технология проектирования ИС. Реферат на тему _Технологии проектирования ИС_. Лекция Технологии проектирования ис 1 Основные определения
 Скачать 0.49 Mb. Скачать 0.49 Mb.
|

|
1. Первичный ключ должен быть единственным. Первичный ключ - это атрибут, который однозначно определяет каждую строку таблицы (например, код товара может быть первичным ключом для таблицы товаров). Это ограничение еще называют правилом целостности сущности, т.к. если у двух экземпляров сущности один первичный ключ, то их невозможно отличить. 2. Каждый внешний ключ должен быть либо пустым, либо соответствовать одному из значений первичного ключа в другой таблице. Внешний ключ - это атрибут таблицы, который является первичным ключом другой таблицы. Внешние ключи используются для описания связей между сущностями (например, код поставщика в таблице видов товаров задает связь с таблицей поставщиков, что описывает принадлежность товаров тому или иному поставщику). Это ограничение называют правилом ссылочной целостности (например, если в таблице товаров указан код поставщика 1010, то это означает, что поставщик неизвестен или данные о нем утеряны, поэтому в таких случаях вместо просмотра таблицы поставщиков коду поставщика назначают пустое значение). 3. Каждый столбец таблицы должен описывать свойство сущности, определенной первичным ключом (например, в таблице товаров не должно встречаться имя покупателя, иначе получится, что этот товар предназначен только для одного покупателя). 4. В каждой строке таблицы должно содержаться только одно значение (например, таблица поставщиков содержит в каждой строке описание одного и только одного поставщика). 5. В каждом столбце все значения должны быть одного типа данных (например, цена товаров не должна указываться прописью). 6. Порядок строк и столбцов не должен иметь значения. Это означает, что переупорядочение строк или столбцов не должно менять смысла информации, представленной в таблице. Данное свойство означает, например, что не должно быть строк, меняющих смысл содержимого следующих за ней строк (то же самое и для столбцов). Например, в таблице поставщиков не могут содержаться строки с описанием “акционерные общества” или “частные предприятия”, которые предполагают разбиение таблицы на части. Вместо этого надо вводить дополнительный атрибут “тип предприятия”. Другой пример: холодильники в таблице товаров не должны быть упорядочены по объему камеры, вместо этого надо использовать отдельный атрибут. 5.2.2. Нормализация Еще один вопрос, на который необходимо получить ответ: почему данные разбиваются на таблицы, каждая из которых представляет отдельную сущность? Чтобы на него ответить, рассмотрим альтернативный вариант - хранение данных в одной таблице 5.3. Таблица 5.3. Хранение данных о товарах и поставщиках в общей таблице.
Отметим несколько недостатков такого подхода: Избыточность данных. Обратите внимание, что фирма BOSS в общей таблице указана два раза. В больших базах данных при использовании такого подхода могут быть объединены десятки таблиц, и подобных повторений может быть многие тысячи. Результат - неэкономное расходование места на носителях данных и, как следствие, - большой расход времени на поиск нужной информации. Аномалия обновления данных. Всякий раз, когда необходимо будет внести изменения в данные о фирме (например при изменении адреса), придется переделывать несколько записей. В варианте с двумя таблицами данные хранятся только в одном месте. Аномалия вставки записей. В общей таблице отсутствует поставщик “Горизонт”, т.к. он реально не поставляет товары. Это означает, что учесть нового поставщика можно будет только после того, как в таблице появится какой-то его товар. Аномалия удаления. Удаление из общей таблицы холодильника с кодом 1036 приведет к потере всех данных о поставщике “Бирюса”. С помощью разбиения данных на таблицы эти недостатки исчезают, что дает экономию места на носителях данных и намного облегчает работу с ними. При этом само разбиение не является искусственным, а производится в соответствии с внутренней логикой объектов-сущностей, которые моделируются, поэтому облегчается не только оперирование с данными, но и общее понимание того, что содержится в базе данных. Процесс следования правилам разработки реляционных таблиц, позволяющим избежать перечисленных недостатков, называют нормализацией. 5.2.3. Запросы к реляционным базам данных Реляционные БД выполняют три основных типа операций с таблицами при выполнении запросов: 1. Проектирование - создание новой таблицы путем выбора заданных столбцов из исходной таблицы (например, создание списка названий поставщиков). 2. Выбор по условию - создание новой таблицы путем выбора из исходной таблицы строк, удовлетворяющих заданным условиям (например, выбор из таблицы товаров холодильников, которые имеются на складе). 3. Объединение - создание новой таблицы путем выбора заданных столбцов из двух или более таблиц (например, создание таблицы видов товаров с указанием их цены и страны изготовления). Важное свойство реляционной модели данных состоит в том, что результатом запроса всегда является новая таблица, и к ней может быть применен новый запрос. Это позволяет выполнять вложенные запросы и делает языки описания запросов очень мощным инструментом просмотра базы данных (пример простого вложенного запроса - после объединения таблицы товаров с указанием стран - изготовителей, можно выбрать товары, изготовленные за рубежом). При этом физически последовательности таблиц при выполнении вложенных запросов могут и не создаваться. Кроме того, запросы позволяют упорядочивать таблицы (например, выбранные товары расположить в порядке возрастания цены), а также делать итоговые вычисления, используя операцию группировки (например, можно посчитать общую стоимость хранимых на складе холодильников, сгруппировав строки таблицы товаров по описанию товара). В большинстве случаев пользователю даже не обязательно знать ЯОЗ, потому что для выбора из БД часто встречающихся, стандартных типов информации создаются специальные формы, с которыми легко работать. Однако для понимания того, что можно получить из базы данных, надо представлять, как работает язык описания запросов. Реляционные языки описания запросов можно разделить на две большие категории: текстовые ЯОЗ и графические ЯОЗ. Ниже на примерах рассматривается язык четвертого поколения SQL как наиболее широко используемый для определения информационных потребностей пользователей. 5.3. Моделирование данных С точки зрения пользователя наибольшая проблема в организации и доступности информации ИС заключена в 3 вопросах: какая информация содержится в ИС? как информация организована? каким образом пользователь может получить необходимую информацию? В соответствии с действующими в настоящее время идеями разработки систем, ответы на эти вопросы лежат в плоскости моделирования данных-процесса построения концептуальной схемы, обеспечивающей единое определение данных в рамках одного предприятия, не ориентированное на какое-то конкретное их использование и не зависящее от того, как физически осуществляется хранение данных или доступ к ним. Моделирование данных - это процесс определения базы данных с целью непротиворечивой интерпретации и установления взаимосвязей данных для их объединения, совместного использования и управления целостностью данных, адекватно отражающих функционирование организации. Задача, следовательно, состоит в том, чтобы надежно собирать и сохранять данные о всякой деятельности, которую организация хочет планировать, контролировать или оценивать. В процессе моделирования данных осуществляется идентификация сущностей, установление связей между сущностями и описание этих сущностей соответствующим набором атрибутов. Эксперты организации (менеджеры, бухгалтеры) обязательно вовлекаются в создание БД и при этом сталкиваются по крайней мере с двумя инструментами - REA-моделью данных и E-R-диаграммами, которые используются на этапе разработки БД. 5.3.1. REA модель данных REA-модель данных была специально создана для разработки БД, предназначенных для учета операций в организациях. REA - это английские начальные буквы трех фундаментальных типов сущностей. Resources (ресурсы), приобретаемые и используемые организацией. Большинство ресурсов организации традиционно относят к ее активам. Это деньги, материально-производственные запасы, недвижимость и т.д. То есть активы, которые подвергаются учету. Однако для организации может быть важно учитывать и что-то другое, например заказы клиентов. Events (события), которые происходят в организации. В широком понимании - это любая деятельность организации, изменяющая состояние ресурсов. В REA модели событиями считаются не только традиционные бухгалтерские операции (продажи, покупки, выплата зарплаты и т.д.), но и другие операции, о которых организация хочет собрать данные (оформление заказов клиентов, стадии их прохождения и др.). Однако такие события должны напрямую влиять на ресурсы. Например, перенос данных из журнала в главную книгу не будет являться событием, если только какой-то из этих документов не рассматривается как ресурс организации, записи в котором подлежат учету. Agents (участники) этих событий. Участники как сущности - это обычно группы людей, о которых организация собирает данные с целью лучше планировать, контролировать или оценивать их деятельность. Участники всегда вовлечены или имеют отношение к каким-то событиям. Например, продавцы совершают сделки продаж, кассиры принимают деньги, поставщики предоставляют товар, клиенты производят заказы и т.д. Таким образом, REA-модель, с точки зрения организации, предназначена для описания учета как бухгалтерских, так и управленческих данных. Например, кроме даты продажи может учитываться и время дня, чтобы по множеству записей о продажах можно было планировать потребность в обслуживающем персонале в течение рабочего дня и тем самым получить возможность адекватно составлять скользящие графики работы служащих. 5.3.2. E-R-диаграммы E-R-диаграммы (Entity-Relationship, Сущность-Отношение) предназначены для графического изображения схемы БД. Они показывают сущности в виде прямоугольников и отношения между ними в виде линий. Такой простой прием позволяет при разработке БД охватывать взором сложные схемы, иногда состоящие из десятков сущностей, скрывая детали, несущественные на определенном этапе. Для примера рассмотрим E-R диаграмму на рис.5.3, описывающую продажи в розничной торговле. Для упрощения в ней моделируются только два типа событий: оформление продажи и прием платежа. 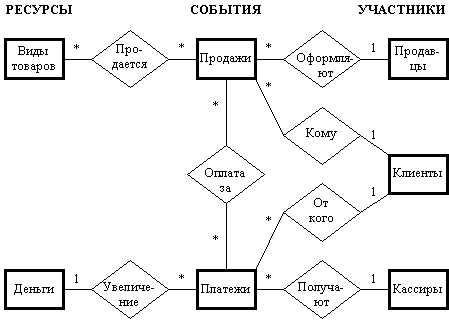 Рис.5.3 E-R- диаграмма, описывающая продажи REA-модель, на основе которой построена данная диаграмма, состоит из 7 сущностей, информация о которых подлежит учету. Поскольку события платежей и продаж являются сделками, то каждое из них связано с двумя участниками и одним предметом сделки. Каждое отношение на диаграмме имеет название-связку, которое позволяет просто понять его смысл (продажи кому? - клиентам, платеж в уплату за продажу и т.д. Продолжите сами для остальных отношений). В дальнейшем каждая из сущностей будет описана в виде таблицы, содержащей ее атрибуты-столбцы и экземпляры-строки. Однако на E-R-диаграмме эти подробности скрыты, позволяя сосредоточиться на разработке концептуальной схемы БД. На диаграмме имеются символы ‘1’ или ‘*’ между каждой сущностью и отношением. Они описывают характер отношения между двумя сущностями. По характеру отношения бывают трех типов: один к одному (1:1), один ко многим (1:*) и многие ко многим (*:*). Характер отношений можно определить, рассматривая их смысл. Например отношение между кассирами и платежами состоит в том, что один кассир может принимать много платежей (*). В то же время каждый отдельный платеж не может быть принят несколькими кассирами, а только одним (1). Аналогично определяется характер отношения между товарами и продажами - многие ко многим (*:*), т.к. один вид товара может быть упомянут во многих сделках продаж (*) и предметом каждой сделки может служить не один, а сразу несколько видов товаров (*). Характер отношения играет важную роль в моделировании деятельности организации с помощью реляционных БД. Чтобы это увидеть, рассмотрим возможные отношения между продажами и платежами. Разработка E-R-диаграммы может быть разложена на 4 шага. Выявление необходимых сущностей. Если мы пользуемся REA-моделью, то этот шаг всегда начинается с определения событий, связанных с деятельностью организации. Продажи и платежи, поставки и покупки, прием и доставка заказов, прием на работу и выплата вознаграждений персоналу, продвижения по службе - все это примеры событий, которые организация может учитывать для обеспечения лучшего принятия решений. После выявления событий для каждого из них определяются ресурсы, состояние которых изменяется после того, как событие произошло. И наконец выявляются участники каждого события. Важно помнить, что в REA-модели под термином “участник” подразумевается не конкретный человек, а его функция в организации. Поэтому один из кассиров и один из продавцов может быть одним и тем же лицом, а для учета персонала при этом потребуется выделение отдельной сущности. При выявлении сущностей важно помнить, что в их число должны попасть только те, которые связаны с проблемами, решаемыми с помощью БД. Иначе организация рискует столкнуться с эффектом информационной перегрузки. Изображение сущностей на диаграмме. Поскольку сущности делятся на три класса и события связаны как с ресурсами, так и с участниками, то прямоугольники для каждой сущности помещаются в три столбца (слева направо): столбец ресурсов, событий и участников. Это облегчает изображение отношений. Возможно, потом для удобства и придется делать перестановки, но только внутри столбцов. Выявление и изображение отношений на диаграмме. При построении E-R-диаграммы не используются прямые отношения между ресурсами и участниками. Это обусловлено самой природой событий, происходящих в организации, поскольку само воздействие участника на ресурс является событием. Изображение ромбов и линий, связывающих две сущности для каждого отношения, несложная задача. Проблемы чаще возникают при подборе удачного названия для отношения. Возможно также, что на этом шаге придется переставить на диаграмме некоторые сущности, чтобы связи не перекрещивались. Определение характера отношений. Характер отношений не является чем-то произвольным, а отражает их природу и определяется двумя факторами: политикой предприятия при проведении своих операций (пример - на рис. 5.4) и спецификой операций (например, отношение клиенты-продажи на рис. 5.3 - один ко многим - отражает тот факт, что любая продажа оформляется только на одного клиента). 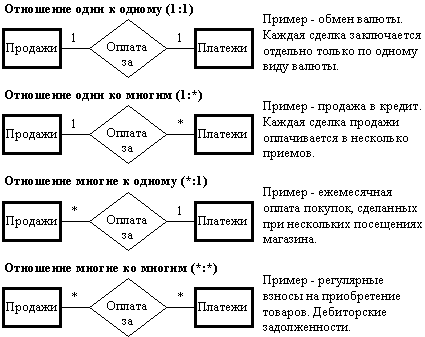 Рис. 5.4. Характер отношения между продажами и платежами Мы рассмотрели моделирование данных с помощью E-R-диаграммы на простом примере. Однако моделирование данных может быть сложным и длительным процессом, сопровождающимся преодолением проблем, связанных со спецификой отрасли и отдельного предприятия, и даже с различиями в терминологии, используемой в разных подразделениях организации. Опишем 4 шага, необходимые для перевода E-R-диаграммы в схему реляционной базы данных. Создание таблиц для каждой сущности и каждого отношения (*:*). Пример на рис.5.3. требует создания 9 таблиц - 7 для каждой из сущностей и 2 для отношений "продажи-товары" и "продажи-платежи". Создание таблиц для отношений (*:*) гарантирует выполнение требований нормализации. Каждой таблице дается имя по названию соответствующей сущности (в примере - товары, деньги, продажи, платежи, продавцы, клиенты, кассиры). Что касается имен таблиц, представляющих отношения, то они обычно составляются из имен связываемых сущностей (в примере - "продажи-товары" и "продажи-платежи"). Большинство СУБД накладывают ограничения на имена таблиц и полей, например, допускают использование только букв английского алфавита и некоторых символов. |