Архитектура ЭВМ и систем (конспект лекций). Конспект лекций
 Скачать 1.14 Mb. Скачать 1.14 Mb.
|

Направления развития суперскалярной архитектурыКак уже отмечалось ранее, в суперскалярных процессорах предпринимается попытка в рамках модели последовательных программ реализовать параллельное исполнение команд этих программ. После извлечения последовательного потока команд между командами устанавливаются только действительно необходимые зависимости по данным. При этом сохраняется достаточно информации о порядке следования команд в исходной программе, чтобы сохранить их порядок при наступлении прерывания. Типичный суперскалярный процессор выбирает команды и исследует их по мере выполнения. Исследование проводится с целью выявления и обработки команд перехода, идентификации типа команды для ее дальнейшего направления на соответствующий исполнительный блок или в буфер памяти. Выполняются также некоторые действия для смягчения зависимостей по данным, например переименование регистров. VLIW процессор возлагает на компилятор статическую реализацию тех функций, которые в суперскалярном процессоре выполняются динамически. По крайней мере два обстоятельства ограничивают эффективность использования суперскалярных архитектур. Во-первых, есть ограничения на степень параллелизма на уровне команд, даже если применяется самая совершенная техника суперскалярных вычислений. Первое ограничение проистекает из условных переходов. Другое следует из того, что размер окна исполнения (число активных команд, могущих исполняться параллельно) ограничивает возможный присущий программе параллелизм, так как не рассматривается параллельное исполнение команд, находящихся на расстоянии, превышающем размер окна. 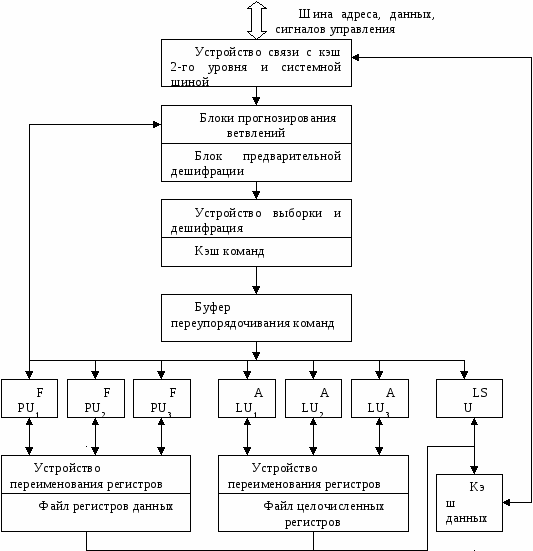 Структура суперскалярного микропроцессора Во-вторых, сложность суперскалярного процессора возрастает как количество параллельно исполняемых команд и даже быстрее. Вероятнее всего, что пределом распараллеливания при суперскалярной обработке является запуск одновременно на исполнение в каждом такте 7-8 команд. Альтернатива суперскалярной обработке - длинное командное слово (VLIW). Использование этого метода предполагает задание в командном слове совокупности параллельно выполняемых команд. Подготовкой таких программ занимается компилятор. Достоинства VLIW заключаются в следующем. Во-первых, компилятор может более эффектно исследовать зависимости между командами и выбирать параллельно исполняемые команды, чем это делает аппаратура суперскалярного процессора, ограниченная размером окна исполнения. Во-вторых, VLIW процессор имеет более простое устройство управления и потенциально может иметь более высокую тактовую частоту. Однако у VLIW процессоров есть серьезный фактор, снижающий их производительность. Это команды ветвления, зависящие от данных, значения которых становятся известны только в динамике вычислений. Окно исполнения VLIW-процессора, не может быть очень большим в виду отсутствия у компилятора информации о зависимостях, формируемых динамически, в процессе выполнения. Этот недостаток препятствует возможности переупорядочивания операций в VLIW процессоре. Например, статически не может быть гарантировано правильное выполнение операции загрузки в вызываемой функции параллельно с операцией запоминания в вызывающей функции (особенно, если вызываемая функция определена динамически). Кроме того, VLIW реализация требует большого размера памяти имен, многовходовых регистровых файлов, большого числа перекрестных связей. Возможен также останов, когда во время выполнения возникла ситуация, отличающаяся от состояния в момент генерации плана выполнения (например, во время выполнения произошло неудачное обращение в кэш). Другим возможным подходом служит переход к мультипроцессорному исполнению, когда вводится несколько счетчиков команд. В этом случае речь идет о распараллеливающих компиляторах с языков высокого уровня. Таким образом, суперскалярные микропроцессоры являются лидирующим продуктом микроэлектроники, и их производительность постоянно растет, но при использовании этих процессоров необходимо тщательно исследовать архитектурные приемы получения высокой производительности и проверять адекватность этих приемов проблемной области, для решения задач которой создается вычислительная система. Дальнейшее повышение производительности микропроцессоров связывается в настоящее время со статическим и динамическим анализом кода с целью выявления резервов параллелизма уровня отдельных команд и программных сегментов с использованием информации, предоставляемой компилятором языка высокого уровня Исследования в данном направлении привели к разработке мультискалярной архитектуры процессоров, которые являются дальнейшим развитием суперскалярной архитектуры В настоящее время работы в данном направлении находятся на стадии теоретического исследования и имитационного моделирования, однако, по видимому, уже в скором времени следует ожидать появления первых микропроцессоров, в полной мере использующих все преимущества, предоставляемые мультискалярной архитектурой. Поэтому основные моменты, связанные с данной архитектурой, будут рассмотрены ниже достаточно подробно. 9.16. Принципы организации системы прерывания программ Во время выполнения ЭВМ текущей программы внутри машины и в связанной с ней внешней среде (например, в технологическом процессе, управляемом ЭВМ) могут возникать события, требующие немедленной реакции на них со стороны машины. Реакция состоит в том, что машина прерывает обработку текущей программы и переходит к выполнению некоторой другой программы, специально предназначенной для данного события. По завершении этой программы ЭВМ возвращается к выполнению прерванной программы. Рассматриваемый процесс, называемый прерыванием программ, поясняется на рис. 9.23. Принципиально важным является то, что моменты возникновения событий, требующих прерывания программ, заранее неизвестны и поэтому не могут быть учтены при программировании. Каждое событие, требующее прерывания, сопровождается сигналом, оповещающим ЭВМ. Назовем эти сигналы запросами прерывания. Программу, затребованную запросом прерывания, назовем прерывающей программой, противопоставляя ее прерываемой программе, выполнявшейся машиной до появления запроса. З 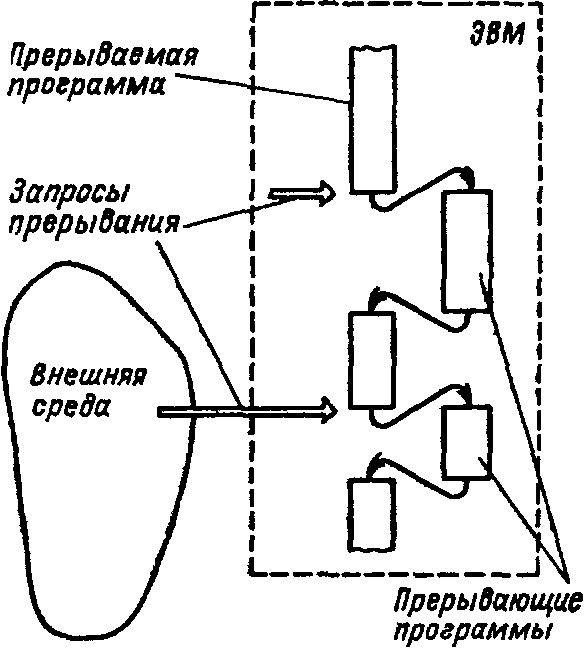 Рис. 9.23. Прерывание программы апросы на прерывания могут возникать внутри самой ЭВМ и в ее внешней среде. К первым относятся, например, запросы при возникновении в ЭВМ таких событий, как появление ошибки в работе ее аппаратуры, переполнение разрядной сетки, попытка деления на 0, выход из установленной для данной программы области памяти, затребование периферийным устройством операции ввода-вывода, завершение операции ввода-вывода периферийным устройством или возникновение при этой операции особой ситуации и др.. Хотя некоторые из указанных событий порождаются самой программой, моменты их появления, как правило, невозможно предусмотреть. Запросы во внешней среде могут возникать от других ЭВМ, от аварийных и некоторых других датчиков технологического процесса и т. п. В сущности, запросы прерывания генерируются несколькими развивающимися параллельно во времени процессами, которые в некоторые моменты требуют вмешательства процессора. К этим процессам, в частности, относятся процесс выполнения самой программы, процесс контроля правильности работы ЭВМ, операции ввода-вывода, технологический процесс в управляемом машиной объекте и др. Возможность прерывания программ - важное архитектурное свойство ЭВМ, позволяющее эффективно использовать производительность процессора при наличии нескольких протекающих параллельно во времени процессов, требующих в произвольные моменты времени управления и обслуживания со стороны процессора. В первую очередь это относится к организации параллельной во времени работы процессора и периферийных устройств машины, а также к использованию ЭВМ для управления в реальном времени технологическими процессами. В некоторых машинах наряду или вместо прерывания с переключением управления на другую программу используется примитивное прерывание - так называемая приостановка, когда по соответствующему запросу приостанавливается выполнение программы и выполняется аппаратурными средствами некоторая процедура без изменения содержания счетчика команд, а по ее окончании продолжается выполнение приостановленной программы. Чтобы ЭВМ могла, не требуя больших усилии от программиста, реализовывать с высоким быстродействием прерывания программ, машине необходимо придать соответствующие аппаратурные и программные средства, совокупность которых получила название системы прерывания программ или контроллера прерывания. Основными функциями системы прерывания являются:
П 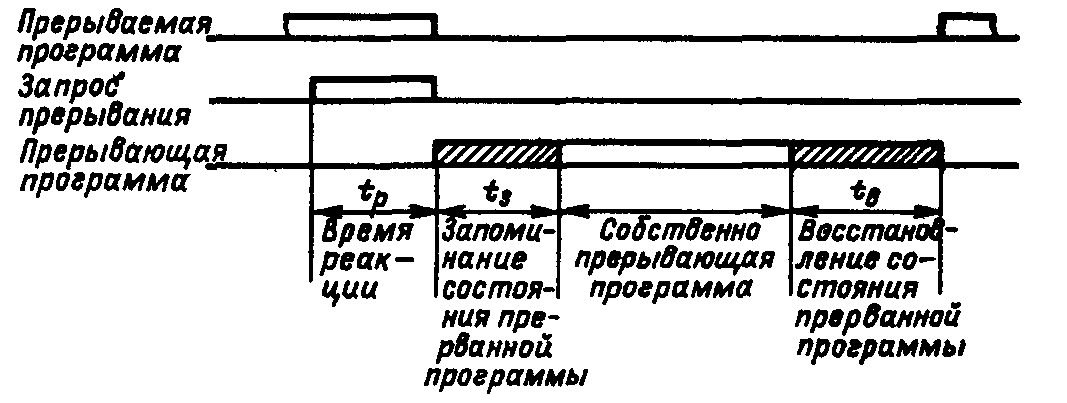 Рис. 924. Упрощенная временная диаграмма процесса прерывания ри наличии нескольких источников запросов прерывания должен быть установлен определенный порядок (дисциплина) в обслуживании поступающих запросов. Другими словами, между запросами (и соответствующими прерывающими программами) должны быть установлены приоритетные соотношения, определяющие, какой из нескольких поступивших запросов подлежит обработке в первую очередь, и устанавливающие, имеет право или не имеет данный запрос (прерывающая программа) прерывать ту или иную программу. Приоритетный выбор запроса для исполнения входит в процедуру перехода к прерывающей программе. Характеристики системы прерывания. Для оценки эффективности систем прерывания могут быть использованы следующие характеристики. Общее число запросов прерывания (входов в систему прерывания). Время реакции - время между появлением запроса прерывания и началом выполнения прерывающей программы На рис. 9.24 приведена упрощенная временная диаграмма процесса прерывания в предположении, что управление запоминанием состояния и возвратом возложено на саму прерывающую программу, которая в этом случае состоит из трех частей: подготовительной и заключительной, обеспечивающих переключение программ, и собственно прерывающей программы, выполняющей затребованную запросом работу. Для одного и того же запроса задержки в исполнении прерывающей программы зависят от того, сколько программ со старшим приоритетом ждут обслуживания. Поэтому время реакции определяют для запроса с наивысшим приоритетом. Время реакции зависит от того, в какой момент допустимо прерывание. Большей частью прерывание допускается после окончания текущей команды. В этом случае время реакции определяется в основном длительностью выполнения команды. Это время реакции может оказаться недопустимо большим для ЭВМ, предназначенных для работы в реальном масштабе времени. В таких машинах часто допускается прерывание после любого такта выполнения команды. Однако при этом возрастает количество информации, подлежащей запоминанию и восстановлению при переключении программ, так как в этом случае необходимо сохранять также и состояния в момент прерывания счетчика тактов, регистра кода операции и некоторых других. Поэтому такая организация прерывания возможна только в машинах с быстродействующей сверхоперативной памятью. И 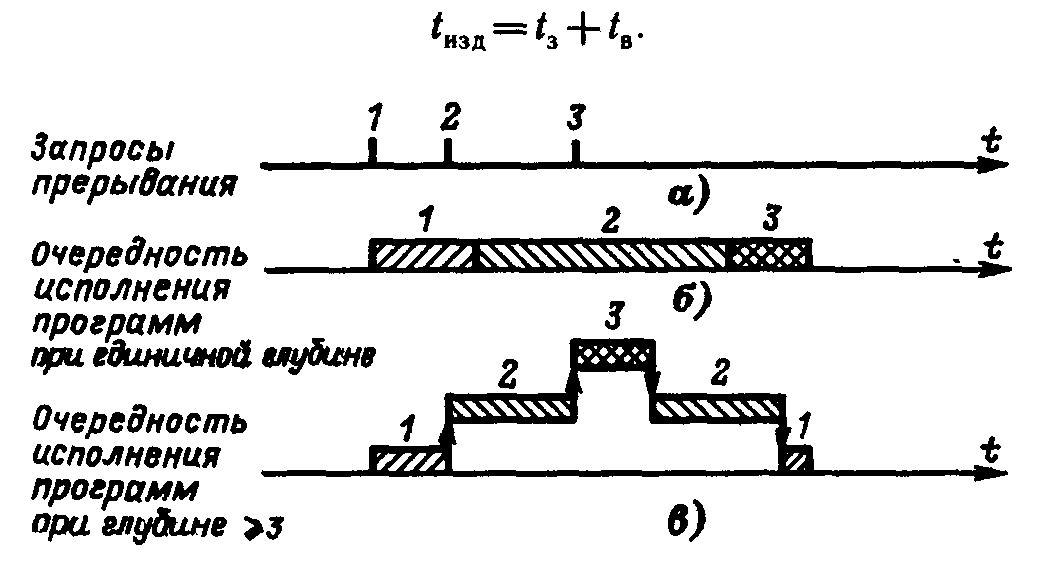 Рис 9 25 Прерывание в системах с различной глубиной прерывания меются ситуации, в которых желательно немедленное прерывание. Если аппаратура контроля обнаружила ошибку, то целесообразно сразу же прервать операцию, пока ошибка не оказала влияния на следующие такты работы машины. Затраты времени на переключение программ (издержки прерывания) равны суммарному расходу времени на запоминание и восстановление состояния программы: Глубина прерывания — максимальное число программ, которые могут прерывать друг друга. Если после перехода к прерывающей программе и вплоть до ее окончания прием других запросов запрещается, то говорят, что система имеет глубину прерывания, равную 1. Глубина равна n, если допускается последовательное прерывание до п программ. Глубина прерывания обычно совпадает с числом уровней приоритета в системе прерывании. На Рис. 9.25, а—в показано прерывание в системах с различной глубиной прерывания (предполагается, что приоритет каждого следующего запроса выше предыдущего). Системы с большим значением глубины прерывания обеспечивают более быструю реакцию на срочные запросы. Если запрос окажется необслуженным к моменту прихода нового запроса от того же источника, то возникнет так называемое насыщение системы прерывания. В этом случае предыдущий запрос прерывания от данного источника будет машиной утрачен, что недопустимо. Быстродействие ЭВМ, характеристики системы прерывания, число источников прерывания и частота возникновения запросов должны быть согласованы таким образом, чтобы насыщение было невозможным. Количество уровней прерывания. В ЭВМ число различных запросов прерывания может достигать нескольких десятков или сотен. В таких случаях часто запросы разделяют на отдельные классы или уровни. Совокупность запросов, инициирующих одну и ту же прерывающую программу, образует класс или уровень прерывания (рис 926). З 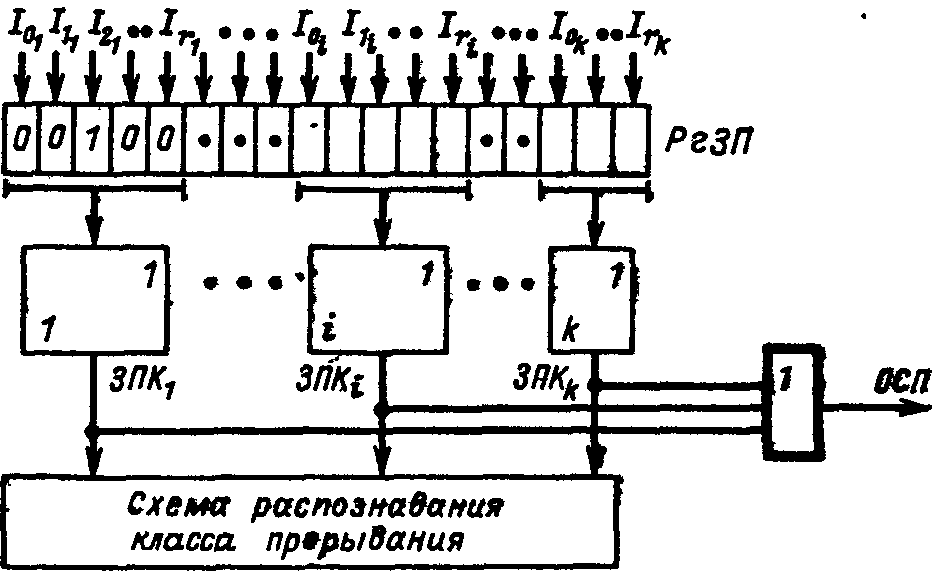 Рис. 9.26. Разделение запросов на классы прерывания апросы всех источников прерывания поступают на регистр запросов прерывания РгЗП, устанавливая соответствующие его разряды (флажки) в состояние 1, указывающее на наличие запроса прерывания определенного источника. Запросы классов прерывания ЗПК1 — ЗПКk формируются элементами ИЛИ, объединяющими разряды РгЗП, относящиеся к соответствующим классам (уровням). Еще одна схема ИЛИ формирует общий сигнал прерывания ОСП, поступающий в устройство управления процессора. Значение сигнала ОСП определяется выражением Информация о действительной причине прерывания, породившей запрос данного класса, содержится в коде прерывания, который отражает состояние разрядов РгЗП, относящихся к данному классу прерывания. После принятия запроса прерывания на исполнение и передачи управления прерывающей программе соответствующий триггер РгЗП сбрасывается. Объединение запросов в классы прерывания позволяет уменьшить объем аппаратуры, но связано с замедлением работы системы прерывания. Организация перехода к. прерывающей программе. Приоритетное обслуживание запросов прерывания. Назовем вектором прерывания вектор начального состояния прерывающей программы. Вектор прерывания содержит всю необходимую информацию для перехода к прерывающей программе, в том числе ее начальный адрес. Каждому запросу (уровню) прерывания, а в ряде случаев, например в малых и микроЭВМ и микропроцессорах, каждому периферийному устройству соответствует свой вектор прерывания, способный инициировать выполнение соответствующей прерывающей программы. Векторы прерывания обычно находятся в специально выделенных фиксированных ячейках памяти. Главное место в процедуре перехода к прерывающей программе занимают передача из соответствующего регистра (регистров) процессора в память (в частности, в стек) на сохранение текущего вектора состояния прерываемой программы (чтобы можно было вернуться к ее исполнению) и загрузка в регистр (регистры) процессора вектора прерывания прерывающей программы, к которой при этом переходит управление процессором. Процедура организации перехода к прерывающей программе включает в себя выделение из выставленных запросов такого, который имеет наибольший приоритет. Различают абсолютный и, относительный приоритеты. Запрос, имеющий абсолютный приоритет, прерывает выполняемую программу и инициирует выполнение соответствующей прерывающей программы. Запрос с относительным приоритетом является первым кандидатом на обслуживание после завершения выполнения текущей программы. Если наиболее приоритетный из выставленных запросов прерывания не превосходит по уровню приоритета выполняемую процессором программу, то запрос прерывания игнорируется или его обслуживание откладывается до завершения выполнения текущей программы. П 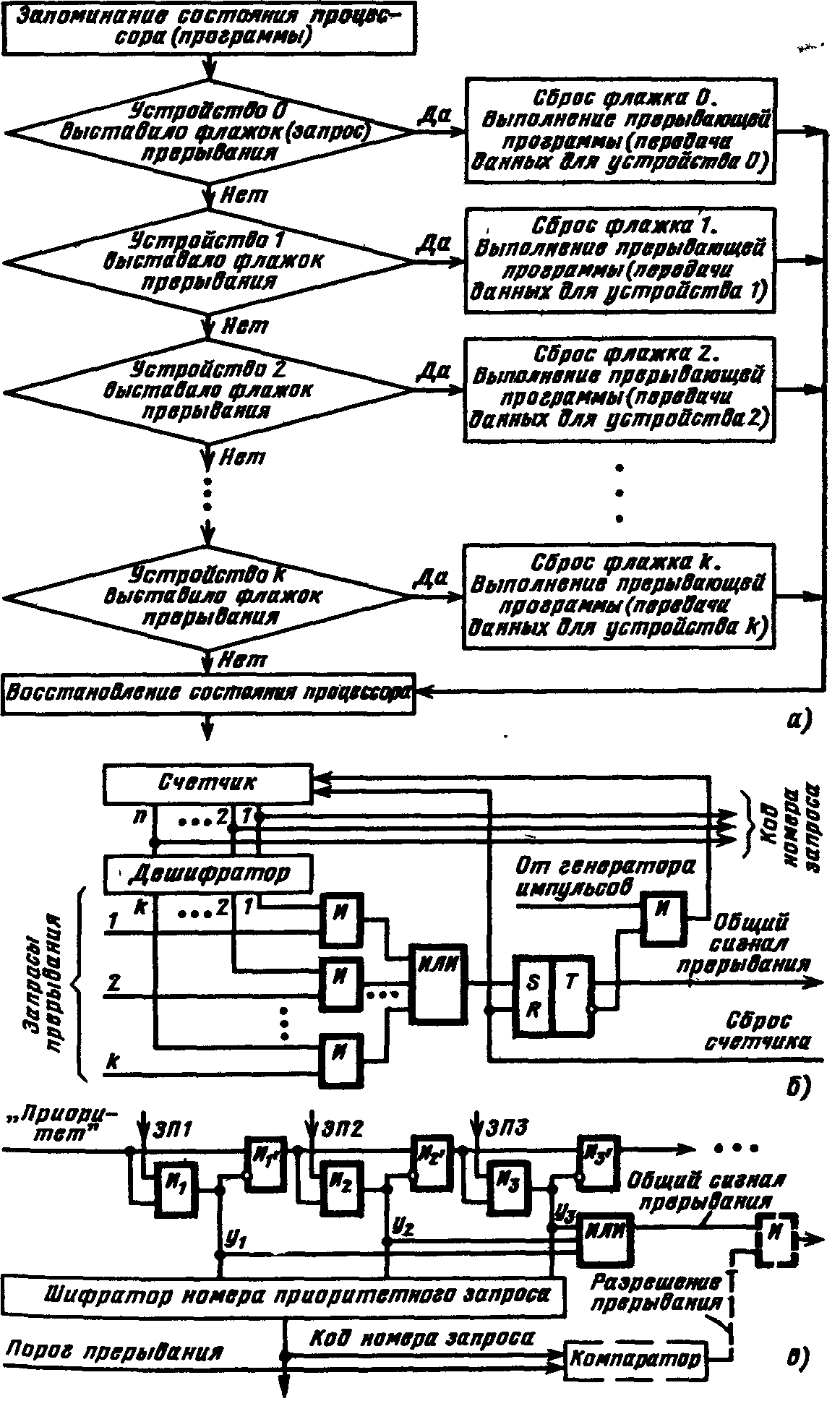 Рис 9.27. Способы опроса источников сигналов прерывания: а -программный опрос, б -циклический (многотактный) опрос, в -цепочечный однотактный опрос («дейзи-цепочка») ростейший способ установления приоритетных соотношений между запросами (уровнями) прерывания состоит в том, что приоритет определяется порядком присоединения линий сигналов запросов ко входам системы прерывания. При появлении нескольких запросов прерывания первым воспринимается запрос, поступивший на вход с меньшим номером. В этом случае приоритет является жестко фиксированным. Изменить приоритетные соотношения можно лишь пересоединением линий сигналов запросов на входах системы прерывания. Процедура прерывания с опросом источников (флажков) прерывания. При указанном способе задания приоритета между запросами каждому источнику запросов соответствует разряд (флажок) в регистре запросов прерывания (регистре флажков). При наличии запроса или нескольких запросов прерывания формируется общий сигнал прерывания (ОСП) (как это, например, показано на рис. 9.26), инициирующий выполняемую специальной программой или аппаратурой процедуру опроса регистра прерывания (флажков) или просто линий сигналов прерывания для установления источника, выставившего запрос прерывания наибольшего приоритета. По существу, эта процедура состоит в определении местоположения крайней слева единицы (крайнего флажка) в регистре запросов прерывания. На рис. 9.27 приведены различные способы реализации процедуры опроса источников сигналов прерывания. На рис 9.27, а показан процесс прерывания с программным опросом флажков прерывания (или, другими словами, опросом периферийных устройств, затребовавших передачу данных). Программный опрос источников прерываний занимает сравнительно много времени. Для уменьшения этого времени процедуру опроса реализуют аппаратурным путем. Схема циклического опроса запросов (источников) прерываний (рис. 9.27,6). Опрос k линий запросов прерывания (или разрядов регистра запросов прерывания) производится последовательно (циклически) с помощью n-разрядного счетчика (2n k), на который с некоторой частотой поступают импульсы от генератора. Поиск приоритетного запроса прерывания начинается со сброса счетчика и одновременно триггера Т в нулевое состояние, при этом импульсы генератора начинают поступать на вход счетчика. При помощи дешифратора и элементов И в каждом такте поиска проверяется наличие запроса прерывания, номер которого совпадает с кодом счетчика. Если на данном входе нет запроса прерывания, то после прибавления 1 к счетчику проверяется следующий по порядку вход. Если имеется запрос, триггер Т перебрасывается в 1, при этом в процессор посылается общий сигнал прерывания ОСП и прекращается поступление импульсов на вход счетчика, т. е. завершается цикл просмотра входов системы прерывания. Содержимое счетчика — код номера старшего по приоритету выставленного запроса — используется для формирования начального адреса прерывающей программы. После передачи управления прерывающей программе счетчик (и триггер Т) сбрасывается в 0, и процедура опроса запросов возобновляется, начиная с первого входа. Циклический (последовательный) опрос входов системы прерывания в аппаратурном отношении сравнительно прост, однако время реакции и при этом методе все-таки велико, особенно при большом числе источников запросов. Поэтому во многих случаях, например в ряде микропроцессоров, предназначенных для использования при работе в реальном времени, применяют схемы, позволяющие определять номер выставленного запроса или уровня прерывания старшего приоритета за один такт. Цепочечная однотактная схема определения приоритетного запроса («дейзи-цепочка») представлена на рис. 9.27, в. Как и в предыдущих случаях, приоритет запросов прерывания возрастает с уменьшением их номера. Процедура определения приоритетного запроса инициируется сигналом Приоритет, поступающим на цепочку последовательно включенных схем И. При отсутствии запросов этот сигнал пройдет через цепочку и сигнал общего запроса прерывания не сформируется. Если среди выставленных запросов прерывания наибольший приоритет имеет i-й запрос, то распространение сигнала Приоритет правее схемы И с номером i блокируется. На i-м выходе цепочечной схемы будет сигнал yi = 1, на всех других 0. В процессор поступит общий сигнал прерывания, при этом шифратор по сигналу yi = 1 сформирует код номера i-го запроса, принятого к обслуживанию. По сигналу процессора Подтверждение прерывания (на рис. 9.27 не показан) этот код передается в процессор и используется для формирования начального адреса прерывающей программы. Схемы, представленные на рис. 9.27, б и в, производят поиск крайней левой единицы в наборе сигналов прерывания и формируют код номера i запроса, удовлетворяющего условию Векторное прерывание Представленные на рис. 9.27 способы определения запроса с наибольшим приоритетом включают в себя так или иначе выполняемую процедуру опроса источников прерывания (входов системы прерывания). Эта процедура, даже если она выполняется аппаратурными средствами, требует сравнительно больших временных затрат. Более гибким и динамичным является векторное прерывание, при котором исключается опрос источников прерывания (флажков регистра прерывания). Прерывание называется векторным, если источник прерывания, выставляя запрос прерывания, посылает в процессор (выставляет на шины интерфейса) код адреса в памяти своего вектора прерывания. Отметим, что если прерывание на основе опроса источников прерываний всегда сопровождается переходом по одному и тому же адресу и инициирует одну и ту же прерывающую подпрограмму, которая после идентификации источника запроса и формирования адреса начала соответствующей запросу прерывающей программы передает ей управление, то при векторном прерывании каждому запросу прерывания, или, другими словами, устройству — источнику прерывания, соответствует переход к начальному адресу соответствующей прерывающей программы, задаваемому вектором прерывания. Программно-управляемый приоритет прерывающих программ Относительная степень важности программ, их частота повторения, относительная степень срочности в ходе вычислительного процесса могут меняться, требуя установления новых приоритетных отношений. Поэтому во многих случаях приоритет между прерывающими программами не может быть зафиксирован раз и навсегда. Необходимо иметь возможность изменять по мере надобности приоритетные соотношения программным путем, другими словами, приоритет между прерывающими программами должен быть динамичным, т. е. программно-управляемым. В ЭВМ широко применяются два способа реализации программно-управляемого приоритета прерывающих программ, в которых используются соответственно порог прерывания и маски прерывания. Порог прерывания. Этот способ позволяет в ходе вычислительного процесса программным путем изменять уровень приоритета процессора (а следовательно, и обрабатываемой в данный момент на процессоре программы) относительно приоритетов запросов источников прерывания (в основном периферийных устройств), другими словами, задавать порог прерывания, т. е. минимальный уровень приоритета запросов, которым разрешается прерывать программу, идущую на процессоре. Порог прерывания задается командой программы, устанавливающей в регистре порога прерывания код порога прерывания. Специальная схема выделяет наиболее приоритетный запрос прерывания, сравнивает его приоритет с порогом прерывания и, если он оказывается выше порога, вырабатывает общий сигнал прерывания, и начинается процедура прерывания (рис 9.27,в). В современных ЭВМ общего назначения наибольшее распространение получило программное управление приоритетом на основе маски прерывания (рис. 9.28). М 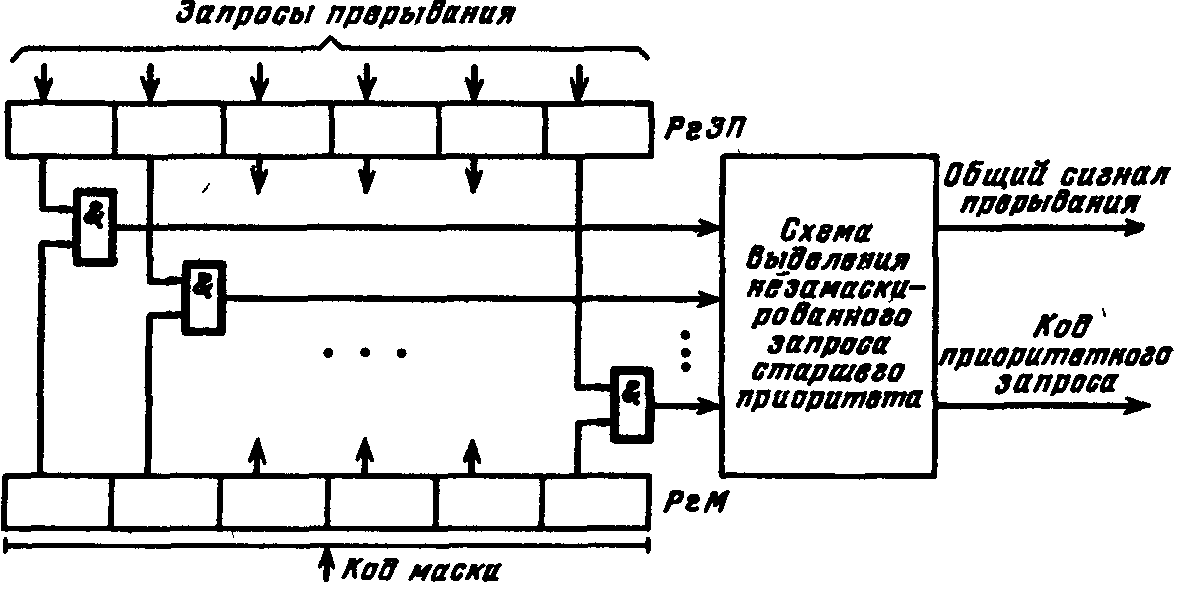 Рис 9.28. Программно управляемый приоритет на основе маски прерывания аска прерывания представляет собой двоичный код, разряды которого поставлены в соответствие запросам или классам прерывания. Маска загружается командой программы в регистр маски. Состояние 1 в данном разряде регистра маски разрешает, а состояние 0 запрещает (маскирует) прерывание текущей программы от соответствующего запроса. Таким образом, программа, изменяя маску в регистре маски, может устанавливать произвольные приоритетные соотношения между программами без перекоммутации линий, по которым поступают запросы прерывания. Каждая прерывающая программа может установить свою маску. При формировании маски 1 устанавливаются в разряды, соответствующие запросам (прерывающим программам) с более высоким, чем у данной программы, приоритетом. Схемы И выделяют поступившие незамаскированные запросы прерывания, из которых специальная схема, аналогичная цепочечной схеме на' рис. 9.28, в, выделяет наиболее приоритетный и формирует код его номера i, удовлетворяющего условию 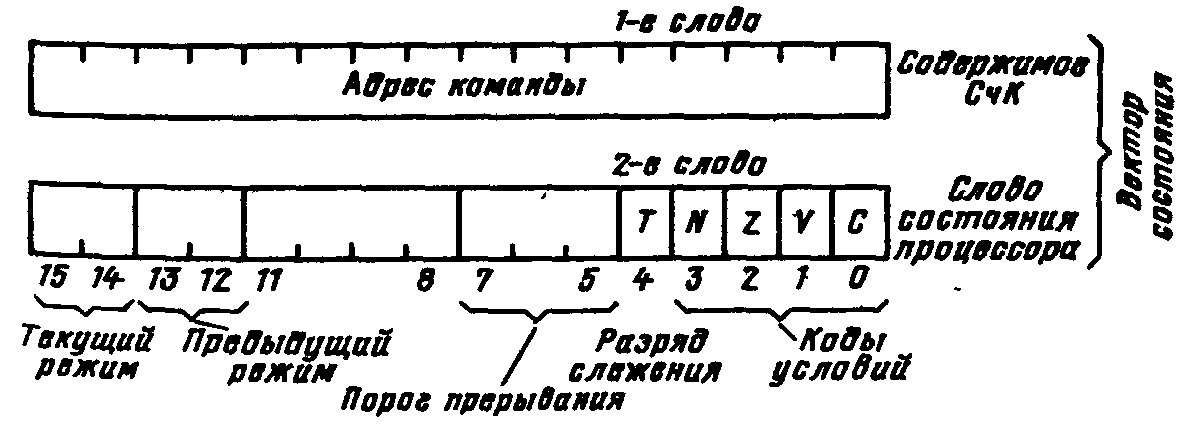 Рис. 9.29. Вектор состояния процессора в малых ЭВМ С 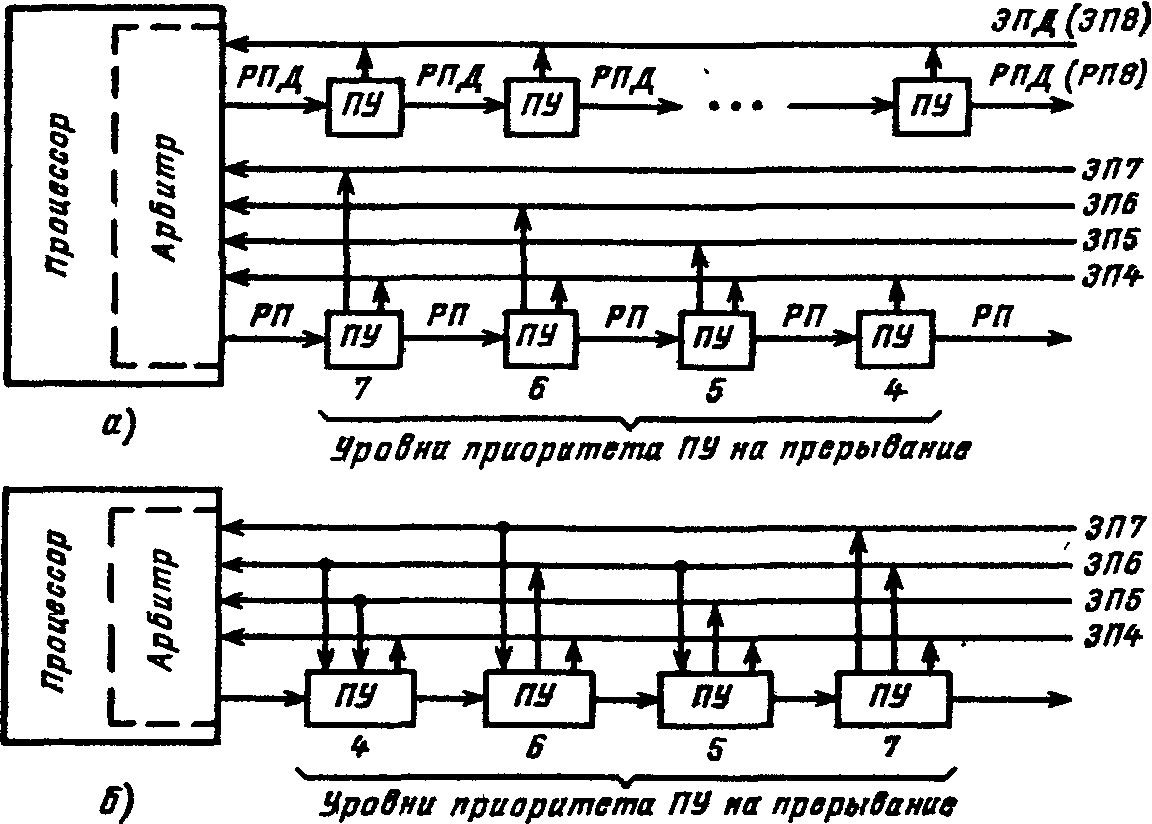 Рис. 9.30. Схема цепей запросов и разрешений прерываний в малых и микроЭВМ с интерфейсом «Q-шина»: а — с позиционно-зависимым приоритетом; б - с позиционно-независимым приоритетом; ЗПi РПi - соответственно запрос и разрешение прерывания i-ro класса; ЗПД, РПД - соответственно запрос в разрешение прямого доступа к памяти. замаскированным запросом в зависимости от причины прерывания поступают двояким образом: или он игнорируется, или запоминается, с тем чтобы осуществить затребованные действия, когда запрет будет снят. Например, если прерывание вызвано окончанием операции в периферийном устройстве, то его следует, как правило, запомнить, так как иначе ЭВМ останется неосведомленной о том, что периферийное устройство освободилось. Прерывание, вызванное переполнением разрядной сетки при арифметической операции, следует при его маскировании игнорировать, так как запоминание этого запроса может привести к тому, что он окажет действие на часть программы или другую программу, к которым это переполнение не относится. 9.17. Особенности систем прерывания малых ЭВМ Во многих малых ЭВМ, микропроцессорах и построенных на микропроцессорах микроЭВМ реализованы многоуровневые векторные системы прерывания с порогом прерывания и с использованием стековой памяти в процедурах перехода к прерывающей программе и возврата к прерванной программе. Векторная система прерывания в малых машинах СМ ЭВМ Рассмотрим особенности системы прерывания малых и микроЭВМ, в которых используется интерфейс «Q-шина». Запросы прерываний. Запросы внешних прерываний генерируются периферийными устройствами, подсоединенными к интерфейсу «Q-шина». На рис. 9.30 представлены варианты схем присоединения периферийных устройств и процессора (схемы арбитража) к линиям сигналов запросов и разрешения прерывания и прямого доступа к памяти. Имеется четыре уровня приоритета запросов прерывания — с четвертого по седьмой (в порядке возрастания). Еще более высокий (восьмой) уровень приоритета имеют запросы прямого доступа к памяти. Каждый уровень обслуживает своя линия запросов прерывания ЗПi„ к которой параллельно (по схеме ИЛИ) подсоединяются ПУ соответствующего уровня приоритета. Имеется одна линия для выдаваемого арбитром сигнала разрешения прерывания РП, проходящая последовательно через все ПУ с приоритетом от четвертого до седьмого. Кроме того, имеется отдельная линия для сигнала разрешения прямого доступа к памяти РПД, также проходящая последовательно через все ПУ, подключенные к линии запросов прямого доступа ЗПД. При наличии одной линии разрешения прерывания для выделения устройства, которому разрешается прерывание, используется цепочечный метод, при этом возможны два варианта схем прерывания с позиционно зависимым (рис 9 30, а) и с позиционно независимым приоритетом (рис 9.30,6). В позиционно-зависимой схеме устройства подсоединяются к процессору, точнее, к линии РП в порядке убывания приоритета. Если это неудобно, может применяться позиционно-независимая схема, в которой благодаря дополнительным связям при появлении ЗП на линиях более высокого приоритета выставившие ЗП устройства меньшего приоритета игнорируют сигнал разрешения прерывания и пропускают его на соседние устройства. Во второй схеме позиционность сохраняется только в отношении устройств, имеющих одинаковый приоритет. Из них преимущественное право на прерывание имеет устройство, расположенное электрически ближе к процессору. Схема Арбитр из выставленных запросов выделяет запрос старшего уровня приоритета и сравнивает его уровень с приоритетом процессора, т.е. с программно- устанавливаемым в регистре слова состояния процессора порогом прерывания (может принимать значения 4—7). Если уровень наиболее приоритетного из выставленных запросов прерывания превышает порог прерывания, арбитр (процессор) после завершения выполнения текущей команды выдает сигнал разрешения прерывания на линию РП. Этот сигнал поступает в первое по пути его прохождения выставившее запрос (и не заблокированное в схеме рис 9 30, б) устройство, которое прекращает дальнейшее распространение сигнала РП. Устройство, пославшее ЗПi и получившее разрешение на прерывание, передает в процессор адрес соответствующего вектора прерывания. Процессор, получив адрес вектора прерывания, помещает в стек, т. е. в ячейки памяти, адресуемые указателем стека, два слова вектора состояния: сначала текущее слово состояния процессора (второе слово вектора состояния), затем первое слово — содержимое счетчика команд (продвинутый адрес прерванной программы). Перед каждой передачей в стек значение указателя стека уменьшается на два. Далее в счетчик команд из ячейки, хранящей первое слово вектора прерывания, передается начальный адрес прерывающей программы, а из следующей ячейки второе слово вектора прерывания заносится в регистр слова состояния процессора. В новом слове состояния процессора порог прерывания должен быть не меньше уровня приоритета принятого к обслуживанию запроса, чтобы повторный запрос от этого источника прерывания не мог прервать выполняемую прерывающую программу. Управление переходит к программе обработки прерывания, заданной вектором прерывания. Если эта программа использует общие регистры, то она начинается с передачи их содержимого в стековую память с помощью команд передачи с автодекрементной прямой адресации по регистру указателя стека. Возврат к прерванной программе осуществляет заключительная часть прерывающей программы, в которой команды передачи данных с автоинкрементной прямой адресацией по указателю стека производят передачу из стека сохраненных в нем состояний общих регистров в соответствующие регистры. Последней командой прерывающей программы — командой «Возврат из прерываний»—.первое слово вектора состояния прерванной программы загружается из стека в счетчик команд, а второе слово — в регистр слова состояния процессора. Передача каждого слова сопровождается увеличением УС на два. После этого восстанавливается выполнение прерванной программы. Имеются особенности в процедуре выполнения запросов прерываний ЗП8 (запросов прямого доступа к памяти). Их приоритет всегда выше приоритета процессора. Поэтому в ответ на запрос ЗПД (ЗП8) сигнал разрешения РПД посылается немедленно, даже если не завершено выполнение текущей команды, и производится обмен данными между периферийным устройством и ОП без участия процессора. 9.19. Процедура выполнения команд. Рабочий цикл процессора Функционирование процессора в основном состоит из повторяющихся рабочих циклов, каждый из которых соответствует выполнению одной команды программы. Завершив рабочий цикл для текущей команды, процессор переходит к выполнению рабочего цикла для следующей команды программы. На рис. 9.34 представлена схема рабочего цикла процессора. Эта схема имеет достаточно общий характер. 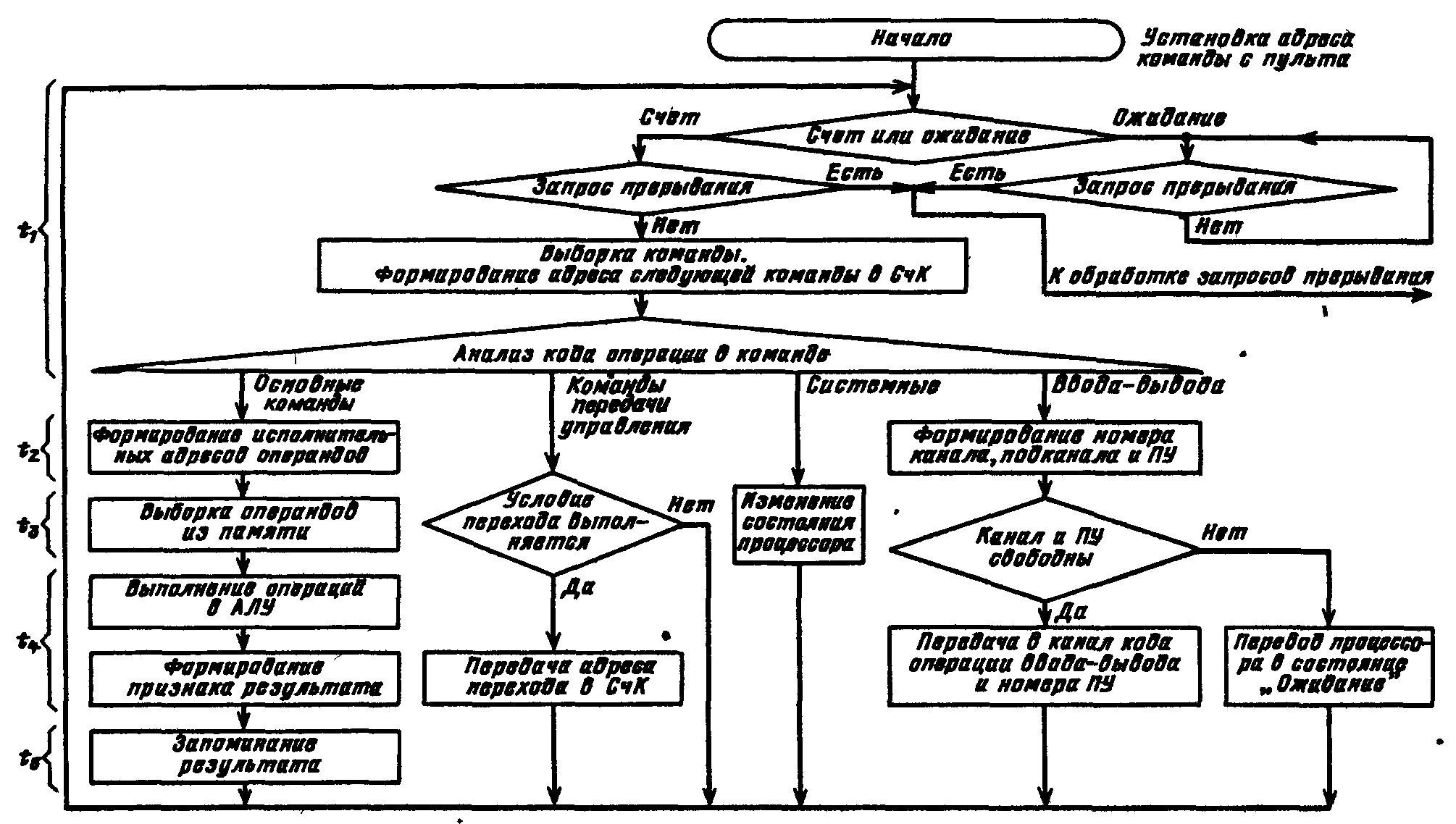 Рис. 9.34. Рабочий цикл процессора На схеме показаны варианты рабочего цикла для четырех групп команд: 1) основных (осуществляющих арифметические, логические и пересылочные операции), 2) передачи управления, 3) ввода-вывода и 4) системных (устанавливающих состояние процессора, маску прерывания, слово состояния программы и др.). Рабочий цикл начинается с распознавания состояния процессора. Устанавливается, какое из альтернативных состояний — Счет или Ожидание — имеет место. Далее проверяется наличие незамаскированных прерываний. В состоянии Ожидание никакие программы не выполняются. Процессор ждет прихода запроса прерывания, после чего управление переходит к соответствующей прерывающей программе, переводящей процессор в состояние Счет. В состоянии Счет при наличии незамаскированных прерываний происходят выход из нормального рабочего цикла н переход к процедуре обработки запросов прерывания. При отсутствии в состоянии Счет запросов прерывания последовательно выполняются этапы рабочего цикла: выборка очередной команды и определение по коду операции команды ее группы, подготовка операндов (формирование исполнительных адресов и выборка операндов из памяти), обработка операндов в АЛУ и запоминание результата. На этапе выборки очередной команды образуется согласно естественному порядку адрес следующей за ней команды (продвинутый адрес), при этом содержимое счетчика команд (соответствующего поля ССП) увеличивается на число, равное числу байт в очередной команде. В некоторых ЭВМ формирование адреса следующей команды составляет отдельный этап, завершающий рабочий цикл. В процессе выполнения заданной командой операции формируется признак результата операции, используемый командами условного перехода при организации ветвлений в программах. Указанная выше последовательность этапов составляет основной вариант рабочего цикла, реализуемый при выполнении основных команд. При выполнении команд передачи управления проверяется заданное командой (например, ее полем маски) условие. Если условие не выполняется, то следующую команду указывает продвинутый адрес, ранее установленный в СчК (регистре ССП). Если условие выполняется или имеется один из вариантов команды безусловного перехода, то адрес, задаваемый командой передачи управления, передается в СчК. Команды ввода-вывода инициируют в канале операцию обмена информацией между ядром ЭВМ (основной памятью) и периферийным устройством. Сама эта операция выполняется каналом под управлением его собственной. программы. Поэтому на долю процессора остается только процедура опроса состояний канала и периферийного устройства — свободны ли они для операции ввода-вывода. Если свободны, процессор выдает в канал информацию, необходимую для начала операции ввода-вывода. В противном случае процессор переключается в состоянии Ожидание и ждет сигнала прерывания от этого канала. Системные команды осуществляют переключение состояния процессора (программы) путем загрузки нового ССП или его части. В частности, эти команды изменяют маски прерывания, устанавливают ключи памяти и ключи защиты в ССП, реализуют операции прямого управления. 9.20. Принцип совмещения операций академика С. А. Лебедева. Конвейер операций Вернемся к схеме рабочего цикла (рис. 9.34) и рассмотрим совокупность этапов цикла для основных команд (основной вариант цикла). Если эти этапы выполняются последовательно во времени, то, суммируя обозначенные на рисунке продолжительности отдельных этапов, получаем время цикла tпосл = t1 + t2 + t3 + t4 + t5 и производительность процессора, операций (команд)/с, Pпосл = 1 / tпосл = 1 / (t1 + t2 + t3 + t4 + t5) Во многих случаях последовательная процедура выполнения этапов цикла не обеспечивает требуемую производительность процессора. Академик С. А. Лебедев в 1956 г. предложил повышать производительность, используя принцип совмещения во времени отдельных операций (этапов) рабочего цикла, и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операции в АЛУ и выборки из памяти следующей команды. П 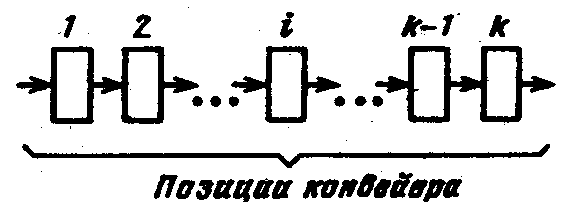 Рис. 9.35. Конвейер операций усть рабочий цикл процессора состоит из k этапов, причем 1-й этап имеет продолжительность ti, тогда при последовательном выполнении этапов продолжительность процедуры и общая производительность процессора, операций/с, Скорость работы машины может быть увеличена, если для выполнения каждого этапа иметь отдельный аппаратурный блок и соединить эти блоки в обрабатывающую линию — конвейер операций (в данном случае конвейер команд) так, чтобы результат выполнения в данном блоке некоторого этапа передавался для реализации очередного этапа на следующий блок, и т. д. (рис. 9.35). Синхронный конвейер операций. Если конвейер работает в принудительном темпе и для выполнения любого этапа выделено одно и то же время tT, (такт конвейера), то такой конвейер называется синхронным. Разбиение процедуры на этапы и выбор длительности такта производятся согласно условиям tT = max{ti}, i = 1, …, k; (**) ti + ti+1 > tT, i = 1, …, k. (***) причем в силу цикличности рабочего процесса в последнем неравенстве принимаем tk+ 1 = t1. Е 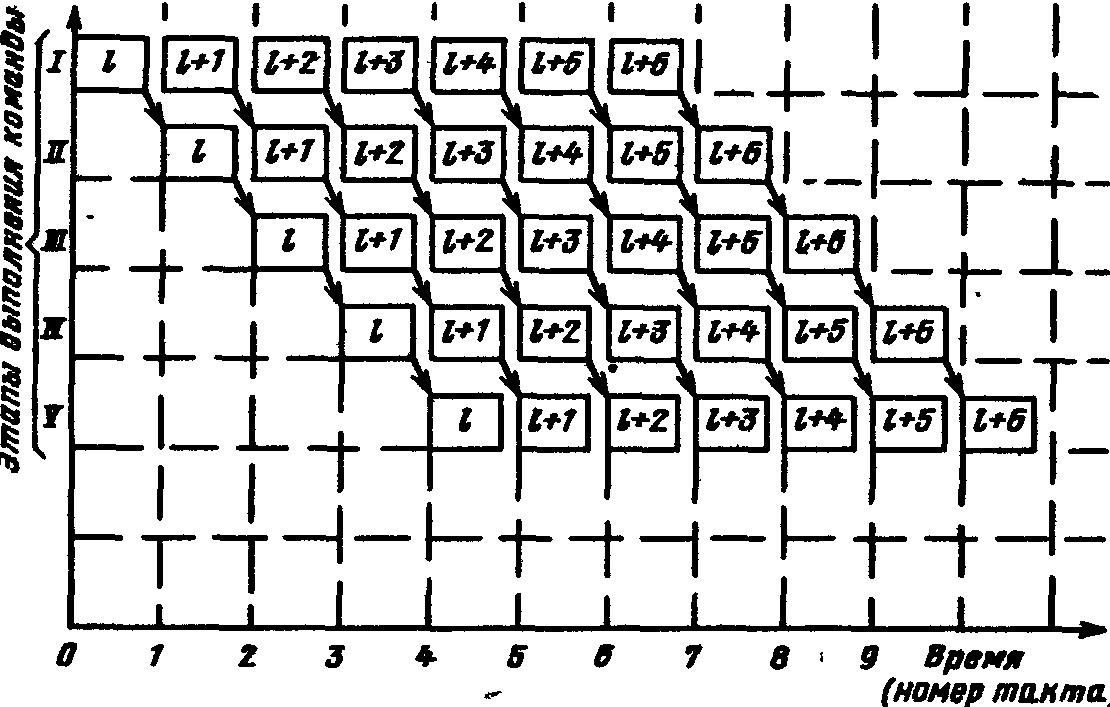 Рис. 9.36. Синхронный конвейер команд сли для каких-либо смежных этапов второе условие не выполняется, то их следует объединить в один этап либо наиболее длинный этап разбить на несколько этапов. В последнем случае заново выбирается tT и вновь проверяется условие (**). На рис. 9.36 показана временная диаграмма выполнения команд на 5-позиционном синхронном конвейере. Одинаковыми символами помечены разные этапы рабочего цикла одной и той же команды. После того как все позиции конвейера окажутся заполненными, параллельно во времени обрабатывается столько команд, сколько в конвейере обрабатывающих блоков (позиций). Конвейер характеризуется коэффициентом совмещения операций, равным числу одновременно выполняемых этапов обработки информации. Номинальная производительность синхронного конвейера при его полной загрузке Найдем соотношение производительностей процессора при конвейерной обработке и при последовательном выполнении этапов рабочего цикла. Из (*) и (**) имеем а из (*) и (***) получаем Из (****) и (*****) получаем В действительности рост реальной производительности процессора окажется ниже из-за простоев (задержек) конвейера. В процедурах выполнения некоторых команд (например, команд пересылки данных) отдельные этапы общего рабочего цикла отсутствуют, и, следовательно, простаивают отдельные блоки конвейера. Для команды условного перехода по результату предыдущей операции выборка следующей команды должна быть задержана (конвейер простаивает несколько тактов), пока не будет сформирован признак результата (формируется на более позднем этапе) предыдущей операции. Если pm — вероятность выборки команды, вызывающей задержку конвейера на m тактов (m = 1, 2, ..., k), то действительная производительность конвейера 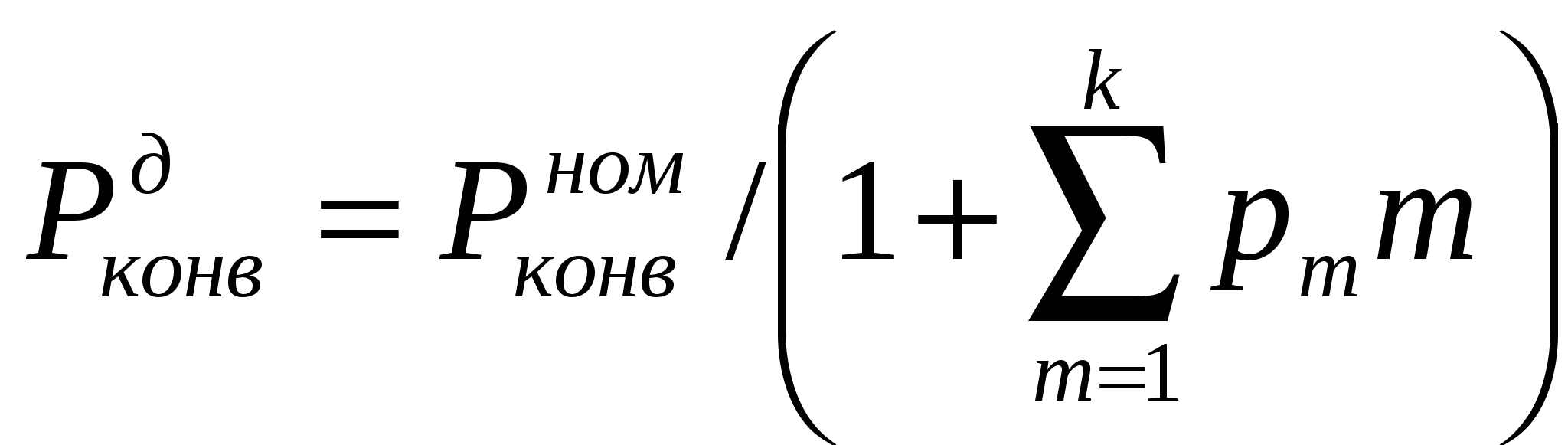 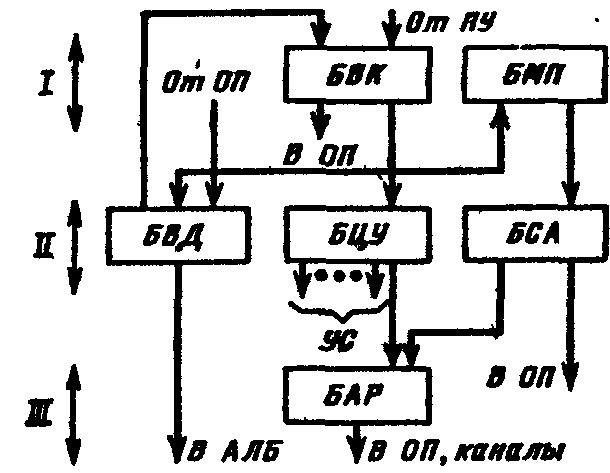 Рис. 9.37. Структура управляющего устройства процессора: БВК. — блок выборки команд; БМП — блок местной памяти; БВД — блок выборки данных; БЦУ — блок центрального управления; БСА — блок , сумматора адреса; БАР — блок адреса результата: АЛБ — арифметико-логический блок; ПУ — пульт управления; УП — управляющие сигналы Асинхронный конвейер команд. При большой зависимости продолжительности выполнения процедур отдельных этапов от типа команды и вида операндов целесообразно применение асинхронного конвейера, в котором отсутствует единый такт работы его блоков, а информация с одного блока конвейера передается на следующий, когда данный блок закончит свою процедуру, а следующий полностью освободится от обработки предыдущей команды. Управление передачей информации между соседними блоками в асинхронном конвейере осуществляется с помощью двух триггеров — готовности блока (сигнализирует о завершении операции в блоке) и освобождения последующего блока. В качестве примера применения асинхронного конвейера команд может служить процессор ЭВМ ЕС-1050, в котором реализован конвейер, выполняющий одновременно три команды. Рабочий цикл выполнения команды разбит на три этапа: I — выборка очередной команды, II — формирование исполнительных адресов и выборка операндов, III — операция в АЛУ, формирование признака результата и запись результата в память. Для каждого из указанных этапов выполнения команды имеется соответствующая аппаратура. Например, кроме сумматора АЛУ есть отдельный сумматор для формирования исполнительного адреса на этапе II. На рис. 9.37 представлена структура управляющего устройства с «жесткой» логикой процессора ЭВМ ЕС-1050, на которой показаны блоки, управляющие процедурами отдельных этапов выполнения команды. Н 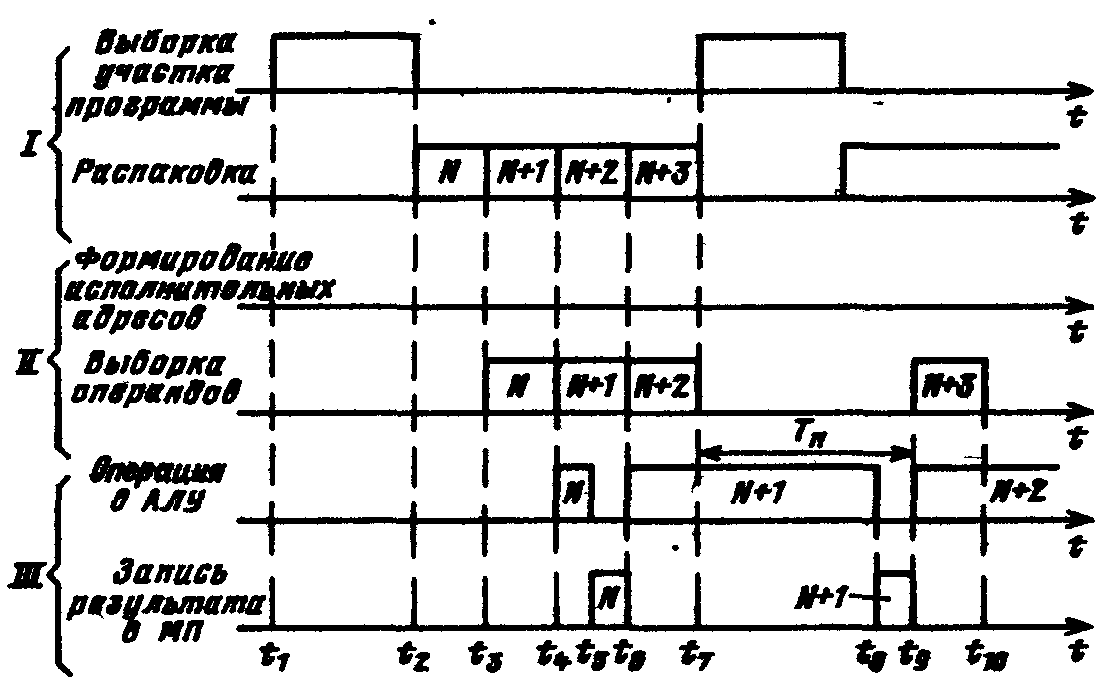 Рис. 9.38. Временная диаграмма совмещения выполнения трех команд (формата “регистр-регистр”) в асинхронном конвейере команд. а рис. 9.38 показана временная диаграмма совмещения выполнения трех команд в ЭВМ ЕС-1050 Временная диаграмма построена для случая, когда выбираемый за одно обращение к памяти «участок программы» содержит четыре команды формата «регистр-регистр». Этап I содержит две процедуры, выборку из ОП участка программы (8 байт) и распаковку участка — выделение из него очередной команды и размещение ее в регистре команды. Этап II в общем случае включает в себя формирование исполнительных адресов (при выполнении команд формата “регистр-регистр” отсутствует) и выборку операндов. Этап III состоит также из двух процедур: выполнения операций в АЛУ и записи результата в память. Из диаграммы видно, что, начиная с момента времени t4выполняются одновременно три этапа цикла соответственно для трех команд. В приведенном примере с момента t7 из-за большой длительности в команде N+1 операции в АЛУ приостанавливается работа блоков аппаратуры, соответствующих этапам I и II. Арифметический конвейер. Выше был рассмотрен конвейер команд. Однако в целях повышения производительности машины принцип конвейерной обработки широко используется и в самих выполняющих содержательную обработку информации устройствах (АЛУ), которые строятся в виде арифметического конвейера, причем таких арифметических конвейерных линий может быть в процессоре несколько, в том числе и специализированных для определенных операций с данными Подобные операционные (арифметические) устройства часто называют магистральными. Пусть операционное устройство должно вычислять некоторую функцию Ф от входных данных (выполнять некоторую операцию над входными данными). Можно функцию Ф представить в виде последовательности более простых подфункций 1 2 3 . . . k причем такой, что результаты преобразования, выполняемые подфункцией i, используются в качестве входных данных при вычислении подфункции i+1, и если при этом для каждой подфункции иметь реализующую ее схемный блок, то получим арифметический конвейер, который может быть выполнен как синхронный или как асинхронный. Приведенные выше элементы теории синхронного конвейера команд остаются в силе и для синхронного арифметического конвейера. Если tT — такт конвейера, то после полной загрузки он станет выдавать значения функции Ф через интервалы времени tT. Увеличение производительности процессора за счет использования арифметического конвейера можно оценить по (******). Если арифметический конвейер используется для выполнения разных операций, то осложняется определение состава рабочих позиций (блоков) конвейера и может потребоваться настройка (диспетчеризация) с соответствующей коммутацией блоков конвейера на операцию, задаваемую текущей командой. Рассмотрим в качестве примера использование арифметического конвейера для сложения двух векторов X+Y=Z, компонентами» которых являются числа, представленные в форме с плавающей точкой и в нормализованном виде. Выделим в операции сложения чисел с плавающей точкой четыре этапа: 1) сравнение и определение разности порядков, 2) выравнивание порядков - сдвиг мантиссы числа с меньшим порядком на число разрядов, равное разности порядков; 3) сложение мантисс; 4) нормализация результата. В арифметическом конвейере эти этапы выполняются отдельными блоками, образующими конвейер, по которому перемещаются операнды или промежуточные результаты операции По мере их перемещения в конвейер вводятся новые компоненты векторов. Пусть времена, необходимые для выполнения этапов сложения чисел с плавающей точкой, есть t1, t2, t3, t4. 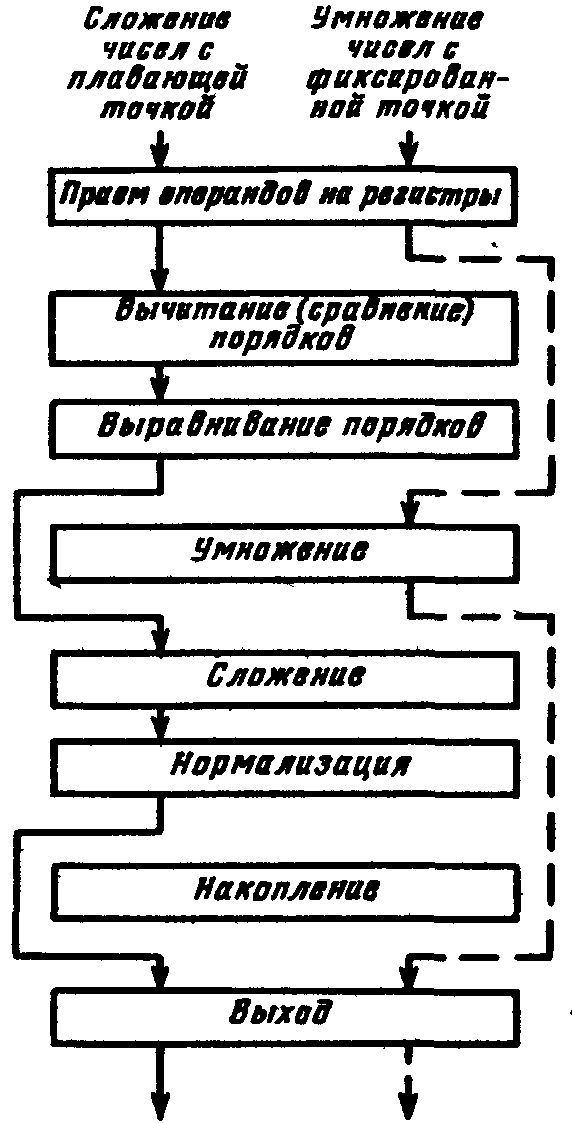 Рис.9.39 Пример настройки арифметического конвейера на выполнение различных операций Следовательно, если не организовать конвейер и выполнять все этапы операции последовательно, то для получения компонента zi = xi + yi потребуется время T = t1 + t2 + t3 + t4. В синхронном конвейере, как указывалось выше, продолжительность каждого этапа устанавливается по самому длинному из них, пусть в данном случае это t3. Тогда, если конвейер заполнен, результаты сложения элементов векторов будут выдаваться через каждые промежутки времени t3, т. е. значительно быстрее, чем в случае отсутствия конвейерной обработки. На рис. 9.39 в качестве примера представлена структура конвейерного (магистрального) АЛУ, соответствующего АЛУ известной в свое время ЭВМ ASC фирмы Texas Instruments, и показаны варианты коммутации блоков конвейера для выполнения разных операций, в данном случае сложения чисел с плавающей точкой и умножения чисел с фиксированной точкой. Особенно эффективно использование операционных (арифметических) конвейеров в специализированных вычислительных устройствах с ограниченным набором алгоритмов обработки входных потоков данных, так как в этом случае возможно разбиение АЛУ на большое число простейших быстродействующих конвейерных блоков при небольших схемных и временных потерях на их коммутацию. В ряде микропроцессоров одновременно присутствуют конвейер команд и арифметический конвейер, при этом часто в процессоре (микропроцессоре) выделяют I-часть — аппаратуру, относящуюся к обработке собственно команд и E-часть — аппаратуру, связанную с операциями над данными1. I — от Instruction (инструкция, команда) и Е — от Execution (выполнение). |