ(t)i∥2≤∥xp−μ(t)j∥2∀j=1,...,k}, где каждый вектор xp соотносится единственному кластеру S(t) 4. Обновление центров кластеров μ(t+1)i=1|S(t)i|∑xj∈S(t)ixj 5. if ∃i∈1,k¯¯¯¯¯¯¯:μ(t+1)i≠μ(t)i then t=t+1; goto 3; else stop 1.6 Последовательная сложность алгоритмаОбозначим Θd,mcentroid временную сложность вычисления центорида кластера, число элементов которого равна m, в d-мерном пространстве. Аналогично Θddistance – временная сложность вычисления расстояния между двумя d-мерными векторами. Сложность шага инициализации k кластеров мощности m в d-мерном пространстве – Θk,d,minit Стратерия Forgy: вычисления не требуются, Θk,d,minit=0 Стратегия случайного разбиения: вычисление центров k кластеров, Θk,d,minit=k⋅Θd,mcentroid,m≤n Cложность шага распределения d мерных векторов по k кластерам – Θk,ddistribute На этом шаге для каждого вектора xi∈X, i=1,...,n, вычисляется k расстояний до центров кластеров μ1,...μk Θk,ddistribute=n⋅k⋅Θddistance Сложность шага пересчета центров k кластеров размера m в d-мерном пространстве – Θk,d,mrecenter На этом шаге вычисляется k центров кластеров μ1,...μk Θk,d,mrecenter=k⋅Θd,mcentroid Рассчитаем Θd,mcentroid для кластера, число элементов которого равно m Θd,mcentroid = m⋅d сложений + d делений Рассчитаем Θddistance в соответствие с формулой (2) Θddistance = d вычитаний + d умножений + (d−1) сложение Предположим, что алгоритм сошелся за i итераций, тогда временная сложность алгоритма Θd,nk−means Θd,nk−means≤Θk,d,ninit+i(Θk,ddistribute+Θk,d,nrecenter) Операции сложения/вычитания: Θd,nk−means≤knd+i(kn(2d−1)+knd)=knd+i(kn(3d−1))∼O(ikdn) Операции умножения/деления: Θd,nk−means≤kd+i(knd+kd)=kd+ikd(n+1)∼O(ikdn) Получаем, что временная сложность алгоритма k-means кластеризации n d-мерных векторов на k кластеров за i итераций: Θd,nk−means∼O(ikdn) 1.7 Информационный графРассмотрим информационный граф алгоритма. Алгоритм k-means начинается с этапа инициализации, после которого следуют итерации, на каждой из которых выполняется два последовательных шага (см. "Схема реализации последовательного алгоритма"): распределение векторов по кластерам перерасчет центров кластеров Поскольку основная часть вычислений приходится на шаги итераций, распишем информационные графы данных шагов. Распределение векторов по кластерам Информационный граф шага распределения векторов по кластерам представлен на рисунке 1. Исходами данного графа является исходные векторы x1,...,xn, а также центры кластеров μ1,...μk, вычисленные ранее (на шаге инициализации, если рассматривается первая итерация алгоритма, или на шаге пересчета центров кластеров предыдущей итерации в противном случае). Каждая пара векторов данных xi, i=1,...,n, и центров кластера μj, j=1,...,k : (xi, μj) подаются на независимые узлы "d" вычисления расстояния между векторами (более подробная схема вычисления расстояния представлена далее, рисунок 2). Далее узлы вычисления расстояния "d", соответствующие одному и тому же исходному вектору xi передаются на один узел "m", где далее происходит вычисление новой метки кластера для каждого вектора xi (берется кластер с минимальным результатом вычисления расстояния). На выходе графа выдаются метки кластеров , L1,...,Ln, такие что ∀xi, i=1,...,n, xi∈Sj⇔Li=j. 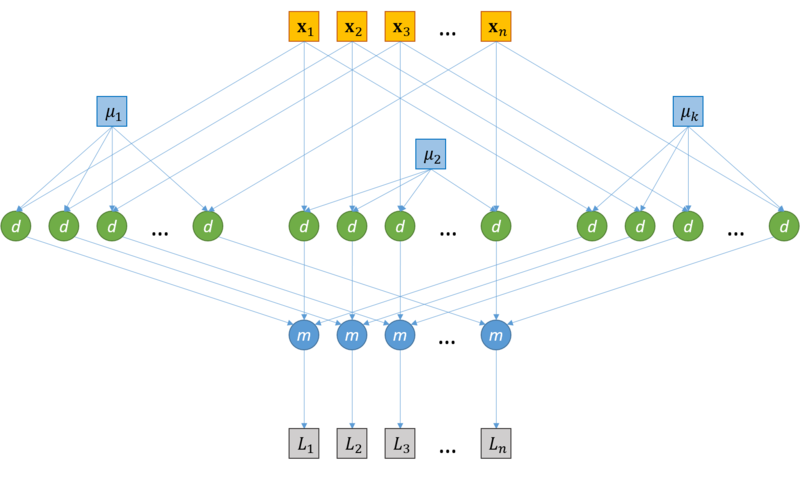 Рис. 1. Схема распределения векторов по кластерам. d – вычисление расстояния между векторами; m – вычисление минимума. Вычисление расстояния между векторами Подробная схема вычисления расстояния между векторами xi,μj представлена на рисунке 2. Как показано на графе, узел вычисления расстояния между векторами "d" состоит из шага взятия разности между векторами (узел "−") и взятия нормы получившегося вектора разности (узел "||⋅||2"). Более подробно, вычисление расстояния между векторами xi=xi1,,...,xin,μj=μj1,...,μjn может быть представлено как вычисление разности между каждой парой компонент (xiz,μjz), z=1,...,d (узел "−"), далее возведение в квадрат для каждого узла "−" (узел "()2") и суммирования выходов всех узлов "()2" (узел "+"). 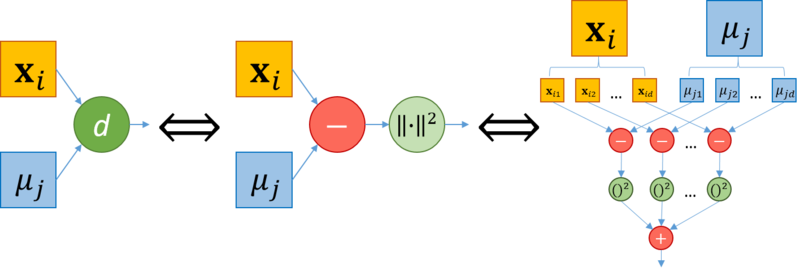 Рис. 2. Схема вычисления расстояния между вектором и центром кластера. Пересчет центров кластеров Информационный граф шага пересчета центров кластеров представлен на рисунке 3. Исходами данного графа является исходные векторы x1,...,xn, а также им соответствующие метки кластера, L1,...,Ln, такие что ∀xi, i=1,...,n, xi∈Sj⇔Li=j, вычисленные на этапе распределения векторов по кластерам. Все векторы x1,...,xn подаются в узлы +1,...+k, каждый узел +m, m=1,...,k, соответствует операции сложения векторов кластера с номером m. Метки кластера L1,...,Ln также совместно передаются на узлы Sm, m=1,...,k, на каждом из которых вычисляется количество векторов в соответствующем кластере (количество меток с соответствующим значением). Далее каждая пара выходов узлов +m и Sm подается на узел "/", где производится деление суммы векторов кластера на количество элементов в нем. Значения, вычисленные на узлах "/", присваиваются новым центрам кластеров (выходные значения графа). 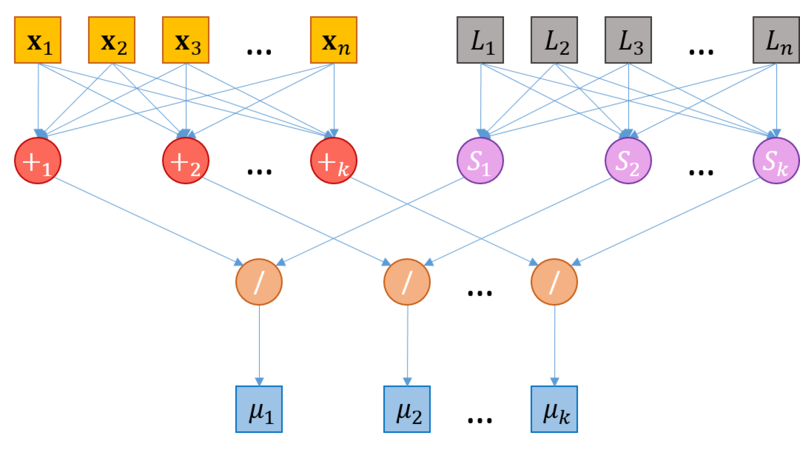 Рис. 3. Схема пересчета центров кластеров 1.8 Ресурс параллелизма алгоритмаРабота алгоритма состоит из i итераций, в каждой из которых происходит распределение d-мерных векторов по k кластерам, а также пересчет центров кластеров в d-мерном пространстве. В шаге распределения d-мерных векторов по k кластерам расстояния между вектором и центрами кластеров вычисляются независимо (отсутствуют информационные зависимости). Центры масс кластеров также пересчитываются независимо друг от друга. Таким образом, имеет место массовый параллелизм. Вычислим параллельную сложность Ψ∗ каждого из шагов, а также параллельную сложность всего алгоритма, Ψk−means. Будем исходить из предположения, что может быть использовано любое необходимое число потоков. Распределение d-мерных векторов по k кластерам Поскольку на данном шаге для каждой пары векторов xi, i=1,...,n и μj, j=1,...,k, операции вычисления расстояния не зависят друг от друга, они могут выполняться параллельно. Тогда, разделив все вычисление расстояний на n потоков, получим, что в каждом потоке будет выполняться только одна операция вычисления расстояния между векторами размерности d. При этом каждому вычислительному потоку передаются координаты центров всех кластеров μ1,...,μk. Таким образом, параллельная сложность данного шага определяется сложностью параллельной операции вычисления расстояния между d-мерными векторами, Ψddistance и сложностью определения наиболее близкого кластера (паралельное взятие минимума по расстояниям), Ψkmin. Для оценки Ψddistance воспользуемся параллельной реализацией нахождения частичной суммы элементов массива путем сдваивания. Аналогично, Ψkmin=log(k). В результате, Ψddistance=O(log(d)). Таким образом: Ψk,ddistribute=Ψddistance+Ψkmin=O(log(d))+O(log(k))=O(log(kd)) Пересчет центров кластеров в d-мерном пространстве Поскольку на данном шаге для каждого из k кластеров центр масс может быть вычислен независимо, данные операции могут быть выполнены в отдельных потоках. Таким образом, параллельная сложность данного шага, Ψk,drecenter, будет определяться параллельной сложностью вычисления одного центра масс кластера размера m, Ψk,drecenter, а так как m≤n⇒Ψd,mrecenter≤Ψd,nrecenter. Сложность вычисления центра масс кластера d-мерных векторов размера n аналогично предыдущим вычислениям равна O(log(n)). Тогда: Ψk,drecenter≤Ψd,nrecenter=O(log(n)) Общая параллельная сложность алгоритма На каждой итерации необходимо обновление центров кластеров, которые будут использованы на следующей итерации. Таким образом, итерационный процесс выполняется последовательно[7]. Тогда, поскольку сложность каждой итерации определяется Ψk,ddistribute и Ψrecenter, сложность всего алгоритма, Ψk−means в предположении, что было сделано i операций определяется выражением Ψk−means≈i⋅(Ψk,ddistribute+Ψk,drecenter)≤i⋅O(log(kdn)) 1.9 Входные и выходные данные алгоритмаВходные данные Матрица из n⋅d элементов xi,j∈R, i=1,...,n, j=1,...,d, – координат векторов (наблюдений). Целое положительное число k, k≤n – количество кластеров. Объем входных данных 1 целое число + n⋅d вещественных чисел (при условии, что координаты – вещественные числа). Выходные данные n целых положительных чисел L1,...,Ln– номера кластеров, соотвествующие каждому вектору (при условии, что нумерация кластеров начинается с 1). Объем выходных данных n целых положительных чисел. 1.10 Свойства алгоритмаВычислительная мощность Вычислительная мощность алгоритма k-means равна ikdnnd=ki, где k – число кластеров, i – число итераций алгоритма. Детерминированность и Устойчивость Алгоритм k-means является итерационным. Количество итераций алгоритма в общем случае не фиксируется и зависит от начального расположения объектов в пространстве, параметра k, а также от начального приближения центров кластеров, μ1,...,μk. В результате этого может варьироваться результат работы алгоритма. При неудачном выборе начальных параметров итерационный процесс может сойтись к локальному оптимуму[8]. По этим причинам алгоритм не является ни детермирированным, ни устойчивым. Соотношение последовательной и параллельной сложности алгоритма Θk−meansΨk−means=O(ikdn)O(i⋅log(kdn)) Сильные стороны алгоритма: Сравнительно высокая эффективность при простоте реализации Высокое качество кластеризации Возможность распараллеливания Существование множества модификаций Недостатки алгоритма[9]: Количество кластеров является параметром алгоритма Чувствительность к начальным условиям Инициализация центров кластеров в значительной степени влияет на результат кластеризации. Чувствительность к выбросам и шумам Выбросы, далекие от центров настоящих кластеров, все равно учитываются при вычислении их центров. Возможность сходимости к локальному оптимуму Итеративный подход не дает гарантии сходимости к оптимальному решению. Использование понятия "среднего" Алгоритм неприменим к данным, для которых не определено понятие "среднего", например, категориальным данным. 2 Программная реализация алгоритма2.1 Особенности реализации последовательного алгоритма2.2 Локальность данных и вычислений2.2.1 Локальность реализации алгоритма2.2.1.1 Структура обращений в память и качественная оценка локальности2.2.1.2 Количественная оценка локальности2.3 Возможные способы и особенности параллельной реализации алгоритма2.4 Масштабируемость алгоритма и его реализацииВ настоящем разделе проведено исследование масштабируемости различных параллельных реализации алгоритма k средних согласно методике AlgoWiki. 2.4.1 Реализация 1Исследование масштабируемости параллельной реализации алгоритма k-means проводилось на суперкомпьютере "Ломоносов"[10] Суперкомпьютерного комплекса Московского университета. Алгоритм реализован на языке C с использованием средств MPI. Для исследования масштабируемости проводилось множество запусков программы с разным значением параметра (количество векторов для кластеризации), а также с различным числом процессоров. Фиксировались результаты запусков – время работы t и количество произведенных итераций алгоритма i. Параметры запусков для экспериментальной оценки: Значения количества векторов n: 20'000, 30'000, 50'000, 100'000, 200'000, 300'000, 500'000, 700'000, 1'000'000, 1'500'000, 2'000'000. Значения количества процессоров p: 1, 8, 16, 32, 64, 128, 160, 192, 224, 256, 288, 320, 352, 384, 416, 448, 480, 512. Значение количества кластеров k: 100. Значение размерности векторов d: 10. Для проведения экспериментов были сгенерированы нормально распределенные псевдослучайные данные (с использованием Python библиотеки scikit-learn): from sklearn.datasets import make_classification X1, Y1 = make_classification(n_features=10, n_redundant=2, n_informative=8, n_clusters_per_class=1, n_classes=100, n_samples=2000000) Для заданной конфигурации эксперимента (n,d,p,k) и полученных результатов (t,i) производительность и эффективность реализации расчитывались по формулам: Performance=Nd,nk−meanst (FLOPS), где Nd,nk−means – точное число операций с плавающей точкой (операции с памятью, а также целочисленные операции не учитывались), вычисленное в соответствие с разделом "Последовательная сложность алгоритма"; Efficiency=100⋅PerformancePerformancepPeak (%), где PerformancepPeak – пиковая производительность суперкомпьютера при p процессорах, вычисленная согласно спецификациям Intel® XEON® X5670[11]. Графики зависимости производительности и эффективности параллельной реализации k-means от числа векторов для кластеризации (n) и числа процессоров (p) представлены на рисунках 4 и 5, соответственно. 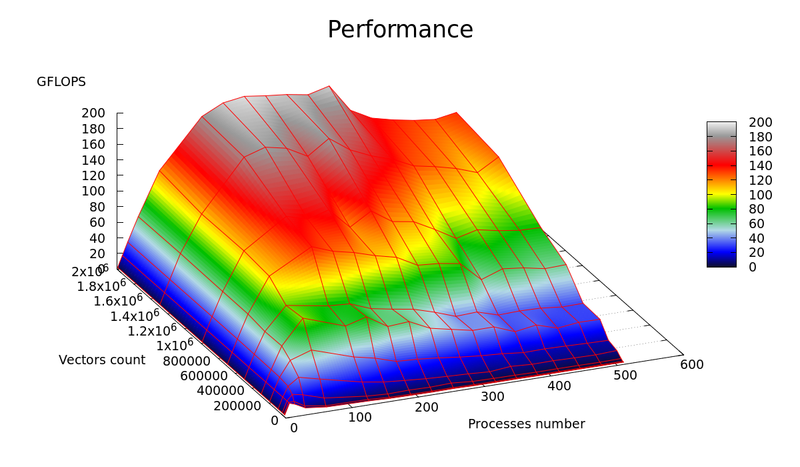 Рис. 4. Параллельная реализация k-means. График зависимости производительности реализации алгоритма от числа векторов для кластеризации (n) и числа процессоров (p).  Рис. 5. Параллельная реализация k-means. График зависимости эффективности реализации алгоритма от числа векторов для кластеризации (n) и числа процессоров (p). В результате экспериментальной оценки были получены следующие оценки эффективности реализации: Минимальное значение: 0.000409 % достигается при n=20′000,p=480 Максимальное значение: 0.741119 % достигается при n=300′000,p=1 Оценки масштабируемости реализации алгоритма k-means: По числу процессоров: -0.002683 – эффективность убывает с ростом числа процессоров. Данный результат вызван ростом накладных расходов для обеспечения параллельного выполнения алгоритма. По размеру задачи: 0.002779 – эффективность растет с ростом числа векторов. Данный результат вызван тем, что при увеличении размера задачи, количество вычислений растет по сравнению с временем, затрачиваемым на пересылку данных. Общая оценка: -0.000058 – можно сделать вывод, что в целом эффективность реализации незначительно уменьшается с ростом размера задачи и числа процессоров. Использованная параллельная реализация алгоритма k-means 2.4.2 Реализация 2Исследование также проводилось на суперкомпьютере "Ломоносов". Набор данных для тестирования состоял из 946000 векторов размерности 2 (координаты на сфере) Набор и границы значений изменяемых параметров запуска реализации алгоритма: число процессов (виртуальных ядер) [8 : 512]; число кластеров [128 : 384]. В результате проведённых экспериментов был получен следующий диапазон эффективности реализации алгоритма: минимальная эффективность реализации 2,47 достигается при делении исходных данных на 128 кластеров с использованием 512 процессов; максимальная эффективность реализации 7,13 достигается при делении исходных данных на 352 кластера с использованием 8 процессов. На рисунках 6 и 7, соответственно, представлены графики зависимости производительности и эффективности параллельной реализации k-means от числа кластеров и числа процессов.  Рис. 6. График зависимости производительности параллельной реализации алгоритма от числа кластеров и числа процессов. По рис. 6 можно отметить практически полное отсутствие роста производительности с увеличением числа процессов от 256 до 512 при минимальном размере задачи. Это связано с быстрым ростом накладных расходов по отношению к крайне низкому объёму вычислений. При росте размерности задачи данный эффект пропадает, и при одновременном пропорциональном увеличении числа кластеров и числа процессов рост производительности становится близким к линейному. 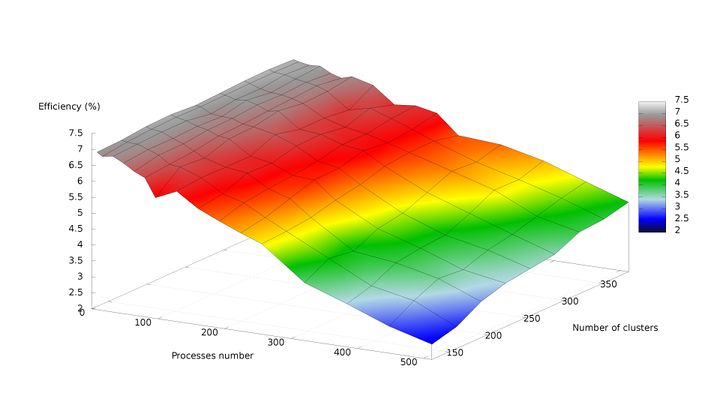 Рис. 7. График зависимости эффективности параллельной реализации алгоритма от числа кластеров и числа процессов. Исследовалась параллельная реализация алгоритма k-means на MPI. Были получены следующие оценки масштабируемости реализации алгоритма k-means: По числу процессов: −0.02209. Следовательно, с ростом числа процессов эффективность уменьшается. На рис. 7 можно наблюдать плавное и равномерное снижение производительности по мере увеличения числа процессов при неизменном числе кластеров, что свидетельствует об относительно невысоком росте накладных расходов на передачу данных между процессами и преобладании объёма вычислений над объёмом пересылок данных по сети. По размеру задачи: 0.01252. Следовательно, с ростом размера задачи (числа кластеров) эффективность увеличивается. При этом объём пересылок данных по сети пропорционален (n+k)⋅p (где k - число кластеров, n - число входных векторов, p - число процессов) таким образом, поскольку k< Общая оценка: −0.00081. Таким образом, с ростом и размера задачи, и числа процессов эффективность уменьшается. Это связано с тем, что отношение объёма вычислений к объёму передаваемых данных изменяется пропорционально kn(n+k)⋅p∼kp, что представляет собой невысокий коэффициент, но при этом позволяет параллельной реализации не деградировать до нулевой эффективности при значительном увеличении числа процессов. 2.4.3 Реализация 3Исследование масштабируемости алгоритма k-means в зависимости от количества используемых процессов было проведено в статье Кумара[12]. Исследование происходило на суперкомпьютере Jaguar - Cray XT5[13]. На момент экспериментов данный суперкомпьютер имел следующую конфигурацию: 18,688 вычислительных узлов с двумя шестнадцатиядерными процессорами AMD Opteron 2435 (Istanbul) 2.6 GHz, 16 GB of DDR2-800 оперативной памяти, и SeaStar 2+ роутер. Всего он состоял из 224,256 вычислительных ядер, 300 TB памяти, и пиковой производительностью 2.3 petaflops. Реализация алгоритма была выполнена на языке программирования C с использованием MPI. Объем данных составлял 84 ГБ, количество объектов (d-мерных векторов) n равнялось 1,024,767,667, размерность векторов d равнялась 22, количество кластеров k равнялось 1000. На рис. 8 показана зависимости времени работы алгоритма кластеризации k-means в зависимости от количества используемых процессоров. Можно отметить, что время, затраченное на чтение данных и запись результатов кластеризации, практически не изменяется с увеличением количества задействованных процессоров. Время же работы самого алгоритма кластеризации уменьшается с увеличением количества процессоров. 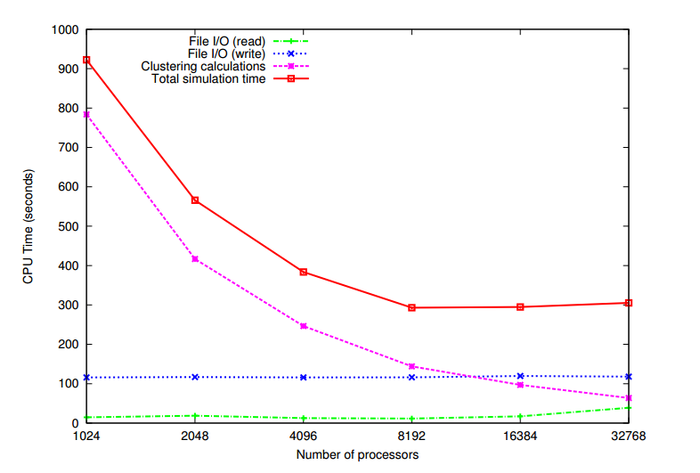 Рис. 8. Зависимости времени работы алгоритма кластеризации k-means в зависимости от количества используемых процессоров (из работы: Kumar etc. 2011). Также было произведено самостоятельное исследование масштабируемости алгоритма k-means. Исследование производилось на суперкомпьютере "Blue Gene/P"[14]. Набор и границы значений изменяемых параметров запуска реализации алгоритма: число процессоров [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]; количество объектов [5000, 10000, 25000, 50000]. Был использован набор данных Dataset for Sensorless Drive Diagnosis Data Set[15] из репозитория Machine learning repository[16]. Исследуемый набор данных содержит векторы, размерность которых равна 49. Компоненты векторов являются вещественными числами. Количество кластеров равно 11. Пропущенные значения отсутствуют. Для исследования масштабируемости алгоритма была использована реализация на языке C с использованием MPI[17]. Код можно найти здесь: https://github.com/serban/kmeans. Данная реализация предоставляет возможность распараллеливать решение задачи с помощью технологий MPI, OpenMP И CUDA. Для запуска MPI-версии программы использовалась цель "mpi_main" Makefile. На рис. 9 показана зависимости времени работы алгоритма кластеризации k-means в зависимости от количества используемых процессоров (использовались логарифмические оси). Разными цветами помечены запуски, соответствующие разным количествам объектам, участвующих в кластеризации. Можно видеть близкое к линейному увеличение времени работы программы в зависимости от количества процессоров. Также можно видеть увеличение времени работы алгоритма при увеличении количества объектов. 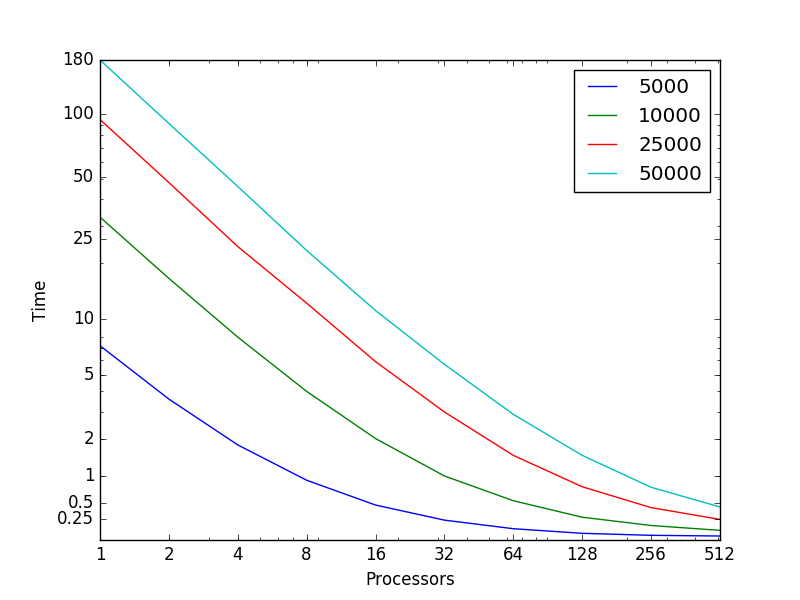 Рис. 9. Зависимости времени работы алгоритма кластеризации k-means в зависимости от количества используемых процессоров. На рис. 10 показана эта же зависимость, только в трехмерном пространстве. По аналогии с рис. 9, были использованы логарифмические оси. Как и в случае двумерного рисунка, можно видеть близкое к линейному увеличение времени работы программы. 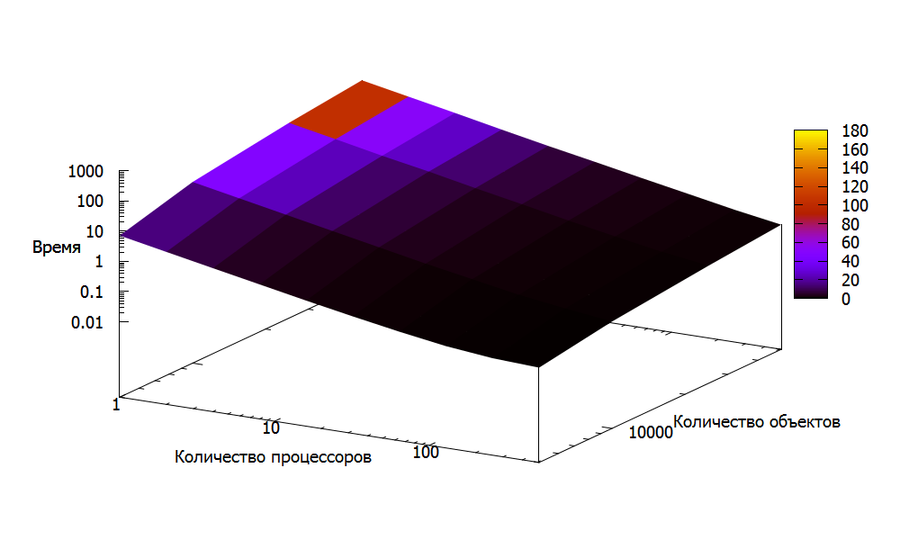 Рис. 10. Зависимости времени работы алгоритма кластеризации k-means в зависимости от количества используемых процессоров. 2.4.4 Реализация 4Исследование масштабируемости данной параллельной реализации алгоритма k-средних также проводилось на суперкомпьютере "Ломоносов". Параллельная реализация была написана самостоятельно на языке C, ссылка на реализацию. Так как на каждой итерации число действий на единицу данных не велико и данные должны быть собраны вместе при перерасчете центроидов, было решено для ускорения вычислений воспользоваться только OpenMP без использовании MPI. Код собирался под gcc c опцией -fopenmp. Код считался на одном процессоре, технология hyperthreading не использовалась. Набор и границы значений изменяемых параметров запуска реализации алгоритма: число процессоров [1 : 16] с увеличением в 2 раза; размер данных [100000 : 1600000] с увеличением в 2 раза. В результате проведённых экспериментов были получены следующие данные: Максимальная эффективность в точке достигается при переходе от 1 потока на 4 при минимальном размере данных, она равна 87,5. Усредненная максимальная эффективность достигается при переходе с одного потока на два. Среднее время вычислений на всех рассмотренных потока снижается с 16,33 до 11.87 секунд, поэтому формально эффективность =16.33/11.87/2≈68,4% Минимальная эффективность в точке достигается при переходе от 1 потока на 16 при размере данных 800000, она равна 11,1%. Усредненная минимальная эффективность наблюдается при переходе с одного на максимальное рассматриваемое в эксперименте число потоков, равное 16. Время вычисления изменяется с 16,33 до 7,6 секунд, поэтому формально эффективность =16.33/7.6/16≈14,9% Ниже приведены графики зависимости вычислительного времени алгоритма и его эффективности от изменяемых параметров запуска — размера данных и числа процессоров:  Рис. 11. Параллельная реализация алгоритма k-средних. Изменение вычислительного времени алгоритма в зависимости от числа процессоров и размера исходных данных. Здесь видно, что время выполнения операций алгоритма плавно убывает по каждому из параметров, причем скорость убывания по параметру числа процессоров выше, чем в зависимости от размерности задачи. 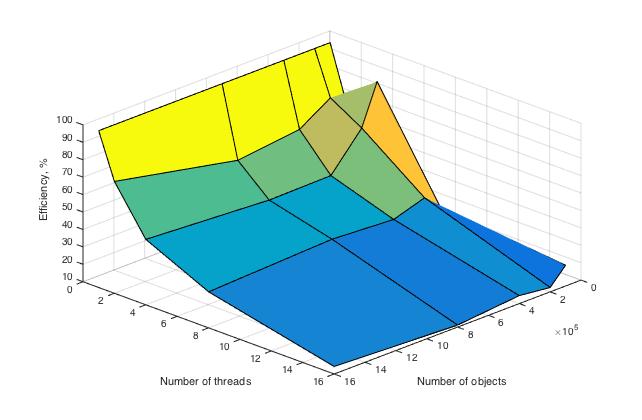 Рис. 12. Параллельная реализация алгоритма k-средних. Изменение эффективности алгоритма в зависимости от числа процессоров и размера исходных данных. Здесь построена эффективность перехода от последовательной реализации к параллельной. Рассчитывается она по формуле Время вычисления на 1 потоке / Время вычисления на T потоках / T, где T — это число потоков. При вычислении на 1 процессоре она равна 100 \% в силу используемой формулы, что и отражено на графике. Проведем оценки масштабируемости: По числу процессов — при увеличении числа процессов эффективность уменьшается на всей области рассматриваемых значений, причем темп убывания замедляется с ростом числа процессов. По размеру задачи — при увеличении размера задачи эффективность вычислений вначале кратковременно возрастает, но затем начинает относительно равномерно убывать на всей рассматриваемой области. По размеру задачи — при увеличении размера задачи эффективность вычислений в общем случае постепенно убывает. На малых данных она выходит на пик мощности, являющийся максимумом эффективности в исследуемых условиях, но затем возвращается к процессу убывания. 2.5 Динамические характеристики и эффективность реализации алгоритма2.6 Выводы для классов архитектурВ однопоточном режиме на наборах данных, представляющих практический интерес (порядка нескольких десятков тысяч векторов и выше), время работы алгоритма неприемлемо велико. Благодаря свойству массового параллелизма должно наблюдаться значительное ускорение алгоритма на многоядерных архитектурах (Intel Xeon), а также на графических процессорах, даже на мобильных вычислительных системах (ноутбуках), оснащенных видеокартой. Алгоритм k-means также будет демонстрировать значительное ускорение на сверхмощных вычислительных комплексах (суперкомпьютерах, системах облачных вычислений[18]). На сегодняшний день существует множество реализаций алгоритма k-means, в частности, направленных на оптимизацию параллельной работы на различных архитектурах[19][20][21]. Предлагается множество адаптаций алгоритма под конкретные архитектуры. Например, авторы работы[22] производят перерасчет центров кластеров на этапе распределения векторов по кластерам. 2.7 Существующие реализации алгоритма2.7.1 Открытое программное обеспечениеCrimeStat Программное обеспечение, созданное для операционных систем Windows, предоставляющее инструменты статистического и пространственного анализа для решения задачи картирования преступности. Julia Высокоуровневый высокопроизводительный свободный язык программирования с динамической типизацией, созданный для математических вычислений, содержит реализацию k-means. Mahout Apache Mahout - Java библиотека для работы с алгоритмами машинного обучения с использованием MapReduce. Содержит реализацию k-means. Octave Написанная на C++ свободная система для математических вычислений, использующая совместимый с MATLAB язык высокого уровня, содержит реализацию k-means. Spark Распределенная реализация k-means содержится в библиотеке Mlib для работы с алгоритмами машинного обучения, взаимодействующая с Python библиотекой NumPy и библиотека R. Torch MATLAB-подобная библиотека для языка программирования Lua с открытым исходным кодом, предоставляет большое количество алгоритмов для глубинного обучения и научных расчётов. Ядро написано на Си, прикладная часть выполняется на LuaJIT, поддерживается распараллеливание вычислений средствами CUDA и OpenMP. Существуют реализации k-means. Weka Cвободное программное обеспечение для анализа данных, написанное на Java. Содержит k-means и x-means. Accord.NET C# реализация алгоритмов k-means, k-means++, k-modes. OpenCV Написанная на С++ библиотека, направленная в основном на решение задач компьютерного зрения. Содержит реализацию k-means. MLPACK Масштабируемая С++ библиотека для работы с алгоритмами машинного обучения, содержит реализацию k-means. SciPy Библиотека Python, содержит множество реализаций k-means. scikit-learn Библиотека Python, содержит множество реализаций k-means. R Язык программирования для статистической обработки данных и работы с графикой, а также свободная программная среда вычислений с открытым исходным кодом в рамках проекта GNU, содержит три реализации k-means. ELKI Java фреймворк, содержащий реализацию k-means, а также множество других алгоритмов кластеризации. |