Ревью 5. Generics и Коллекции. Array length и Array. Size
Array.length и Array.Size Студент: Святослав Семенов integerList = Arrays.asList(1, 2, 3); { void m(Collection collection) { void m(List list) {используй даймонд оператор 1) Что такое дженерики? Какую проблему они решают. Дженерики – это параметризованные типы. С их помощью можно объявлять классы, интерфейсы и методы, в которых тип данных указан в виде параметра. list вместо List list, например.Плюсы : Что можно параметризовать? Метод, интерфейс, класс, поле Сырые типы — это типы без указания типа в фигурных скобках ( List list = new ArrayList<>() ), они использовались до появления дженериков.Raw типы! Если аргумент типа не определен, то используйте wildcard , компилятор выдаст ошибку. Этого как раз и добивались создатели языка, создавая дженерики — проверки на этапе компиляции. Но когда весь написанный тобой Java-код превратится в байт-код, в нем не будет информации о типах-параметрах.<> - даймонд оператор - синтаксический сахар; когда компилятор сам выводит тип правой части исходя из контекста, но контекстом не всегда является левая часть выражения(может быть возвращаемое значение метода, т.е. то, что должно вернуться из левой части). Дает компилятору 100% гарантию, что будет тот же тип. 2) Wildcard символом подстановки , с верхней границей (extends) или с нижней границей (super).2.1) Что можно поставить в дженерики, что нельзя? Что можно типизировать? Что нельзя параметризировать? void append(List list) {нельзя void rtti(List list) {instanceof ArrayList) { strSet) { } intSet) { } arrayLists = new ArrayList(); List > arrayList = new ArrayList<ArrayList >(); ? Термин Расшифровка параметризованным типом будет, например, List T — это параметр типа сырой тип — это List
3) Принцип PECS list = new ArrayList<>; Стирание типов - во время компиляции компилятор имеет полную информацию о типе, но эта информация обычно намеренно отбрасывается при создании байтового кода в процессе, известном как стирание типов . Это делается таким образом из-за проблем совместимости: целью разработчиков языка было обеспечение полной совместимости исходного кода и полной совместимости байтового кода между версиями платформы. Если бы он был реализован по-другому, вам пришлось бы перекомпилировать устаревшие приложения при переходе на более новые версии платформы. 4) Параметризация статических методов. void list, T val) 5) Что такое коллекция. Иерархия коллекций. 6) Внутреннее устройство коллекций. 6.1) Методы интерфейса Collection? iterator()
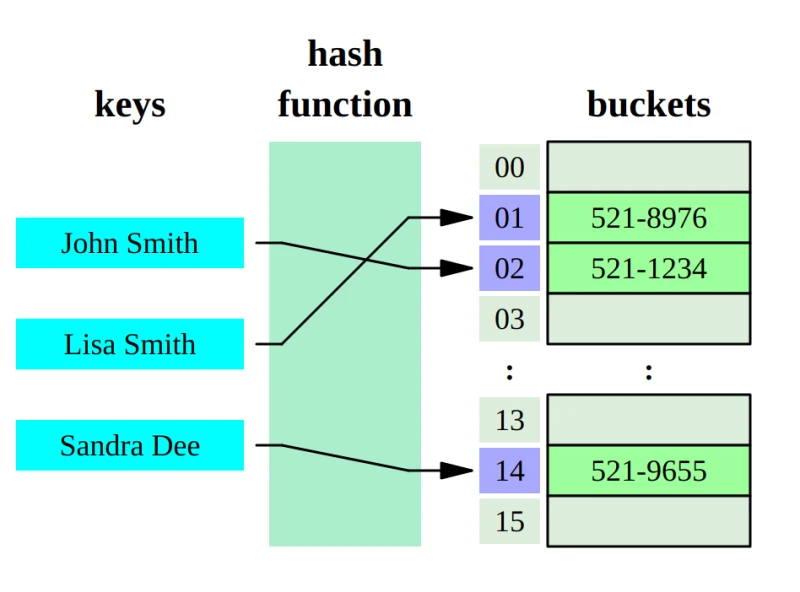
6.2) ArrayList места в массиве не достаточно , новая емкость рассчитывается по формуле // newCapacity - новое значение емкости elementData = (E[])new Object[newCapacity]; // oldData - временное хранилище текущего массива с данными System.arraycopy(oldData, 0, elementData, 0, size); listIterator (): возвращает объект ListIterator для обхода элементов списка List of(элементы): создает из набора элементов объект List LinkedList LinkedList содержит три поля:transient int size = 0 ; transient Node first; transient Node last; LinkedList использует объекты своего вложенного класса Node :private static class Node < E > { E item; Node next; Node prev; } Node(Node prev, E element, Node next) { this .item = element; this .next = next; this .prev = prev; } size , first , last ). null и повторяющиеся;O(1) выполняются операции вставки и удаления первого и последнего элемента, операции вставки и удаления элемента из середины списка (не учитывая время поиска позиции элемента, который осуществляется за линейное время);O(n) выполняются операции поиска элемента по индексу и по значению. addFirst() / offerFirst() : добавляет элемент в начало спискаaddLast() / offerLast() : добавляет элемент в конец спискаremoveFirst() / pollFirst() : удаляет первый элемент из начала спискаremoveLast() / pollLast() : удаляет последний элемент из конца спискаgetFirst() / peekFirst() : получает первый элементgetLast() / peekLast() : получает последний элемент Map > entrySet(): возвращает набор элементов коллекции. Все элементы представляют объект Map.Entryесли коллекция пуста keySet(): возвращает набор всех ключей отображения values(): возвращает набор всех значений отображения представляет объект с ключом типа K и значением типа V и определяет следующие методы: Set HashSet HashSet будет хранить элементы так, как ему удобно.LinkedHashSet TreeSet хранит элементы отсортированными Класс HashSet не добавляет новых методов Как работает HashSet? Почему в HashSet вместо value не null а new Object? Операции добавления , удаления и поиска будут выполняться за константное время при условии, что хэш-функция правильно распределяет элементы по «корзинам», о чем будет рассказано далее. static final int TREEIFY_THRESHOLD = 8 — это «порог» количества элементов в одной корзине, при достижении которого внутренний связный список будет преобразован в древовидную структуру (красно-черное дерево). static final int UNTREEIFY_THRESHOLD = 6 — если количество элементов в одной корзине уменьшится до 6, то произойдет обратный переход от дерева к связному списку; static final int MIN_TREEIFY_CAPACITY = 64 — минимальная емкость (количество корзин) хеш-таблицы, при которой возможен переход к древовидной структуре. Т.е. если в хеш-таблице по крайней мере 64 бакета и в одном бакете 8 или более элементов, то произойдет переход к древовидной структуре. MIN_TREEIFY_CAPACITY )resize() для увеличения размера хеш-таблицы с перераспределением элементов. Метод resize() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.ListIterator ListIterator - это подинтерфейс of Iterator. Это один из способов обхода (traverse) элементов List . В отличие от Iterator , ListIterator поддерживает перемещение элементов как в прямом, так и в обратном направлениях. ListIterator также поддерживает удаление, обновление или вставку элемента во время итерации. Метод и описание void add(Object obj) boolean hasNext( ) boolean hasPrevious( ) Object next( ) int nextIndex( ) Object previous( ) int previousIndex( ) void remove( ) void set(Object obj)
Iterator ListIterator Collection . List . Collection ) List ).
Можно ли с помощью цикла for each изменить поле объектов, которые находятся в массиве? И можно ли изменить сам объект? Отличие ArrayList от LinkedList? Когда лучше использовать ArrayList, а когда LinkedList? элементов находящихся не в конце списка , так как при этой операции все элементы правее добавляемого/удаляемого сдвигаются.В чём разница между Queue и Deque и Stack? Расскажи отличие List от Set? Как работает метод contains в ArrayList, LinkedList, HashSet? getEntry(Object key) { e = table[indexFor(hash, table.length)];В чём разница между Iterable и Iterator? Скорость вставки элемента в начало середину и конец у ArrayList vs LinkedList? Как работает HashMap? Расскажите подробно, как работает метод put? Что происходит при коллизии? implements Map.Entry { next; next) {[] table;сделано из-за того , что hashCode() можно реализовать так, что только нижние биты int'a будут заполнены. Например, для Integer, Float – если мы в HashMap кладем маленькие значения, то у них и биты хеш-кодов будут заполнены только нижние. В таком случае ключи в Hash Map будут иметь тенденцию скапливаться в нижних ячейках, а верхние будут оставаться пустыми, что не очень эффективно. На то, в какой бакет попадёт новая запись, влияют только младшие биты хеша. Поэтому и придумали различными манипуляциями подмешивать старшие биты хеша в младшие, чтобы улучшить распределение по бакетам (чтобы старшие биты родного хеша объекта начали вносить коррективы в то, в какой бакет попадёт объект) и, как следствие, производительность. Потому и придумана дополнительная функция hash внутри HashMap.
 Скачать 0.84 Mb.
Скачать 0.84 Mb.