Архитектура ЭВМ и систем (конспект лекций). Конспект лекций
 Скачать 1.14 Mb. Скачать 1.14 Mb.
|

|
Пример показывает, что, пока данные размещаются во внутрикристальной кэш-памяти, производительность высока. Как только объем данных превышает размер кэш-памяти и обращения в память идут в "равномерно" распределенные по объему адреса, производительность падает более, чем в 7 раз. Развитие микропроцессоров происходит при постоянном стремлении сохранения преемственности программного обеспечения (ПО) и повышения производительности за счет совершенствования архитектуры и увеличения тактовой частоты. Сохранение преемственности ПО и повышение производительности, вообще говоря, противоречат друг другу. Процессоры с системой команд х86, относящиеся к классу CISC-процессоров, имеют более низкие тактовые частоты по сравнению с микропроцессорами ведущих компаний-изготовителей RISC-процессоров. Существуют приложения, на которых производительность х86 микропроцессоров значительно ниже, чем у RISC-процессоров, реализованных на той же элементной базе. Однако возможность использования совместимого ПО для различных поколений х86 процессоров, выпущенных в течение последнего десятилетия, обеспечивает им устойчивое доминирующее положение на рынке. В настоящее время на основе пионерских разработок компаний NexGen и AMD, подхваченных компанией Intel, предпринята попытка решить проблему повышения производительности в рамках архитектуры х86. Эти компании в последних разработках, сохраняя преемственность по системе команд с CISC-микропроцессорами семейства х86, создают новые устройства с использованием элементов RISC-архитектуры. Примером такого подхода могут служить микропроцессоры Nx586 (NexGen), K5, К6 (AMD), Pentium PRO, Pentium II (Intel), использующие концепцию разделенной (decoupled) архитектуры и RISC ядра. В микропроцессор встраивается аппаратный транслятор, превращающий команды х86, в команды RISC-процессора. При этом одна команда х86 может порождать до четырех команд RISC-процессора. Исполнение команд происходит как в развитом суперскалярном процессоре. Компания Intel использовала этот подход в своем микропроцессоре Pentium Pro, что весьма укрепило ее позиции на фоне достижений RISC-архитектур. Суперскалярные процессоры Архитектура суперскалярных процессоровЕсть два крайних подхода, при возможных промежуточных, к отображению присущего микропроцессору внутреннего параллелизма обработки данных на архитектурном уровне в системе команд. Первый подход более консервативен и состоит в том, что никакого указания на параллельную обработку внутри процессора система команд не содержит. Такие процессоры относятся к классу суперскалярных. Второй подход - напротив полностью открывает все возможности параллельной обработки. В специально отведенных полях команды каждому из параллельно работающих обрабатывающих устройств предписывается действие, которое устройство должно совершить. Такие процессоры называются процессорами с длинным командным словом (VLIW или EPIC). Предполагается, что существуют компиляторы с языков высокого уровня, которые готовят программы для загрузки их в микропроцессоры. Основная идея, определяющая развитие суперскалярных микропроцессоров, состоит в построении возможно большего количества параллельных структур при сохранении традиционных последовательных программ. Это означает, что компиляторы и аппаратура микропроцессора сами, без вмешательства программиста, обеспечивают загрузку параллельно работающих функциональных устройств микропроцессора. В соответствии с моделью последовательного программирования, программы пишутся в предположении, что команды будут выполнены в том же порядке, в каком они представлены в программе. Однако с целью достижения большей эффективности современные процессоры пытаются выполнять несколько команд одновременно и в некоторых случаях в порядке, отличном от их исходной последовательности в программе. Это переупорядочение может быть выполнено в трансляторе и (или) в аппаратных средствах во время выполнения. Суперскалярные и VLIW-процессоры принадлежат классу архитектур, которые используют параллельность уровня команды (ILP). ILP-процессоры и компиляторы обычно преобразуют полностью упорядоченное множество команд исходной программы в частично упорядоченное множество, структурированное зависимостями по данным и управлению. Зависимости по управлению (которые проявляются как переходы по условию) представляют главное препятствие высокопараллельному выполнению потому, что эти зависимости должны быть установлены прежде, чем будут выполнены все последующие команды. Текст последовательной программы, представленной на языке высокого уровня, компилируется в машинный код, отражающий статическую структуру программы, т. е. упорядоченное множество команд (инструкций) в памяти компьютера. Процесс выполнения программы с конкретными наборами входных данных может быть представлен динамической структурой программы, т. е. множеством последовательностей инструкций в порядке их исполнения. Повысить степень параллелизма программы можно изменяя соответствующим образом ее статическую или динамическую структуру. Поскольку статическая структура программы однозначно соответствует ее исходному тексту (в предположении неизменности компилятора), то изменение статической структуры сводится к изменению исходного кода, что, в общем случае, не всегда возможно. Динамическая же структура программы может быть изменена при неизменной статической структуре. И главной целью такого изменения должно быть повышение степени параллельного исполнения команд. Допустимые границы преобразования динамической структуры программы задают существующие на множестве инструкций отношения: зависимость по управлению и зависимость по данным. При описании архитектур суперскалярных процессоров часто используется модель окна исполнения. При исполнении программы микропроцессор как бы продвигает по статической структуре программы окно исполнения. Команды в окне могут исполняться параллельно, если между ними нет зависимости. Для устранения зависимостей, вызванных командами переходов, используется метод предсказания, позволяющий извлекать и условно исполнять команды предсказанного перехода. Если позднее обнаруживается, что предсказание было сделано верно, то результаты условно исполненных команд принимаются. Если предсказание было ошибочным, состояние процессора восстанавливается на момент принятия решения о выполнении перехода. Команды, помещенные в окно исполнения, могут быть зависимы по данным. Эти зависимости обусловлены использованием одних и тех же ресурсов памяти (регистров, ячеек памяти) в разных командах. Поэтому для правильного исполнения программы необходимо использование этих ресурсов в предписываемом программой порядке. В 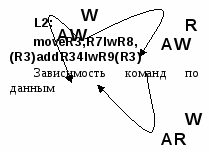 се виды зависимостей по данным могут быть классифицированы по типу ассоциаций: RAR - "чтение после чтения", WAR - "запись после чтения" и WAW - "запись после записи", RAW - "чтение после записи". се виды зависимостей по данным могут быть классифицированы по типу ассоциаций: RAR - "чтение после чтения", WAR - "запись после чтения" и WAW - "запись после записи", RAW - "чтение после записи".Некоторые из зависимостей по данным могут быть устранены. RAR, по сути дела, соответствует отсутствию зависимостей, поскольку в данном случае порядок выполнения команд не имеет значения. Действительной зависимостью является только "чтение после записи" (RAW), так как необходимо прочитать предварительно записанные новые данные, а не старые. Лишние зависимости по данным появляются в результате "записи после чтения" (WAR) и "записи после записи" (WAW). Зависимость WAR состоит в том, что команда должна записать новое значение в ячейку памяти или регистр, из которых должно быть произведено чтение. Лишние зависимости появляются по нескольким причинам: не оптимизированный программный код, ограничение количества регистров, стремление к экономии памяти, наличие программных циклов. Важно отметить, что запись может быть произведена в любой свободный ресурс, а не только тот, который указан в программе. После удаления лишних зависимостей по управлению и данным команды могут исполняться параллельно. Формирование расписания параллельного выполнения команд возлагается на аппаратные средства микропроцессора. Это расписание учитывает существующие зависимости между командами и имеющиеся функциональные модули процессора. В современных микропроцессорах широко используется принцип конвейерного выполнения отдельных элементарных операций. Конвейеризация внутренних процессов позволяет выполнять команду за каждый процессорный цикл. Дальнейшее внедрение принципов конвейеризации привело к появлению класса суперскалярных микропроцессоров. Их отличительной особенностью является возможность выполнения нескольких команд за один процессорный цикл. Такой режим выполнения программы стал возможным благодаря наличию в процессорах нескольких исполнительных устройств. В число основных блоков суперскалярного микропроцессора входят блок выборки команд и предсказания переходов, блок декодирования команд, анализа зависимостей между командами, переименования и диспетчеризации, блоки регистров и обрабатывающих устройств с плавающей и фиксированной точками, блок управления памятью, а также блок упорядочения выполненных команд. Ниже рассмотрены основные приемы повышения быстродействия в суперскалярных микропроцессорах. |