Доклад по Теории информации. Символы. 5 доклад. Доклад 5 по дисциплине Теория информации
 Скачать 246.26 Kb. Скачать 246.26 Kb.
|

Доклад 5 по дисциплине «Теория информации»
Самара 2021 г. 2.1.9.1 Знаки валют Символ или знак валюты (¤) — типографский символ, который входит в группу «Управляющие символы C1 и дополнение 1 к латинице» (англ. C1 Controls and Latin-1 Supplement) стандарта Юникод: оригинальное название — Currency sign (англ.); код — U+00A4. Мнемоника HTML — ¤ Используется, когда в том или ином компьютерном шрифте недоступен или отсутствует знак конкретной валюты. Символ «¤» представляет собой слегка приподнятую над основной строкой окружность, от которой под углом 90° друг по отношению к другу отходят четыре луча. Для набора в ОС Windows необходимо на цифровой клавиатуре набрать цифры «0164», удерживая клавишу «Alt». 2.1.9.2 Смайлики Смайлик (англ. smiley — «улыбающийся» и непосредственное название такого значка) или счастливое лицо (☺/☻) — стилизованное графическое изображение улыбающегося человеческого лица; традиционно изображается в виде жёлтого круга с двумя чёрными точками, представляющими глаза, и чёрной дугой, символизирующей рот. Смайлики широко используются в популярной культуре, само слово «смайлик» также часто применяется как общий термин для любого эмотикона (изображения эмоции не графикой, а знаками препинания). Смайлик имеется в формате Юникод Basic Multilingual Plane[11]. Также расширенный набор смайликов находится в диапазоне 1F600-1F64F. Символы смайлика в Юникоде в диапазоне BMP: ☺ U+263A Alt+1 Белый смайлик ☻ U+263B Alt+2 Чёрный смайлик 2.1.9.3 Специальный символ ‘’BOM’’ Маркер последовательности байтов или метка порядка байтов (англ. Byte Order Mark, BOM) — специальный символ из стандарта Юникод, вставляемый в начало текстового файла или потока для обозначения того, что в файле (потоке) используется Юникод, а также для косвенного указания кодировки и порядка байтов, с помощью которых символы Юникода были закодированы. Номер этого символа в стандарте Юникод — U+FEFF. Использование этого символа, согласно спецификации Юникод, не является обязательным, однако оно широко распространено, так как позволяет легко избежать неверного декодирования текстовой информации. Согласно спецификации Юникода, маркер может стоять только в самом начале файла или потока. Если же символ U+FEFF встречается в середине потока данных, он должен[источник не указан 1193 дня] интерпретироваться как «нулевой ширины неразрывный пробел» (по существу, неотображаемый и ничего не меняющий символ). Однако, большинство[сколько?] браузеров, кроме Opera версий 12 и ниже, воспринимают BOM в середине документа как символ, занимающий целую строку, после чего генерируют перенос строки[1]. Для неразрывного пробела нулевой ширины в Юникоде есть и отдельный специальный символ — U+2060, который и рекомендуется использовать в этом качестве, а маркер последовательности байтов U+FEFF рекомендуется использовать только по своему прямому назначению. Если формат представления символов Юникода точно известен принимающей программе заранее, то по стандарту Юникода маркер ставить не следует. И если формат объявлен другим способом, маркер по стандарту ставить не полагается. Определение кодировки по маркеру последовательности байтов 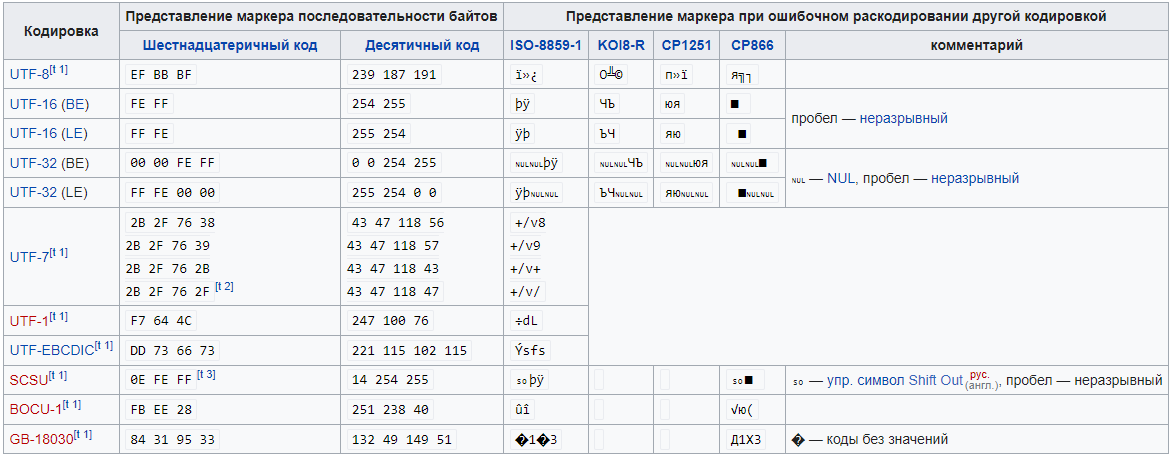 2.1.9.4 Символ перевода конца строки Перевод строки, или разрыв строки, — продолжение печати текста с новой строки, то есть с левого края на строку ниже, или уже на следующей странице. На компьютерах это осуществляется клавишей ввода Enter. Разделителем строк, обозначающим место перевода строки, в текстовых данных служит один или пара управляющих символов, а в размеченном тексте также — определённый тег (в HTML — тег , от англ. break — «разрыв»). Разделитель строк также называют просто переводом строки, когда нет надобности их различать. Вместе с другими действиями перевод строки выполняется также перед следующим абзацем или страницей. По стандарту, любое совместимое с Юникодом приложение должно воспринимать как перевод строки каждый из нижеследующих символов: LF (U+000A): англ. line feed — подача строки <ПС>; CR (U+000D): англ. carriage return — возврат каретки <ВК>; NEL (U+0085): англ. next line — переход на следующую строку; LS (U+2028): англ. line separator — разделитель строк; PS (U+2029): англ. paragraph separator — разделитель абзацев. Последовательность CR+LF (U+000D U+000A) надлежит воспринимать как один перевод строки, а не два 2.1.9.5 Другие специальные символы Знаки пунктуации 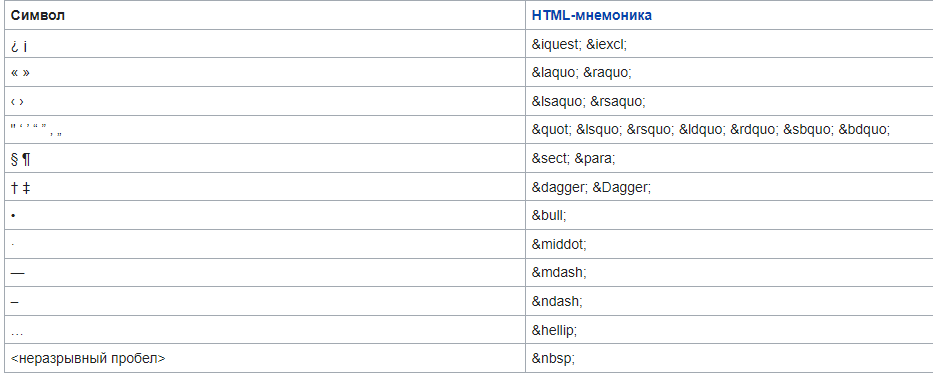 Коммерческие символы  Математические символы 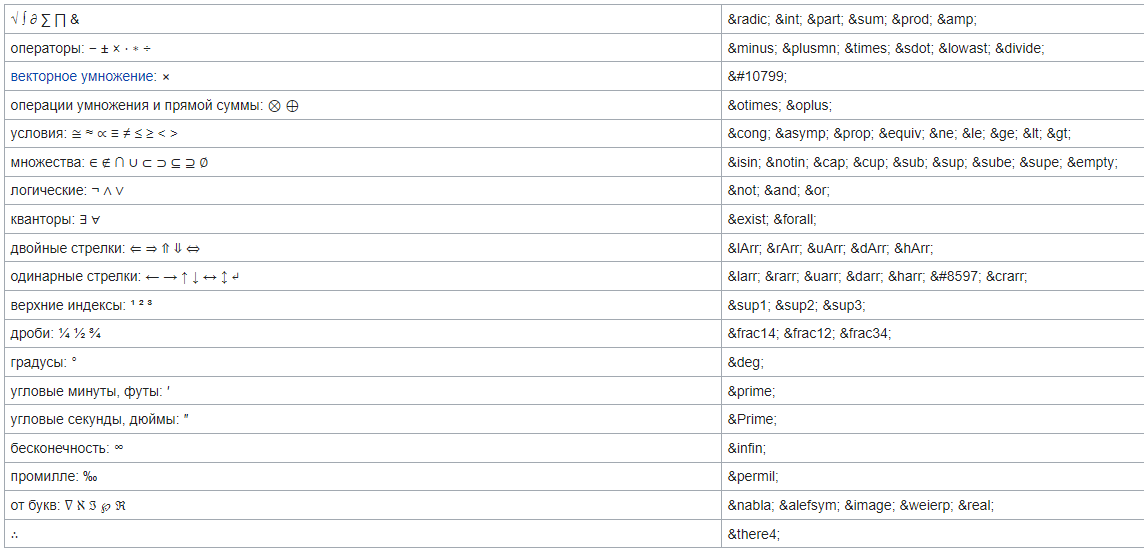 Шахматные символы Кресты (даггеры)  Другие символы 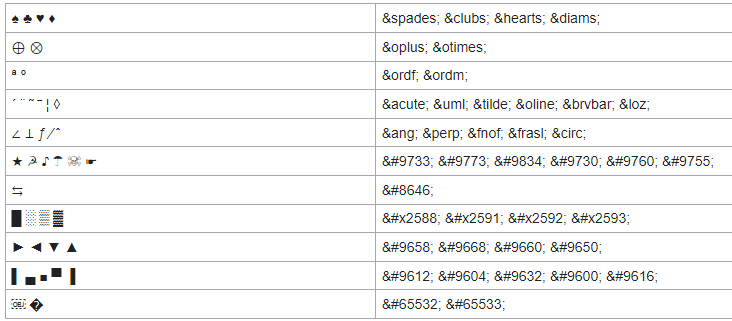 Греческие символы 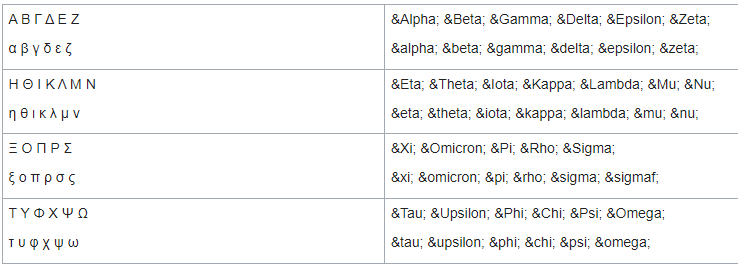 2.1.9.6 Локализация в ОС Linux Только организовать ввод и вывод символов национального языка еще недостаточно для того, чтобы можно было считать решенным проблему применения компьютеров в той или иной стране. В разных странах в силу сложившихся традиций имеются различия не только в используемом алфавите, но и в способах представления некоторых конкретных данных. Это касается, например, символов, используемых для обозначения валюты, форматов представления даты и времени, обычаев записи (чтения) текстов слева направо или справа налево и т.д. При создании ПО, рассчитанного на применение в разных странах, приходится учитывать такие местные особенности. Кроме того, большие трудности вызывают такие вопросы как проверка орфографии на конкретном языке, автоматическая расстановка переносов при вводе текста или перевод на данный язык всех меню и служебных сообщений в программном обеспечении. В стандарте POSIX (Portable Operating System) были определены средства локализации, которые состоят из следующих компонент: • набор библиотечных (libc) вызовов (locale API): setlocale(), isalpha(), toupper(), и т.д; • исходные тексты описания средств локализации, в том числе файл(ы) описания кодировки (Character Set Definition File); • наборы данных для локализации, которые в Linux размещаются в каталогах /usr/share/i18n/* и /usr/share/locale/*; • утилита для получения информации о средствах локализации: locale; • утилита для изготовления (компиляции) объектов локализации: localedef; • переменные окружения, для управления средствами локализации: LANG, LC_ALL, LC_CTYPE, LC_TIME, LC_COLLATE, LC_NUMERIC и LC_MONETARY (они соответствуют категориям локализации). 2.1.9.7 Перекодирование текстов, ошибки Перекодирование - преобразование данных из одного формата в другой. Обычно с сохранением основного логически-структурного содержания информации. В сфере компьютерных технологий есть множество вариантов представления данных. Например, компьютерное оборудование построено на основе определенных стандартов, которые требуют, чтобы данные содержали, к примеру, проверку бита четности. Точно так же операционная система утверждена по определенным стандартам касательно обработки файлов и данных. Кроме того, каждая компьютерная программа обрабатывает данные по-своему. Каждый раз, когда любая из этих переменных изменена, данные должны быть некоторым образом преобразованы прежде чем они смогут быть пригодны для использования другим компьютером, операционной системой или программой. Даже различные версии этих элементов обычно включают различные структуры данных. Например, изменение битов из одного формата в другой, обычно в целях прикладной совместимости или способности использования новых функций, является просто преобразованием данных. Преобразования данных могут быть столь же простыми как преобразование текстового файла из одной системы кодировки символов в другую или сложными, такими как преобразование офисных форматов файлов или преобразование изображения и аудио форматов файлов. Есть много путей, которые используются для преобразования данных в рамках компьютерной среды. Он может быть прямой, как в случае модернизации до более новой версии компьютерной программы. В альтернативном варианте конвертация может потребовать использование специальной конвертирующей программы или может включать сложный процесс прохождения промежуточных стадий или вовлечения сложных "экспортирующих" и "импортирующих" процессов перехода от одного формата к другому. В некоторых случаях программа может распознать несколько форматов файла на стадии ввода данных и затем также способна к хранению выходных данных во многих различных форматах. Такая программа может использоваться для конвертации формата файла. Если исходный формат или целевой формат не распознан, то порой используется третья программа, которая способна переконвертировать в промежуточный формат, который может быть переформатирован с помощью первой программы. Есть много возможных сценариев. |
