Архитектура ЭВМ и систем (конспект лекций). Конспект лекций
 Скачать 1.14 Mb. Скачать 1.14 Mb.
|

|
В машинах ЕС ЭВМ используется четырехразрядная маска, и это дает возможность задавать в качестве условия перехода выполнение не только любого из ПР, но и их дизъюнкции (если в маске М несколько 1). В общем случае имеем Отметим, что при М=1111 команда УП выполняет безусловный переход, а при М=0000 (пустая команда) действует естественный порядок выборки команд. Таким образом, исключается необходимость в отдельной команде безусловного перехода. Команды условных переходов позволяют реализовать программы с разветвлениями в зависимости от промежуточных результатов вычислений или состояния машины. Важным случаем передачи управления являются безусловные переходы к подпрограммам. Их особенность состоит в том, что помимо перехода они должны обеспечить по окончании подпрограммы возврат к исходной программе, к той точке ее, откуда был совершен переход. Обычно для переходов к под программам используется специальная команда Безусловный перевод с возвратом (БПВ). По этой команде (рис. 3.11) сначала адрес возврата АВОЗ, т.е. содержимое СчК (увеличенное па «приращение адреса команды» LК), запоминается по адресу Р, указанному в команде БПВ. затем в счетчик команд заносится содержимое поля А команды БПВ, т.е. адрес А начала подпрограммы. В конце подпрограммы размещается команда возврата, которая представляет собой команду БПК, указывающую путем косвенной адресации адрес ячейки (или регистра), в которой находится адрес АВОЗ. Формально всю эту процедуру после приема в РгК команды БПВ можно представить в следующем виде (см. рис. 3.9 и 3.11): СчК := СчК + LК; образование адреса возврата АВОЗ РгИОП := СчК; РгАОП := РгК [Р]; Запись: ОП[РгАОП] = РгИОП; запоминание адреса возврата АВОЗ, в ячейке Р СчК := РгК[А]; передача в СчК адреса начала подпрограммы . . . . . . . . . . . . ; Выполнение подпрограммы . . . . . . . . . . . . ; Считывание и передача в РгК заключающей подпрограммы команды БПК, содержащей в поле А косвенный адрес Р *) РгАОП := РгК[А]; Счит: РгИОП := ОП[РгАОП]; извлечение адреса возврата АВОЗ АСКБПВ: СчК := РгИОП [А]; возврат к основной программе - команде в ячейке АВОЗ О 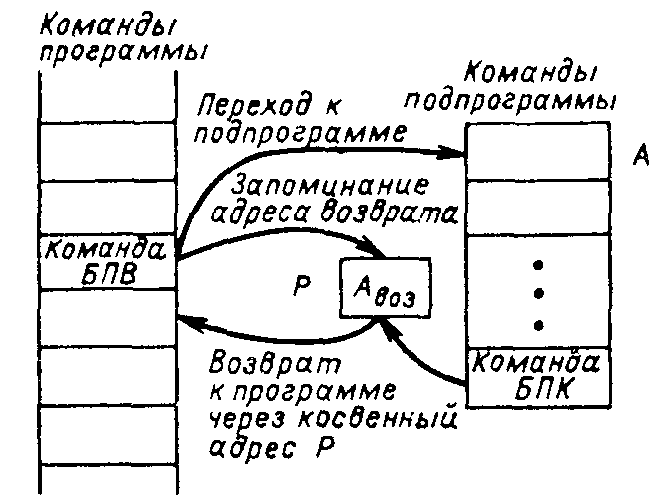 Рис. 3.11. Обращение к подпрограмме с помощью команды безусловного перехода с возвратом. перация замещения, реализуемая командой Выполнение (Вып), состоит в том, что вместо очередной команды, соответствующей естественному порядку выборки команд, исполняется замещающая команда, указываемая адресной частью команды Вып, а затем, если только замещающая команда не оказалась командой перехода, восстанавливается приостановленный на время выполнения команды Вып естественный порядок выборки команд. Команда Вып должна сохранять неизменным содержимое СчК. Поэтому адрес замещающей команды берется не из СчК, а из РгК. (см. рис. 9.10). Соответствующую процедур после приема в РгК команды Вып можно представить в виде РгАОП := РгК[А]; Счит:РгИОП := ОП[РгАОП]; РгК := РгИОП; выборка замещающей команды . . . . . . . . . . . . ; Выполнение замещающей команды . . . . . . . . . . . . СчК := СчК + LК восстановление естественного порядка выборки команд. Особенности RISC архитектуры RISC-архитектура предполагает реализацию в ЭВМ сокращенного набора простейших, но часто употребляемых команд, что позволяет упростить аппаратурные средства процессора и благодаря этому получить возможность повысить его быстродействие. При использовании RISC-архитектуры выбор набора команд и структуры процессора (микропроцессора) направлены на то, чтобы команды набора выполнялись за один машинный цикл процессора. Выполнение более сложных, но редко встречающихся операций обеспечивают подпрограммы.. В ЭВМ с RISC машинным циклом называют время, в течение которого производится выборка двух операндов из регистров, выполнение операции в АЛУ и запоминание результата в регистре. Большинство команд в RISC являются быстрыми командами типа «регистр - регистр» и выполняются без обращений к ОП. Обращения к ОП сохраняются лишь в командах загрузки регистров из памяти и запоминания в ОП. Чтобы это было возможным, процессор должен содержать достаточно большое число общих регистров. Благодаря характерным для RISC-архитектуры особенностям - сокращенному набору команд (обычно не более 50-100), небольшому числу (обычно 2-3) простых способов адресации (в основном регистровой), небольшому числу простых форматов команд с фиксированными размерами и функциональным назначением их полей - упрощается управляющее устройство процессора, который в этом случае обходится без микропрограммного уровня управления и управляющей памяти, и его УУ может быть выполнено на «схемной логике». Уменьшение количества выполняемых команд и другие отмеченные выше особенности RISC-архитектуры приводят к столь значительному упрощению структуры процессора, что становится возможной его реализация на одном кристалле вместе с большим регистровым файлом и кэшем. Большое число регистров, особенно при наличии обеспечивающего их эффективное использование «оптимизирующего компилятора», позволяет до предела сократить обращение к ОП путем сохранения на регистрах промежуточных результатов, передачи через регистры операндов из одних программ в другие программы или подпрограммы, отказа от передач на сохранение в ОП содержимого регистров при прерываниях. Особенностью RISC-архитектуры является механизм перекрывающихся регистровых окон, предназначенный для уменьшения числа обращений к ОП и межрегистровых передач, что способствует повышению производительности ЭВМ. Процедурам динамически выделяются небольшие группы регистров фиксированной длины (регистровые окна). Окна последовательно выполняемых процедур перекрываются, благодаря чему возможна передача параметров от одной процедуры к другой При вызове процедуры процессор переключается на работу с другим регистровым окном, при этом не возникает необходимости в передаче содержимого регистров в память. Окно состоит из трех подгрупп регистров (рис. 9.21). Первая подгруппа содержит параметры, переданные данной процедуре от ее вызвавшей, и результаты для вызывающей процедуры при возврате в нее. Вторая подгруппа содержит локальные переменные процедуры. Третья, являясь буфером для двустороннего обмена между данной и ею вызываемой следующей процедурами, передает последней параметры от данной, которая, в свою очередь, получает через этот буфер результаты от ею вызванной процедуры. Таким образом, одна и та же подгруппа для данной процедуры является регистрами временного хранения, а для следующей — регистрами параметров. Отдельное окно, доступное всем процедурам программы, выделяется для ее глобальных переменных. В 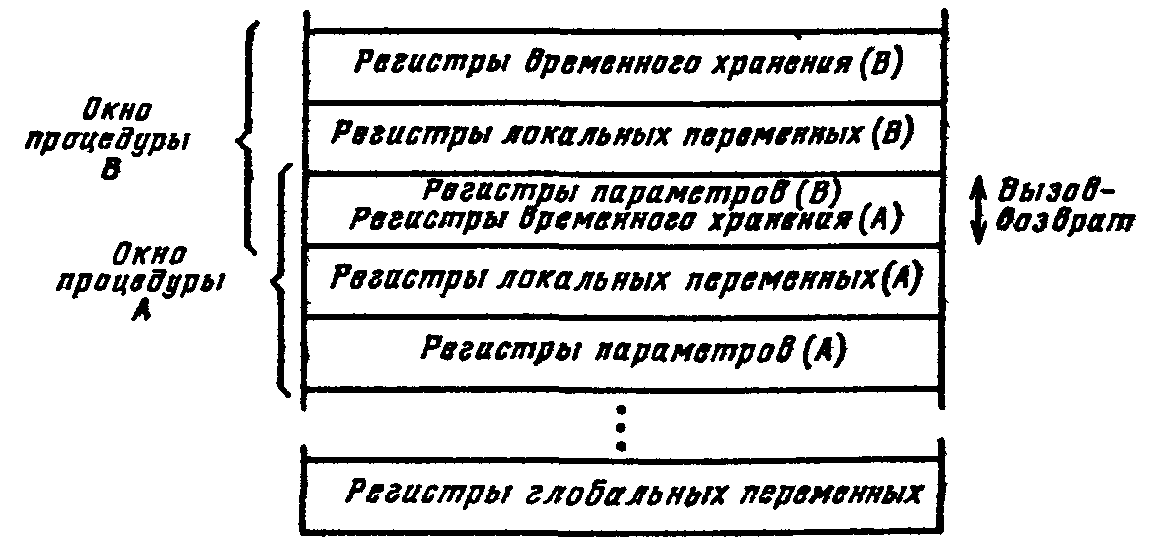 Рис 9.21. СНК-архитектура ЭВМ. Перекрывающиеся регистровые окна. настоящее время за рубежом выпущен ряд микропроцессоров с RISC-архитектурой. Примером являются высокопроизводительные станции на базе микропроцессора Alpha 21264, микропроцессор для WindowsCE Intel StrongARM. Несмотря на начавшееся использование RISC-архитектуры в выпускаемой промышленностью ЭВМ, продолжаются дискуссии вокруг достоинств и недостатков этой архитектуры. К последним, в частности, относят большую длину кода программы после компиляции по сравнению с длиной кода машин обычной архитектуры. Например, при эмуляции команд x86 в среднем на каждую его команду требуется пять-шесть команд машины с RISC-архитектурой. Однако, как показали исследования, выигрыш в скорости выполнения команд перекрывает проигрыш от удлинения объектного кода программы. В 1989 фирме Intel удалось на основе RISC-архитектуры создать однокристальный микропроцессор 80860, который практически представляет собой кремниевый эквивалент суперЭВМ Gray-1. Классификация архитектур микропроцессоров Развитие архитектуры ЭВМ, направленное на повышение их производительности, во многих случаях идет по пути усложнения процессоров путем расширения системы (набора) команд, введения сложных команд, выполняющих процедуры, приближающиеся к примитивам языков высокого уровня, увеличения числа используемых способов адресации и т. д. Однако расширение и усложнение набора команд порождают и ряд нежелательных побочных эффектов. Расширение набора команд, увеличение числа способов адресации, введение сложных команд сопровождаются увеличением длины кода команды, в первую очередь, кода операции, что может приводить к использованию «расширяющегося кода операции», увеличению числа форматов команд. Это вызывает усложнение и замедление процесса дешифрации кода операции и других процедур обработки команд. Возрастающая сложность процедур обработки команд заставляет прибегать к микропрограммным управляющим устройствам с управляющей памятью вместо более быстродействующих УУ с «жесткой» («схемной») логикой. Усложнение процессора делает более трудным или даже невыполнимым реализацию его на одном кристалле интегральной микросхемы, что благодаря сокращению длин межсоединений могло бы облегчить достижение высокой производительности. Анализ кода программ, генерируемого компиляторами языков высокого уровня, показал, что практически используется только ограниченный набор простых команд форматов "регистр, регистр -> регистр" и "регистр <-> память". Компиляторы не в состоянии эффективно использовать сложные команды. Именно это наблюдение способствовало формированию концепции процессоров с сокращенным набором команд, так называемых RISC-процессоров. Другим обстоятельством, фактически приведшим к появлению RISC-процессоров, было развитие архитектуры конвейерных процессоров типа Cray. В этих процессорах используются отдельные наборы команд для работы с памятью и отдельные наборы команд для преобразования информации в регистрах процессора. Каждая такая команда единообразно разбивается на небольшое количество этапов с одинаковым временем исполнения (выборка команды, дешифрация команды, исполнение, запись результата), что позволяет построить эффективный конвейер процессора, способный каждый такт выдавать результат исполнения очередной команды. Однако конвейерность исполнения команд породила проблемы, связанные с зависимостями по данным и управлению между последовательно запускаемыми в конвейер командами. Например, если очередная команда использует результат предыдущей, то ее исполнение невозможно в течение нескольких тактов, необходимых для получения этого результата. Аналогичные проблемы возникают при исполнении команд перехода по условию, когда данные, по которым производится переход, к моменту дешифрации команды условного перехода еще не готовы. Эти проблемы решаются либо компилятором, устанавливающим очередность запуска команд в конвейере и вставляющим команды "Нет операции" при невозможности запуска очередной команды, либо специальной аппаратурой процессора, отслеживающей зависимости между командами и устраняющей конфликты. После обособления RISC-процессоров в отдельный класс, процессоры с традиционными наборами команд стали называться CISC-процессорами с полным набором команд. Как правило, в этих процессорах команды имеют много разных форматов и требуют для своего представления различного числа ячеек памяти. Это обусловливает определение типа команды в ходе ее дешифрации при исполнении, что усложняет устройство управления процессора и препятствует повышению тактовой частоты до уровня, достижимого в RISC-процессорах на той же элементной базе. Очевидно, что RISC-процессоры эффективны в тех областях применения, в которых можно продуктивно использовать структурные способы уменьшения времени доступа к оперативной памяти. Если программа генерирует произвольные последовательности адресов обращения к памяти и каждая единица данных используется только для выполнения одной команды, то фактически производительность процессора определяется временем обращения к основной памяти. В этом случае использование сокращенного набора команд только ухудшает эффективность, так как требует пересылки операндов между памятью и регистром вместо выполнения команд "память, память - память". Программист должен учитывать необходимость локального размещения обрабатываемых данных, чтобы при пересылках между уровнями памяти по возможности все данные пересылаемых блоков данных принимали участие в обработке. Если программа будет написана так, что данные будут размещены хаотично и из каждого пересылаемого блока данных будет использоваться только небольшая их часть, то скорость обработки замедлится в несколько раз до скорости работы основной памяти. В качестве примера приведем в таблице 1.1 результаты замеров производительности микропроцессора Alpha 21066 233 Мгц при реализации преобразования Адамара при n = 8 - 20. Таблица 1.1 Производительность микропроцессора Alpha 2I066 при выполнении преобразования Адамара
|