Лекции и практики (1). Курс лекций и материалы для практических занятий
 Скачать 1.01 Mb. Скачать 1.01 Mb.
|

Использование хешированияХеширование таблицы полезно в следующих случаях: В таблице есть уникальный ключ, и большинство запросов обращается к за- писям по значению этого ключа, например: SELECT <список выбора> FROM <таблица> WHERE unique_key = <значение>; Значение, указанное в условии, хешируется; по этому хеш-значению проис- ходит прямой доступ к соответствующему блоку данных (обычно, одно фи- зическое чтение, если нет коллизий и запись помещается в одном блоке). Для неуникального хеш-ключа все записи с таким значением ключа поме- щаются в одном блоке, который также можно прочитать за один раз. Таблица практически статична (редко обновляется). Число записей и их средний размер можно определить заранее и сразу выделить под таблицу требуемое физическое пространство. Хеширование не рекомендуется в следующих случаях: Нельзя сразу выделить столько памяти, сколько требуется таблице. Если по- требуется выделять таблице дополнительную память, эта память будет отве- дена под коллизионные страницы, что сильно ухудшит производительность (это следует из формулы (5.3), по которой рассчитывается адрес записи). Большинство запросов выбирает записи в некотором интервале значений ключа. Хеширование не даёт здесь преимуществ, т.к. записи обычно не упо- рядочены, и система использует последовательное чтение. Эффективность использования хеширования не в последней степени определяется качеством хеш-функции. Системы, поддерживающие возмож- ность хеширования данных, обычно имеют встроенную хеш-функцию, но и позволяют пользователю задавать свою. Это может понадобиться тогда, когда встроенная хеш-функция не даёт хороших результатов, а пользовательская хеш-функция может учесть особенности распределения значений конкретного ключа. Если же ключ является уникальным и распределение его значений рав- номерно, то сами значения могут быть использованы в качестве хеш-значений (тогда данные будут размещаться в порядке увеличения значений хеш-ключа). Лекция 6.Кластеризация данных Принцип организации кластеровКластеризация является методом совместного хранения родственных данных (таблиц). Кластер – это структура памяти, в которой хранится набор таблиц (в одних и тех же блоках памяти). Таблицы, помещаемые в кластер, должны иметь общие столбцы, используемые для соединения (например, пер- вичный ключ таблицы ТОВАРЫи внешний ключ таблицы ПОСТАВКИ, рис. 5.8,б). Кластерный ключ (КК) – это поле или набор полей, общих для всех таб- лиц кластера. Каждая таблица, хранимая в кластере, должна иметь поля, соот- ветствующие типам и размерам полей кластерного ключа. Количество полей в кластерном ключе ограничено (например, для Oracle это ограничение равно 16). Совместное хранение данных означает, что на одной странице или в од- ном блоке памяти хранятся данные из всех кластеризованных таблиц, имеющие одинаковое значение кластерного ключа. Физически это обычно реализуется так: в начале страницы (блока) хранится запись из таблицы, для которой кла- стерный ключ является первичным (или уникальным), а вслед за ней распола- гаются записи из другой таблицы (таблиц), имеющие те же значения кластерно-  го ключа. Фактически, данные хранятся в виде соединения таблиц по значени- ям кластерного ключа. Поэтому соединение кластеризованных таблиц по срав- нению с раздельно хранимыми таблицами выполняется в 3-6 раз быстрее. го ключа. Фактически, данные хранятся в виде соединения таблиц по значени- ям кластерного ключа. Поэтому соединение кластеризованных таблиц по срав- нению с раздельно хранимыми таблицами выполняется в 3-6 раз быстрее.
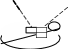 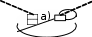 Рис. 5.8. Некластеризованные (а) и кластеризованные (б) данные Рис. 5.8. Некластеризованные (а) и кластеризованные (б) данныеЕсли все данные, относящиеся к одному значению кластерного ключа, не помещаются в одном блоке, то выделяется новый блок памяти и предыдущий блок хранит ссылку на него. Но если система позволяет изменять размер блока (в частности, СУБД Oracle), при создании кластера желательно установить раз- мер блока исходя из оценки среднего объёма записей с одинаковыми значения- ми кластерного ключа. Если же записи с одинаковым значением КК занимают только часть блока (например, в среднем 1К при размере блока 4К), то при со- здании таблицы кластера можно указать количество значений КК на один блок. Значения кластерного ключа таблицы могут обновляться. Но это обнов- ление может вызвать физическое перемещение записи, т.к. расположение запи- си зависит от значения кластерного ключа. Поэтому часто обновляющиеся ат- рибуты не являются хорошими кандидатами на вхождение в кластерный ключ. Два основных преимущества кластеров: Уменьшается время соединения таблиц по значению кластерного ключа. Каждое значение кластерного ключа хранится только один раз, за счёт чего достигается экономия памяти. С другой стороны, наличие кластеров обычно увеличивает время выпол- нения операции добавления записи (INSERT): система тратит дополнительное время на поиск блока, в который нужно поместить новую запись. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||