Лабораторная 1. Отчет по лабораторным работам по дисциплине
 Скачать 5.44 Mb. Скачать 5.44 Mb.
|

|
Федеральное государственное бюджетное образовательное учреждение высшего образования «РОССИЙСКАЯ АКАДЕМИЯ НАРОДНОГО ХОЗЯЙСТВА И ГОСУДАРСТВЕННОЙ СЛУЖБЫ ПРИ ПРЕЗИДЕНТЕ РОССИЙСКОЙ ФЕДЕРАЦИИ» НИЖЕГОРОДСКИЙ ИНСТИТУТ УПРАВЛЕНИЯ – филиал РАНХиГС Факультет управления Кафедра экономики и обеспечения экономической безопасности Направление подготовки / специальность: 38.03.01 Экономика Направленность (профиль) / специализация: Финансы и кредит Отчет по лабораторным работам
Нижний Новгород, 2022 г. ОглавлениеЛабораторная №1. 2 Задание1.Импорт данных 3 Лабораторная №2. Парциальная предобработка 9 Задание 1.Восстановление пропущенных данных 12 Задание 2.Удаление аномалий 15 Задание 3.Спектральная обработка 17 Задание 4.Удаление шумов 20 Задание 5.Сглаживание шумов 23 Лабораторная работа № 3. Корреляционный анализ 26 Задания 1.Исходные данные 26 Задание 2.Устранение незначащих входных факторов 27 Лабораторная работа № 4. Фильтрация данных 31 Задания 1.Фильтрация данных 31 Лабораторная работа № 5. Выявление дубликатов и противоречий 34 Задание 1.Исходные данные 34 Задание 2.Поиск дубликатов и противоречий 35 Лабораторная №1.Задание1.Импорт данных Рис. 1(вызов мастера импорта) Импорт осуществляется путем вызова мастера импорта на панели «Сценарии», при нажатии открывается окно мастера импорта. (рис.1) 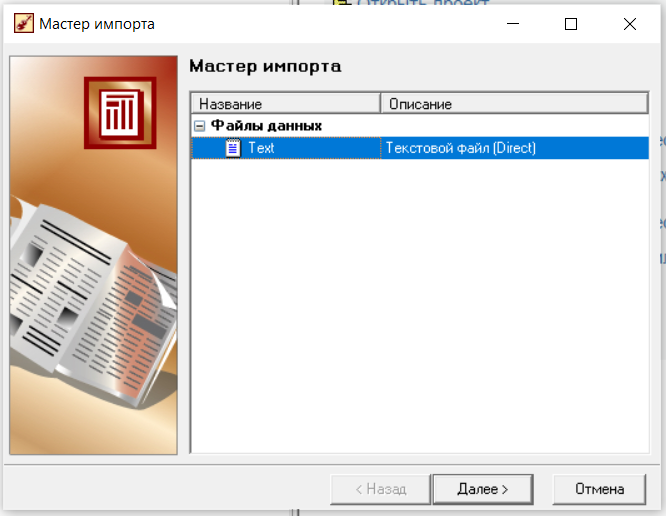 Рис. 2 (выбор типа импорта) В диалоговом окне мастера импорта выбираем тип импорта «Текстовый файл (Direct)» далее перейдем к настройке импорта.(рис.2) 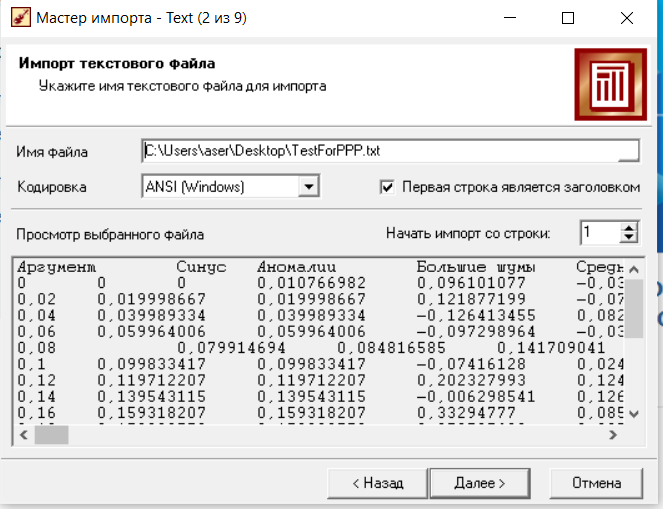 Рис. 3(выбор текстового файла для импорта) Далее укажем имя файла, из которого необходимо получить данные (файл TestForPPP.txt). Перед этим сохраняем данный текстовый файл на рабочем столе. В окне просмотра выбранного файла можно увидеть содержание данного файла. В данном окне так же мы имеем возможность указать, с какой строки следует начать импорт, указать, то, что первая строка является заголовком. В данном случае параметры по умолчанию на этой странице мастера установлены правильно, а именно: начать импорт с первой строки, первая строка является заголовком. (рис.3) 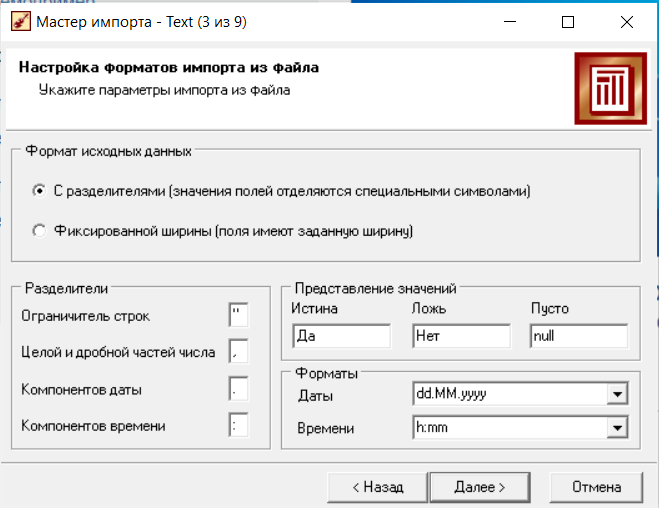 Рис. 4 (настройка форматов импорта из файлов) В диалоговом окне мастера импорта (рис.3) нажимаем «Далее», тем самым мы переходим в диалоговое окно «Настройка форматов импорта из файла». В данном окне мы имеем возможность указать формат исходных данных (С разделением или фиксированной ширины), так же можем выбрать разделители для чисел, присутствует настройка представлений значений, а также настройка формата даты и времени. Аналогично предыдущему окну параметры по умолчанию установлены правильно, а именно: разделителем между столбцами является знак табуляции, разделителем целой и дробной частей является запятая.(рис.4)  Рис. 5(параметр импорта файла с разделителем) После нажатия кнопки «Далее» в диалоговом окне «Настройка форматов импорта из файла» мы попадаем в диалоговое окно «Параметр импорта файла с разделителем».(рис.5) В данном окне у нас есть возможность выбрать, что будет являться символом-разделителем. А так же в нижней части окна мы видим пример, как будет выглядеть наш текстовый фал в зависимости от выбора символа-разделителя. Параметры по умолчанию установлены верно.  Рис. 6(установка параметров столбов) Нажимая «Далее» в окне с рис.5 мы переходим в «Параметры столбцов»(рис.6) изначально настройки в правой части окна недоступны для выбора, нажимая на наименование одного из столбцов в левой части экрана мы делаем выборку активной. На этом шаге мастера предоставляется возможность настроить имя, название (метку), размер, тип данных, вид данных и назначение. Некоторые свойства (например, тип данных) можно задавать для выделенного набора столбцов. Вид данных определяет – конечный ли это набор (дискретные) или бесконечный (непрерывные). Назначение столбцов определяет характер их использования в алгоритмах обработки (при импорте можно оставить значение по умолчанию). Для правильного импорта данных необходимо изменить тип данных у первых трех столбцов («АРГУМЕНТ», «СИНУС», «АНОМАЛИИ»). Тип данных по умолчанию неверный, поскольку программа определяет его, основываясь на значениях первой строки данных. В данном случае там находятся нули – целые числа. Поэтому программа определила, что столбец содержит целочисленные значения. Выделим их с помощью мыши и укажем им тип данных -«Вещественный». Далее осталось только выполнить импорт данных, нажав на кнопку «Пуск» на следующем шаге мастера импорта.  Рис. 7(запуск процесса импорта данных из текстового файла) После нажатия кнопки «Далее» с окна на рис.6- мы переходим в диалоговое окно «Запуск процесса импорта данных из текстового файла» (рис.7) Далее осталось только выполнить импорт данных, нажав на кнопку «Пуск» .  Рис. 8(выбор способа отображения данных) После импорта данных на следующем шаге мастера необходимо выбрать способ отображения данных. В данном случае самым информативным является диаграмма, выберем ее. От того, какие способы отображения будут выбраны на этом этапе, зависят последующие шаги мастера. В данном случае необходимо настроить, какие столбцы диаграммы следует отображать и как именно.(рис.8)  Рис. 9(настройка параметров столбцов диаграммы) После нажатия кнопки «Далее» в окне с рис.8 Выберем для отображения поле «СИНУС» и тип диаграммы «Линии». (рис. 9)  Рис. 10(завершение работы мастера импорта) На последнем шаге мастера необходимо указать название ветки в дереве сценариев. Напишем в поле заголовка окна «Импорт примера для демонстрации парциальной обработки» и нажмем «Готово». На этом работа мастера импорта заканчивается. Теперь в дереве сценариев появится новый узел с необходимыми данными. В главном окне программы представлены все выбранные отображения данных этого узла. В данном случае только диаграмма.(рис.10) Вывод В процессе выполнения Лабораторной работы №1 мы получаем опорные знания для работы с программой Deductor Studio, а точнее- механика импорта данных в программу для последующей работы с ними. Лабораторная №2. Парциальная предобработкаПарциальная предобработка служит для восстановления пропущенных данных, редактирования аномальных значений и спектральной обработке данных (например, сглаживания данных). Именно этот шаг часто проводится в первую очередь. 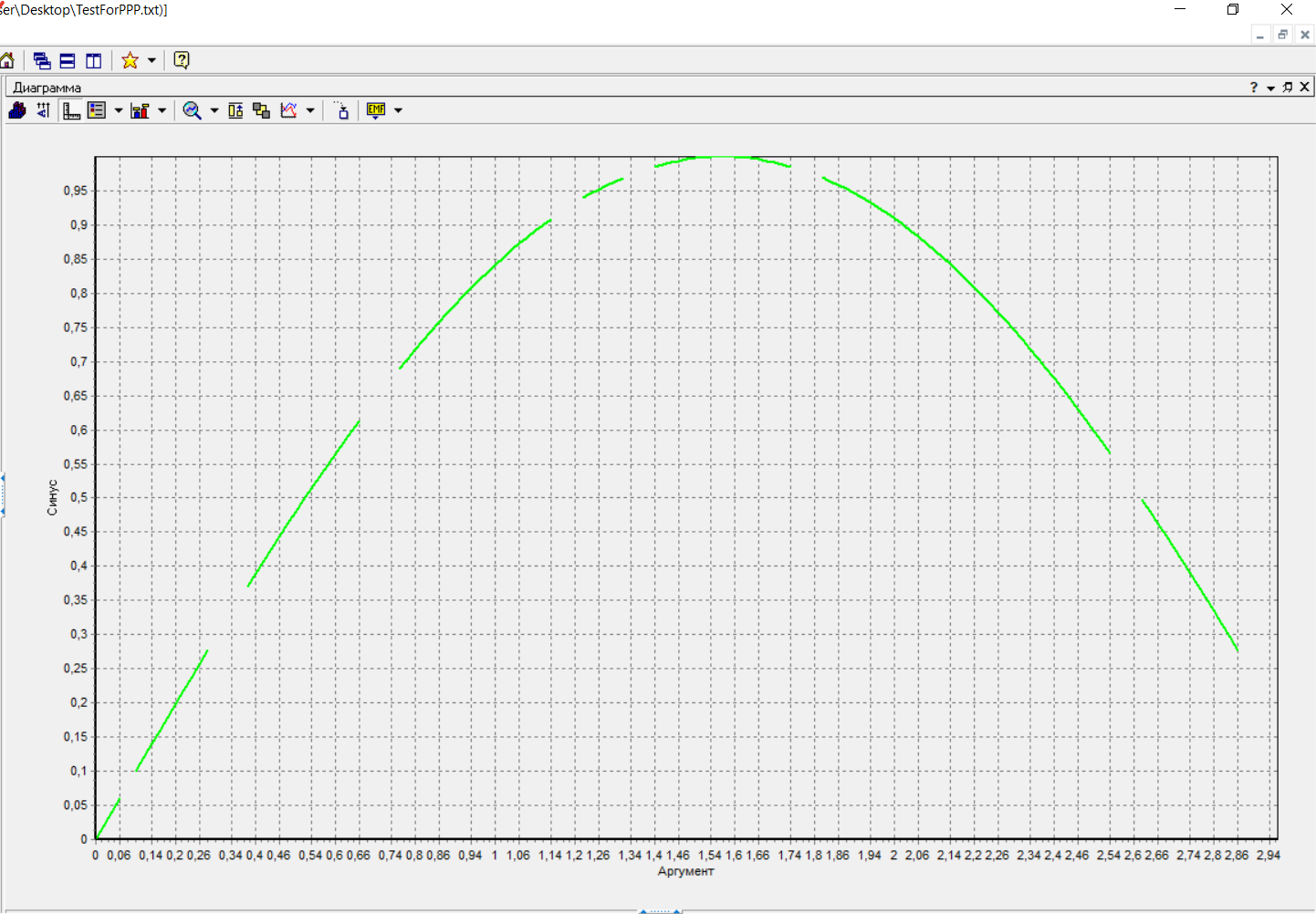 Рис. 11(график с заданными нами параметрами) После нажатия кнопки «Готово» программа выстраивает график с заданными нами параметрами. (рис.11) Исходные данные  Рис. 12(переключение между таблицами) Рассмотрим применение обработки на примере данных из файла «TestForPPP.txt». Для этого нам нужно нажать на знак «лупы» в верхней части экрана, таким образом мы видим выпадающий список с перечнем полей. (рис.12)  Рис. 13 (содержание поля «аргумент») Первое поле в выпадающем списке –«Аргумент» (рис.13)  Рис. 14 (содержание поля «синус») Второе поле в выпадающем списке –«Синус» (рис.14)  Рис. 15 (содержание поля «аномалии») Третье поле в выпадающем списке –«Аномалии» (рис.15)  Рис. 16 (содержание поля «большие шумы») Четвертое поле в выпадающем списке –«Большие шумы» (рис.16) 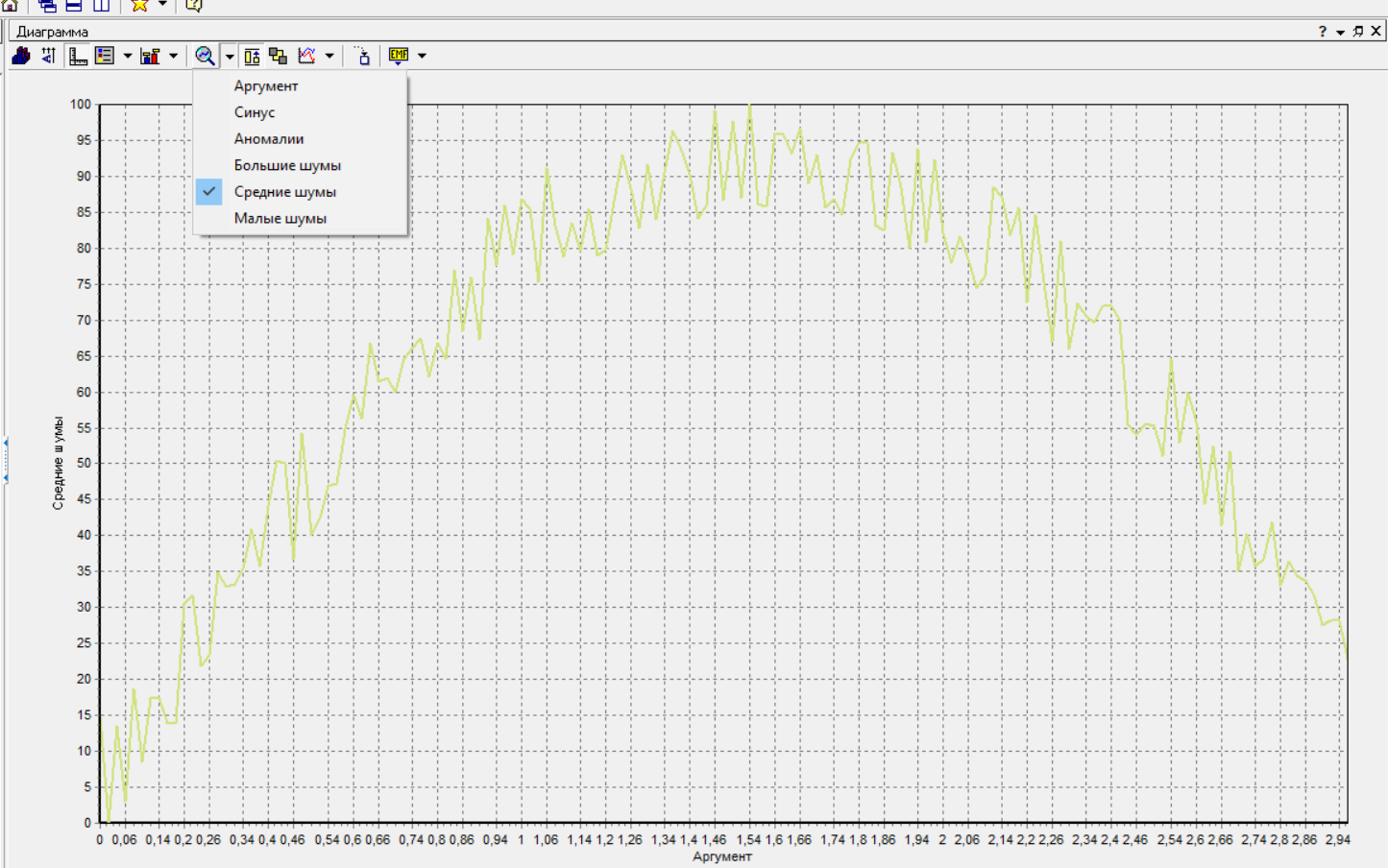 Рис. 17 (содержание поля «средние шумы») Пятое поле в выпадающем списке –«Средние шумы» (рис.17) 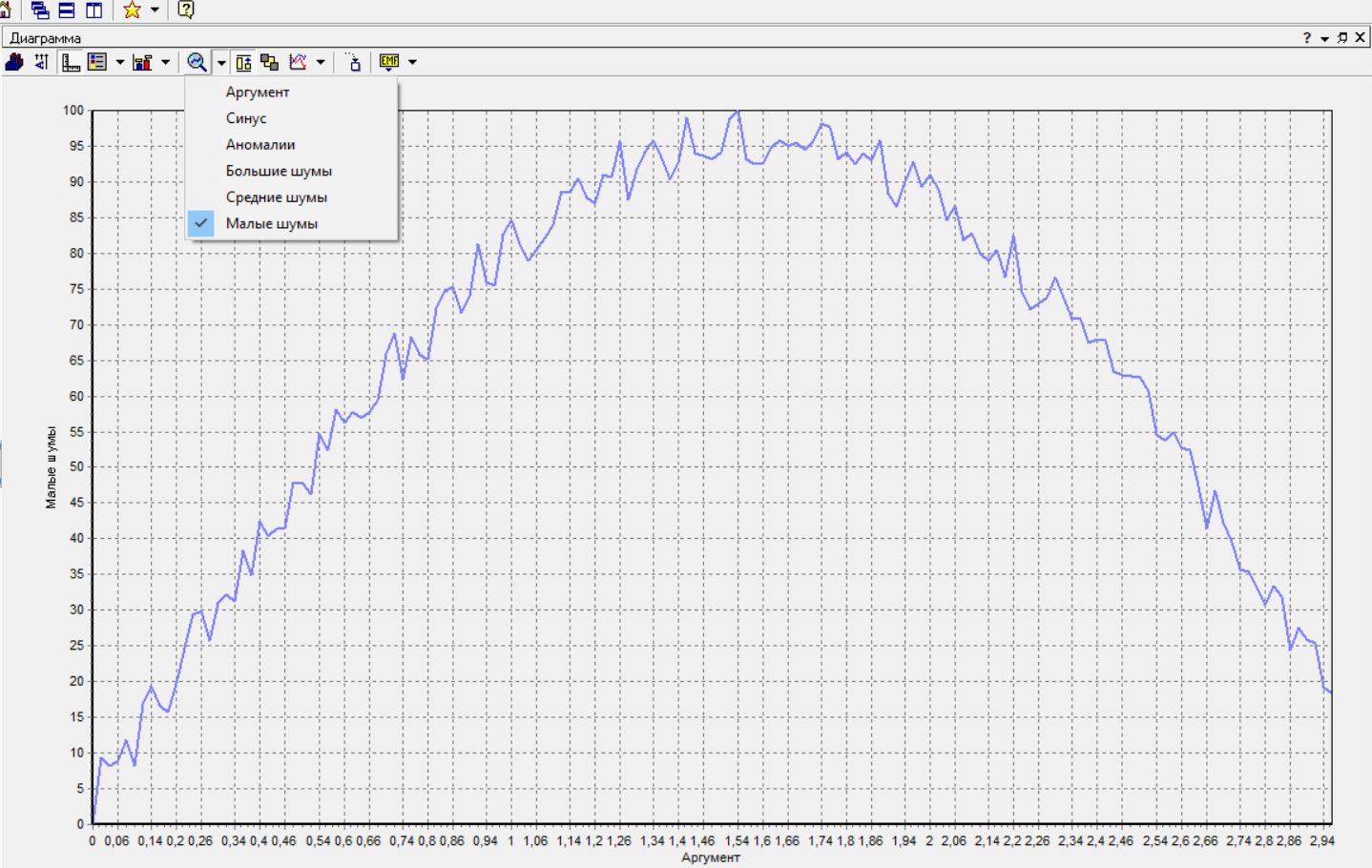 Рис. 18 (содержание поля «малые шумы») Шестое поле в выпадающем списке –«Малые шумы» (рис.18) Задание 1.Восстановление пропущенных данныхЧасто бывает так, что в столбце некоторые данные отсутствуют в силу каких либо причин (данные не известны, либо их забыли внести и т.п.). Обычно из–за этого пришлось бы убрать из обработки все строки, которые содержат пропущенные данные. Но механизмы Deductor Studio позволяют решить эту проблему. Один из шагов парциальной обработки как раз отвечает за восстановление пропущенных значений. Если данные упорядочены (например, по времени), то рекомендуется в качестве восстановления пропущенных значений использовать аппроксимацию. Алгоритм сам подберет значение, которое должно стоять на месте пропущенного значения, основываясь на близлежащих данных. Если же данные не упорядочены, то следует использовать режим максимального правдоподобия, когда алгоритм подставляет вместо пропущенных данных наиболее вероятные значения, основываясь на всей выборке. Для демонстрации воспользуемся мастером парциальной обработки. Импортировав файл можно увидеть, что в столбце «СИНУС» содержатся пустые значения.(рис. 14) На диаграмме выше видно, что некоторые значения синуса пропущены. Для дальнейшей обработки необходимо их восстановить. Для Этого следует запустить мастер парциальной обработки.  Рис. 19 (мастер парциальной обработки) Чтобы запустить мастер парциальной обработки мы должны начать фиолетовый значок в верхней части экрана (рис.19)  Рис. 20 (диалоговое окно мастера парциальной обработки) В диалоговом окне мастера парциальной обработки для перехода на следующий этап работы мы нажимаем «Далее» (рис.20) 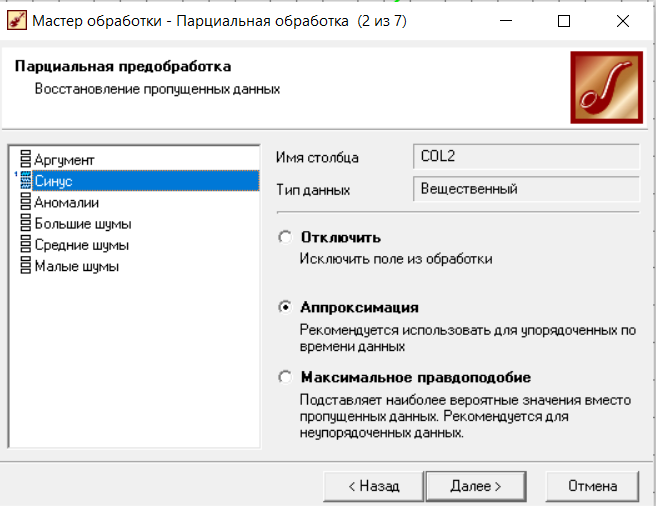 Рис. 21 (окно восстановления пропущенных данных) Поскольку данные в исходном наборе упорядочены, на следующем шаге мастера обработки выделим поле «СИНУС» и укажем для него тип обработки «Аппроксимация». Так как в данном случае больше ничего не требуется, то остальные параметры обработки оставляем отключенными. (рис.21)  Рис. 22 (окно выполнения парциальной обработки ) Перейдя на страницу запуска процесса обработки, выполняем ее, нажав на пуск, и далее выбираем тип визуализации обработанных данных (как в примере импорта).(рис.22) 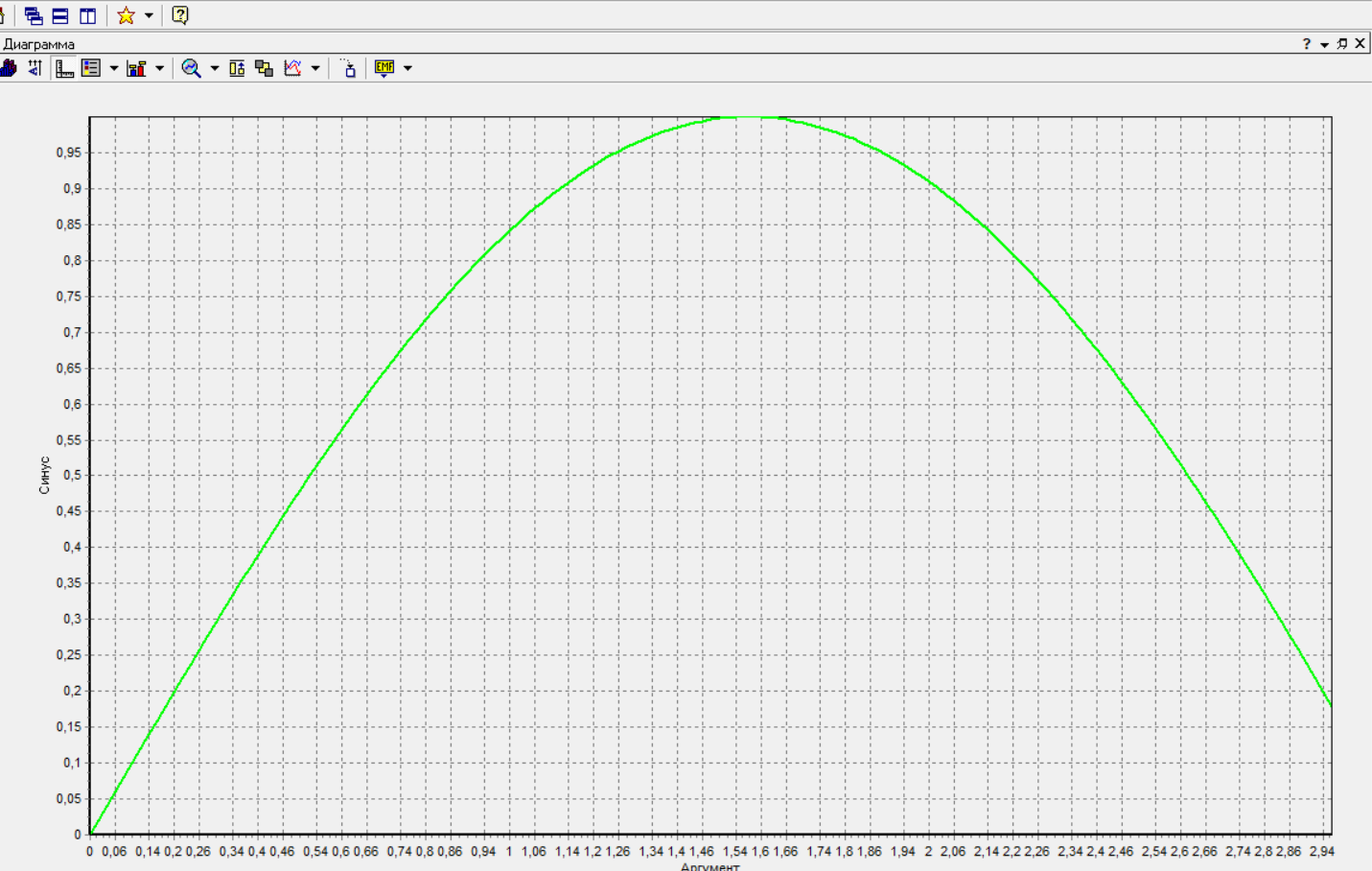 Рис. 23 (график аргумента после парциальной обработки ) После выполнения процесса обработки на диаграмме видно, что пропуски в данных исчезли, что и было необходимо сделать. Задание 2.Удаление аномалийАномалии встречаются в «сырых» данных не реже шумов. По существу они вообще не должны оказывать никакого влияния на результат. Если же они присутствуют при построении модели, то оказывают на нее весьма большое влияние. Т.е. предварительно их необходимо устранить. Также они портят статистическую картину распределения данных. К примеру, вот как выглядят данные с аномалиями, а также гистограмма их распределения: Очевидно, что аномалии не позволяют определить как характер самих данных, так и статистическую картину. После устранения аномалий те же данные представляются в следующем виде: Этот пример еще раз подчеркивает необходимость проведения парциальной обработки данных перед анализом. Вернемся к примеру с удалением аномалий из поля «АНОМАЛИИ» импортированной таблицы. (рис.19-21) 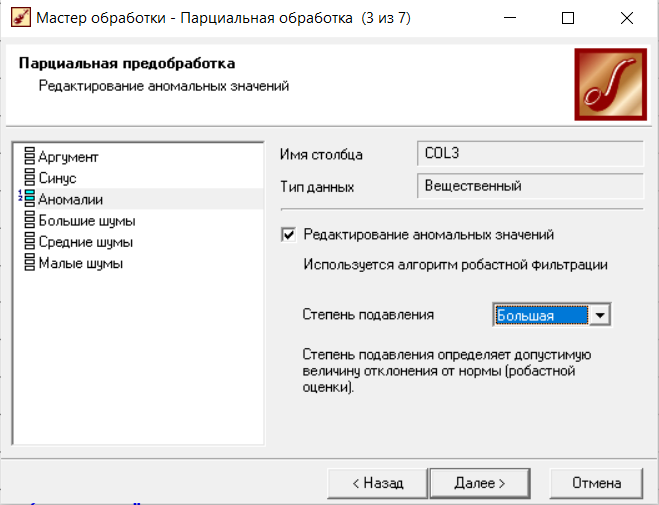 Рис. 24 (окно редактирования аномальных значений) В мастере парциальной предобработки на третьем шаге выбираем поле «АНОМАЛИИ» и указываем ему тип обработки «Удаления аномальных явлений», степень подавления «Большая». (рис. 24)  Рис. 25 (окно выполнения редактирования аномальных значений) Так как больше никаких обработок не планировалось, то переходим на шаг запуска процесса обработки и нажимаем «Пуск».(рис.25)  Рис. 26 (окно выбора способа отображения данных) Не стоит забывать выбрать способ отображения данных «Диаграмма»(рис.26) 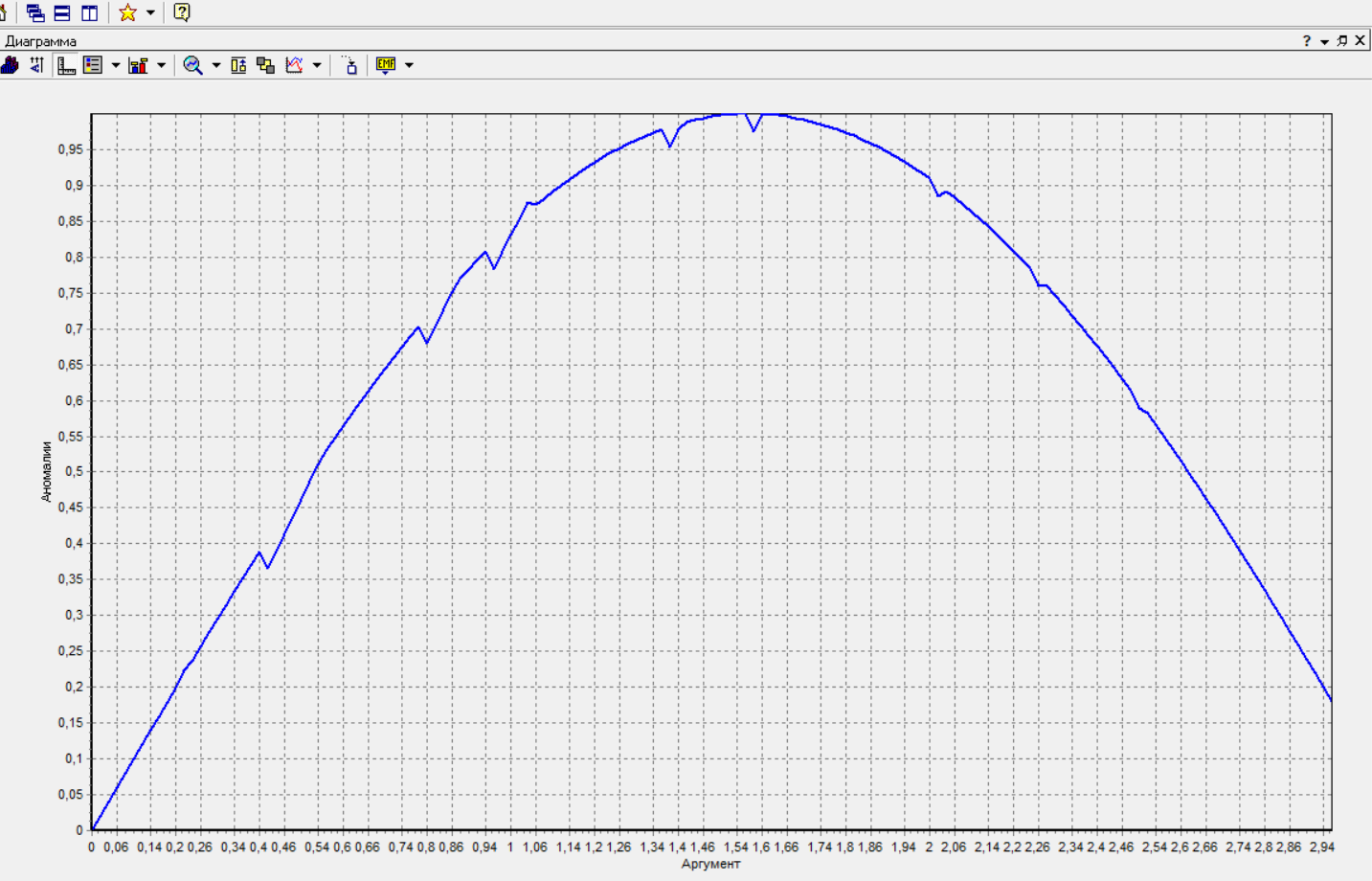 Рис. 27 (график аномалии после редактирования аномальных значений) После выполнения процесса обработки на диаграмме видно, что выбросы исчезли, остались лишь небольшие возмущения, которые легко сгладить при помощи спектральной обработки.(рис. 27) Задание 3.Спектральная обработкаДанные, как мы видим из предыдущего примера, бывает необходимо сгладить. Сглаживание данных применяется для удаления шумов из исходного набора, (что будет продемонстрировано позднее) а также для выделения тенденции, трудно видимой в исходном наборе. Платформа 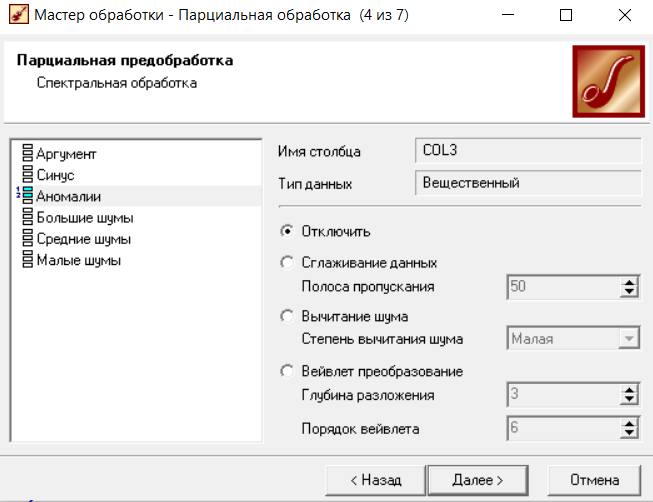 Рис. 28 (виды спектральной обработки) Deductor Studio предлагает несколько видов спектральной обработки: сглаживание данных путем указания полосы пропускания, вычитание шума путем указания степени вычитания шума и вейвлет преобразование путем указания глубины разложения и порядка вейвлета-эти данные расположены в левой части окна спектральной обработки. (рис. 28) 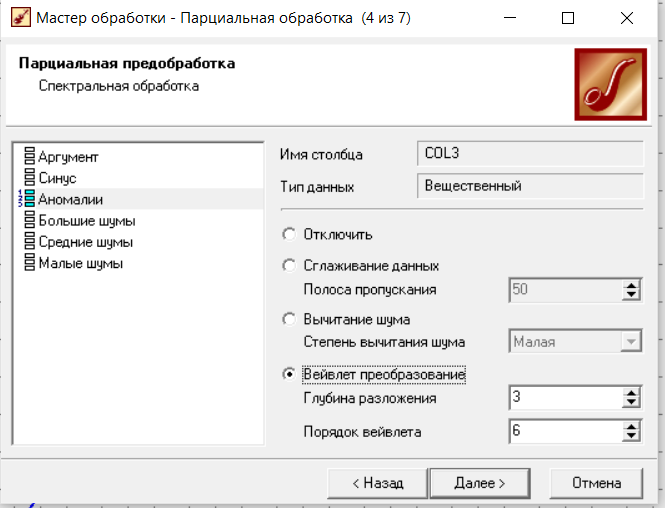 Рис. 29 (окно спектральной обработки) Продемонстрируем такой метод спектральной обработки, как вейвлет преобразование. Для этого продолжим работу с данными, полученными в предыдущем примере. Как видно на рисунке, аномалии были устранены, однако небольшие возмущения остались. Сгладим их при помощи парциальной обработки. Для этого после удаления аномалий вновь запустим мастер парциальной обработки. В нем на четвертом шаге выберем поле «АНОМАЛИИ» и укажем ему тип обработки «Вейвлет преобразование» с параметрами по умолчанию (глубина разложения 3, порядок вейвлета 6). Далее повторяем действия с рисунков 25-26 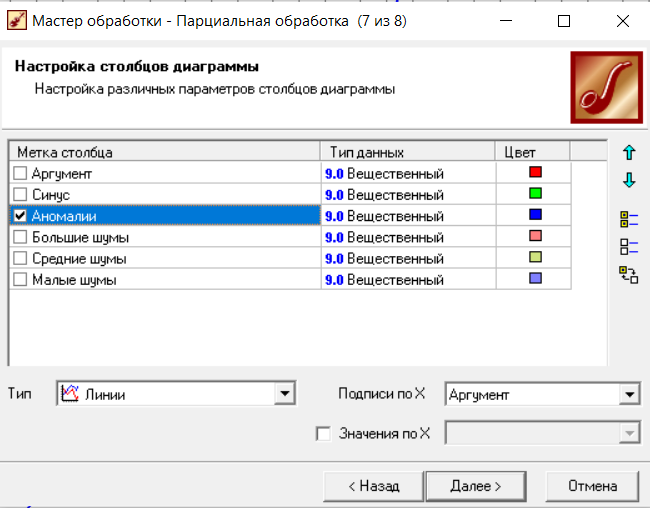 Рис. 30 (настройка параметров столбцов диаграммы) Не стоит забывать выбрать метку столбца «Аномалии»(рис.30) Так как больше ничего не планировалось, то перейдем с шагу запуска процесса обработки и выполним ее. В качестве визуализатора укажем диаграмму. 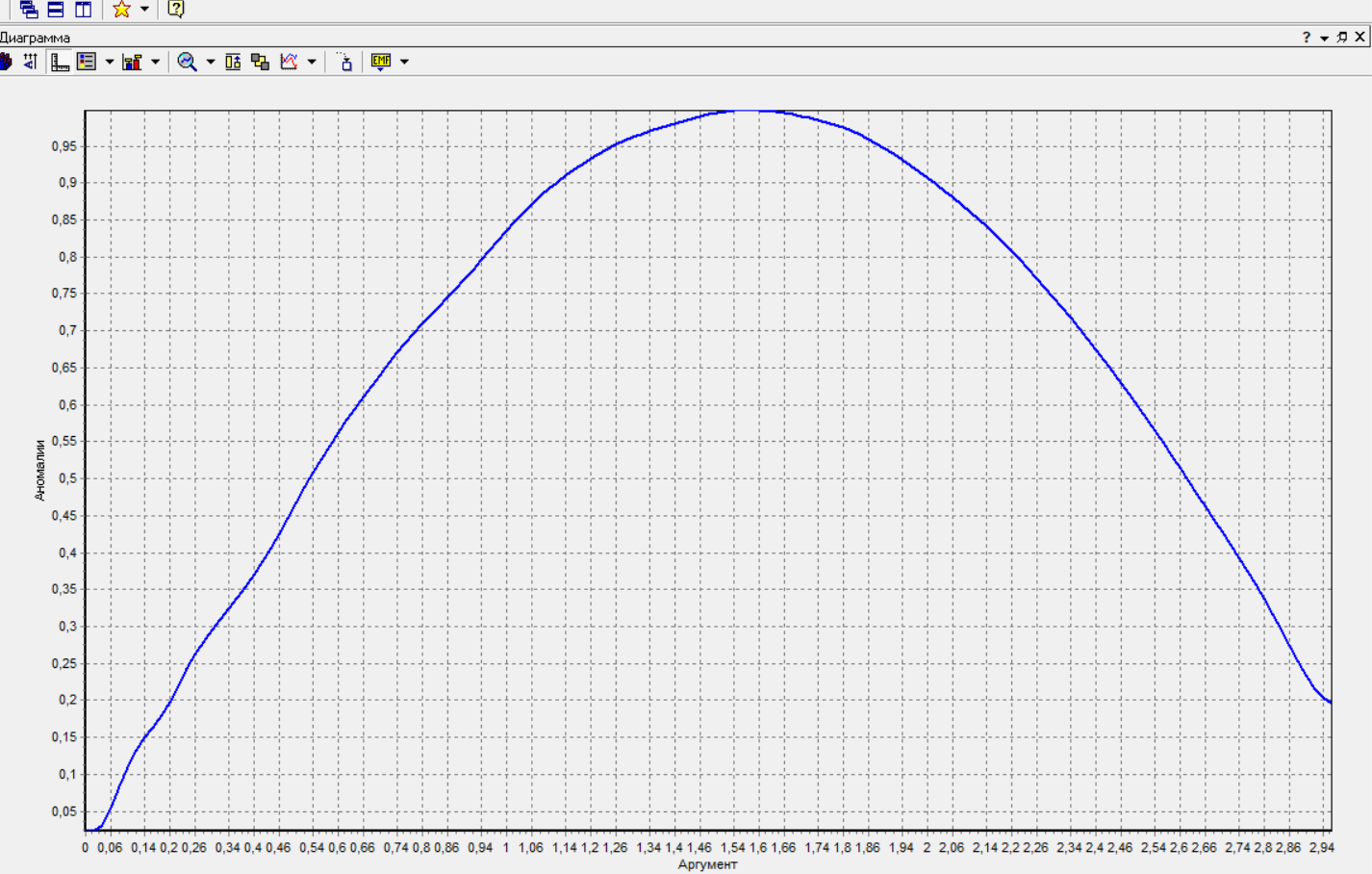 Рис. 31 (график аргумента после спектральной обработки) После спектральной обработки мы получаем график с рисунка 31 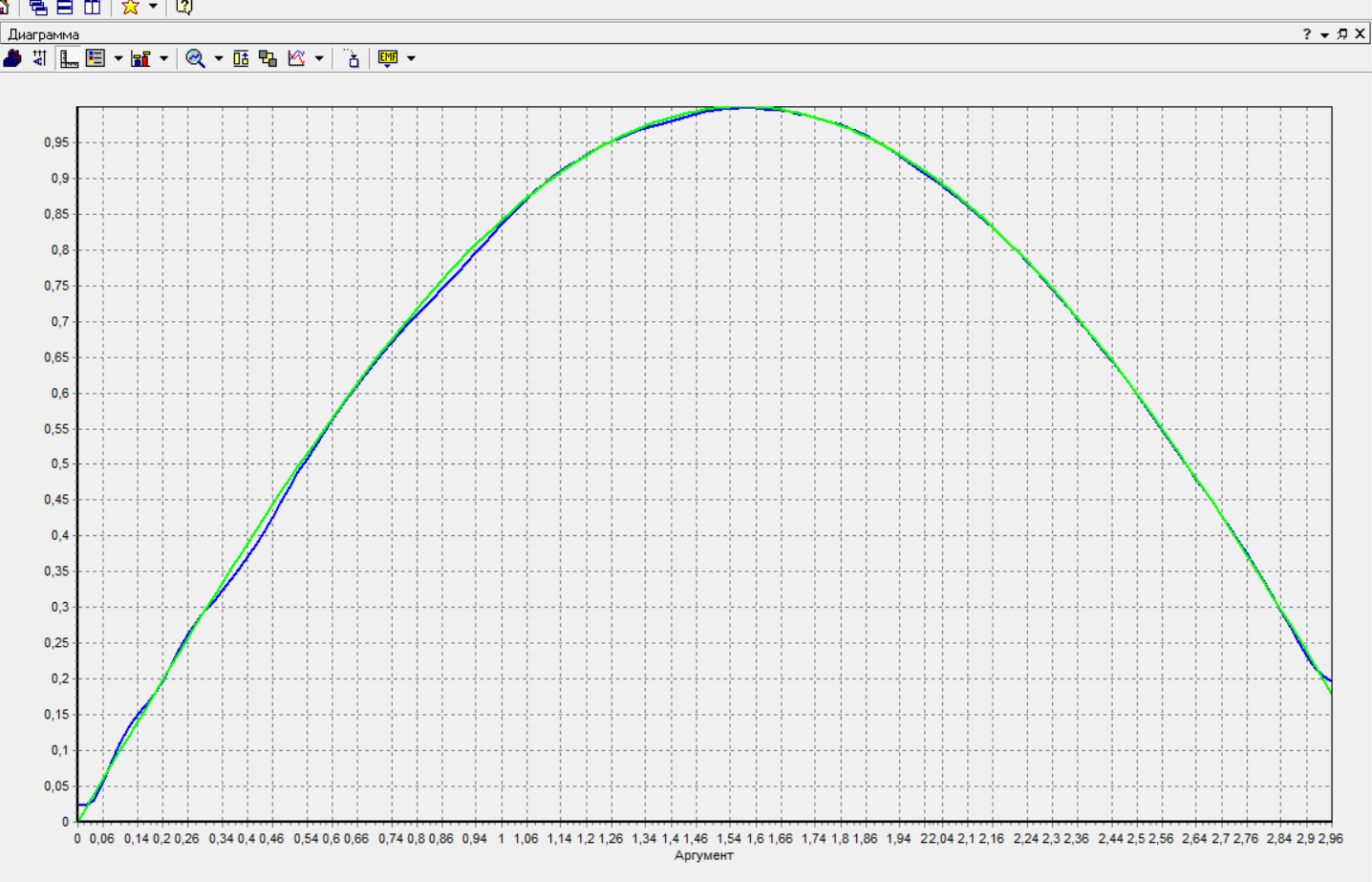 Рис. 32 (сравнение графиков в синусов и аргумента после спектральной обработки) После обработки можно убедиться на диаграмме в отсутствии выбросов и сравнить результат с эталонным значением синуса (столбец «СИНУС»). На рисунке зеленый график – значения синуса, синий –значения сглаженного синуса после устранения аномалий.(рис.32) Задание 4.Удаление шумовШумы в данных не только скрывают общую тенденцию, но и проявляют себя при построении модели прогноза. Из-за них модель может получиться с плохими обобщающими качествами.  Рис. 33 (виды шумов) В примере по парциальной обработке, как было показано ранее, есть 3 столбца с шумами: «БОЛЬШИЕ ШУМЫ», «СРЕДНИЕ ШУМЫ», и «МАЛЫЕ ШУМЫ» - соответственно синус с большими, средними и малыми шумами. Ясно, что для дальнейшей работы с данными эти шумы необходимо устранить. Спектральная обработка, как говорилось ранее, позволяет сделать это с помощью указания для этих полей в качестве типа обработки «Вычитание шума». Настройки обладают определенной гибкостью. Так, существует большая, средняя и малая степень вычитания шума. Аналитик может подобрать степень, устраивающую его. Удаление больших, малых и средних шумов. 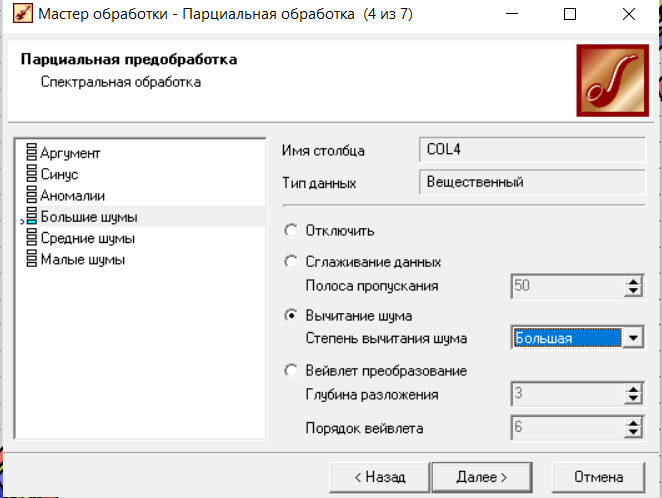 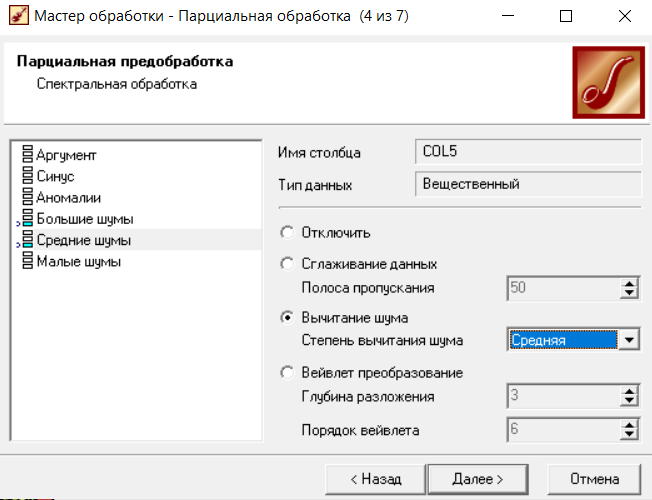 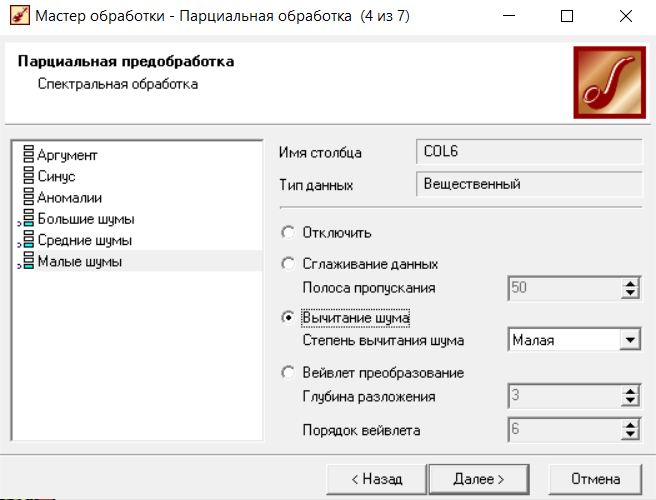 Рис. 33 (типы обработки) 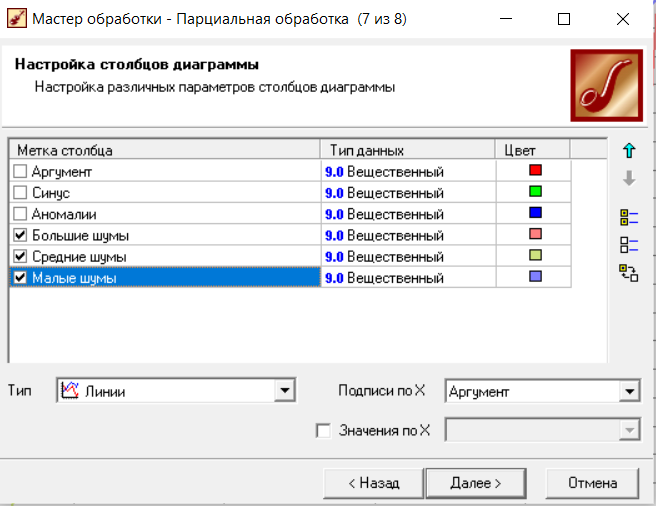 Рис. 34 (настройка параметров столбцов диаграммы) Таким образом, в мастере парциальной обработки на четвертом шаге выберем по очереди поля «БОЛЬШИЕ ШУМЫ», «СРЕДНИЕ ШУМЫ» и «МАЛЫЕ ШУМЫ» (рис.34) , зададим тип обработки «Вычитание шума» и укажем степень подавления – «большая», «средняя» и «малая» соответственно.(рис.33) 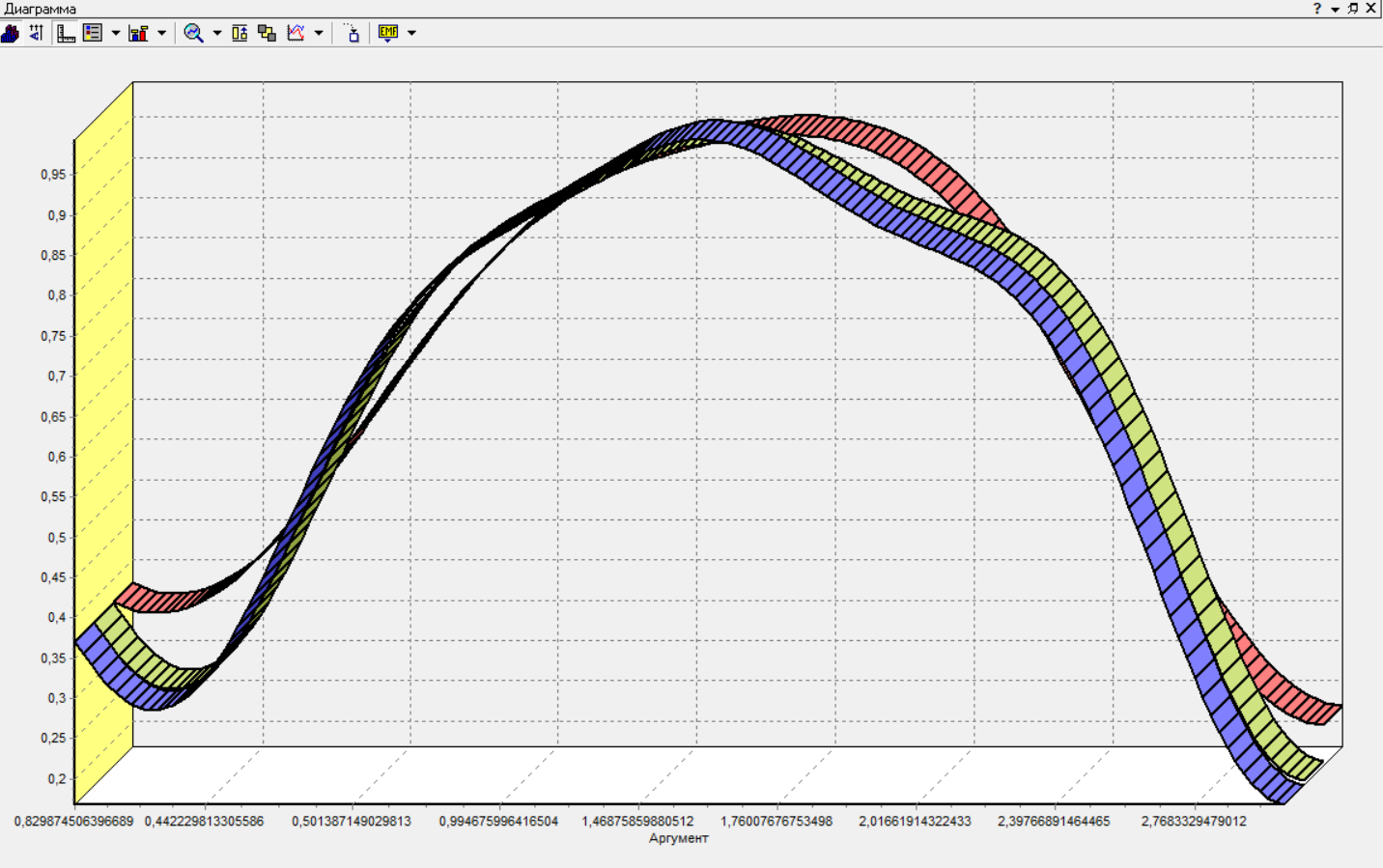 Рис. 35 (график шумов) После выполнения обработки на диаграмме можно просмотреть полученные результаты.(рис.35) Задание 5.Сглаживание шумовСглаживание больших, малых и средних шумов В некоторых случаях неплохие результаты удаления шумов дает вейвлет преобразование. Покажем, какие результаты показывает на этих же данных этот вид спектральной обработки. 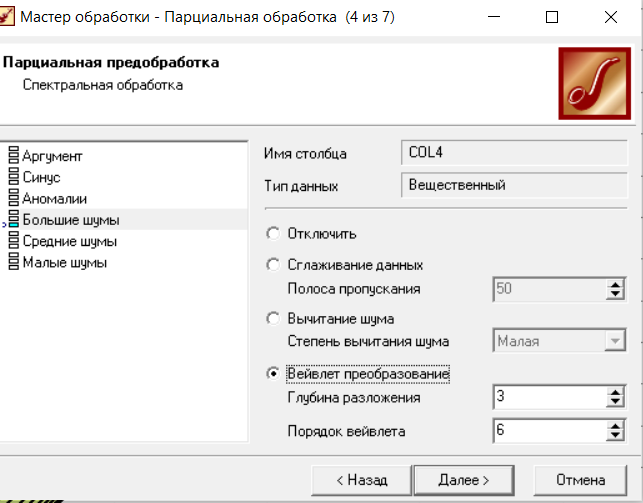 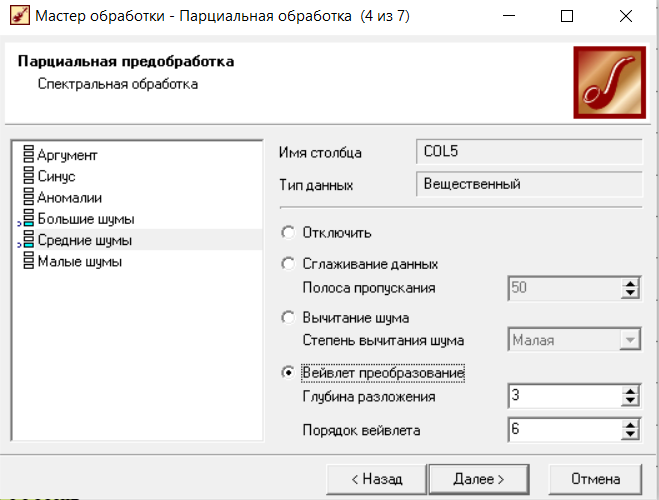 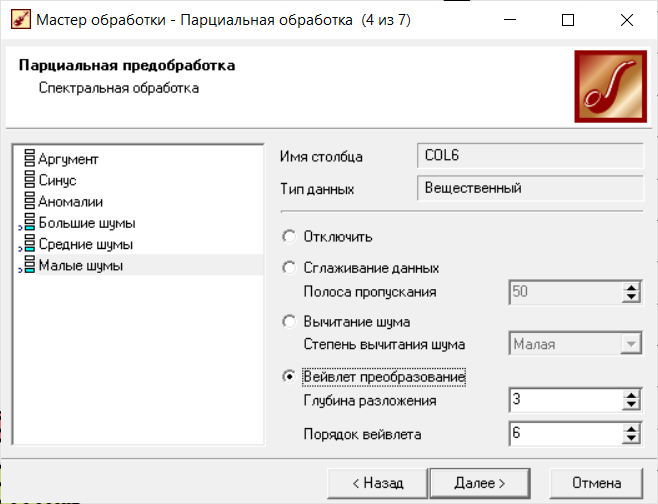 В мастере парциальной обработки выберем поля «БОЛЬШИЕ ШУМЫ». «СРЕДНИЕ ШУМЫ» и «МАЛЫЕ ШУМЫ», укажем тип обработки «Вейвлет преобразование», оставив параметры обработки по умолчанию (глубина разложения – 3, порядок вейвлета – 6). 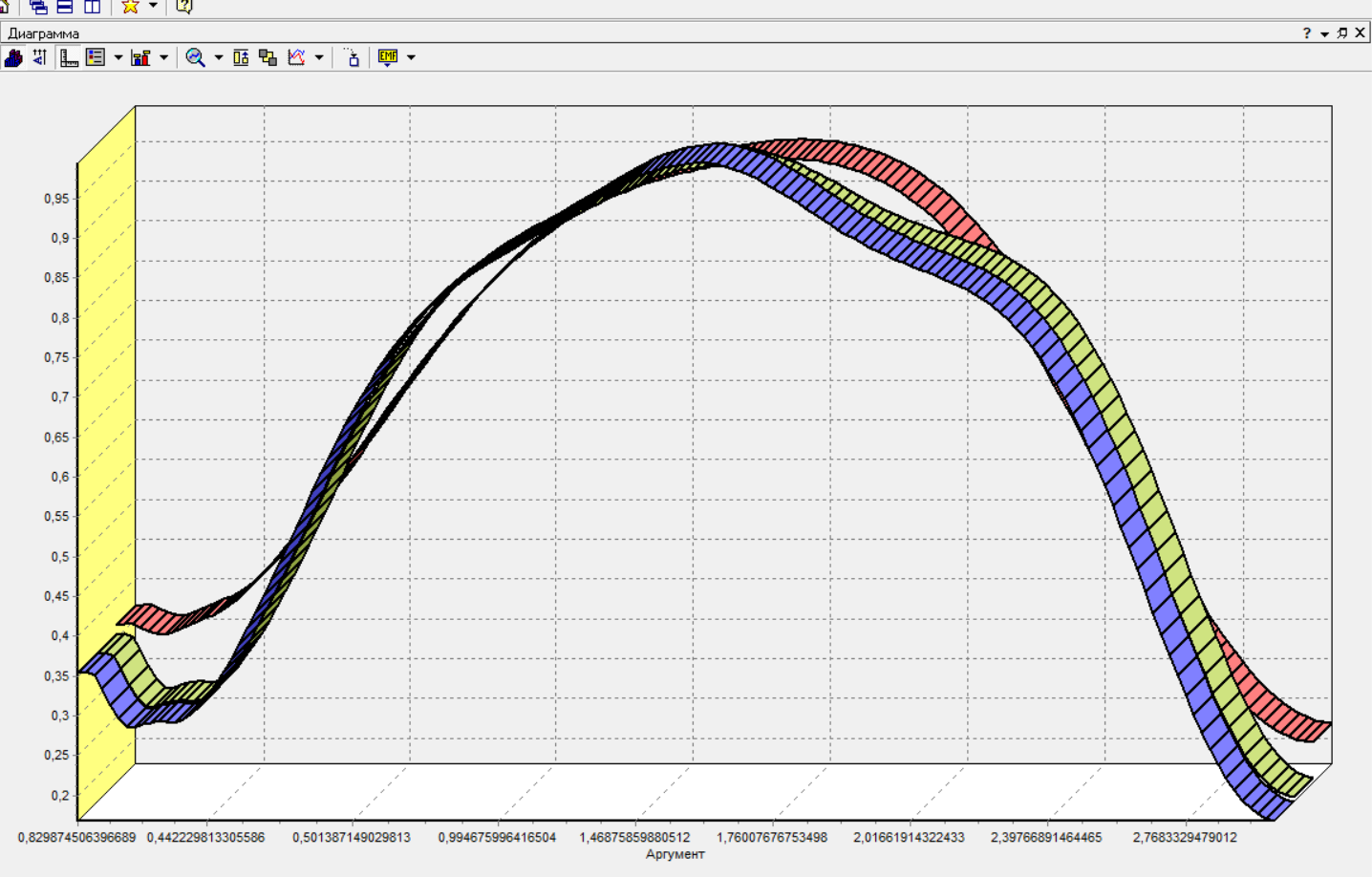 Рис. 36 (график сглаженных шумов) На диаграмме можно убедиться в том, что данные сгладились. Синий график – сглаженные большие шумы, красный – сглаженные средние и желтый – сглаженные малые шумы. Повысить качество сглаживания шумов таким способом можно, путем подбора удовлетворительных параметров обработки. Вывод В процессе выполнения Лабораторной работы № 2 мы ознакомились с некоторыми функциями программы, а точнее- обработка данных. На практике ознакомились с процессом восстановления пропущенных данных, спектральная обработка данных, удаление аномалий, сглаживание шумов. Лабораторная работа № 3. Корреляционный анализКорреляционный анализ применяется для оценки зависимости выходных полей данных от входных факторов и устранения незначащих факторов. Принцип корреляционного анализа состоит в поиске таких значений, которые в наименьшей степени коррелированы (взаимосвязаны) с выходным результатом. Такие факторы могут быть исключены из результирующего набора данных практически без потери полезной информации. Критерием принятия решения об исключении является порог значимости. Если корреляция (степень взаимозависимости) между входным и выходным факторами меньше порога значимости, то соответствующий фактор отбрасывается как незначащий. Задания 1.Исходные данные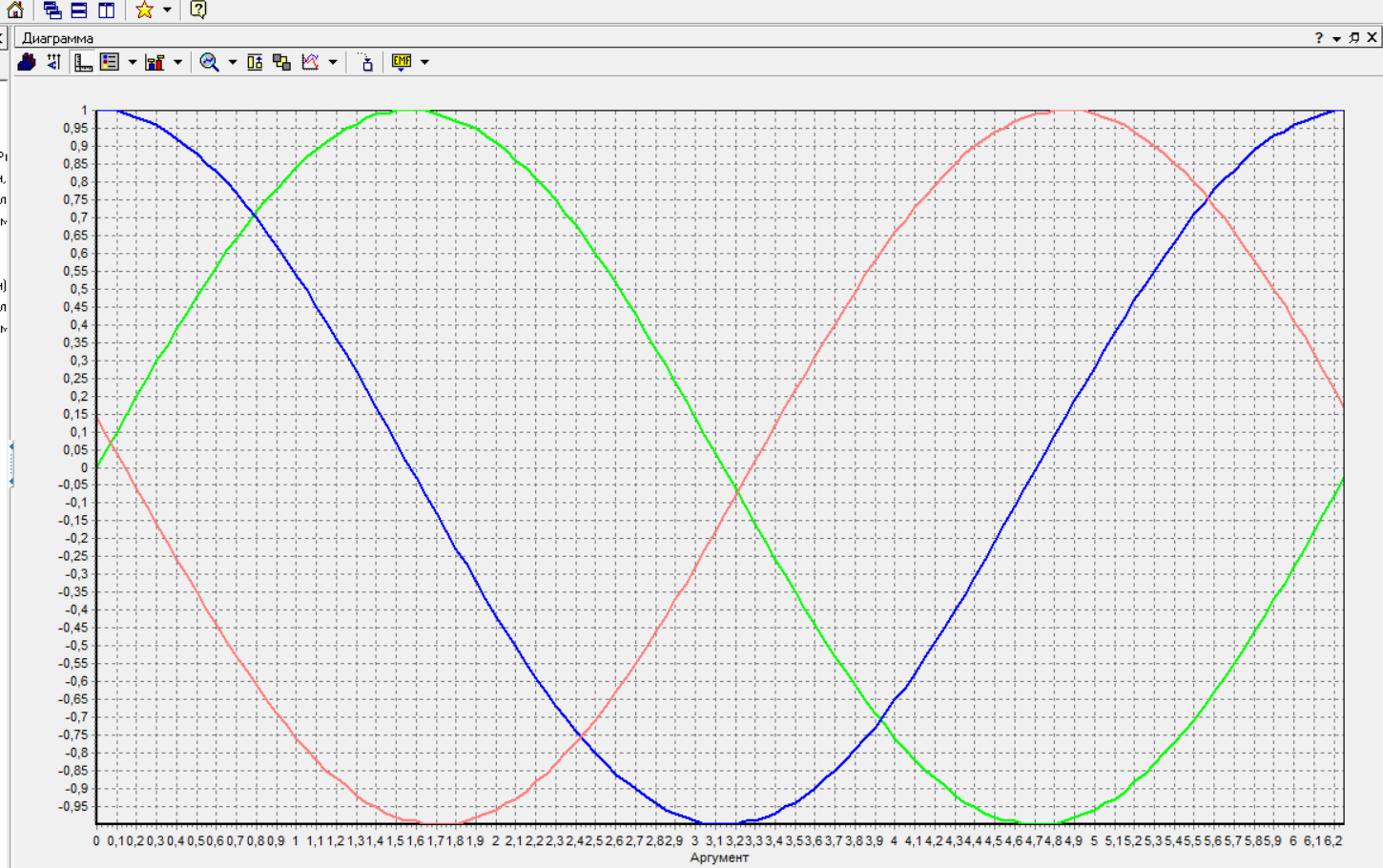 Рис. 37 (график входных значений) 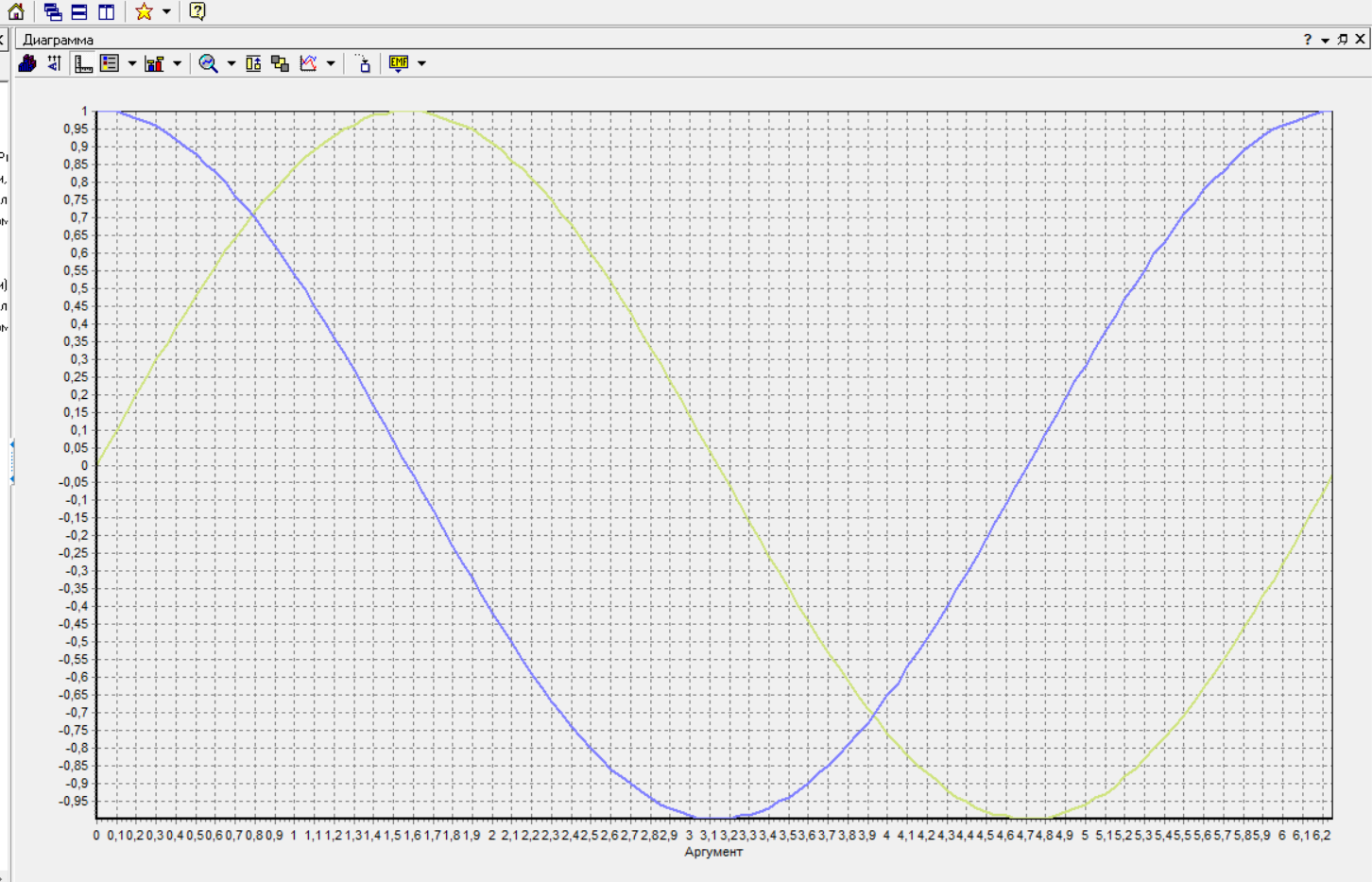 Рис. 38 (график выходных значений) Рассмотрим применение обработки на примере данных из файла «TestForCPP.txt».Для этого проводим действие с рисунков 1-10 только заменив файл на «TestForCPP.txt» Данный файл содержит таблицу со следующими полями: «АРГУМЕНТ» – аргумент, «ФАКТОР1», «ФАКТОР2», «ФАКТОР3» – входные значения,(рис.37) «РЕЗУЛЬТАТ1», «РЕЗУЛЬТАТ2» – выходные значения.(рис.38) В данном примере определим степень влияния входных факторов на один из выходов – «РЕЗУЛЬТАТ2» и оставим только значимые факторы. Задание 2.Устранение незначащих входных факторов Рис. 39 (нахождение мастера корреляционного анализа)  Рис. 40 (обозначение некоторых значений входными полями)  Рис. 41 (обозначение некоторых значений информационными полями) В мастере корреляционного анализа(рис. 39) зададим «ФАКТОР1», «ФАКТОР2», «ФАКТОРЗ» входными полями(рис.40), «РЕЗУЛЬТАТ2» - выходными, а поля «АРГУМЕНТ» и «РЕЗУЛЬТАТ1» - информационным.(рис.41) 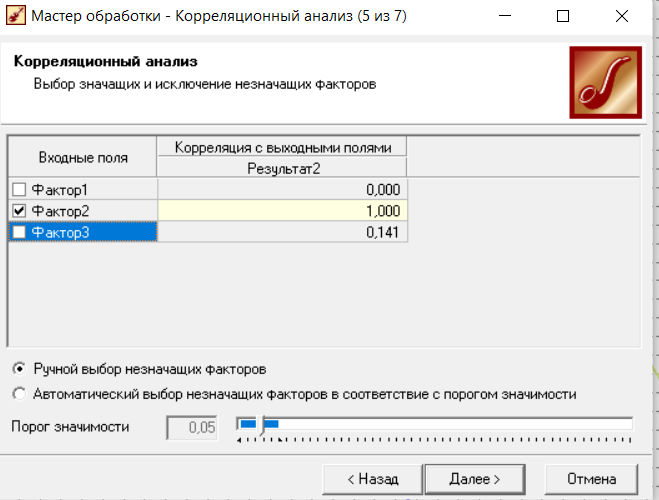 Рис. 42 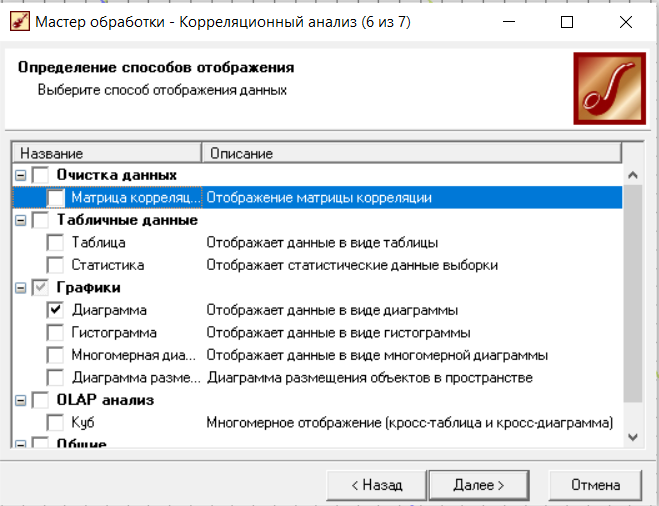 Рис.43 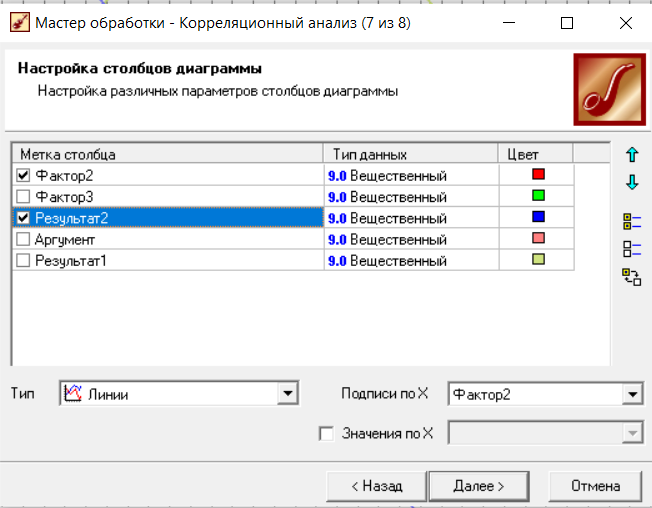 Рис.44 Рис. 42-44 (процесс выбора факторов для корреляции) Следующий шаг предлагает запустить процесс корреляционного анализа. После завершения процесса на следующем шаге предлагается выбрать, какие факторы оставить для дальнейшей работы. Это делается либо вручную, основываясь на значениях матрицы ковариации, либо путем указания порога значимости (по умолчанию порог значимости равен 0.05). Из рассчитанной матрицы ковариации видно, что выходное поле «РЕЗУЛЬТАТ2» напрямую зависит от поля «ФАКТОР2» (вообще, значение коэффициента, равное 1.000 говорит о том, что эти поля идентичны), и в меньшей степени от остальных факторов. В данном случае без потери полезной информации можно исключить из дальнейшего рассмотрения «Фактор1» и «Фактор З». (рис. 42-43) Теперь необходимо перейти на следующий шаг и выбрать способ визуализации: просмотрим результаты на диаграмме (например, можно убедиться в идентичности полей «Фактор2» и «Результат2»).(рис.44) 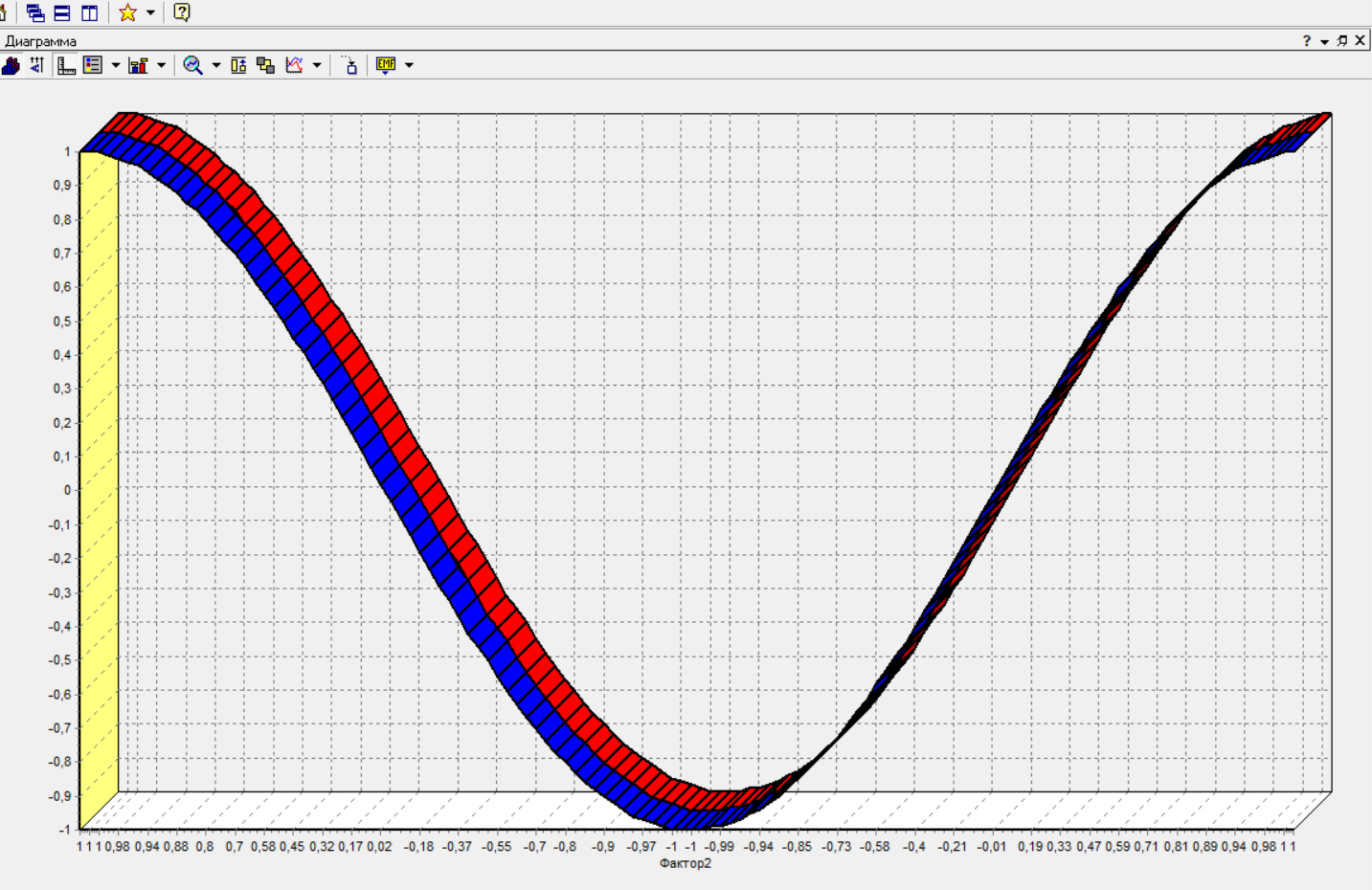 Рис.45 (результат корреляционного анализа по заданным параметрам) Рис.45 (результат корреляционного анализа по заданным параметрам)Таким образом, корреляционный анализ позволил проанализировать влияние входных факторов на результат и исключить незначащие факторы из дальнейшего анализа. Вывод В процессе выполнения Лабораторной работы №3 мы ознакомились с корреляционный анализом, который применяется для оценки зависимости выходных полей данных от входных факторов и устранения незначащих факторов. На практике изучили и рассмотрели процесс корреляционного анализа. Лабораторная работа № 4. Фильтрация данныхЗадания 1.Фильтрация данныхПочти всегда исходный набор данных, или набор данных после обработки аналитику необходимо отфильтровать. Фильтрация бывает необходима для разбиения данных на какие либо группы (например, товарные группы) для последующей обработки или анализа данных уже отдельно по каждой группе. Также некоторые данные могу не подходить, или наоборот, подходить для дальнейшего анализа в силу накладываемых условий (например, если на каком – либо этапе обработки данных были выявлены противоречивые записи, то их необходимо исключить из последующей обработки). Здесь тоже возникает необходимость фильтрации. Фильтрация позволяет из базового набора данных получить набор данных, удовлетворяющий определенным аналитиком условиям. В Deductor Studio механизм построения условий фильтрации прост для понимания. В окне мастера можно определить несколько элементарных условий фильтрации (<ПОЛЕ> <ОТНОШЕНИЕ> <ЗНАЧЕНИЕ>), последовательно связанных логическими операциями (И, ИЛИ). 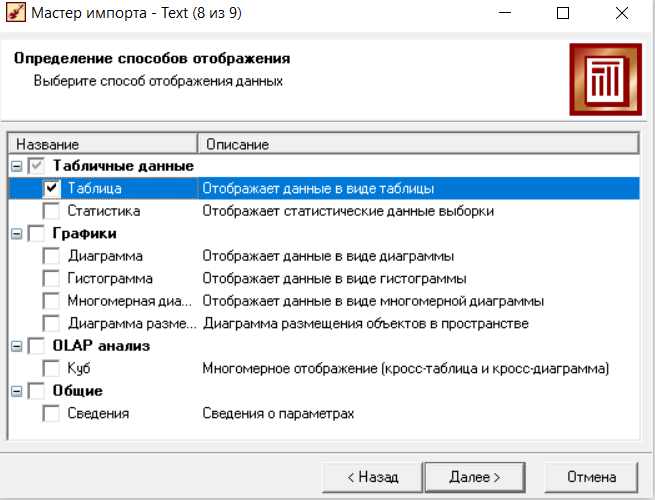 Рис. 46 (выбор способа отображения данных) Рассмотрим ситуацию, когда аналитику необходимо спрогнозировать кредитоспособность потенциального кредитора (файл Credit.txt).Повторяем шаги с 1 по 10 картинку, только в форматировании используем таблицу(рис.46)  Рис. 47 (выбор категории «фильтрация») Предполагается, что кредиторы, берущие суммы разного диапазона ведут Себя по-разному, следовательно, модели прогноза должны свои для каждой группы. Т.е. для дальнейшего построения моделей прогноза кредитоспособности определенных аналитиком категорий необходимо использовать фильтрацию.(рис.47) 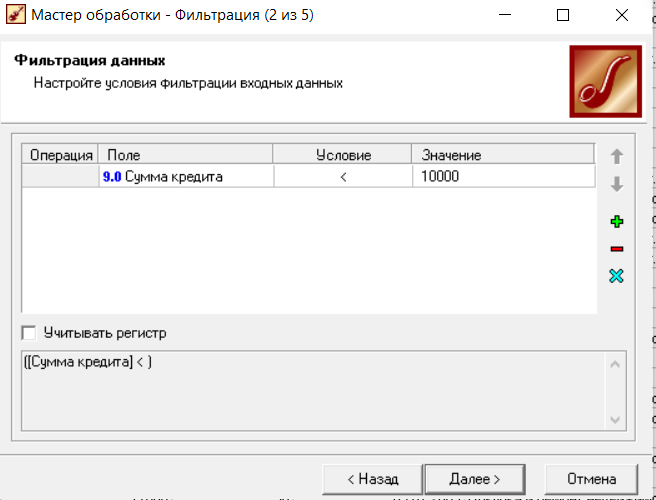 Рис. 48 (настройки условия фильтрации) Определим, для примера группу кредиторов, взявших кредит менее 10000 руб. Воспользуемся данными предыдущего примера. Для этого, находясь на узле импорта данных из текстового файла, запустим мастер обработки. В нем в качестве метода обработки выберем фильтрацию. На втором шаге мастера можно видеть одно неопределенное условие фильтрации (при необходимости их можно добавлять или удалять соответствующими кнопками на форме). Поскольку необходимо отфильтровать данные только по кредиторам, взявших кредит менее 10000, то в графе «Имя поля» выбираем поле «СУММА КРЕДИТА», в графе «Условие» выбираем знак меньше, в графе «Значение» пишем «10000».(рис.48) 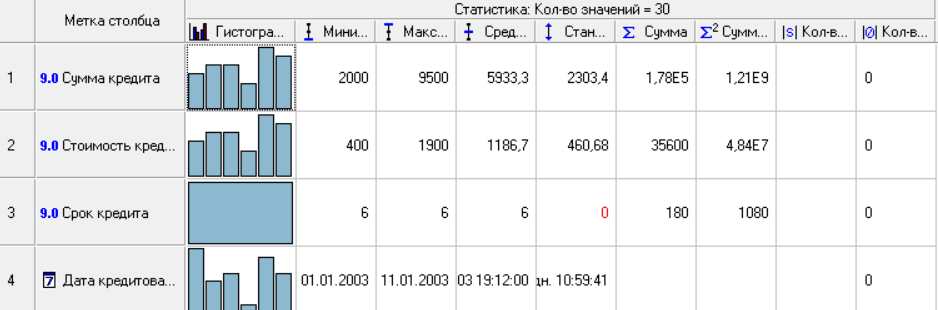 Рис. 49 (статистика) Больше никаких условий не требуется, поэтому переходим на следующий шаг мастера и запускаем процесс фильтрации. После выполнения обработки можно манипулировать уже только с данными по кредиторам выбранного кредитного диапазона. В правильности выполненной операции можно легко убедиться, выбрав в качестве визуализации данных статистику и просмотрев значения минимального и максимального значения поля «СУММА КРЕДИТА».(рис.49) Вывод В процессе выполнения Лабораторной работы №4 мы изучили важный механизм программы-фильтрацию данных, что позволяет нам отделить нужные нам данные, посредствам настройки мастера фильтров. Лабораторная работа № 5. Выявление дубликатов и противоречийБывают ситуации, когда проблема неочищенных данных не позволяет построить хорошую модель прогнозирования вообще. Такое происходит, если в наборе данных для прогноза содержатся строки с одинаковыми входными факторами, но разными выходными. В такой ситуации непонятно, какое результирующее значение верное – налицо противоречие. Если противоречивые использовать для построения модели прогноза, то модель окажется неадекватной. Поэтому противоречивые данные, чаще всего, лучше вообще исключить из исходной выборки. Также в данных могут встречаться записи с одинаковыми входными факторами и одинаковыми выходными, т.е. дубликаты. Таким образом, данные несут избыточность. Присутствие дубликатов в анализируемых данных можно рассматривать как способ повышения «значимости» дублирующийся информации. Иногда они даже необходимы, например, если при построении модели нужно особо выделить некоторые наборы значений. Но все равно, включение в выборку дублирующей информации должно происходить осознанно: в большинстве случаев дубликаты в данных являются следствием ошибок при подготовке данных. Так или иначе, возникает задача выявления дубликатов и противоречий. В Deductor Studio для автоматизации этого процесса есть соответствующий инструмент – обработка «Дубликаты и противоречия». Суть обработки состоит в том, что определяются входные (факторы) и выходные (результаты) поля. Алгоритм ищет во всем наборе записи, для которых одинаковым входным полям соответствуют одинаковые (дубликаты) или разные (противоречия) выходные поля. На основании этой информации создаются два дополнительных логических поля – «Дубликат» и «Противоречие», принимающие значения «правда» или «ложь». В дополнительные числовые поля «Группа дубликатов» и «Группа противоречий» записываются номер группы дубликатов и группы противоречий, в которые попадает данная запись. Если запись не является дубликатом или противоречием, то соответствующее поле будет пустым. Задание 1.Исходные данныеРассмотрим механизм выявления дубликатов и противоречий на примере данных файла «MultTable.txt». В нем находится таблица умножения двух целых аргументов в диапазоне от 1 до 10. Таблица имеет четыре поля: «АРГУМЕНТ1», «АРГУМЕНТ2» – аргументы, «ПРОИЗВЕДЕНИЕ», «ПРОИЗВЕДЕНИЕ С ПРОТИВОРЕЧИЯМИ» – произведение аргументов, содержащее противоречия. Данные подготовлены следующим образом: сначала идет 100 строк таблицы умножения (от 1*1 до 10*10), причем в поле «ПРОИЗВЕДЕНИЕ С ПРОТИВОРЕЧИЯМИ» в некоторых строках содержатся неверный результат умножения (например, «АРГУМЕНТ1» = 1, «АРГУМЕНТ2»=5, «ПРОИЗВЕДЕНИЕ» = 5, «ПРОИЗВЕДЕНИЕ С ПРОТИВОРЕЧИЯМИ» = 10). Следующие 50 строк дублируют первые 50, причем значения поля «ПРОИЗВЕДЕНИЕ С ПРОТИВОРЕЧИЯМИ» содержат верный результат умножения. Таким образом, данные содержат ряд строк с одинаковыми входными значениями, но разными выходными и строки с одинаковыми входными и выходными значениями. Т.е. присутствуют дубликаты и противоречия. Остается только обнаружить их. 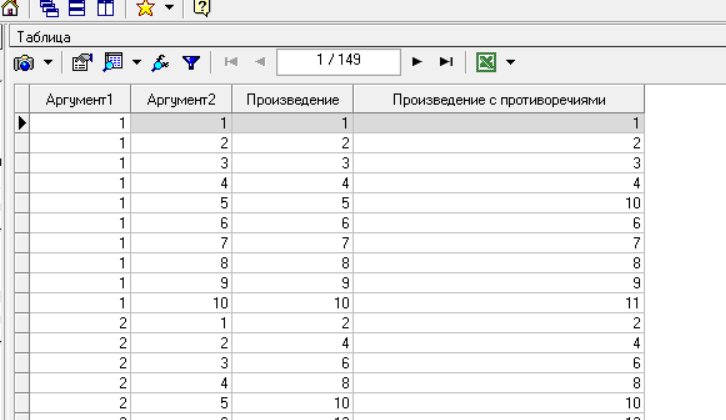 Рис. 50 (импортированные данные из файла в виде таблицы) Импортируем данные из текстового файла и посмотрим их в виде таблицы.(рис.50) Задание 2.Поиск дубликатов и противоречий Рис. 51(выбор типа обработки «дубликаты и противоречия») Для выявления дубликатов и противоречий запустим мастер обработки. В нем выберем тип обработки «Дубликаты и противоречия».(рис.51) 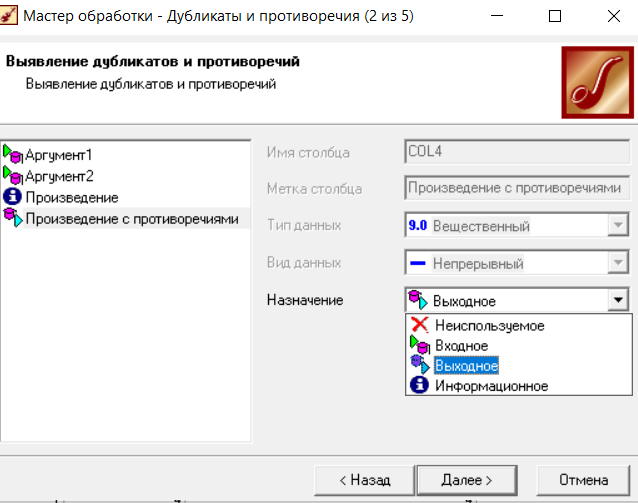 Рис.52 (настройка назначения полей) На втором шаге мастера необходимо настроить назначение полей. В данном случае входными полями являются «АРГУМЕНТ1» и «АРГУМЕНТ2», а выходным «ПРОИЗВЕДЕНИЕ С ПРОТИВОРЕЧИЯМИ».(рис.52)  Рис. 53(запуск процесса обработки) На следующем шаге необходимо запустить процесс обработки.(рис.53) 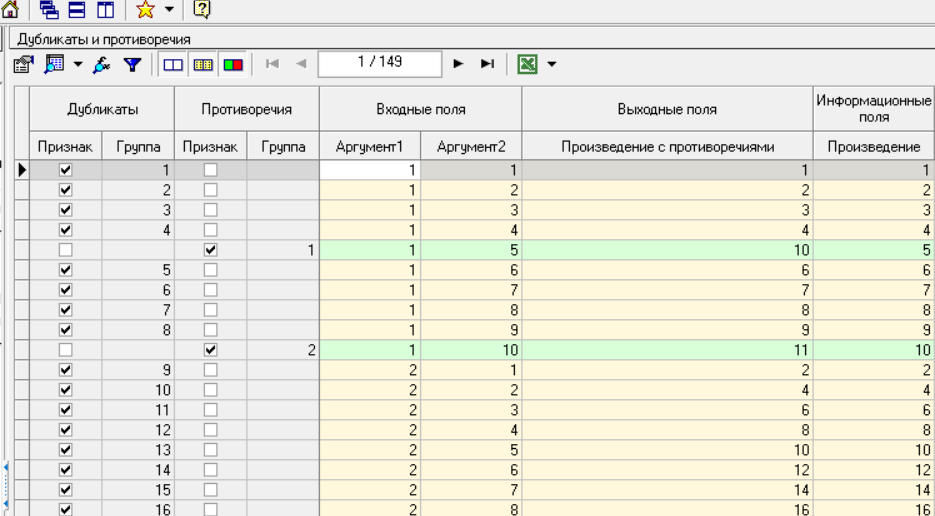 Рис.54 (результат выявления дубликатов в таблице) После завершения выявления дубликатов и противоречий просмотрим результат в виде таблицы.(рис.54) В четырех новых столбцах как раз и находится интересующая нас информация: какие записи являются дубликатами, какие – противоречиями, к какой группе дубликатов или противоречий относятся.  Рис. 55 (кнопка фильтрации данных) Нажав на кнопку фильтрации таблицы, появится мастер настроек условий Фильтра(рис.56) (аналогичный обработчику «Фильтрация», рассмотренного ранее).(рис 55) 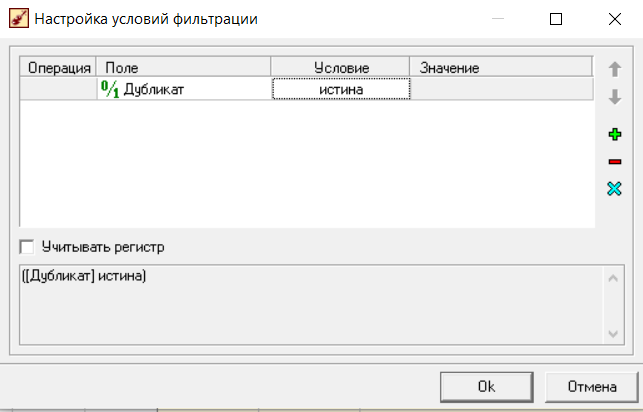 Рис.56 (мастер настройки фильтрации) Для просмотра только дубликатов необходимо задать условие «Дубликат истина» (рис.56) 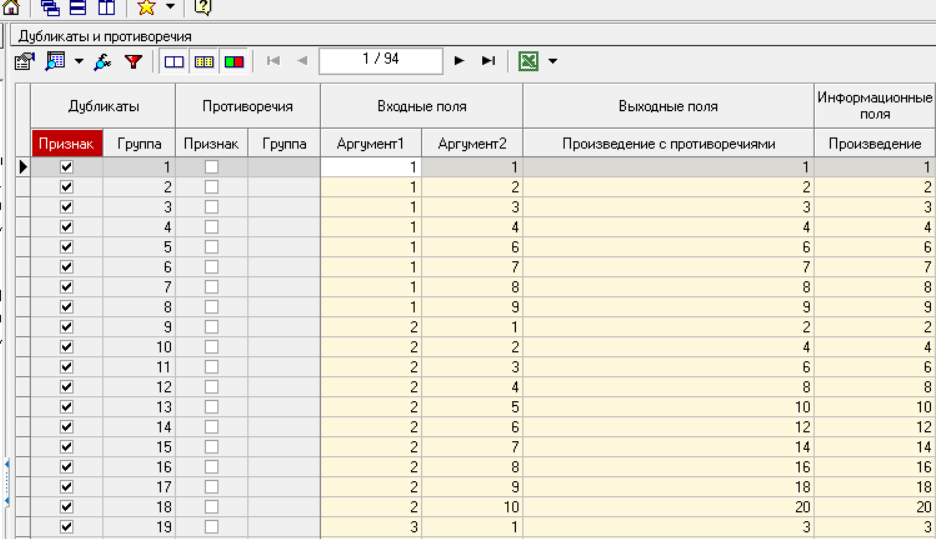 Рис.57(результат применения фильтра дубликата) После ввода условия необходимо нажать на кнопку «Ок» и в таблице будут только дубликаты. (рис.57) Аналогично отфильтруем только противоречия.(рис.58) 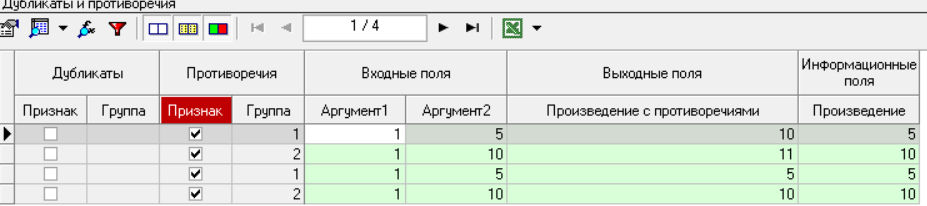 Рис.58 (результат применения фильтра противоречия) Вывод В процессе выполнения Лабораторной работы № 5 нами было проделано изучение и использование на практике механизма выявления дубликатов и противоречий, для автоматизации этого процесса есть соответствующий инструмент – обработка «Дубликаты и противоречия». |