Учебное пособие (Интеллектулльные информационные технологии) (ТГУ). Учебное пособие (Интеллектулльные информационные технологии) (Т. Интеллектуальные информационные технологии
 Скачать 3.62 Mb. Скачать 3.62 Mb.
|

|
Глава 10. Новые тенденции инженерии знаний, хранилища данных и управление знаниями 10.1. Методы извлечения глубинных пластов экспертного знания Большинство методов извлечения знаний не затрагивают их глубинную структуру, а отражают лишь поверхностную составляющую знаний эксперта. Для увеличения глубинных пластов экспертного знания используют методы психосемантики – науки, возникшей на стыке когнитивной психологии, психолингвистики, психологии восприятия и исследований индивидуального сознания. Психосемантика исследует структуры сознания через моделирование индивидуальной системы знаний и выявление тех структур сознания, которые могут не осознаваться (латентные, имплицитные или скрытые) [2].
В основе построения семантических пространств, как правило, лежит статистическая процедура (факторный анализ, многомерное шкалирование, кластерный анализ), позволяющая группировать ряд отдельных признаков описания в более емкие категории-факторы – построение концептов более высокого уровня абстракции. При геометрической интерпретации семантического пространства значение отдельного признака отображается как точка или вектор с заданными координатами внутри n-мерного пространства, координатами которого выступают выделенные факторы. На основе получаемых методами психосемантики моделей можно проводить контроль знаний. Контроль структуры знаний проводится на основе сопоставления семантических пространств хороших специалистов и новичков. Степень согласованности семантических пространств будет определять уровень знаний новичка. Построение семантического пространства обычно включает три этапа:
Поиск смысловых эквивалентов для выделенных структур.
В основе данного подхода лежит интерактивная процедура субъективного шкалирования. Эксперту предлагается оценить сходство между различными элементами с помощью некоторой градуированной шкалы (0÷9, -2 ÷ +2). Мера близости между двумя объектами (i, j) – dij. Если dij такова, что большие значения соответствуют наиболее похожим объектам, то dij – мера сходства, в противном случае dij – мера различия.
Введение метафор – это некая игра, которая раскрепощает сознание эксперта и, как все игровые методики извлечения знаний, является хорошим катализатором трудоемких серий интервью с экспертом. Пример метафорической классификации языков программирования – мир животных (мир транспорта). При интерпретации удалось выявить такие латентные понятия и структуры, как «степень изощренности языка», «сила», «универсальность», «скорость». Полученные результаты в виде координатных пространств позволили выявить скрытые предпочтения экспертов и существенные характеристики объектов, выступающих в виде стимулов – «сила» языка С («слон»), скорость С++ («яхта»), «старомодность» Фортрана («телега»). Среди методов когнитивной психологии – науки, изучающей то, как человек познает и воспринимает мир, других людей и самого себя, как формируется целостная система представлений и отношений конкретного человека, особое место занимает метод репертуарных решеток. Репертуарная решетка представляет собой матрицу, которая заполняется либо самим испытуемым, либо экспериментатором в процессе обследования или беседы. Столбцу матрицы соответствует определенная группа объектов (элементов). В качестве элементов могут выступать люди, предметы, понятия, звуки, цвета – все, что интересует психодиагноста. Строки матрицы конструкты. Конструкт – некоторый признак или свойство, по которому два или несколько объектов сходны между собой и, следовательно, отличны от третьего объекта или нескольких других объектов. Например, из трех элементов «диван», «кресло», «табурет» два элемента «диван», «кресло» выявляют конструкт «мягкость мебели». В процессе заполнения репертуарной решетки испытуемый должен оценить каждый элемент по каждому конструкту. Конструкты – не изолированные образования, они носят целостный характер. Элементы выбираются по определенным правилам так, чтобы они соответствовали какой-либо одной области и все вместе были связаны осмысленным образом (контекстом) аналогично репертуару ролей в пьесе. Изменяя репертуар элементов, можно «настраивать» методики на выявление конструктов разных уровней общности и относящихся к разным системам. Репертуарная решетка не всегда является матрицей в строгом смысле, так как элементы – не всегда числа, строки могут быть разной длины, матрица – непрямоугольного формата. Репертуарная решетка – это специфическая разновидность структурированного интервью. Анализ репертуарных решеток позволяет определить силу и направленность связей между конструктами респондента, выявить наиболее значимые (глубинные конструкты), лежащие в основе конкретных оценок и отношений. 10.2. Хранилища данных Для устранения разрозненности, разнотипности, противоречивости данных используется концепция «хранилище данных» (ХД). ХД – предметно-ориентированная, интегрированная, некорректируемая, зависимая от времени коллекция данных, предназначенная для поддержки принятия управленческих решений. ХД должно предложить такую среду накопления данных, которая оптимизирована для выполнения сложных аналитических запросов управленческого персонала. Данные в хранилище не предназначены для модификации. Предметная ориентация означает, что данные объединены и хранятся в соответствии с теми областями, которые они описывают. Интегрированность определяет данные таким образом, чтобы они удовлетворяли требованиям всего предприятия. Некорректируемость заключается в том, что данные в ХД не создаются (поступают из внешних источников), не корректируются и не удаляются. Данные в ХД должны быть согласованы во времени. При реализации ХД особое значение приобретают следующие процессы: извлечение, преобразование, анализ, представление. При извлечении данные приводятся к единому формату. Источники данных могут быть классифицированы по территориальному, административному расположению, степени достоверности, частоте обновляемости, количеству пользователей, секретности и используемым СУБД. Вся эта информация составляет основу словаря метаданных ХД. Словарь метаданных призван обеспечить корректную периодическую актуализацию ХД. Инструментальные средства, реализующие аналитические методы анализа и обработки данных, классифицируются по способу представления данных:
Помимо извлечения данных из БД для принятия решений актуален процесс извлечения знаний в соответствии с информационными потребностями пользователя. Если в ЭС основное внимание уделяется проблеме извлечения знаний от экспертов, то в данном случае знания извлекаются из БД. С точки зрения пользователя в процессе извлечения знаний из БД должны решаться задачи преобразования данных (неструктурированных наборов чисел, символов) в информацию (описание обнаруженных закономерностей), информации в знания (значимые для пользователя закономерности), знаний в решения (последовательность шагов, направленная на достижение информационных потребностей пользователя). Интеллектуальные средства извлечения знаний из БД позволяют выявить закономерности и вывести правила из них. Эти закономерности и правила можно использовать для принятия решений и прогнозирования их последствий. Существует несколько интеллектуальных методов выявления и анализа знаний: ассоциация, последовательность, классификация, кластеризация и прогнозирование. Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Если существует цепочка связанных во времени событий, то говорят о последовательности. С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Кластеризация аналогична классификации, но отличается от нее тем, что сами группы еще не сформированы. С помощью прогнозирования на основе особенностей поведения данных оцениваются будущие значения непрерывно изменяющихся переменных. 10.3. Управление знаниями Понятие «управление знаниями» появилось в середине 90-х годов прошлого века в крупных корпорациях, где проблемы обработки информации приобрели особую остроту. Системы управления знаниями (Knowledge Management) получили название КМ-систем. Для их применения используются технологии:
Хранилища данных, которые работают по принципу центрального склада, были одним из первых инструментариев КМ. Управление знаниями – это совокупность процессов, которые управляют созданием, распространением, обработкой и использованием знаний внутри предприятия. Причины необходимости разработки КМ-систем:
Одним из новых решений по управлению знаниями является понятие корпоративной памяти, которая фиксирует информацию из различных источников предприятия и делает ее доступной специалистам для решения производственных задач. Корпоративная память не позволяет исчезнуть знаниям выбывающих специалистов. Различают два уровня корпоративной памяти:
При разработке КМ-систем можно выделить следующие этапы:
Автоматизированные системы КМ (Organizational Memory Information Systems) OMIS предназначены для накопления и управления знаниями предприятия. Основные функции OMIS (рис. 10.1):
В отличие от ЭС первичная цель систем OMIS – не поддержка одной задачи, а лучшая эксплуатация необходимого общего ресурса знаний. Первые информационные системы на основе гипертекстовых (ГТ) моделей появились в середине 60-х годов прошлого века, но первые коммерческие ГТ-системы появились в 80-х годах. Под гипертекстом понимают технологию формирования информационных массивов в виде ассоциативных сетей, элементами или узлами которой выступают фрагменты текста, рисунки, диаграммы. Навигация по таким сетям осуществляется по связям между узлами. 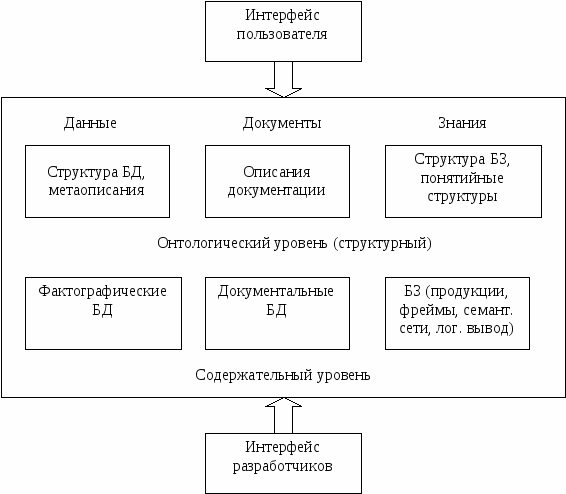 Рис. 10.1. Архитектура OMIS Основные функции связей:
Мультимедиа (ММ) понимается как интегрированная компьютерная среда, позволяющая использовать наряду с традиционными средствами взаимодействия человека и компьютера (дисплей, принтер, клавиатура) новые возможности – звук, мультипликацию, видеоролики. Когда элементы ММ объединены на основе сети гипертекста, можно говорить о гипермедиа (ГМ). Основной сферой применения ГМ являются автоматизированные обучающие системы или электронные учебники. Глобальный успех в этом направлении получила сеть Интернет. 10.4. Технология создания систем управления знаниями Проектирование систем управления знаниями (СУЗ) декомпозируется на этапы, которые свойственны любой другой ИИ-системе. Вместе с тем имеется ряд особенностей:
Этапы проектирования СУЗ:
– определение типов решаемых задач; – отбор источников знаний; – определение категорий пользователей;
– выявление понятий (категорий); – выявление свойств (отношений); – построение правил (ограничений);
– выбор метода представления знаний; – представление знаний;
– создание онтологий; – аннотирование и подключение источников знаний; – настройка (создание) приложений;
– тестирование; – развитие. Онтология – это точное (явное) описание концептуализации знаний (от греч. онтос – сущее, логос - учение) – учение о сущем. Идентификация проблемной области. В первую очередь определяется состав решаемых задач. Возможно создание узкоспециализированных систем по отдельным функциям управления: маркетинга, менеджмента, финансов. Разработка СУЗ может начинаться с отдельных областей, например с маркетинга, не требуя одновременной разработки всех необходимых онтологий и источников знаний. Для создания БЗ прецедентов требуется определить набор типовых бизнес-процессов, для которых будут отбираться прецеденты, например, разработка проектов, заключение договоров, проведение PR-акций. Центральное место в проектировании СУЗ занимает онтология, которая определяет и интегрирует все источники знаний. Требования разработки онтологий оформляются в виде спецификации требований (табл. 3) Таблица 3
Концептуализация знаний с помощью онтологий Назначение онтологий – обеспечение возможностей:
Требования к проектированию онтологий знаний:
Онтологическое знание организуется на трех уровнях: онтология верхнего уровня (метаонтология); онтология предметной области; онтология задач. Метаонтология отражает такие общие понятия, как «сущность», «класс», «свойство», «значение», «типы данных», «типы отношений», «процесс», «событие». Определение общих категорий позволяет системе контролировать синтаксические конструкции понятий предметных и проблемных областей, которые объявляются как наследники общих категорий. Онтология предметной области определяет набор понятий, используемых при решении различных интеллектуальных задач и не зависимых от самого метода решения задач. При построении онтологии предметной области выявляются свойства и отношения понятий, строятся логические правила, расширяющие семантику модели предметной области. Онтология задач имеет дело с понятиями, описывающими методы преобразования объектов предметной области в процессе решения задач. Например, для задач обучения в качестве методов обучения могут использоваться дедуктивный (от общего к частному), индуктивный (от частного к общему) и абдуктивный (от частного к частному). С помощью понятий, свойств и отношений описывается сущность используемых методов, устанавливается последовательность их выполнения. Введение онтологии задач позволяет расширить класс интеллектуальных задач, решаемых с помощью СУЗ, в частности перейти от простых поисковых задач к задаче конфигурации, когда система автоматически разбивает задачу на подзадачи, для каждой подзадачи выбирает метод решения задачи, а для каждого метода выбирает необходимые единицы предметных знаний. Такая СУЗ является не просто интеллектуальной информационно-поисковой системой, но и системой, которая планирует и генерирует решение задачи. В этом аспекте СУЗ должна обладать развитым механизмом вывода и по своей реализации сближается с классом ЭС, но на более развитой семантической основе. Формализация онтологического знания В основе формализации онтологий, с одной стороны, лежат общепризнанные методы представления знаний (исчисление предикатов, семантические сети и фреймы), с другой методы описания онтологических знаний с помощью специальных семантических конструкций. В качестве языков представления онтологического знания используются:
Языки, основанные на исчислении предикатов, построены на декларативной семантике и обеспечивают выражение произвольных логических предложений. С помощью этих языков хорошо представляется метазнание. Это позволяет пользователю представлять знания в явном виде и разрешает пользователю новые конструкции представления знаний без изменения самого языка. Одним из таких языков является KIF, разработанный для обмена знаниями между различными программными агентами (ЛИСП-подобный язык). HTML-подобные языки (Hypertext Markup Language). Язык разметки гипертекста. С использованием HTML создано более 60% ресурсов современного Интерента. Браузер – специальная клиентская программа, предназначенная для просмотра содержимого Web-узлов и отображения документов HTML. В качестве основы для описания онтологий и онтологического аннотирования текстов может выступать язык разметки данных HTML, дополненный специальными тегами (указателями). С помощью тегов происходит выделение семантических фрагментов текста, которые унифицированно интерпретируются семантическими анализаторами различных ПС. Языки данной группы позволяют описать объекты онтологии (концепты), отношения между ними и определить правила вывода. Основное назначение таких языков состоит в возможности описания онтологии, аннотирования необходимых Web-страниц концептами онтологии и дальнейшее осуществление поиска данных Web-страниц с помощью специальной поисковой машины. XML-подобные языки. В качестве основы для таких языков выступает расширяемый язык разметки. В настоящее время существует около 20 различных языков, основанных на XML. Основным достоинством языка является то, что для работы с документами, подготовленными с помощью него, достаточно обычного интернет-браузера, т.е. не требуется никаких дополнительных средств. XML-документ представляет собой размеченное дерево, например, структура XML представления описания обычного учебного курса приведена на рис. 10.2. Р 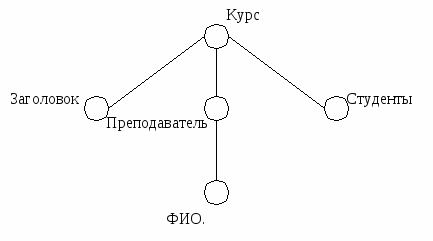 ис.10.2. Размеченное дерево Сам язык XML в принципе не обладает практически никакими возможностями в области представления онтологий. В нем отсутствуют специальные конструкции, позволяющие описать взаимоотношения между концептами онтологии, правила вывода. Он предназначен исключительно для представления данных. Язык RDF, представляющий расширение XML, позволяет описать концепты, отношения между ними, поддерживает иерархию концептов и их наследование, задает некоторые правила вывода. Базовыми строительными блоками в RDF является триплет «объект-атрибут-значение», часто записываемый в виде A (O, V), который читается как объект О, имеет атрибут А со значением V. В семантической сети эту связь можно представить как ребро с меткой А, соединяющее два узла О и V. Выбор ИС реализации СУЗ во многом определяется требуемой функциональностью использования СУЗ: информационный поиск в источниках знаний, коллективное решение задач, обучение и др. Для узкоспециализированных целей, ориентированных на поиск в интернет- ресурсах, используются специализированные системы, например SHOE, которая обеспечивает аннотацию документов, сбор знаний в централизованную БЗ, выполнение поисковых запросов. ИС должны обеспечивать две основные группы функций.
– создание и поддержание онтологий; – аннотирование источников знаний; – подключение источников знаний; – автоматическая рубрикация и индексирование источников знаний;
– реализация запросов; – навигация и просмотр; – коммуникация пользователей; – распространение знаний. Глава 11. Интеллектуальные информационные системы в условиях неопределенности и риска 11.1. Понятие риска в СППР слабоструктурированных проблем Экономические решения в зависимости от определенности возможных исходов или последствий рассматриваются в рамках трех моделей:
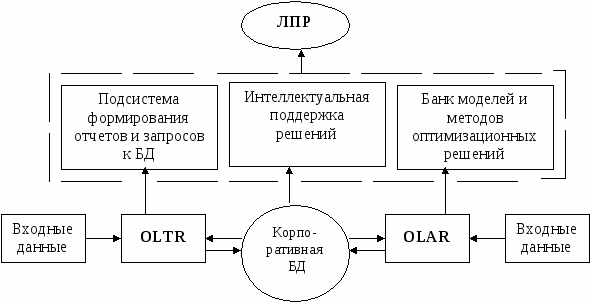
Вероятностные методы обеспечивают подходящие условия для принятия решения и содержательные гарантии качества выбора. При этом исходят из предположения, что суждения относительно значений, предпочтений и намерений представляют ценные абстракции человеческого опыта и их можно обрабатывать для принятия решений. В то время как суждения относительно правдоподобия событий квалифицируются вероятностями, суждения относительно желательности действий представляются понятиями. Байесовская методология рассматривает ожидаемую полезность U(d) как оценку качества решения d. В соответствии с этим, если мы можем выбрать либо действие d1, либо d2, вычисляем U(d1), U(d2) и выбираем действие, которое соответствует наибольшему значению. Семантика полезности состоит в том, чтобы описать риск. Под риском принято понимать вероятность (угрозу) утраты лицом или организацией части своих ресурсов, недополучения доходов или появление дополнительных расходов в результате осуществления определенной финансовой политики. Под уровнем риска понимается объективная или субъективная вероятность возникновения потерь. Объективная – это количественная мера возможности наступления случайного события, полученная с помощью расчетов или опыта, позволяющая оценить вероятность выявления данного события. Субъективная представляет собой меру уверенности и истинности высказанного суждения и устанавливается экспертным путем. Уровень рисков наиболее легко устанавливается при помощи атрибутивных оценок типа «высокий», «средний», «небольшой». Разновидностью атрибутивной оценки рисков является буквенная кодировка. При этом в порядке нарастания риска и падения надежности используются латинские буквы от А до D. AAA – самая высокая надежность; AA – очень высокая надежность; A – высокая надежность; D – максимальный риск. Оценивать уровень риска можно, используя показатели бухгалтерской и статистической отчетности. Из всех возможных показателей лучше всего для этой цели подходит коэффициент текущей ликвидности (КТЛ) – отношение ликвидных средств партнера к его долгам, который отвечает на вопрос, сможет ли партнер покрыть долги своими активными ликвидными активами. В результате анализа ситуации строятся причинно-следственные диаграммы («дерево причин») и диаграммы зависимостей. Причинно-следственная диаграмма является формальным отображением структуры проблемной ситуации в виде иерархически незамкнутого графа, вершины которого соответствуют элементам проблемы, отражающим причины ее возникновения, а дуги – связям между ними. Связь элементов-подпроблем отображается в виде отношения «причина – следствие» (рис. 11.1). OLTR – средства складирования данных и оперативной обработки транзакций; OLAR – средства оперативной обработки информации. Корпоративная БД, организованная в виде хранилища данных, заполняется информацией с использованием технологий OLTR и OLAR. Для разработки и реализации СППР слабоструктурированных проблем должны быть разработаны и адаптированы к ее условиям следующие методы и средства:
 |