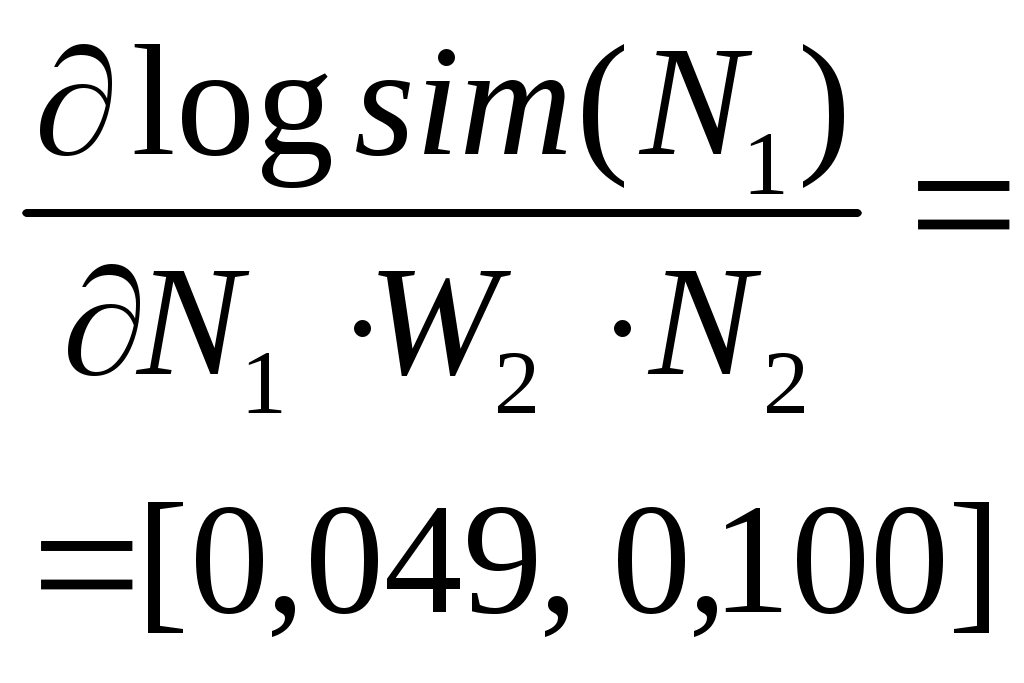Моделирование искусственных нейронных сетей в среде matlab
 Скачать 348 Kb. Скачать 348 Kb.
|

|
ПРИМЕР 1 Создание и обучение нейронной сети с помощью алгоритма обратного распространения ошибки Зададим с помощью графика исходную функцию: % входы НС P = [0 1 2 3 4 5 6 7 8]; % желаемые реакции НС T = [0 0.44 0.88 0.11 -0.66 -0.95 -0.45 0.18 0.92]; % изображение аппроксимируемой функции plot(P, T, 'o'); Используем функцию newff,чтобы создать двухслойную сеть прямого распространения. Пусть сеть имеет входы с интервалом значений от 0 до 8, первый слой с 10 нелинейными сигмоидальными, второй – с одним линейным нейронами. Используем для обучения алгоритм обратного распространения ошибки (backpropagation) Левенберга – Марквардта (рис. 6). % создание двухслойной НС прямого распространения с интервалом % значений входов от 0 до 8, причем первый слой содержит % 10 нелинейных сигмоид, а второй — один линейный нейрон. % Для обучения используется алгоритм обратного распространения % ошибки (backpropagation). net = newff([0 8], [10 1], {'tansig' 'purelin'},'trainlm'); % имитация работы необученной НС yl = sim (net, P); % изображение результатов работы необученной НС plot(P, T, 'o', P, yl, 'x') ; % Обучим сеть на 100 эпохах с целевой ошибкой 0.01: % установка количества проходов net.trainParam.epochs = 50; % установка целевого значения ошибки net.trainParam.goal = 0.01; % обучениеНС (рис. 6) net = train(net, P, T) ; % имитация работы обученной НС y2 = sim(net, P); % изображение результатов работы НС (рис. 7) plot(P, T, 'o', P, yl, 'x', P, y2, '+'); 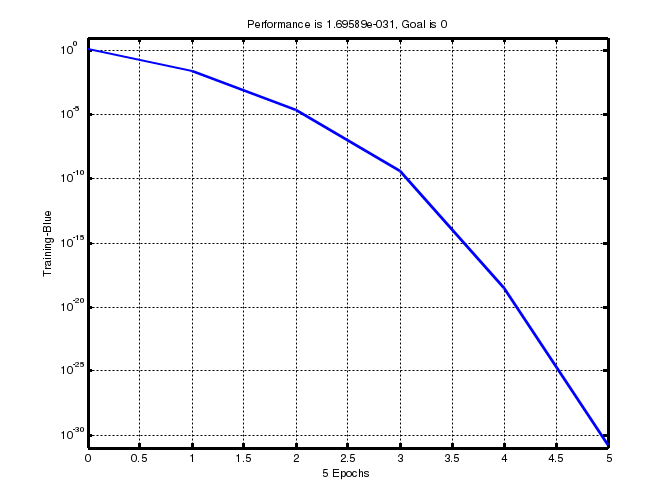 Рис. 6. График обучения двухслойного персептрона Для исследования работы алгоритма обратного распространения ошибки воспользуемся примером, встроенным в Matlab toolbox, набрав команду demo. В появившемся диалоговом окне необходимо последовательно выбирать пункты меню: Toolboxes->Neural Network->Other Demos->Other Neural Network Design textbook demos->Table of Contents->10-13->Backpropagation Calculation. 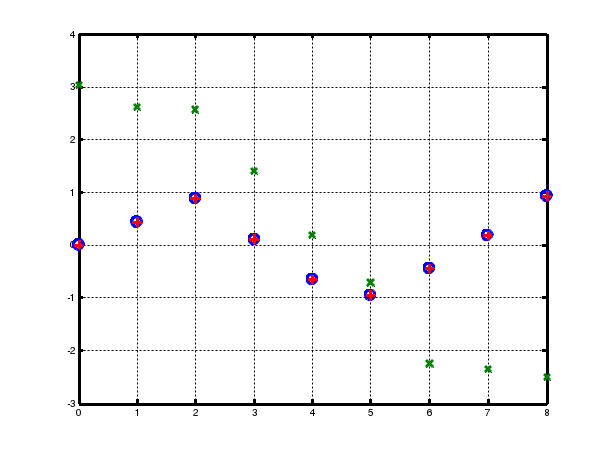 Рис. 7. Результат аппроксимации векторов двухслойным персептроном В примере используется двухслойный персептрон с двумя нелинейными нейронами в первом слое и одним во втором. Действие алгоритма обратного распространения ошибки разбито на следующие шаги: назначение входа и желаемого выхода, прямой проход входного сигнала до выхода, обратное распространение ошибки, изменение весов. Переменные, позволяющие проследить работу алгоритма обратного распространения ошибки, обозначены следующим образом: Р –входной сигнал; W1(i) –вектор весов первого слоя, W1(1) –вес связи, передающий входной сигнал на первый нейрон, a W1(2) – на второй; W2(i) –вектор весов второго слоя, W2(1) –вес связи, передающий входной сигнал с первого нейрона во второй слой, a W2(2) –со второго; B1(i) –вектор пороговых значений (bias) нейронов первого слоя, i = 1, 2; В2– пороговое значение (bias) нейрона второго слоя; N1(i) – вектор выходов первого слоя, i = 1, 2; N2– выход второго слоя; A1(i) – вектор выходных сигналов первого слоя после выполнения функции активации (сигмоиды), i = 1, 2; А2– выход второго слоя после выполнения функции активации (линейной); lr – коэффициент обучаемости. Пусть входной сигнал Р = 1,0, а желаемый выход Результаты выполнения этапов алгоритма представлены в табл. 1. Таблица 1 Результаты поэтапного выполнения алгоритма обратного распространения ошибки
4 КОНТРОЛЬНЫЕ ВОПРОСЫ Каким алгоритмом обучают многослойные НС? Из каких основных этапов состоит алгоритм обратного распространения ошибки? Почему алгоритм обратного распространения ошибки относится к классу алгоритмов градиентного спуска? Как влияет функция принадлежности на правило изменения весов в обратном алгоритме распространения ошибки? Какая функция в среде MATLAB создает НС прямого распространения? Какие функции активации могут быть назначены для нейронов НС прямого распространения? Лабораторная работа № 3 ИЗУЧЕНИЕ РАДИАЛЬНЫХ БАЗИСНЫХ, ВЕРОЯТНОСТНЫХ НЕЙРОННЫХ СЕТЕЙ, СЕТЕЙ РЕГРЕССИИ 1 ЦЕЛЬ РАБОТЫ Изучить модель вычислений радиального базисного нейрона, структуру и функции сетей регрессии, вероятностных нейронных сетей. 2 СВЕДЕНИЯ ИЗ ТЕОРИИ 2.1 Радиально-базисные сети. Сети регрессии. Вероятностные НС Рассмотрим радиальный базисный нейрон с R входами. Структура нейрона представлена на рис. 8. Радиальный базисный нейрон (РБН) вычисляет расстояние между векторами входов X ивектором весов W,затем умножает его на фиксированный порог b. Функция активации РБН, полученная в среде MATLAB, представлена на рис. 10. Радиальная базисная функция имеет максимум, равный 1, когда ее входы нулевые. Следовательно, радиальный базисный нейрон действует как детектор, который получает на выходе 1, когда вход X идентичен его вектору весов W. Фиксированный порог b даст возможность управлять чувствительностью нейрона. Например, если нейрон имеет порог 0,1, то выход равен 0,5 для любого входного вектора X, находящегося на векторном расстоянии 8,326 (8,326/b) от W. 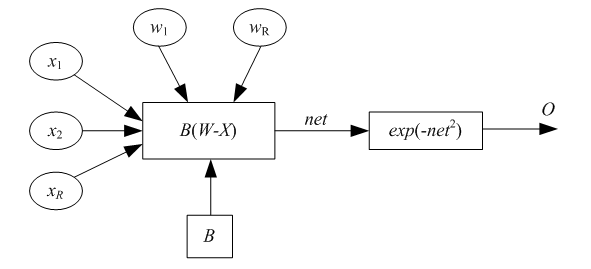 Рис. 8. Радиальный базисный нейрон Радиальная базисная нейронная сеть (РБНС) состоит из двух слоев: скрытого радиального базисного слоя из S1нейронов и выходного линейного слоя из S2нейронов. Элементы первого слоя РБНС вычисляют расстояния между входным вектором и векторами весов первого слоя, сформированных из строк матрицы W 2,1. Вектор порогов В и расстояния поэлементно умножаются. Выход первого слоя можно выразить формулой где A1 – выход первого слоя; функция radbas – радиально-базисная функция; W – матрица весов первого слоя сети; X – входной вектор; В – вектор порогов первого слоя. Согласно формуле радиальные базисные нейроны с вектором весов, близким к X, сгенерируют значения, близкие к 1. Если нейрон имеет выход 1, то это значение весами второго слоя будет передано на его линейные нейроны. Фактически радиальный базисный нейрон с выходом 1превращает выходы всех остальных нейронов в нули. Тем не менее, типичным является случай, когда несколько нейронов дают на выходах значимый результат, хотя и с разной степенью. Радиальные базисные нейронные сети обучаются в три этапа. Опишем этапы обучения. Первый этап – выделение центров (весов). Центры, представленные в РБН-слое, оптимизируются первыми с помощью обучения без учителя. Центры могут быть выделены разными алгоритмами, в частности обучением Кохонена. Алгоритмы должны разместить центры, отражая кластеризацию исходных данных. Второй этап – назначение отклонений. Отклонения могут быть назначены различными алгоритмами, например алгоритмом «ближайшего соседа». Третий этап – линейная оптимизация. Можно использовать методы обучения по дельта-правилу, обратному распространению ошибки. Нейронные сети регрессии (НСР) имеют такой же, как и РБНС, первый слой, но второй слой строится специальным образом. Для аппроксимации функций часто используются обобщенные сети регрессии (generalized regression neuron networks). Второй слой, как и в случае РБНС, выполняет поэлементное произведение строки W1,2и вектора выхода первого слоя a1. Он имеет столько нейронов, сколько существует целевых пар <входной вектор/целевой вектор>. Матрица весов W – это набор целевых строк. Целевое значение – это значение аппроксимируемой функции в обучающей выборке. Предположим, имеется один входной вектор хi,который сгенерирует на выходе первого слоя выход, близкий к 1. В результате выход второго слоя будет близок к tiодному из значений аппроксимируемой функции, использованной при формировании второго слоя. Сети регрессии иногда называют Байесовскими вероятностными сетями регрессии, или обобщенными НС регрессии. Некоторые реализации сетей регрессии имеют четыре слоя: входной, выходной, слои радиальных центров, элементов регрессии. Радиальный слой представляет собой центры-кластеры известных обучающих данных и содержит такое же количество элементов, как обучающая выборка; РБН обучаются алгоритмом кластеризации. Слой регрессии имеет только на один элемент больше, чем выходной слой, и содержит линейные элементы одного из двух типов. Элемент первого типа вычисляет условную вероятность каждого выходного атрибута, элемент второго типа вычисляет плотность вероятности. Выходной слой выполняет специальные функции деления. Каждый элемент делит выходы, ассоциированные первым типом, с помощью элементов второго типа. Байесовские вероятностные НС используются только для проблем классификации. Они содержат четыре слоя: входной, выходной, слой РБН и элементов линейной классификации. Слои могут содержать квадратную матрицу потерь, включение которой возможно, только если третий и четвертый слои состоят из одинакового числа элементов. Радиальные базисные нейроны в таких сетях используются для хранения образцов, взятых из обучающей выборки, которая берется полностью. Следовательно, первый скрытый слой содержит такое же количество элементов, что и обучающая выборка. Так как элементы слоя классификации связаны с выходом каждого класса, можно оценить вероятность принадлежности последнему. Если используется матрица потерь, то цена решения минимальна. Такие сети обычно быстро тренируются, но медленно вычисляют из-за большого размера. Вероятностные нейронные сети (ВНС, probabilistic neuron networks) используются для решения проблемы классификации. Первым слоем в архитектуре ВНС является слой радиальных базисных нейронов, который вычисляет расстояние и вектор индикаторов принадлежности другим входным векторам, используемым при обучении. Второй слой суммирует эти значения для каждого класса входов и формирует выходы сети, как вектор вероятностей. Далее специальная функция активации (compete) определяет максимум вероятностей на выходе второго слоя и устанавливает данный выход в 1, а остальные выходы в 0. Матрица весов первого слоя W1,1 установлена в соответствии с обучающими парами. Блок расчета расстояний получает вектор, элементы которого показывают, насколько близок входной вектор к векторам обучающего множества. Элементы вектора умножаются на вектор порогов и преобразуются радиальной базисной функцией. Входной вектор, близкий к некоторому образцу, устанавливается в 1 в выходном векторе первого слоя. Если входной вектор близок к нескольким образцам отдельного класса, то несколько элементов выходного вектора первого слоя будут иметь значения, близкие к 1. Веса второго слоя W1,1устанавливаются по матрице T целевых векторов, каждый вектор которой включает значение 1 в строке, связанной с определенным классом входов, и нули в остальных позициях. Произведения Т a1 суммируют элементы выходного вектора первого слоя а1 для каждого из K классов. Затем функция активации второго слоя (compete) установит значение 1 в позицию, соответствующую большему элементу выходного вектора, и 0 во все остальные. Следовательно, сеть классифицирует входные векторы, назначая входу единственный класс на основе максимальной вероятности принадлежности. 2.2 Описание основных функций Функция newrb создает радиальную базисную сеть и имеет следующий синтаксис: net = newrb(P, Т, goal, spread). Радиальные базисные сети используют для аппроксимации функций. Функция newrb конструирует скрытый (первый) слой из радиальных базисных нейронов и использует значение средней квадратичной ошибки (goal). Функция newrb(P, Т, goal, spread) имеет следующие аргументы: Р – матрица Q входных векторов размерности R на Q; Т – матрица Q векторов целевых классов S на Q; goal –средняя квадратичная ошибка, по умолчанию 0,0; spread – разброс радиальной базисной функции, по умолчанию 1,0. Функция создает и возвращает в качестве объекта радиальную базисную сеть. Большое значение разброса приводит к большей гладкости аппроксимации. Слишком большой разброс требует много нейронов, для того чтобы подстроиться под быстро изменяющуюся функцию, слишком малый – для достижения гладкости аппроксимации. Подобрать значение разброса можно с помощью многократных вызовов функции newrb. Создадим в среде MATLABрадиальную базисную сеть: net = newrbe(P, T, spread). |