большие данные и нейронные сети. лаб 1. Искусственный интеллект и нейронные сети прочно вошли в нашу жизнь, но как они взаимосвязаны с большими данными
 Скачать 199.41 Kb. Скачать 199.41 Kb.
|

ВведениеВот если вы хоть немного, хоть косвенно прикасаетесь к миру ИТ или общаетесь с программистами, то вы точно хотя бы раз слышали «нейронные сети», «большие данные или Big Data». данных ». В мире, где технологии быстро развиваются и информация также быстро обновляется, трудно не быть знакомым с ИТ- технологиями. В наших реалиях — когда данных с каждым годом становится все больше — необходимо меняться и адаптироваться ко всему новому, ведь если ты не изменишься, то мир просто побежит вперед, оставив тебя позади, никогда не оборачиваясь. Если говорить о техническом мире, то вышеперечисленные понятия звучат не первый год и даже не первое десятилетие. Если говорить о том, как люди пришли к идее создания того, что сейчас пытается сделать каждый начинающий и самоуверенный программист, то мы будем весьма удивлены, ведь еще в Древней Греции, еще в древности, философы спорили, как искусственно механизировать человеческое мышление и управлять им с помощью разумных «нечеловеческих» машин. Когда классические философы, математики и логики рассмотрели возможность манипулирования символами (механически) и привели к изобретению в 1940-х годах программируемого цифрового компьютера, компьютера Атанасова - Берри (АВС), все это вдохновило ученых на продвижение идеи создания «электронный мозг» или существа с искусственным интеллектом. Если вы посмотрите, сколько информации и данных в мире, то увидите, как быстро эта цифра растет. По данным IDC, до 60% корпоративных хранилищ занимает информация, не приносящая никакой пользы организации (информация, к которой никто не обращался, несколько отсутствует и вряд ли будет когда-либо доступна ; прочий «корпоративный мусор»). Искусственный интеллект и нейронные сети прочно вошли в нашу жизнь, но как они взаимосвязаны с большими данными? ИсторияКак я уже говорил ранее, идея искусственной механизации человеческого мышления и управления им с помощью разумных «нечеловеческих» машин зародилась очень давно, еще в глубокой древности. Программируемый цифровой компьютер был создан в 1940 году, а в 1956 году во время летней конференции (это была даже не конференция, а скорее посевная ) в Дартмутском колледже был введен термин «искусственный интеллект». С середины 20 века многие ученые, математики, программисты, логики и теоретики внесли свой вклад в укрепление современного понимания искусственного интеллекта в целом. Период между 1940 и 1960 годами можно считать рождением ИИ на волне кибернетики, так как он (период) отмечен сочетанием технического прогресса и стремлением понять, как совместить работу машин и органических существ. Первая математическая и компьютерная модель биологического нейрона (формального нейрона) была разработана Уорреном МакКаллохом и Уолтером Питтс в 1943 году. В начале 1950-х годов Джон фон Нейман и Алан Тьюринг еще не придумали термин ИИ, но были отцами-основателями лежащей в его основе технологии: они перешли от компьютеров с десятичной логикой XIX века к машине с двоичной логикой. Тьюринг также впервые поднял вопрос о возможном интеллекте машины в своей знаменитой статье 1950 года «Вычислительные машины и интеллект» и описал «игру в имитацию», где человек должен уметь различать в телетайпном диалоге, говорит ли он с человеком или машина. Герберт Саймон , экономист и социолог, предсказал в 1957 году, что ИИ сможет обыгрывать людей в шахматы в ближайшие 10 лет, но затем ИИ вступил в период стагнации развития и видение подтвердилось лишь 30 лет спустя. Период с 1970 по 1980 год можно считать периодом повышенного интереса к ИИ. Так, в 1968 году был снят фильм «Космическая одиссея 2001», в котором компьютер HAL 9000 демонстрирует перед ИИ сумму этических вопросов. Воздействие фильма помогло популяризировать тему ИИ, и после появления первых микропроцессоров в конце 1970-х годов эта тема снова набрала обороты и открыла золотой век экспертных систем. Путь вверх был открыт в Массачусетском технологическом институте в 1965 году с DENDRAL , экспертной системой, специализирующейся на молекулярной химии, и в Стэнфордском университете в 1972 году с MYCIN , системой, специализирующейся на диагностике заболеваний крови и отпускаемых по рецепту лекарств. Эти системы были основаны на «механизме логического вывода», который был запрограммирован как логическое отражение человеческого мышления. В 1971 г. В.Н. Вапник и А.Я. Червоненкис обосновал сходимость методов обучения на основе минимизации эмпирического риска, что позволяет получить оценку скорости сходимости алгоритмов машинного обучения. Методы решения этой задачи называются методами минимизации структурного риска, в настоящее время они широко используются в задачах распознавания образов, восстановления регрессионных зависимостей и при решении обратных задач физики, статистики и других научных дисциплин. В 1974 году произошло знаменательное событие, А. И. Галушкин первым описал метод обратного распространения ошибки — итерационный градиентный алгоритм, который используется для обновления весов многослойного персептрона с целью минимизации ошибки и получения желаемого результата. В конце 1980-х — начале 1990-х повальное увлечение снова прекратилось, так как программирование таких знаний требовало больших усилий, а при программировании 200-300 правил возникал эффект «черного ящика»: непонятно, как рассуждала машина. В 1990-е годы термин «искусственный интеллект» стал почти «табу». В мае 1997 года в шахматной партии с Гарри Каспаровым Deep Синий IBM исполнила пророчество Герберта Саймона в 1957 году, но это не привело к ожидаемому увеличению финансирования и дальнейшему развитию. С 2010 года начался новый бум, основанный на больших данных и новых вычислительных мощностях. Новый бум объясняется двумя факторами: Доступ к огромным объемам памяти. Например, для того, чтобы иметь возможность использовать алгоритмы классификации изображений и распознавания кошек, ранее требовалось самостоятельно проводить долгий процесс ручной выборки. Сегодня простой поиск в Google позволяет найти миллионы изображений по запросу за долю секунды. Открытие очень высокой эффективности процессоров компьютерных видеокарт для ускорения расчета алгоритмов обучения. Этот процесс очень итеративный, и до 2010 года обработка всей выборки могла занимать несколько недель. Вычислительная мощность видеокарт (более тысячи миллиардов транзакций в секунду) позволила добиться значительного прогресса при ограниченных финансовых затратах (менее 1000 евро на видеокарту). В 2012 году Гугл X заставил ИИ распознавать кошек в видео, в 2016 году AlphaGo победила чемпиона Европы (Fang Hui ) и чемпиона мира (Lee Sedol ) в игре Го . На сегодняшний день реалистичность генерируемых изображений достигла высокого уровня, этот результат во многом обусловлен успехами алгоритмов GAN ( Generative враждебный сеть ). Лучшие результаты показали решения BigGan от Google и vid 2 vid от NVidia . Это открыло возможность создания графических редакторов, генерирующих реалистичные изображения, и так называемого « глубокого фейк » — фальшивые видео или изображения, которые «трудно» отличить от оригиналов, что в свою очередь стало серьезным вызовом для новой дисциплины — киберкриминалистики. Модели в области обработки естественного языка также достигли высокого уровня — благодаря к алгоритмам ELMo , BERT , XLNet , GPT Модели обыграли лучших игроков в сложных играх -- модель DeepMind обыграла двух профессиональных игроков в StarCraft со счетом 10-1 . Системы ИИ для распознавания изображений получают регистрационные удостоверения на медицинские изделия, что позволяет использовать их в клинических процессах наравне с другими, но уже более привычными медицинскими изделиями. Нейронные сети в ИИВ публикациях можно найти множество вариантов классификации алгоритмов машинного обучения и ИИ: На основе решаемых математических задач - регрессия, классификация и кластеризация. Исходя из решаемых практических задач, наиболее популярными являются кластеризация (обучение без учителя), классификация (обучение с учителем) и игра (обучение с подкреплением). По функциональным свойствам. Классификации, сделанные без какого-либо явного критерия, являются самой популярной категорией. На рисунке 1 мы можем видеть визуализацию классификации ИИ . 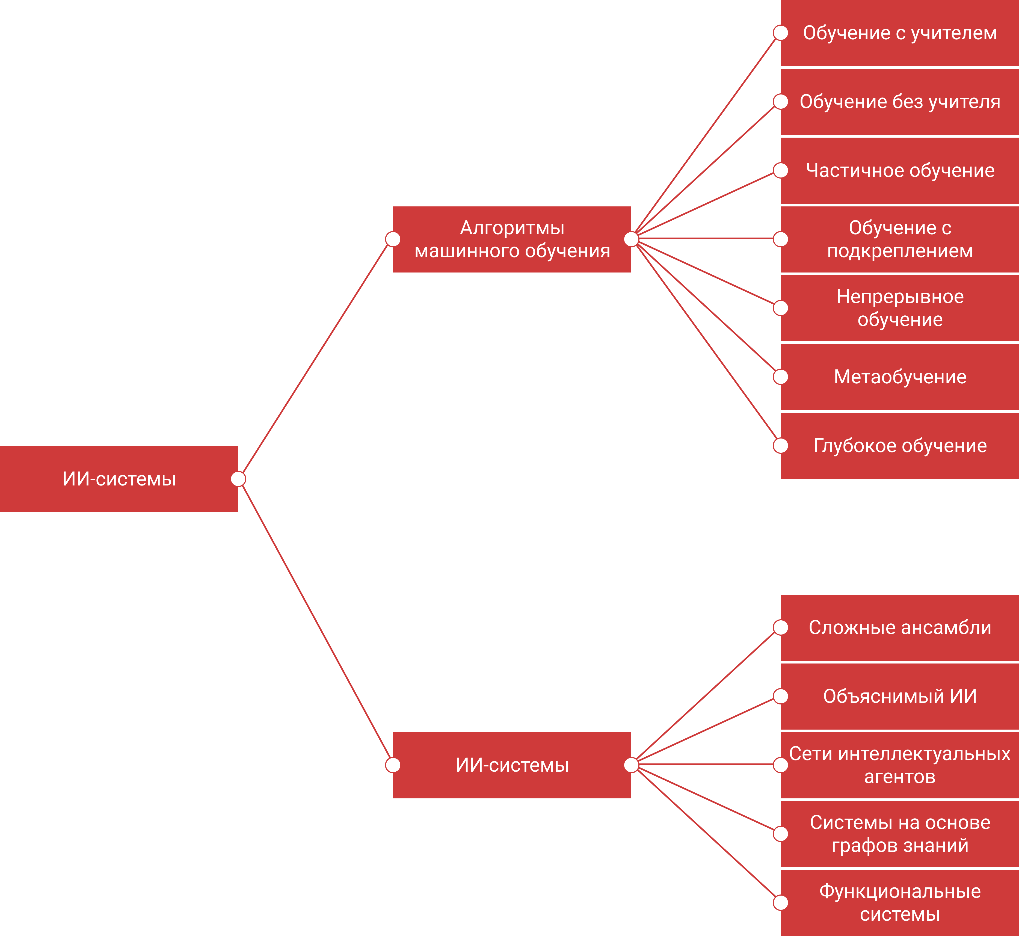 Рисунок 1 – Классификация ИИ Мы видим, что многое взаимосвязано и часто пересекается. На рис. 2 показано место глубокого обучения в машинном обучении. 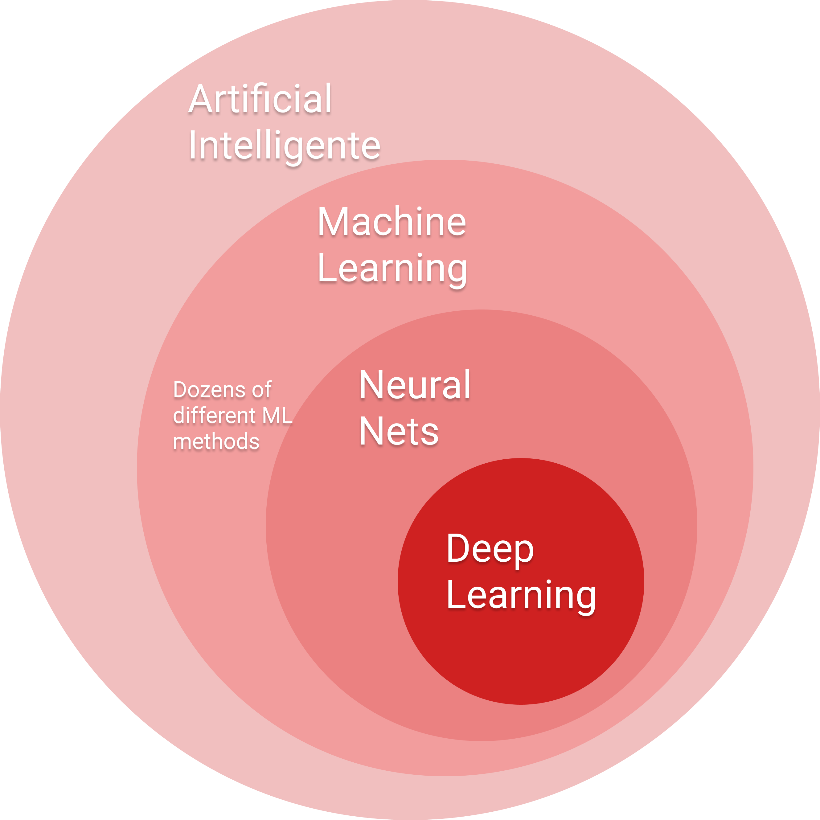 Рисунок 2 – Место глубокого обучения в машинном обучении |