Булутли ҳисоблашлар. 4. 0ишлаб чиариш интернети
 Скачать 1.42 Mb. Скачать 1.42 Mb.
|

3.2. Уч “V” ва учта катта маълумотлар принциплариКатта маълумотларнинг аниқловчи хусусиятлари, уларнинг жисмоний ҳажмидан ташқари, ушбу маълумотларни қайта ишлаш ва таҳлил қилиш вазифасининг мураккаблигини таъкидлайдиган бошқа хусусиятлардир. Мета Group компанияси 2001 йилда Мета Group компанияси томонидан ҳар уч жиҳат бўйича ҳам маълумотларни бошқаришнинг бир хил аҳамиятлилигини намойиш этиш учун VVV атрибутлари тўпламини (VVV - volume, velocity, variety) (ҳажм, тезлик, хилма-хиллик - жисмоний ҳажм, маълумотларнинг ўсиш суръати ва тезкор қайта ишлаш зарурати, турли хил маълумотларни бир вақтнинг ўзида қайта ишлаш қобилияти) ишлаб чиқди. 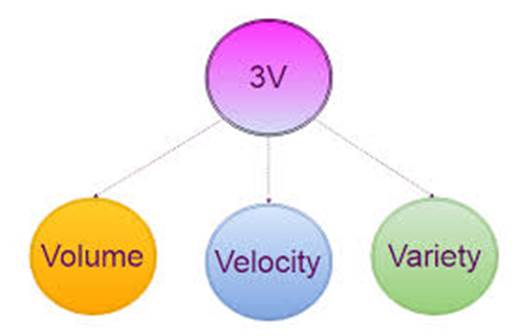 3.2-расм. Катта маълумот асослари Келажакда талқинлар тўртта V (veracity – ишончлилик кўшилган), бешта V (viability - ҳаётийлик ва value – қиймат кўшилган) ва еттита V (variability - ўзгарувчанлик ва visualization – визуализация кўшилган) билан изохланади. Юқоридаги таърифларга асосланиб, катта маълумотлар билан ишлашнинг асосий принциплари қуйидагилардан иборат: 1. Горизонтал масштаблаш. Бу катта маълумотларни қайта ишлашнинг асосий принципи. Юқорида айтиб ўтилганидек, ҳар куни кўп маълумотлар бор. Шунга кўра, ушбу маълумотлар тақсимланадиган ҳисоблаш тугунлари сонини кўпайтириш керак лекин ишлаш самарасини бузмасдан амалга оширилиши керак. 2. Камчиликларга бардошлик (отказоустойчивость). Ушбу тамойил аввалгисидан келиб чиқади. Кластерда жуда кўп ҳисоблаш тугунлари бўлиши мумкин (баъзида ўн минглаб) ва уларнинг сони, мумкин, кўпаяди ва машинанинг ишдан чиқиши эҳтимоли ҳам ортади. Катта маълумотлар билан ишлаш усуллари бундай ҳолатларнинг эҳтимолини ҳисобга олиши ва профилактика чораларини кўриши керак. 3. Маълумотларнинг локаллиги. Маълумотлар жуда кўп сонли ҳисоблаш тугунлари бўйлаб тақсимланганлиги сабабли, улар битта серверда жойлашган бўлса ва бошқасида ишлов берилса, маълумотларни узатиш харажатлари асоссиз равишда ошиб кетиши мумкин. Шунинг учун, улар сақланадиган машинада маълумотларни қайта ишлашни амалга ошириш мақсадга мувофиқдир. Ушбу принциплар анъанавий, марказлаштирилган ва яхши тузилган маълумотларни сақлаш учун вертикал моделлардан фарқ қилади. Шунга кўра, катта маълумотлар билан ишлаш учун янги ёндашувлар ва технологиялар ишлаб чиқилмоқда. 3.3. Big Data билан ишлаш технологиялар ва тенденцияларДастлаб, СУБД NoSQL MapReduce алгоритмлари ва Hadoop лойиҳаси воситалари каби номаълум тузилган маълумотларга оммавий равишда параллел равишда ишлов бериш усуллари ва технологиялари киритилган. Кейинчалик, бошқа эчимлар катта маълумот технологияларига тааллуқли бўлиб, улар катта-катта маълумотлар массивларини, шунингдек баъзи бир ускуналарни қайта ишлаш қобилиятларида ўхшаш хусусиятларни тақдим этишди. MapReduce - Google томонидан тақдим этилган компютер кластерларида тақсимланган параллел ҳисоблаш модели. Ушбу моделга кўра дастур кластер тугунларида бажариладиган жуда кўп ўхшаш элементар вазифаларга бўлинади ва кейинчалик табиий равишда якуний натижага туширилади. • NoSQL (инглиз тилидан Not Only SQL) - ҳар хил номутаносиб маълумотлар базалари ва омборхоналар учун умумий атама бирон бир аниқ технология ёки маҳсулотни англатмайди. Анъанавий реляцион маълумотлар базалари жуда тез ва бир хил бўлган сўровлар учун жуда мос келади ва катта маълумотларга хос бўлган мураккаб ва мослашувчан қурилган сўровларда юк ўртача чегаралардан ошиб кетади ва маълумотлар базасидан фойдаланиш самарасиз бўлади. • Hadoop - бепул тарқатиладиган ёрдамчи воситалар тўплами, кутубхоналар ва юзлаб ва минглаб тугунлар кластерларида ишлайдиган тарқатилган дастурларни ишлаб чиқиш ва бошқариш. У катта маълумотларнинг асосий технологияларидан бири ҳисобланади. • Р - статистик маълумотларни ва графикаларни қайта ишлаш учун дастурлаш тили. У маълумотларни таҳлил қилиш учун кенг қўлланилади ва аслида статистик дастурлар учун стандарт бўлиб қолди. • Ускунa эчимлари. Teradata, EMC ва бошқа корпорациялар катта маълумотларни қайта ишлаш учун мўлжалланган аппарат ва дастурий таъминотни таклиф этади. Ушбу тизимлар серверлар ва оммавий параллел ишлов бериш учун бошқариш дастурларини ўз ичига олган ўрнатишга тайёр телекоммуникация шкафлари сифатида этказиб берилади. Бунга баъзан тасодифий кириш хотирасида аналитик ишлов бериш учун аппарат эчимлари, хусусан, SAP ва Oracle Analytics-дан Hana дастурий таъминоти ва дастурий таъминотлари киради, гарчи бундай қайта ишлаш дастлаб катта даражада параллел бўлмаса ҳам ва битта тугуннинг хотира ҳажми чекланган бир неча терабайт McKinsey консалтинг компанияси аксарият таҳлилчилар томонидан кўриб чиқилган NoSQL, MapReduce, Hadoop, Р технологияларига қўшимча равишда, катта маълумотларга ишлов бериш шароитида SQL қўллаб-қувватлайдиган Business Intelligence технологиялари ва маълумотлар базасини бошқариш тизимларини ҳам ўз ичига олади.  3.3-расм. Катта маълумотлар технологияси |