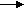Учебное пособие (Интеллектулльные информационные технологии) (ТГУ). Учебное пособие (Интеллектулльные информационные технологии) (Т. Интеллектуальные информационные технологии
 Скачать 3.62 Mb. Скачать 3.62 Mb.
|

Рис. 3.1. Обобщенная структура статической ЭСИнтерфейс пользователя – комплекс программ, реализующих диалог пользователя и ЭС как на стадии ввода информации, так и при получении результатов. Рабочая память предназначена для хранения исходных и промежуточных данных решаемой в текущий момент задачи. Решатель является программой, моделирующей ход рассуждений эксперта на основании знаний, имеющихся в БЗ. Синонимами понятия «решатель» являются дедуктивная машина, машина вывода, блок логического вывода. Используя исходные данные рабочей памяти знания из БЗ, решатель формирует такую последовательность правил, которая, будучи применима к исходным данным, приведет к решению задачи. БЗ – ядро ЭС, совокупность знаний предметной области. Подсистема объяснений – это программа, позволяющая пользователю получить ответы на вопросы: «Как была получена рекомендация? Почему система приняла такое решение?». Ответ на вопрос «Как?..» – это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ. Ответ на вопрос «Почему?..» – ссылка на умозаключение, непосредственно предшествовавшее полученному решению, то есть отход на один шаг назад. Развитие подсистемы объяснений поддерживают и другие типы вопросов. Интеллектуальный редактор БЗ – программа, представляющая инженеру по знаниям (когнитологу) возможность создавать БЗ в диалоговом режиме. Программа включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок и других сервисных средств, облегчающих работу с БЗ. Промышленные прикладные ЭС включают дополнительно БД, интерфейсы обмена данными с различными пакетами прикладных программ (ППП). ЭС может функционировать в двух режимах: режиме приобретения знаний и режиме использования. В режиме приобретения знаний эксперт, используя интеллектуальный редактор, наполняет БЗ знаниями. В режиме использования общение с ЭС осуществляет конечный пользователь, который в общем случае не является специалистом в данной проблемной области. Существуют проблемные области, требующие учитывать динамику исходных данных в процессе решения задачи (системы противовоздушной обороны, управление атомными электростанциями). Соответствующие ЭС называются динамическими (рис. 3.2) [7]. 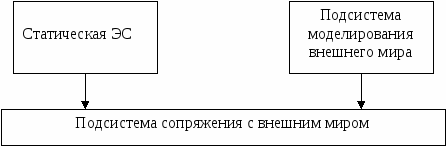 Рис. 3.2. Обобщенная структура динамической ЭСПодсистема моделирования внешнего мира необходима для анализа и адекватной оценки состояния внешней среды. Подсистема сопряжения с внешним миром осуществляет связь с внешним миром через систему датчиков и контроллеров. С целью отражения временной логики происходящих в реальном мире событий претерпевают существенные изменения БЗ и решатель. 3.2. Характеристики, стадии существования и этапы проектирования статических ЭС ЭС, как любую сложную систему, можно определить совокупностью характеристик. В основном исходят из статичности предметной области. Характеристики, определяющие ЭС [2]: - число и сложность правил, используемых в задаче. По степени сложности выделяют простые и сложные правила; - связанность правил. Малосвязанные задачи удается разбить на несколько подзадач; - пространство поиска, которое определяется размером, глубиной и широтой. Малыми считаются пространства поиска до 10! состояний. Глубина характеризуется средним числом последовательно применяемых правил, преобразующих исходные данные в конечный результат. Ширина характеризуется средним числом правил, пригодных к выполнению в текущем состоянии. По типу используемых методов и знаний ЭС подразделяются на традиционные и гибридные. Традиционные используют в основном неформализованные методы инженерии знаний и неформализованные знания, полученные от эксперта. Гибридные ЭС используют методы инженерии знаний и формализованные методы. Выделяют три поколения ЭС: - статические поверхностные, в которых знания представляются в виде правил и процесс поиска не обрывается до решения; - статические глубинные, которые обладают способностью при возникновении неизвестной ситуации определить действия, которые следует выполнить; - динамические (глубинные и гибридные). Простые ЭС являются поверхностными, традиционными, БЗ включает от 200 до 1000 правил. Сложные ЭС – это глубинные, гибридные системы с БЗ от 1500 до 10 000 правил. Стадии существования ЭС: - демонстрационный прототип – решает часть требуемых задач, БЗ содержит до 100 правил; - исследовательский прототип – решает все задачи, в работе не устойчив, БЗ содержит до 500 правил; - действующий прототип – решает все задачи , но для решения сложных задач требуется большой объем вычислительных ресурсов. БЗ содержит до 1000 правил; - промышленный образец обеспечивает высокое качество решаемых задач; - коммерческая система – предназначена для широкого распространения. Статические поверхностные ЭС предусматривают следующие этапы проектирования: - идентификация – определяются задачи, выявляются цели, ресурсы, наличие экспертов, категории пользователей; - концептуализация – содержательный анализ предметной области, выделяются используемые понятия и их взаимосвязи, определяются методы решения задач; - формализация – определяются способы представления, специфицируются выделенные ранее понятия, фиксируются способы интерпретации знаний, моделируется работа ЭС, оцениваются полученные результаты; - реализация – создание программной обстановки, в которой будет функционировать ЭС и наполнение БЗ; - тестирование – эксперт и когнитолог в интерактивном режиме, используя объяснения, проверяют компетентность ЭС. Процесс разработки промышленной ЭС можно разделить на шесть основных этапов. 1. Выбор проблемы. Данный этап предшествует решению начать разработку ЭС и предусматривает: - определение проблемной области; - нахождение экспертов и разработчиков; - определение предварительного подхода к решению подставленных задач; - анализ расходов и прибыли от разработки; - подготовку плана разработки ЭС. Задачи, подходящие для решения с помощью ЭС, являются узкоспециализированными; не являются для эксперта ни слишком легкими, ни слишком сложными; время, необходимое эксперту для решения задачи, может составлять от трех часов до трех недель; условия исполнения задачи определяются пользователем ЭС; полученные результаты можно оценить. 2. Разработка прототипной системы. Прототипная система является усеченной версией ЭС, спроектированной для проверки жизнеспособности выбранного подхода к представлению фактов, связей и стратегий рассуждений эксперта. Разработка прототипной ЭС включает стадии: - Идентификация проблемы. Уточняется задача и определяются необходимые ресурсы, источники знаний, аналогичные ЭС, цели и классы решаемых задач. Задача стадии – создание неформальной формулировки проблемы. - Извлечение знаний. Получение когнитологом наиболее полного из возможных представления о предметной области и способах принятия решения в ней. - Структурирование (концептуализация) знаний. Выявляется структура полученных знаний о предметной области, то есть определяются терминология, список основных понятий и атрибутов; отношения между понятиями; структура входной и выходной информации; стратегия принятия решений; ограничения стратегий. Задача стадии – разработка неформального описания знаний о предметной области в виде графа, таблицы, диаграммы или текста, которое отражает основные концепции и взаимосвязи между понятиями предметной области. Такое описание называется полем знаний Pz. - Формализация. Строится формализованное представление концепции предметной области на основе выбранного языка представления знаний (ЯПЗ) или специального формализма с использованием логических методов, продукционных моделей, семантических сетей, фреймов. Задача стадии – разработка БЗ. - Реализация. Создается прототип ИИС, включающий БЗ и остальные блоки (п. 2.1), при помощи одного из следующих способов: программирование на языках С++, Паскаль и др.; программирование на специализированных языках ЛИСП, ПРОЛОГ, SMALL TALK; использование инструментальных средств типа СПЭИС, ПИЭС, ART, J2; использование «пустых» ЭС GURU, ЭКСПЕРТ, ФИАКР. Задача стадии – разработка программного комплекса, демонстрирующего жизнеспособность подхода в целом. - Тестирование. Прототип проверяется на удобство и адекватность интерфейсов ввода/вывода, эффективность стратегии управления, качество проверочных примеров, корректность БЗ. Задача стадии – выявление ошибок в подходе и реализации прототипа, выработка рекомендаций по доводке системы до промышленного образца. 3. Доработка прототипа до промышленной ИИС. Основное на данном этапе заключается в добавлении большого числа дополнительных эвристик, которые увеличивают «глубину» ЭС. После установления основной структуры системы когнитолог приступает к разработке и адаптации интерфейсов, с помощью которых ЭС будет общаться с пользователем и экспертом. 4. Оценка ЭС. Оценку системы можно проводить исходя из различных критериев: критерии пользователей (понятность и «прозрачность» работы ЭС, удобство интерфейсов); критерии приглашенных экспертов (оценка советов-решений, предлагаемых системой; сравнение с собственными решениями; оценка подсистемы объяснений); критерии коллектива разработчиков (эффективность реализации, производительность, время отклика, дизайн, широта охвата предметной области, непротиворечивость БЗ, количество тупиковых ситуаций). 5. Стыковка системы. Под стыковкой понимается включение всех процедур, необходимых для успешной работы ЭС совместно с остальными системами, эксплуатируемыми в организации. 6. Поддержка системы. Поддержка ЭС предусматривает деятельность по ее совершенствованию и адаптации. При перекодировании ЭС на язык, подобный С, повышается быстродействие системы, увеличивается переносимость, однако гибкость ЭС уменьшается. Это приемлемо лишь в том случае, если ЭС сохраняют все знания проблемной области, и эти знания не будут изменяться. Однако, если ЭС создана именно из-за того, что проблемная область изменяется, то необходимо поддерживать ЭС в ее инструментальной среде разработки. Глава 4. Методы обработки знаний в интеллектуальных системах. Нечеткие знания 4.1. Интерпретатор правил и управление выводом При использовании продукционной модели представления знаний БЗ состоит из набора правил, а программа, управляющая перебором правил, называется интерпретатором правил, или машиной вывода. Интерпретатор правил – это программа, имитирующая логический вывод эксперта, пользующегося продукционной БЗ для интерпретации поступивших в систему данных [8]. Обычно он выполняет две функции:
Механизм вывода представляет собой программу, включающую два компонента, – один реализует собственно вывод, а другой управляет этим процессом. Действие компонента вывода основано на применении правила, называемого modus ponens: «Если известно, что истинно утверждение А, и существует правило вида «Если А, то В», тогда утверждение В также истинно». Таким образом, правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение. Компонент вывода должен функционировать даже при недостатке информации. Полученное решение может быть неточным, однако система не должна останавливаться из-за того, что отсутствует какая-либо часть входной информации. Управляющий компонент определяет порядок применения правил и выполняет четыре функции:
Интерпретатор правил работает циклически (рис.4.1).  Рис. 4.1. Цикл работы интерпретатора правил В каждом цикле интерпретатор правил просматривает все правила, чтобы выявить те посылки, которые совпадают с известными на данный момент фактами из БД. После выбора правило срабатывает, его заключение заносится в БД, и цикл повторяется сначала. В одном цикле может срабатывать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по определенному критерию единственного правила, которое срабатывает в данном цикле. Совокупность отобранных правил составляет конфликтное множество. Работа интерпретатора правил зависит только от состояния БД и состава БЗ. От выбранной стратегии решения зависит порядок применения и срабатывания правил. Процедура вывода сводится к определению направления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно «зашиты» в механизм вывода, поэтому в большинстве систем когнитологи не имеют к ним доступа и, следовательно, не могут в них ничего изменить по своему желанию. При разработке стратегии управления выводом важны:
В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует. Прямой вывод часто называют выводом, управляемым данными. В системах с обратным выводом вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам, пытаясь найти те, которые подтверждают гипотезу. Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями. Существуют системы, в которых вывод основывается на сочетании упомянутых методов, – обратного и ограниченного прямого. Такой комбинированный метод получил название циклического. Пример 4.1. Пусть имеется фрагмент БЗ из двух правил: П1: Если «отдых летом» и «человек активный», то «ехать в горы». П2: Если «любит солнце», то «отдых летом». Предположим, что в систему поступили факты – «человек активный» и «любит солнце». Прямой вывод Первый проход БЗ: Шаг 1. П1 не работает, поскольку не хватает данных «отдых летом». Шаг 2. П2 срабатывает, в БД поступает факт «отдых летом». Второй проход БЗ: Шаг 3. П1 срабатывает, активизируя цель «ехать в горы», которая выступает как совет, который дает ЭС. Обратный вывод Первый проход БЗ: Шаг 1. Цель – «ехать в горы»: пробуем П1-данных «отдых летом» – нет. Они становятся новой целью, и ищется правило, где она находится в правой части. Шаг 2. Цель «отдых летом»: правило П2 подтверждает цель и активизирует ее. Второй проход БЗ: Шаг 3. Правило П1 подтверждает искомую цель. В системах, БЗ которых насчитывают сотни правил, желательным является использование стратегии управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета-алгоритм. При поиске в глубину в качестве очередной подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи. При поиске в ширину вначале анализируют все факты (симптомы), находящиеся на одном уровне пространства состояний. Разбиение на подзадачи подразумевает выделение подзадач, решение которых рассматривается как достижение промежуточных целей на пути к конечной цели. Если удастся правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей-подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимален. Альфа-бета-алгоритм позволяет уменьшить пространство состояний путем удаления ветвей, не перспективных для успешного поиска. Потом просматриваются только те вершины, в которые можно попасть в результате следующего шага, после чего неперспективные направления исключаются. Данный алгоритм нашел широкое применение в системах, ориентированных на различные игры. Основным механизмом вывода в ИИС с фреймовым представлением знаний является механизм наследования. Управленческие функции механизма наследования заключаются в автоматическом поиске и определении значений слотов фреймов нижележащих уровней по значениям слотов фреймов верхних уровней, а также в запуске присоединенных процедур и демонов. Присоединенная процедура запускается по сообщению, переданному из другого фрейма. Демоны и присоединенные процедуры являются процедурными, т.е. описывающими действия знаниями, объединенными вместе с декларативными, описывающими явления знаниями в единую систему. Процедурные знания являются и средствами управления выводом во фреймовых системах, причем с их помощью можно реализовать любой механизм вывода. Возможность организации механизмов вывода является существенным преимуществом фреймовых систем по сравнению с продукционными. Однако практически реализация фреймовых систем сопряжена со значительной трудоемкостью, а их стоимость на порядок выше продукционных. Семантические сети – это общее название методов описания, использующих сети, ими же называют один из способов представления знаний. На основе сетей осуществляются выводы, однако для этого необходимы специальные алгоритмы. Поскольку семантические сети являются собирательным названием систем представления, использующих сети, нет смысла определять для них специфические алгоритмы выводов. Для каждого конкретного формализма определяются собственные правила вывода, поэтому усиливается элемент произвольности, вносимый человеком. Выводы, которые достаточно тщательно не проверены, таят в себе угрозу создания противоречий. Следовательно, в семантических сетях необходимо больше, чем в продукционных системах, уделять внимания таким обстоятельствам, как устранение противоречий. Сама система такими возможностями не обладает, и потому во многих случаях эта функция возлагается на человека. Просматривая все знания, человек способен управлять их непротиворечивостью, однако, если объем знаний будет увеличиваться, то их представление резко усложнится, чем ограничит круг решаемых проблем сравнительно небольшими проблемами [11]. 4.2. Нечеткие знания и нечеткая логика При формализации знаний существует проблема, затрудняющая использование традиционного математического аппарата. Это проблема описания понятий, оперирующих качественными характеристиками объектов (много, мало, больно). Эти характеристики обычно размыты и не могут быть однозначно интерпретированы, однако содержат важную информацию. В задачах, решаемых ИИС, часто приходится пользоваться неточными знаниями, которые не могут быть интерпретированы как полностью истинные или ложные. Существуют знания, достоверность которых выражается некоторым значением, например 07. Таким образом, возникает проблема размытости и неточности. Для разрешения таких проблем в начале 70-х годов ХХ века Лотфи Заде предложил формальный аппарат нечеткой алгебры и нечеткой логики. В последующем это направление получило название «мягкие вычисления». Л. Заде ввел одно из главных понятий в нечеткой логике – лингвистическая переменная (ЛП). ЛП – это переменная, значение которой определяется набором вербальных (словесных) характеристик некоторого свойства. Например, ЛП «рост» определяется через набор {карликовый, низкий, средний, высокий, очень высокий}. Значения ЛП определяются через нечеткие множества (НМ), которые в свою очередь определены на некотором базовом наборе значений или базовой числовой шкале, имеющей размерность. Каждое значение ЛП определяется как НМ, например «низкий рост». НМ определяется через некоторую базовую шкалу В и функцию принадлежности НМ – μ(х), х В, принимающую значения на интервале [0;1]. Таким образом, нечеткое множество А – это совокупность пар вида (х, μ(х)), где х В. Часто используется такая запись: где хi – i-е значение базовой шкалы; n – число элементов НМ. Функция принадлежности определяет субъективную степень уверенности эксперта в том, что данное конкретное значение базовой шкалы соответствует определяемому НМ. Эту функцию нельзя путать с вероятностью, носящей объективный характер и подчиняющейся определенным математическим зависимостям. Пример 4.2. Для двух экспертов определение НМ «высокая цена» для ЛП «цена автомобиля» в условных единицах может существенно отличаться в зависимости от их социального и финансового положения. «Высокая цена автомобиля 1 » = {50000/1 + 25000/0,8 + 10000/0,6 + + 5000/0,4}; «Высокая цена автомобиля 2 » = {25000/1 + 10000/0,8 + 5000/0,7 + + 3000/0,4}. Пример 4.3. Пусть необходимо решить задачу интерпретации значений ЛП «возраст», таких как «младенческий», «детский», «юный»,…, «старческий». Для ЛП «возраст» базовая шкала – это числовая шкала от 0 до 120. На рис. 4.2 отражено, как одни и те же значения В могут участвовать в определении различных НМ.  Возраст   Младенческий Детский  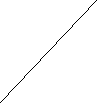 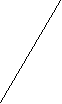 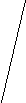 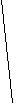      1 0,9 0,8 0,7 0,6 0,3 1 0,9 0,8 0,4 0,1
х Рис. 4.2. Формирование нечетких множеств При этом НМ определяются следующим образом: «младенческий» = «детский» = Таким образом, НМ позволяют при определении понятия учитывать субъективные мнения отдельных экспертов. Для операций с нечеткими знаниями, выраженными при помощи ЛП, существует много различных способов, которые являются в основном эвристическими и реализующими логику Заде или вероятностный подход. Усиление или ослабление лингвистических понятий достигается введением специальных квантификаторов. Для вывода на НМ используются специальные отношения и операции над ними. В настоящее время в большинство инструментальных средств разработки систем, основанных на знаниях, включены элементы работы с НМ, кроме того разработаны специальные ПС реализации нечеткого вывода, например «оболочка» Fuzzy CLIPS. Для обработки нечетких знаний используется нечеткая логика, опирающаяся на теорию Байеса. Эта теория занимается условными вероятностями и входит в качестве раздела в классическую теорию вероятности. Методика разработана на основе утверждения, что «некоторое событие произойдет, потому что раньше уже произошло другое событие». Нечеткая логика играет ту же роль, что и двузначная (булева) логика в классической теории множеств. В общем случае вместо классических истинных значений «истина» и «ложь» рассматриваются классические величины, учитывающие различные степени неопределенности. Они могут принимать целый ряд значений: «верно», «неверно», «в высшей степени верно», «не совсем верно», «более или менее верно», «не совсем ошибочно», «в высшей степени ошибочно» и т.п. Нечеткая логика имеет дело с ситуациями, когда и сформулированный вопрос и знания, которыми мы располагаем, содержат нечетко очерченные понятия. Однако нечеткость формулировки понятий является не единственным источником неопределенности, поскольку порой нет уверенности в самих фактах. Например, если утверждается: «Возможно, что студент Иванов сейчас находится на лекции по ИИС», то говорить о нечеткости понятия «студент Иванов» и «лекция по ИИС» не приходится. Неопределенность заложена в самом факте, действительно ли студент Иванов находится на лекции. Теория возможностей является одним из направления в нечеткой логике, в котором рассматриваются точно сформулированные вопросы, базирующиеся на некоторых знаниях. Пример 4.4. Пусть на занятии присутствуют 10 студентов и известно, что несколько из них готовы ответить на вопросы преподавателя. Какова вероятность того, что преподаватель вызовет отвечать того, кто готов? Обозначим искомую вероятность через Р. Просто вычислить искомое значение, основываясь на знаниях, что несколько студентов знают материал, нельзя. Согласно теории возможности определяется понятие «несколько» как НМ: «несколько» = {(3;0,2), (4;0,6), (5;1), (6;1), (7;0,6), (8;0,3)} В этом определении выражение (3;0,2) означает, что 3 из 10 вряд ли можно признать как «несколько», а выражения (5;1) и (6;1) означают, что значения 5 и 6 из 10 идеально согласуются с понятием «несколько». В определении НМ не входят значения 1 и 10, поскольку интуитивно ясно, что «несколько» означает «больше одного» и не «все». Значение 9 не внесено в НМ, потому как 9 из 10 это «почти все». Распределение возможностей для Р рассчитывается по обычной формуле» которая после подстановки дает Р = {(0,3;0,2), (0,4;0,6), (0,5;1), (0,6;1), (0,7;0,6), (0,8;0,3)} Выражение (0,3;0,2) означает: шанс на то, что Р = 0,3, составляет 20%. Р рассматривается как нечеткая вероятность. Глава 5. Теоретические основы инженерии знаний 5.1. Процедура извлечения знаний Центральным понятием на стадиях получения и структурирования знаний является «поле знаний» Pz (п. 2.1) – условное нормальное описание основных понятий и взаимосвязей между понятиями предметной области, выявленных из системы эксперта в виде текста, графа, диаграммы или таблицы. Поле знаний представляет собой модель знаний о предметной области в том виде, в каком ее сумел выразить аналитик на некотором языке L, который должен обладать свойствами [2.8]:
Учение от символах получило название «семиотика». В последнее время сложилась новая ветвь – «прикладная семиотика». Семиотика включает: синтаксис – совокупность правил построения языка или отношения между знаками; семантику – связь между элементами языка и их значениями или отношения между знаками и реальностью; прагматику – отношения между знаками и их пользователями, отражает практические разработки и использования Pz. При формировании Pz ключевым является сам процесс получения знаний, когда происходит перенос компетентности экспертов на когнитологов. Извлечение знаний – это процедура взаимодействия эксперта с когнитологом, в результате которой становятся явными процесс рассуждений специалистов при принятии решения и структура их представлений о предметной области. При построении промышленной ЭС процесс извлечения знаний является самым «узким» местом, поскольку приходится преодолевать трудности [2]: организационные неувязки; неудачный метод извлечения, не совпадающий со структурой знаний в данной области; неадекватная модель для представления знаний; неумение наладить контакт с экспертом; терминологический разнобой; отсутствие целостной системы знаний в результате извлечения только «фрагментов» знаний и т.д. Процесс извлечения знаний – это длительная и трудоемкая процедура, когда когнитологу необходимо воссоздать модель предметной области, которой пользуются эксперты для принятия решения. Приобретение знаний представляет собой процесс наполнения БЗ экспертом с использованием специализированных программных средств при прямом контакте с ЭС. Формирование знаний является процессом анализа данных и выявления скрытых закономерностей с использованием специального математического аппарата и программных средств [9]. Традиционно к задачам формирования знаний или машинного обучения относятся задачи прогнозирования, идентификации и распознавания образов. Извлечение, приобретение и формирование знаний определяют три основные стратегии получения знаний (рис. 5.1) [2].  |