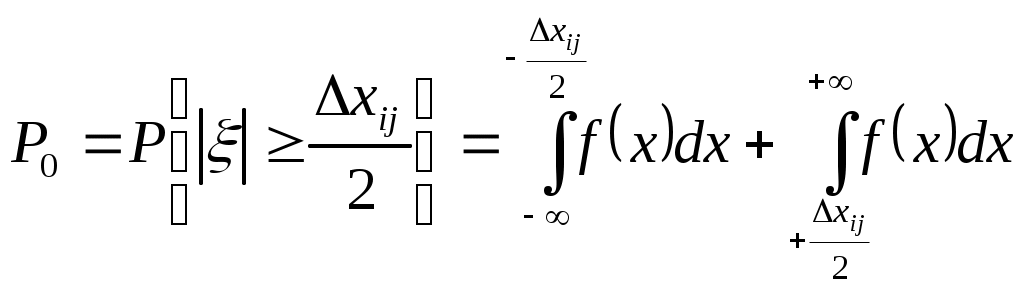екекркер. Кодирование. Основы теории кодирования. Кодирование. Основные понятия
 Скачать 0.93 Mb. Скачать 0.93 Mb.
|

|
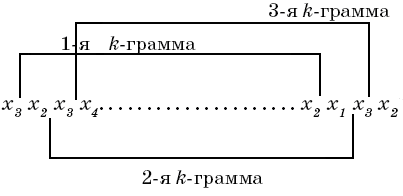
2.6. Алгоритмы эффективного кодирования неравновероятных взаимозависимых символов сообщений Устранение взаимной зависимости символов источника сообщения может быть осуществлено путем укрупнения алфавита исходного источника сообщения. Для этого подлежащие кодированию сообщения последовательно разбиваются на двух-, трех- или n-знаковые сочетания (блоки), вероятности которых известны, а затем эти сочетания кодируются в соответствии с алгоритмами Шеннона-Фено или Хаффмена. Недостаток этого алгоритма состоит в том, что при его использовании не учитываются связи между символами, входящими в состав соседних сочетаний (блоков). Этот недостаток может быть устранен кодированием по методу диаграмм, триграмм или в общем случае k-грамм. k-граммой называют последовательность из kсмежных символов сообщения. При k=2 сочетание смежных знаков называют диаграммой, при k=3 — триграммой и т.д. В процессе кодирования по методу k-грамм производят непрерывное последовательное перемещение k-граммы по сообщению с шагом равным одному символу. Этот процесс (получение 3-х k-грамм) иллюстрируется рис. 2.3, где xi - символы сообщения.
Если вероятности появления различных k-грамм известны, то их эффективное кодирование, в частности, может быть выполнено по алгоритмам Шеннона-Фено или Хаффмена. Конкретное значение kвыбирается исходя из степени взаимозависимости между символами сообщения и сложности технической реализации кодирующих и декодирующих устройств. 2.7. Недостатки алгоритмов эффективного кодирования. Основным недостатком этих алгоритмов является специфическое влияние помех на достоверность декодирования, которое проявляется в том, что одиночная ошибка в кодовой комбинации может перевести ее в другую кодовую комбинацию, не равную ей по длительности. Это может привести к неверному декодированию ряда последующих комбинаций, что называют треком ошибки, хотя существуют методы, позволяющие свести трек ошибки к минимуму. Существенным недостатком является также сложность технической реализации систем эффективного кодирования, которые должны включать в себя буферные устройства и устройства накопления. Использование этих устройств вызвано тем, что длина кодовых комбинаций различна, а каналы связи эффективно работают только в том случае, если символы поступают на них с постоянной скоростью. Кроме этого, при кодировании блоками необходимо накапливать символы, прежде чем присвоить их совокупности какую-либо кодовую комбинацию. 2.8. Помехоустойчивое (корректирующее) кодирование. Общие понятия Высокие требования к достоверности и надежности передачи, обработки и хранения информации в системах передачи данных, в вычислительных системах и сетях, в региональных системах управления и различного рода информационных системах требуют такого кодирования информации, которое обеспечивало бы безошибочную ее передачу, а в случае появления ошибок - их обнаружение и исправление. Коды, обладающие такой способностью, называют помехоустойчивыми или корректирующими. Подавляющее большинство существующих в настоящее время помехоустойчивых кодов обладают требуемыми свойствами благодаря их алгебраической структуре. Поэтому их называют алгебраическими кодами. Хотя существуют и иные коды, корректирующее действие которых основано на оценке вероятности искажения каждого символа кода. Кодовые комбинации (кодовые символы) алгебраических кодов включают в себя две группы элементов кодовых символов: информационные элементы и проверочные элементы. Совокупность информационных элементов кодового символа соответствуют символу кодируемого сообщения, а проверочные (избыточные) элементы добавляются к информационным элементам и служат для обнаружения и исправления ошибок. Все алгебраические коды можно разделить на два больших класса: блочные (блоковые) и непрерывные. Блочные коды представляют собой совокупность кодовых символов, состоящих из отдельных комбинаций (блоков) элементов символов кода, которые кодируются и декодируются независимо. При этом каждому символу кодируемого исходного сообщения ставится в соответствие блок (комбинация) из nэлементов символов кода, куда включаются информационные и проверочные элементы. Блочный код называют равномерным, если nдля всех блоков одинаково. Непрерывные (древовидные) коды представляют собой непрерывную последовательность кодовых символов, причем введение проверочных элементов производится непрерывно, без разделения ее на независимые блоки. Как блочные коды, так и непрерывные могут быть разделимыми и неразделимыми. В разделимых кодах информационные и проверочные элементы символов кода отчетливо разграничены и всегда занимают одни и те же определенные позиции (разряды). Такие коды часто называют (n,k) коды, где n— длина кодового символа, k— число информационных элементов в нем. При кодировании неразделимыми кодами разделение кодового символа на информационные элементы и проверочные невозможно. Среди разделимых кодов выделяют систематические (линейные) и несистематические. Систематическими кодами называют коды, в которых проверочные элементы являются линейными комбинациями информационных. Эти коды наиболее распространены, т.к. их использование существенно упрощает техническую реализацию кодирующих и декодирующих устройств. 2.9. Теоретические основы помехоустойчивого кодирования Теоретические основы помехозащищенного кодирования сообщений базируются на основной теореме Шеннона о кодировании для канала с помехами. Эта теорема гласит: При любой производительности источника сообщений, меньшей чем пропускная, способность канала, существует такой способ кодирования, который позволяет обеспечить передачу всей информации, создаваемой источником сообщений, со сколь угодно малой вероятностью ошибки. Не существует способа кодирования, позволяющего вести передачу информации со сколь угодно малой вероятностью ошибки, если производительность источника сообщений больше пропускной способности канала. Анализируя теорему, важно отметить, что она устанавливает теоретический предел процесса передачи информации, создаваемой источником сообщений, со сколь угодно малой вероятностью ошибки и показывает, что помехи в канале не накладывают ограничений на точность и достоверность передачи сообщений, а ограничения накладываются лишь на скорость передачи, при которой может быть достигнута сколь угодно высокая достоверность передачи. Теорема, к сожалению, не указывает конкретных путей построения кодов, обеспечивающих надежность передачи, однако она доказывает, что такие пути существуют. Для определения конкретных направлений, обеспечивающих повышение надёжности и достоверности передачи сообщений, обратимся к общей информационной модели системы передачи сообщений, представленной на рис. 2.4.  Рис. 2.4. Общая информационная модель системы передачи сообщений. Пусть Таким образом, процесс передачи сообщений u состоит в следующем (Рис. 2.5.): на передающем конце канала пространство сообщений на приёмном конце канала из пространства сигналов  Рис. 2.5. Иллюстрация процесса передачи сообщений по каналу. При отсутствии помех выполняется однозначное соответствие между исходным символом сообщения (ui) и принятым символом (vi). Действительно,
При наличии помех сигнал Xпри прохождении через канал будет искажаться и, в общем случае, Выполнить эту идентификацию можно следующим образом. Если собственные шумы в приёмнике отсутствуют, то можно однозначно определить принятый сигнал x, соответствующий полученному сообщению v: и определить положение сигнала xв пространстве сигналов X(рис. 2.6.).  Рис. 2.6. Положение сигнала xв пространстве сигналов X. Вектору xможно присвоить значение ближайшего к нему известного вектора из пространства сигналов X, то есть для любого Приемник, работающий по выше рассмотренному принципу идентификации, называют идеальным приемником. Ошибка приема идеального приемника (прием сообщения Вероятность появления такой ошибки может служить мерой помехоустойчивости или надежности системы связи (П):
где Очевидно, что с увеличением расстояния между векторами xi и xjпомехоустойчивость повышается. Если величина помехи ξ определяется как ξ = xi- x, то для безошибочного приема сообщения x необходимо выполнение условия: или
где И тогда условие безошибочного приема запишется в виде: В случае, если помеха (ξ) имеет плотность распределения вероятностей f(ξ), то вероятность появления ошибки В общем случае пространство сообщений Uимеет размерность n(например, каждый символ этого сообщения состоит из nэлементов). Тогда условие безошибочного приема получим из следующих соображений. Так как
то а
где Следовательно,
Если
где Корректирующее кодирование применяют в тех случаях, когда возможности других более простых способов повышения помехозащищенности (таких как многократное повторение или фильтрация) исчерпаны. Это обусловлено усложнением систем передачи информации при введении кодирующих устройств. Как следует из выше приведённых выводов теории помехоустойчивости, основной практический принцип построения корректирующих (помехозащищенных) кодов основывается на допущении, что принятый кодовый символ после воздействия на него помехи всегда остается в некоторой близости от кодового символа, однозначно соответствующего передаваемому символу исходного сообщения. Это позволяет в дальнейшем отождествить принятый символ с ближайшим к нему символом кодового алфавита путём нахождения минимального расстояния из всех расстояний между принятым символом и всеми символами кодового алфавита. Создание специальных помехоустойчивых цифровых кодов, позволяющих не только обнаружить, но и при определенных условиях исправить возникающие ошибки, основано на увеличении минимального расстояния между символами кодового алфавита (dmin) путём. увеличения избыточности кодов. Это достигается введением при кодировании дополнительных (избыточных) элементов символов кода, которые удовлетворяют некоторым дополнительным условиям и проверка которых дает возможность обнаружить и исправить ошибки. Принципы практического построения корректирующих кодов удобно продемонстрировать на примере блочных систематических кодов (в частности алгебраических кодов), как наиболее наглядных и широко применяемых. Для алгебраических (n, k) корректирующих кодов избыточность кода (Rn, Rk) определяется выражениями: где n— число элементов в кодовом символе; k— число информационных элементов в кодовом символе (или минимально возможное число элементов в кодовом символе. Величина Rk, с областью изменения от 0 до ∞ предпочтительнее, так как лучше отвечает смыслу понятия избыточности. Коды, обеспечивающие заданную помехоустойчивость при минимально возможной избыточности, называют оптимальными. Очевидно, что при оптимальном кодировании, когда лишние элементы в кодах отсутствуют, т.е. когда n = k, избыточность равна 0. Для оценки кодов с точки зрения возможности обнаружения и исправления ошибок используют понятие кодового расстояния (число кодовых переходов для двоичных кодов) dij. Кодовым расстоянием (dij) между кодовыми символами kiи kjназывают суммарный результат сложения по модулю mkодноименных разрядов кодовых символов kiи kj: где  kikи kjk— kразряд кодовых символов kiи kj; mk— основание кода (основание системы счисления цифрового кода). Например, если даны символы двоичного числового кода ki= 10111 и kj= 01010, то кодовое расстояние между этими символами равно 4 (dij= 4). Кодовое расстояние может быть посчитано и для числовых кодов с иными основаниями, отличными от 2. Кодовое расстояние иногда называют расстоянием Хемминга. |