загрузка. загружено. Курс лекций для студентов специальности 071900 (230201) Информационные системы и технологии
 Скачать 0.78 Mb. Скачать 0.78 Mb.
|

Лекция 1. Представление знаний и выводы на знаниях. Введение. Данные и знания.При изучении интеллектуальных систем традиционно возникает вопрос —(что же такое знания и чем они отличаются от обычных данных} десятилетиями обрабатываемых ЭВМ. Можно предложить несколько рабочих определений, в рамках которых это становится очевидным. Данные — это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства. При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы: D1 — данные как результат измерений и наблюдений; D2 — данные на материальных носителях информации (таблицы, протоколы, справочники); D3 — модели (структуры) данных в виде диаграмм, графиков, функций; D4 — данные в компьютере на языке описания данных; D5 — базы данных на машинных носителях информации. Знания основаны на данных, полученных эмпирическим путем. Они представляет собой результат мыслительной деятельности человека, направленной на обобщение его опыта, полученного в результате практической деятельности. Знания — это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области. При обработке на ЭВМ знания трансформируются аналогично данным. Z1 — знания в памяти человека как результат мышления; Z2 — материальные носители знаний (учебники, методические пособия); Z3 — поле знаний — условное описание основных объектов предметной области, их атрибутов и закономерностей, их связывающих; Z4 — знания, описанные на языках представления знаний (продукционные языки, семантические сети, фреймы — см. далее); 5. Z5 — база знаний на машинных носителях информации. Часто используется такое определение знаний. Знания — это хорошо структурированные данные, или данные о данных, или метаданные. Существует множество способов определять понятия. Один из широко применяемых способов основан на идее интенсионала. Интенсионал понятия — это определение его через соотнесение с понятием более высокого уровня абстракции с указанием специфических свойств. Интенсионалы формулируют знания об объектах. Другой способ определяет понятие через соотнесение с понятиями более низкого уровня абстракции или перечисление фактов, относящихся к определяемому объекту. Это есть определение через данные, или экстенсионал понятия. Пример 1.1 Понятие «персональный компьютер». Его интенсионал: «Персональный компьютер — это дружественная ЭВМ, которую можно поставить на стол и купить менее чем за $2000-3000». Экстенсионал этого понятия: «Персональный компьютер — это Mac, IBMPC, Sinkler...» Для хранения данных используются базы данных (для них характерны большой объем и относительно небольшая удельная стоимость информации), для хранения знаний — базы знаний (небольшого объема, но исключительно дорогие информационные массивы). База знаний — основа любой интеллектуальной системы. Знания могут быть классифицированы по следующим категориям: Поверхностные — знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области. Глубинные — абстракции, аналогии, схемы, отображающие структуру и природу процессов, протекающих в предметной области. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов. Пример 1.2 Поверхностные знания: «Если нажать на кнопку звонка, раздастся звук. Если болит голова, то следует принять аспирин». Глубинные знания: «Принципиальная электрическая схема звонка и проводки. Знания физиологов и врачей высокой квалификации о причинах, видах головных болей и методах их лечения». Современные экспертные системы работают в основном с поверхностными знаниями. Это связано с тем, что на данный момент нет универсальных методик, позволяющих выявлять глубинные структуры знаний и работать с ними. Кроме того, в учебниках по ИИ знания традиционно делят на процедурные и декларативные. Исторически первичными были процедурные знания, то есть знания, «растворенные» в алгоритмах. Они управляли данными. Для их изменения требовалось изменять программы. Однако с развитием искусственного интеллекта приоритет данных постепенно изменялся, и все большая часть знаний сосредоточивалась в структурах данных (таблицы, списки, абстрактные типы данных), то есть увеличивалась роль декларативных знаний. Сегодня знания приобрели чисто декларативную форму, то есть знаниями считаются предложения, записанные на языках представления знаний, приближенных к естественному и понятных неспециалистам. Лекция 2. Представление знаний и выводы на знаниях. Модели представления знаний. Выводы на знаниях. Существуют десятки моделей (или языков) представления знаний для различных предметных областей. Большинство из них может быть сведено к следующим классам: продукционные модели; семантические сети; фреймы; формальные логические модели. Продукционная модель Продукционная модель или модель, основанная на правилах, позволяет представить знания в виде предложений типа «Если (условие), то (действие)». Под «условием» {антецедентом) понимается некоторое предложение-образец, по которому осуществляется поиск в базе знаний, а под «действием» (консеквентом) — действия, выполняемые при успешном исходе поиска (они могут быть промежуточными, выступающими далее как условия и терминальными или целевыми, завершающими работу системы). Чаше всего вывод на такой базе знаний бывает прямой (от данных к поиску цели) или обратный (от цели для ее подтверждения — к данным). Данные — это исходные факты, хранящиеся в базе фактов, на основании которых запускается машинавывода или интерпретатор правил, перебирающий правила из продукционной базы знаний (см. далее). Продукционная модель чаще всего применяется в промышленных экспертных системах. Она привлекает разработчиков своей наглядностью, высокой модульностью, легкостью внесения дополнений и изменений и простотой механизма логического вывода. Имеется большое число программных средств, реализующих продукционный подход (язык OPS 5; «оболочки» или «пустые» ЭС — EXSYS Professional, Kappa, ЭКСПЕРТ; ЭКО, инструментальные системы ПИЭС [Хорошевский, 1993] и СПЭИС [Ковригин, Перфильев, 1988] и др.), а также промышленных ЭС на его основе (например, ЭС, созданных средствами G2 [Попов, 1996]) и др. Семантические сети Термин семантическая означает «смысловая», а сама семантика — это наука, устанавливающая отношения между символами и объектами, которые они обозначают, то есть наука, определяющая смысл знаков. Семантическая сеть — это ориентированный граф, вершины которого — понятия, а дуги — отношения между ними. В качестве понятий обычно выступают абстрактные или конкретные объекты, а отношения — это связи типа: «это» («АКО — A-Kind-Of», «is»), «имеет частью» («has part»), «принадлежит», «любит». Характерной особенностью семантических сетей является обязательное наличие трех типов отношений: класс — элемент класса (цветок — роза); свойство — значение (цвет — желтый); пример элемента класса (роза — чайная). Можно предложить несколько классификаций семантических сетей, связанных с типами отношений между понятиями. По количеству типов отношений: Однородные (с единственным типом отношений). Неоднородные (с различными типами отношений). По типам отношений: Бинарные (в которых отношения связывают два объекта). • N-арные (в которых есть специальные отношения, связывающие более двух понятий). Наиболее часто в семантических сетях используются следующие отношения: связи типа «часть — целое» («класс — подкласс», «элемент —множество», и т. п.); функциональные связи (определяемые обычно глаголами «производит», «влияет»...); количественные (больше, меньше, равно...); пространственные (далеко от , близко от, за, под, над...); временные (раньше, позже, в течение...); атрибутивные связи (иметь свойство, иметь значение); логические связи (И, ИЛИ, НЕ); лингвистические связи и др. Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, отражающей поставленный запрос к базе. Пример 1.3 На рис. 1.1 изображена семантическая сеть. В качестве вершин тут выступают понятия «человек», «т. Иванов», «Волга», «автомобиль», «вид транспорта» и «двигатель». 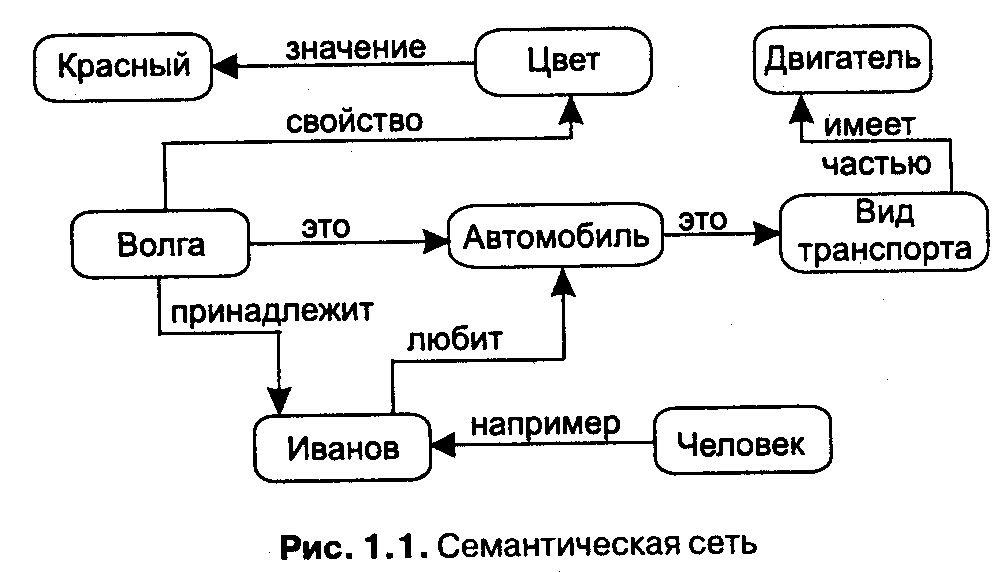 Данная модель представления знаний была предложена американским психологом Куиллианом. Основным ее преимуществом является то, что она более других соответствует современным представлениям об организации долговременной памяти человека [Скрэгг, 1983]. Недостатком этой модели является сложность организации процедуры поиска вывода на семантической сети. Для реализации семантических сетей существуют специальные сетевые языки, например NET [Цейтин, 1985], язык реализации систем SIMER+MIR [Осипов, 1997] и др. Широко известны экспертные системы, использующие семантические сети в качестве языка представления знаний — PROSPECTOR, CASNET, TORUS [Хейес-Рот и др., 1987; Durkin, 1998]. Фреймы Термин фрейм (от английского frame, что означает «каркас» или «рамка») был предложен Маренном Минским [Минский, 1979], одним из пионеров ИИ, в 70-е годы для обозначения структуры знаний для восприятия пространственных сцен. Эта модель, как и семантическая сеть, имеет глубокое психологическое обоснование. Фрейм — это абстрактный образ для представления некоего стереотипа восприятия. В психологии и философии известно понятие абстрактного образа. Например, произнесение вслух слова «комната» порождает у слушающих образ комнаты: «жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, площадью 6-20 м2». Из этого описания ничего нельзя убрать (например, убрав окна, мы получим уже чулан, а не комнату), но в нем есть «дырки» или «слоты» — это незаполненные значения некоторых атрибутов — например, количество окон, цвет стен, высота потолка, покрытие пола и др. В теории фреймов такой образ комнаты называется фреймом комнаты. Фреймом также называется и формализованная модель для отображения образа. Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных фактических ситуаций на основе поступающих данных. Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о мире через: фреймы-структуры, использующиеся для обозначения объектов и понятий (заем, залог, вексель); фреймы-роли (менеджер, кассир, клиент); фреймы-сценарии (банкротство, собрание акционеров, празднование именин); • фреймы-ситуации (тревога, авария, рабочий режим устройства) и др. Традиционно структура фрейма может быть представлена как список свойств: (ИМЯ ФРЕЙМА: (имя 1-го слота: значение 1-го слота), (имя 2-го слота: значение 2-го слота), (имя N-ro слота: значение N-ro слота)). Ту же запись можно представить в виде таблицы, дополнив ее двумя столбцами. Таблица 1.1. Структура фрейма
В таблице дополнительные столбцы предназначены для описания способа получения слотом его значения и возможного присоединения к тому или иному слоту специальных процедур, что допускается в теории фреймов. В качестве значения слота может выступать имя другого фрейма, так образуются сети фреймов. Существует несколько способов получения слотом значений во фрейме-экземпляре: по умолчанию от фрейма-образца (Default-значение); через наследование свойств от фрейма, указанного в слоте АКО; по формуле, указанной в слоте; через присоединенную процедуру; явно из диалога с пользователем; из базы данных. Важнейшим свойством теории фреймов является заимствование из теории семантических сетей — так называемое наследование свойств. И во фреймах, и в семантических сетях наследование происходит по АКО-связям (A-Kind-Of= это). Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно наследуются, то есть переносятся, значения аналогичных слотов. Пример 1.4 Например, в сети фреймов на рис. 1.2 понятие «ученик» наследует свойства фреймов «ребенок» и «человек», которые находятся на более высоком уровне иерархии. Так, на вопрос «любят ли ученики сладкое» следует ответ «да», так как этим свойством обладают все дети, что указано во фрейме «ребенок». Наследование свойств может быть частичным, так как возраст для учеников не наследуется из фрейма «ребенок», поскольку указан явно в своем собственном фрейме. 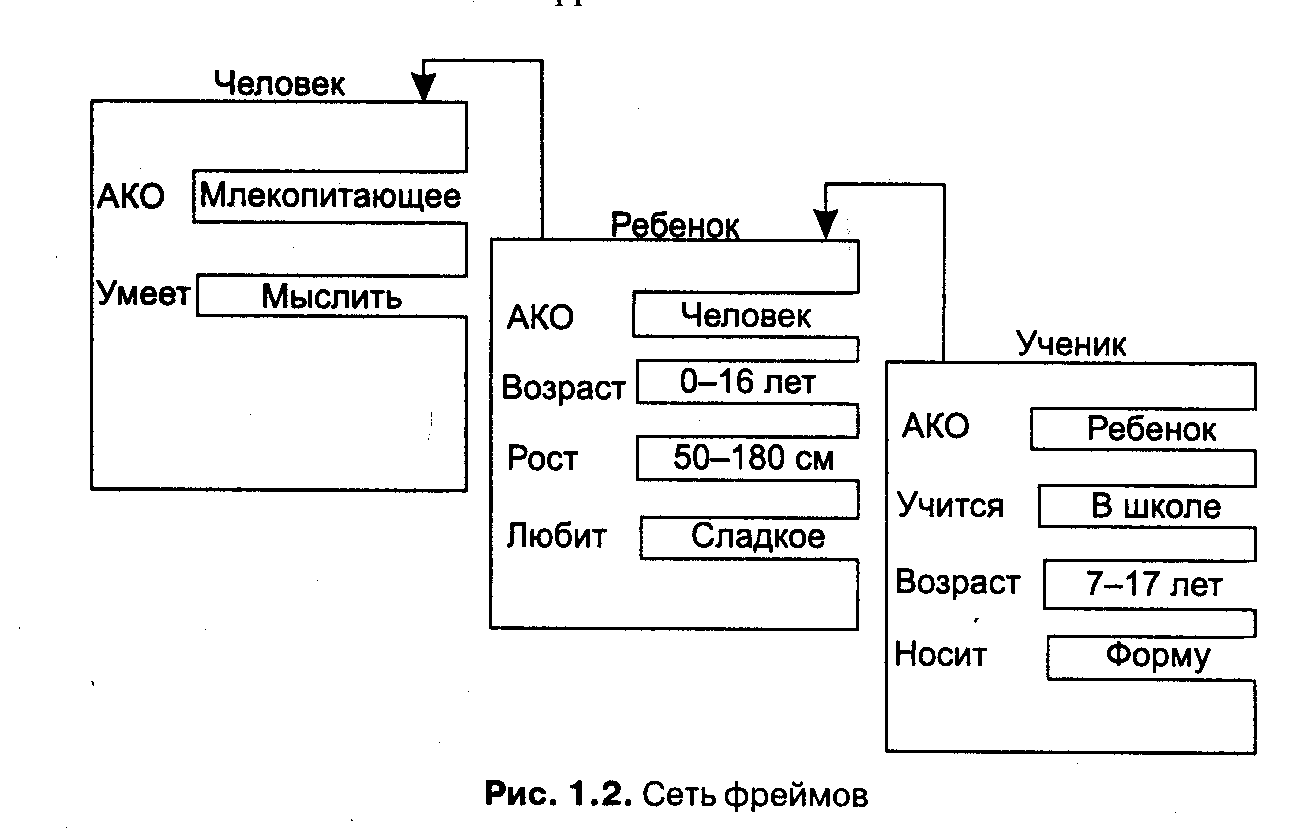 Основным преимуществом фреймов как модели представления знаний является ) на отражает концептуальную основу организации памяти человека [Шенк, 1987J, а также ее гибкость и наглядность. Специальные языки представления знаний в сетях фреймов FRL (Frame Representation Language) [Байдун, Бунин, 1990], KRL (Knowledge Representation Language) [Уотермен, 1989], фреймовая «оболочка» Kappa [Стрельников, Борисов, 1997] и другие программные средства позволяют эффективно строить промышленные ЭС. Широко известны такие фрейм-ориентированные экспертные системы, как ANALYST, МОДИС, TRISTAN, ALTERID [Ковригин, Перфильев, 1988; Николов, 1988; Sisodia, Warkentin, 1992]. Формальные логические модели Традиционно в представлении знаний выделяют формальные логические модели, основанные на классическом исчислении предикатов 1-го порядка, когда предметная область или задача описывается в виде набора аксиом. Мы же опустим описание этих моделей по следующим причинам. Исчисление предикатов 1-го порядка в промышленных экспертных системах практически не используется. Эта логическая модель применима в основном в исследовательских «игрушечных» системах, так как предъявляет очень высокие требования и ограничения к предметной области. В промышленных же экспертных системах используются различные ее модификации и расширения, изложение которых выходит за рамки этого учебника. Вывод на знанияхНесмотря на все недостатки, наибольшее распространение получила продукционная модель представления знаний. При использовании продукционной модели база знаний состоит из набора правил. Программа, управляющая перебором правил, называется машиной вывода. Машина вывода Машина вывода (интерпретатор правил) выполняет две функции: во-первых, просмотр существующих фактов из рабочей памяти (базы данных) и правил из базы знаний и добавление (по мере возможности) в рабочую память новых фактов и, во-вторых, определение порядка просмотра и применения правил. Этот механизм управляет процессом консультации, сохраняя для пользователя информацию о полученных заключениях, и запрашивает у него информацию, когда для срабатывания очередного правила в рабочей памяти оказывается недостаточно данных [Осуга, Саэки, 1990]. В подавляющем большинстве систем, основанных на знаниях, механизм вывода представляет собой небольшую по объему программу и включает два компонента — один реализует собственно вывод, другой управляет этим процессом. Действие компонента вывода основано на применении правила, называемого modusponens. Правило modusponens. Если известно, что истинно утверждение А и существует правило вида «ЕСЛИ А, ТО В», тогда утверждение В также истинно. Правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение. Компонент вывода должен функционировать даже при недостатке информации. Полученное решение может и не быть точным, однако система не должна останавливаться из-за того, что отсутствует какая-либо часть входной информации. Управляющий компонент определяет порядок применения правил и выполняет четыре функции. Сопоставление — образец правила сопоставляется с имеющимися фактами. Выбор — если в конкретной ситуации может быть применено сразу несколько правил, то из них выбирается одно, наиболее подходящее по заданному критерию (разрешение конфликта). Срабатывание — если образец правила при сопоставлении совпал с какими-либо фактами из рабочей памяти, то правило срабатывает. Действие — рабочая память подвергается изменению путем добавления в нее заключения сработавшего правила. Если в правой части правила содержится указание на какое-либо действие, то оно выполняется (как, например, в системах обеспечения безопасности информации). Интерпретатор продукций работает циклически. В каждом цикле он просматривает все правила, чтобы выявить те, посылки которых совпадают с известными на данный момент фактами из рабочей памяти. После выбора правило срабатывает, его заключение заносится в рабочую память, и затем цикл повторяется сначала. В одном цикле может сработать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по определенному критерию единственного правила, которое срабатывает в данном цикле. Цикл работы интерпретатора схематически представлен на рис. 1.3. 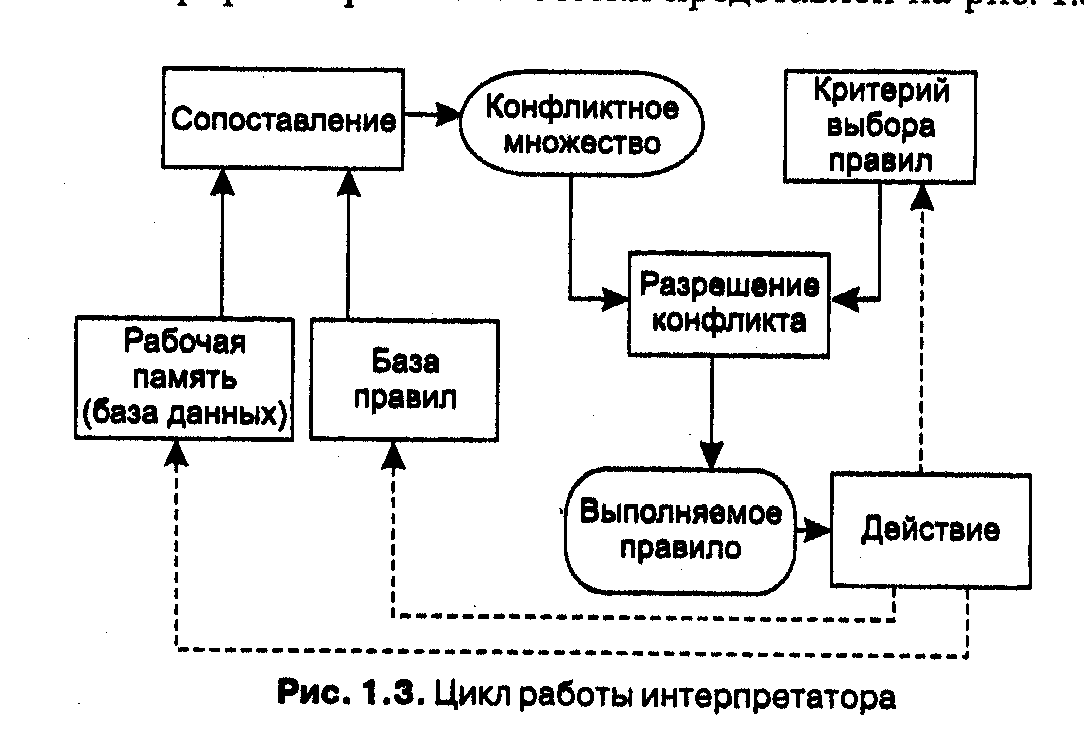 Информация из рабочей памяти последовательно сопоставляется с посылками правил для выявления успешного сопоставления. Совокупность отобранных правил составляет так называемое конфликтное множество. Для разрешения конфликта интерпретатор имеет критерий, с помощью которого он выбирает единственное правило, после чего оно срабатывает. Это выражается в занесении фактов, образующих заключение правила, в рабочую память или в изменении критерия выбора конфликтующих правил. Если же в заключение правила входит название какого-нибудь действия, то оно выполняется. Работа машины вывода зависит только от состояния рабочей памяти и от состава базы знаний. На практике обычно учитывается история работы, то есть поведение механизма вывода в предшествующих циклах. Информация о поведении механизма вывода запоминается в памяти состояний (рис. 1.4). Обычно память состояний содержит протокол системы. 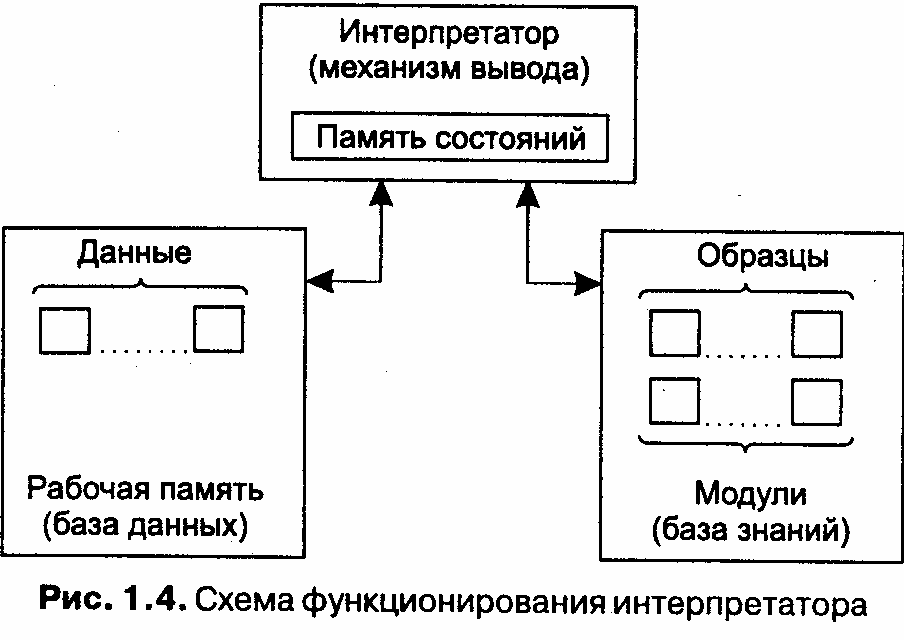 Стратегии управления выводом От выбранного метода поиска, то есть стратегии вывода, будет зависеть порядок применения и срабатывания правил. Процедура выбора сводится к определению направления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно «зашиты» в механизм вывода, поэтому в большинстве систем инженеры знаний не имеют к ним доступа и, следовательно, не могут в них ничего изменять по своему желанию. При разработке стратегии управления выводом важно определить два вопроса: Какую точку в пространстве состояний принять в качестве исходной? От выбора этой точки зависит и метод осуществления поиска — в прямом или обратном направлении. Какими методами можно повысить эффективность поиска решения? Эти методы определяются выбранной стратегией перебора — глубину, в ширину, по подзадачам или иначе. Прямой и обратный вывод П 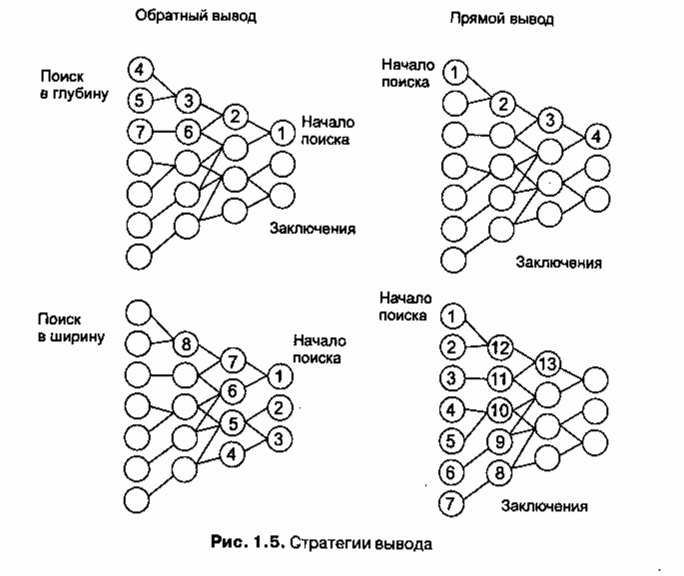 ри обратном порядке вывода вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам, пытаясь найти те, которые подтверждают гипотезу (рис. 1.5, правая часть). Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями, или управляемым консеквентами. Обратный поиск применяется в тех случаях, когда цели известны и их сравнительно немного. В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует (см. рис. 1.5, левая часть). Если такое заключение удается найти, то оно заносится в рабочую память. Прямой вывод часто называют выводом, управляемым данными, или выводом, управляемым антецедентами. Существуют системы, в которых вывод основывается на сочетании упомянутых выше методов — обратного и ограниченного прямого. Такой комбинированный метод получил название циклического. Пример 1.5 Имеется фрагмент базы знаний из двух правил: П1. Если «отдых — летом» и «человек — активный», то «ехать в горы». П2. Если «любит солнце», то «отдых летом». Предположим, в систему поступили факты — «человек активный» и «любит солнце». ПРЯМОЙ ВЫВОД— исходя из фактических данных, получить рекомендацию. 1-й проход. Шаг 1. Пробуем П1, не работает (не хватает данных «отдых — летом»). Шаг 2. Пробуем П2, работает, в базу поступает факт «отдых — летом». 2-й проход. Шаг 3. Пробуем П1, работает, активируется цель «ехать в горы», которая и выступает как совет, который дает ЭС. ОБРАТНЫЙ ВЫВОД — подтвердить выбранную цель при помощи имеющихся правил и данных. 1-й проход. Шаг 1. Цель — «ехать в горы»: пробуем П1 — данных «отдых — летом» нет, они становятся новой целью и ищется правило, где цель в левой части. Шаг 2. Цель «отдых — летом»: правило П2 подтверждает цель и активирует ее. 2-й проход. Шаг 3. Пробуем П1, подтверждается искомая цель. . Методы поиска в глубину и ширину В системах, база знаний которых насчитывает сотни правил, желательным является использование стратегии управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся: поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета алгоритм [Таунсенд, Фохт, 1991; Уэно, Исидзука, 1989; Справочник по ИИ, 1990]. При поиске в глубину в качестве очередной подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи. Например, диагностирующая система, сделав на основе известных симптомов предположение о наличии определенного заболевания, будет продолжать запрашивать уточняющие признаки и симптомы этой болезни до тех пор, пока полностью не опровергнет выдвинутую гипотезу. При поиске в ширину, напротив, система вначале проанализирует все симптомы, находящиеся на одном уровне пространства состояний, даже если они относятся к разным заболеваниям, и лишь затем перейдет к симптомам следующего уровня детальности. Разбиение на подзадачи — подразумевает выделение подзадач, решение которых рассматривается как достижение промежуточных целей на пути к конечной цели. Примером, подтверждающим эффективность разбиения на подзадачи, является поиск неисправностей в компьютере — сначала выявляется отказавшая подсистема (питание, память и т. д.), что значительно сужает пространство поиска. Если удается правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей-подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимален. Альфа-бета алгоритм позволяет уменьшить пространство состояний путем удаления ветвей, неперспективных для успешного поиска. Поэтому просматриваются только те вершины, в которые можно попасть в результате следующего шага, после чего неперспективные направления исключаются. Альфа-бета алгоритм нашел широкое применение в основном в системах, ориентированных на различные игры, например в шахматных программ. Лекция 3. Представление знаний и выводы на знаниях. Краткая история искусственного интеллекта. Искусственный интеллект в России. В 1954 г. в МГУ начал свою работу семинар «Автоматы и мышление» под руководством академика Ляпунова А. А. (1911-1973), одного из основателей российской кибернетики. В этом семинаре принимали участие физиологи, лингвисты, психологи, математики. Принято считать, что именно в это время родился искусственный интеллект в России. Как и за рубежом, выделились два основных направления — ней-. кибернетики и кибернетики «черного ящика». В 1954-1964 гг. создаются отдельные программы и проводятся исследования в области поиска решения логических задач. В Ленинграде (ЛОМИ — Ленинградское отделение математического института им. Стеклова) создается программа АЛПЕВ ЛОМИ, автоматически доказывающая теоремы. Она основана на оригинальном обратном выводе Маслова, аналогичном методу резолюций Робинсона. Среди наиболее значимых результатов, полученных отечественными учеными в 60-е годы, следует отметить алгоритм «Кора» М. М. Бонгарда, моделирующий деятельность человеческого мозга при распознавании образов. Большой вклад в становление российской школы ИИ внесли выдающиеся ученые ЦетлинМ.Л. ,Пушкин В. Я., Гаврилов М. А, чьи ученики и явились пионерами этой науки в России ( например, знаменитая Гавриловская школа). В 1965-1980 гг. происходит рождение нового направления — ситуационного управления (соответствует представлению знаний, в западной терминологии). Основателем этой научной школы стал проф. Поспелов Д. А. Были разработаны специальные модели представления ситуаций — представления знаний [Поспелов, 1986]. В ИПМ АН СССР был создан язык символьной обработки данных РЕФАЛ [Тургин, 1968]. При том что отношение к новым наукам в советской России всегда было настороженное, наука с таким «вызывающим» названием тоже не избежала этой участи и была встречена в Академии наук в штыки [Поспелов, 1997]. К счастью, даже среди членов Академии наук СССР нашлись люди, не испугавшиеся столь необычного словосочетания в качестве названия научного направления. Двое из них сыграли огромную роль в борьбе за признание ИИ в нашей стране. Это были академики А. И. Берг и Г. С. Поспелов. Только в 1974 году при Комитете по системному анализу при президиуме АН СССР был создан Научный совет по проблеме «Искусственный интеллект», его возглавил Г. С. Поспелов, его заместителями были избраны Д. А. Поспелов и Л. И. Микулич. В состав совета входили на разных этапах М. Г. Гаазе-Рапопорт, Ю. И. Журавлев, Л. Т. Кузин, А. С. Нариньяни, Д. Е. Охоцимский, А. И. Половинкин, О. К. Тихомиров, В. В. Чавчанидзе. По инициативе Совета было организовано пять комплексных научных проектов, которые были возглавлены ведущими специалистами в данной области. Проекты объединяли исследования в различных коллективах страны: «Диалог» (работы по пониманию естественного языка, руководители А. П. Ершов, А. С. Нариньяни), «Ситуация» (ситуационное управление, Д. А. Поспелов), «Банк» (банки данных, Л. Т. Кузин), «Конструктор» (поисковое конструирование, А. И. Поло-винкин), «Интеллект робота» (Д. Е. Охоцимский). В 1980-1990 гг. проводятся активные исследования в области представления знаний, разрабатываются языки представления знаний, экспертные системы (более 300). В 1988 г. создается АИИ — Ассоциация искусственного интеллекта. Ее членами являются более 300 исследователей. Президентом Ассоциации единогласно избирается Д. А. Поспелов, выдающийся ученый, чей вклад в развитие ИИ в России трудно переоценить. Крупнейшие центры — в Москве, Петербурге, Переславле-Залесском, Новосибирске. В научный совет Ассоциации входят ведущие исследователи в области ИИ — В. П. Гладун, В. И. Городецкий, Г. С. Осипов, Э. В. Попов, В. Л. Стефанюк, В. Ф. Хорошевский, В. К. Финн, Г. С. Цейтин, А. С. Эрлих и другие ученые. В рамках Ассоциации проводится большое количество исследований, организуются школы для молодых специалистов, семинары, симпозиумы, раз в два года собираются объединенные конференции, издается научный журнал. Уровень теоретических исследований по искусственному интеллекту в России ничуть не ниже мирового. К сожалению, начиная с 80-х гг. на прикладных работах начинает сказываться постепенное отставание в технологии. На данный момент отставание в области разработки промышленных интеллектуальных систем составляет порядка 3-5 лет. | ||||||||||||||||||||