Глава 3 Передача речи по IP сетям. Передача речи по ipсетям 1 Особенности передачи речевой информации по ip сетям
 Скачать 201.5 Kb. Скачать 201.5 Kb.
|

|
3.2.1 Кодирование формы сигнала Импульсно-кодовая модуляция, по сути, и представляет собой схему кодирования формы сигнала. Однако нас интересуют более сложные алгоритмы, позволяющие снизить требования к полосе пропускания. Рассматриваемые методы кодирования формы сигнала используют то обстоятельство, что между случайными значениями нескольких следующих подряд отсчетов существует некоторая зависимость. Проще говоря, значения соседних отсчетов обычно мало отличаются одно от другого. Это позволяет с довольно высокой точностью предсказать значение любого отсчета на основе значений нескольких предшествовавших ему отсчетов. При построении алгоритмов кодирования названная закономерность используется двумя способами. Во-первых, есть возможность изменять параметры квантования в зависимости от характера сигнала. В этом случае шаг квантования может изменяться, что позволяет до некоторой степени сгладить противоречие между уменьшением числа битов, необходимых для кодирования величины отсчета при увеличении шага квантования, и сужением динамического диапазона кодера, неизбежным без адаптации (о которой речь пойдет ниже). Некоторые алгоритмы предусматривают изменение параметров квантования приблизительно в рамках произносимых слогов, а некоторые изменяют шаг квантования на основе анализа статистических данных об амплитуде сигнала, полученных за относительно короткий промежуток времени. Во-вторых, существует подход, называемый дифференциальным кодированием или линейным предсказанием. Вместо того, чтобы кодировать входной сигнал непосредственно, кодируют разность между входным сигналом и «предсказанной» величиной, вычисленной на основе нескольких предыдущих значений сигнала. Если отсчеты входного сигнала обозначить как y(i), то предсказанное значение в момент времени i представляет собой линейную комбинацию нескольких р предыдущих отсчетов: y(i)=a,y(i-1)+a;,y(i-2)+...+apy(i-p) где множители а, называются коэффициентами предсказания. Разность e(i)=y(i)-y(i) имеет меньший динамический диапазон и может кодироваться меньшим числом битов, что позволяет снизить требования к полосе пропускания. Описанный метод называется линейным предсказанием, так как он использует только линейные функции предыдущих отсчетов. Коэффициенты предсказания выбираются так, чтобы минимизировать среднеквадратическое значение ошибки предсказания e(i), при этом значения коэффициентов изменяются, в среднем, каждые 10-25 мс. Простейшей (и представляющей сегодня, скорее, исторический интерес) реализацией последнего подхода является так называемая дельта-модуляция (ДМ), алгоритм которой предусматривает кодирование разности между соседними отсчетами сигнала только одним информационным битом, обеспечивая передачу, по сути, только знака разности. Наиболее совершенным алгоритмом, построенным на описанных выше принципах, является алгоритм адаптивной дифференциальной импульсно-кодовой модуляции (АДИКМ), предложенный ITU-T в рекомендации G.726. Алгоритм предусматривает формирование сигнала ошибки предсказания и его последующее адаптивное квантование. Существует версия этого алгоритма, в которой информационные биты выходного цифрового потока организованы по иерархической схеме, что позволяет отбрасывать наименее значимую информацию, не уведомляя об этом кодер, и получать поток меньшей скорости за счет некоторого ухудшения качества. Документ G.726 специфицирует кодирование при скоростях 40, 32, 24 и 16 Кбит/с, что соответствует передаче 5, 4, 3 или 2 битов на отсчет. Качество речи, передаваемой с использованием АДИКМ G.726 при скорости 32 Кбит/с соответствует качеству речи, обеспечиваемому алгоритмом кодирования G.711. При достаточно хороших характеристиках алгоритма, АДИКМ практически не применяется для передачи речи по сетям с коммутацией пакетов, так как этот алгоритм очень чувствителен к потерям целых блоков отсчетов, происходящим при потерях пакетов в сети. В таких случаях нарушается синхронизация кодера и декодера, что приводит к катастрофическому ухудшению качества воспроизведения речи даже при малой вероятности потерь. 3.2.2 Кодеры исходной информации (вокодеры) и гибридные алгоритмы Многие методы кодирования используют особенности человеческой речи, связанные со строением голосового аппарата. Кодеры, в которых реализуются такие методы, называют кодерами исходной информации или вокодерами (voice coding). Звуки речи образуются при прохождении выдыхаемого воздуха через голосовой аппарат человека, важнейшими элементами которого являются язык, нёбо, губы, зубы и голосовые связки. В формировании того или иного звука участвует та или иная часть этих элементов. Если звук формируется с участием голосовых связок, поток воздуха из легких вызывает их колебание, что порождает звуковой гон. Последовательность формируемых таким образом звуков составляет тоновую речь (или тоновый сегмент речи). Если звук формируется безучастия связок, тон в нем отсутствует, и последовательность таких звуков составляет нетоновую речь {нетоновый сегмент речи). Спектр тонового звука может быть смоделирован путем подачи специальным образом сформированного сигнала возбуждения на вход цифрового фильтра с параметрами, определяемыми несколькими действительными коэффициентами. Спектр нетоновых звуков - практически равномерный, что обусловлено их шумовым характером. В реальных речевых сигналах не все звуки можно четко разделить на тоновые и нетоновые, а приходится иметь дело с некими переходными вариантами, что затрудняет создание алгоритмов кодирования, обеспечивающих высокое качество передачи речи при низкой скорости передачи информации. Рис. 3.5 иллюстрирует описанную упрощенную модель функционирования голосового тракта человека. Работа кодера, согласно такой модели, состоит в том, чтобы, анализируя блок отсчетов речевого сигнала, вычислить параметры соответствующего фильтра и параметры возбуждения (тоновый/нетоновый сегмент речи, частота тона, громкость и т.д.). 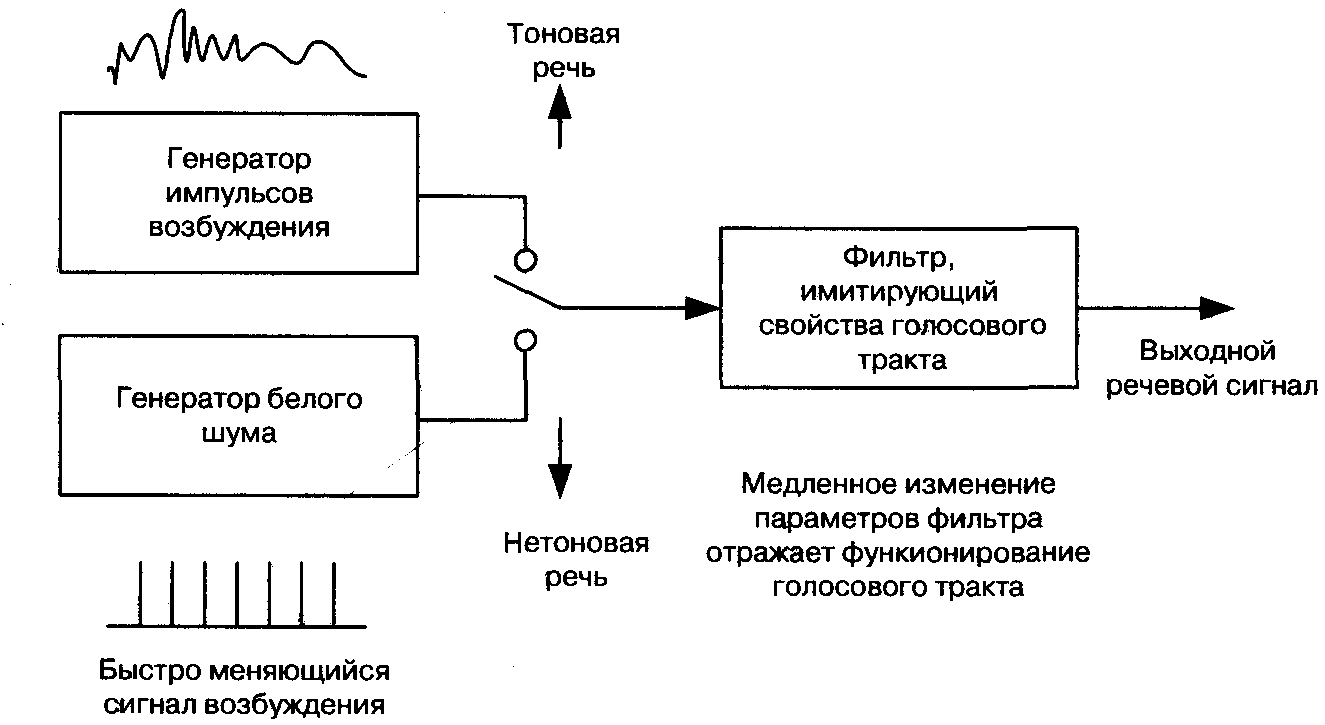 Рис. 3.5 Модель функционирования голосового тракта Описанный принцип кодирования получил название LPC (Linear Prediction Coding - кодирование с линейным предсказанием), поскольку центральным элементом модели голосового тракта является линейный фильтр. Наиболее известный стандартный алгоритм, построенный по описанному принципу, был стандартизован министерством обороны США под названием LPC-10, где число 10 соответствует количеству коэффициентов фильтра. Данный кодер обеспечивает очень низкую скорость передачи информации 2.4 Кбит/с, однако качество воспроизводимых речевых сигналов оставляет желать лучшего и не удовлетворяет требованиям коммерческой речевой связи - речь носит ярко выраженный «синтетический» характер. Как уже отмечалось, алгоритмы кодирования формы сигнала основаны на наличии корреляционных связей между отсчетами сигнала, которые дают возможность линейного предсказания. В сочетании с адаптивным квантованием этот подход позволяет обеспечить хорошее качество речи при скорости передачи битов порядка 24-32 Кбит/с. LPC-кодеры (вокодеры) используют простую математическую модель голосового тракта и позволяют использовать очень низкие скорости передачи информации 1200-2400 бит/с, однако ценой «синтетического» характера речи. Гибридные алгоритмы кодирования и алгоритмы типа «анализ путем синтеза» (ABS) представляют собой попытки совместить положительные свойства двух описанных выше основных подходов и строить эффективные схемы кодирования с диапазоном скоростей передачи битов 6-16Кбит/с. Важное отличие кодеров такого типа состоит в том, что в рамках этих алгоритмов нет необходимости принимать решение о типе воспроизводимого звука (тоновый или нетоновый), так как предусматриваются специальные меры для кодирования сигнала ошибки после прохождения возбуждения через LPC-фильтр. Например, сигнал ошибки может быть закодирован по алгоритму, аналогичному АДИКМ, что обеспечит высокую точность его передачи. ABS-кодеры не могут быть строго классифицированы как кодеры формы сигнала, однако реально целью процедуры минимизации ошибки (рис. 3.6), т.е. различия между входным и синтезированным сигналами, является синтез на выходе кодера сигналов, форма которых наиболее близка к форме входных. ABS-декодер является малой частью кодера и очень прост (рис. 3.7). 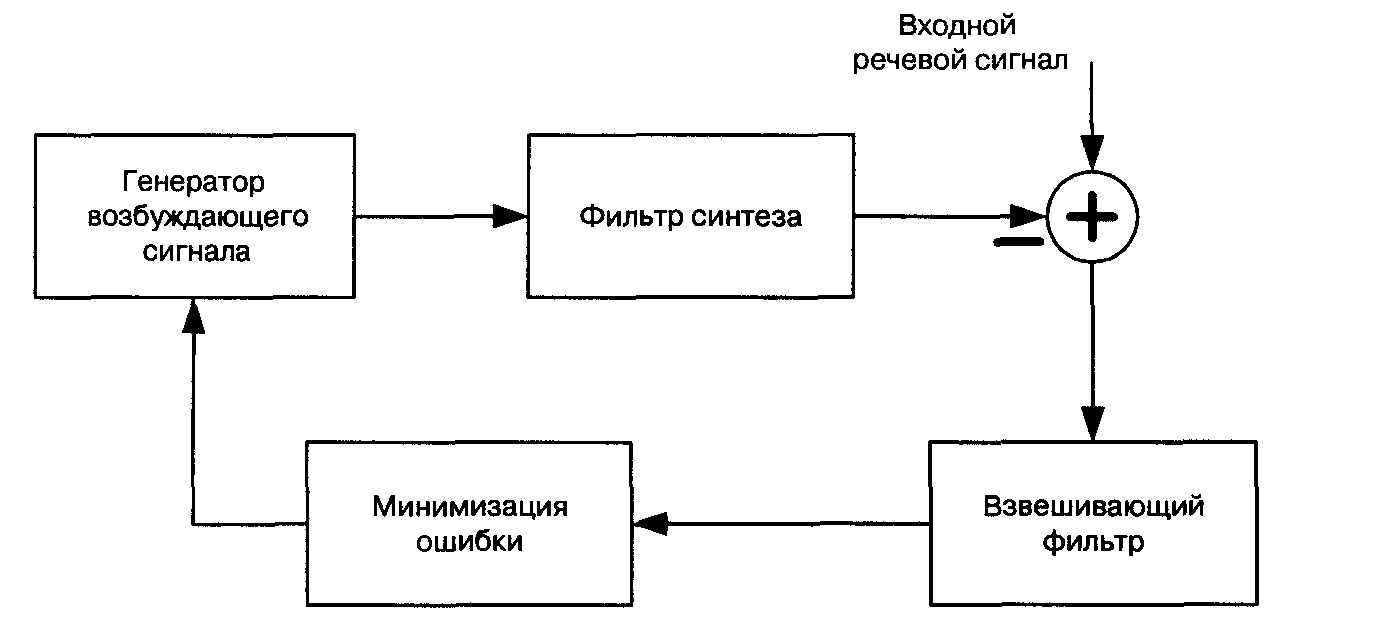 Рис. 3.6 Упрощенная блок-схема ABS-кодера  Рис. 3.7 Упрощенная блок - схема ABS - декодера 3.2.3 Процессоры цифровой обработки сигналов для речевых кодеков Узкополосному кодированию речевых сигналов дорогу на рынок коммерческих приложений открыло развитие микроэлектроники и, в частности, появление дешевых процессоров цифровой обработки сигналов (DSP - Digital Signal Processor) в интегральном исполнении. До этого цифровая обработка сигналов (в том числе, узкополосное кодирование речи) была уделом разработчиков аппаратуры для нужд армии и спецслужб. Процессоры DSP имеют архитектуру, оптимизированную для выполнения операций, которые характерны для типичных алгоритмов обработки сигналов. В качестве примеров таких операций можно назвать умножение с накоплением, а также выборку операндов с бит-инверсной адресацией, необходимую для выполнения быстрого преобразования Фурье. Архитектура процессоров DSP часто характеризуется наличием нескольких вычислительных блоков, обеспечивающих выполнение одновременных операций в одном такте работы процессора. Для загрузки вычислительных блоков данными предусматривается несколько шин передачи данных и многопортовая память данных. Для увеличения производительности память инструкций и память данных разделены, а доступ к ним осуществляется также по раздельным шинам. Для процессоров DSP характерно использование инструкций увеличенной длины, содержащих поля для управления всеми вычислительными блоками. Физически процессоры DSP выполняются в виде интегральных микросхем, содержащих в одном кристалле ядро процессора, память и периферийные устройства для обмена информацией. Наличие встроенной памяти обеспечивает быстрый доступ ядра к ее содержимому для получения максимальной производительности. Существует множество модификацией процессоров DSP, различающихся производительностью, объемом памяти, потребляемой мощностью. В оборудовании IP-телефонии используются дешевые процессоры со средней производительностью и малой потребляемой мощностью, ориентированные на реализацию малого числа (единицы) каналов обработки речевой информации и применяемые, в основном, в составе терминальных устройств, или мощные высокопроизводительные процессоры, ориентированные на многоканальные (десятки каналов) приложения и используемые в составе таких групповых устройств как многоканальные шлюзы IP-телефонии, подключаемые к ТфОП по цифровым трактам Е1. Одними из самых известных производителей DSP являются фирмы Texas Instruments (www.ti.com). Analog Devices (www.analog.com). Motorola (www.motorola.com). на сайтах которых можно получить дополнительную информацию о номенклатуре DSP и об их применении. Оборудование ПРОТЕЙ-1Р использует DSP с лицензированным у одной из ведущих в дан ной области фирм программным обеспечением, реализующим необходимые алгоритмы (речевые кодеки, факс, модем). Это позволило, опираясь на существующий опыт, резко сократить время выхода оборудования на рынок. Кроме того, в данном случае исключается трудоемкая и длительная процедура лицензирования алгоритмов речевых кодеков (G.723.1, G.729), требующая значительных единовременных финансовых затрат. По такому же пути идут и ведущие мировые производители оборудования VolP (Cisco, Dialogic и др.), лицензируя программное обеспечение DSP у компаний, специализирующихся именно в этой области, и концентрируя свои силы на реализации тех функций, которые традиционно обеспечивают данным производителям оборудования технологическое лидерство. 3.2.4 Основные алгоритмы кодирования речи, используемые в IP-телефонии В первую очередь необходимо понять, какими критериями нужно руководствоваться при выборе «хорошего» кодекадля использования в IP-телефонии. Использование полосы пропускания канала Скорость передачи, которую предусматривают имеющиеся сегодня узкополосные кодеки, лежит в пределах 1.2 - 64 Кбит/с. Естественно, что от этого параметра прямо зависит качество воспроизводимой речи. Существует множество подходов к проблеме определения качества. Наиболее широко используемый подход оперирует оценкой MOS (Mean Opinion Score), которая определяется для конкретного кодека как средняя оценка качества большой группой слушателей по пятибалльной шкале. Для прослушивания экспертам предъявляются разные звуковые фрагменты - речь, музыка, речь на фоне различного шума и т.д. Оценки интерпретируют следующим образом: • 4-5 - высокое качество; аналогично качеству передачи речи в ISDN, или еще выше; • 3.5-4- качество ТфОП (toll quality); аналогично качеству речи, передаваемой с помощью кодека АДИКМ при скорости 32 Кбит/с. Такое качество обычно обеспечивается в большинстве телефонных разговоров. Мобильные сети обеспечивают качество чуть ниже toll quality; • 3-3.5- качество речи, по-прежнему, удовлетворительно, однако его ухудшение явно заметно на слух; • 2.5-3 - речь разборчива, однако требует концентрации внимания для понимания. Такое качество обычно обеспечивается в системах связи специального применения (например, в вооруженных силах). В рамках существующих технологий качество ТфОП (toll quality) невозможно обеспечить при скоростях менее 5 Кбит/с. Подавление периодов молчания (VAD, CNG, DTX) При диалоге один его участник говорит, в среднем, только 35 процентов времени. Таким образом, если применить алгоритмы, которые позволяют уменьшить объем информации, передаваемой в периоды молчания, то можно значительно сузить необходимую полосу пропускания. В двустороннем разговоре такие меры позволяют достичь сокращения объема передаваемой информации до 50%, а в децентрализованных многоадресных конференциях (за счет большего количества говорящих) - и более. Нет никакого смысла организовывать многоадресные конференции с числом участников больше 5-6, не подавляя периоды молчания. Технология подавления таких периодов имеет три важные составляющие. Нужно отметить, что определение границ пауз в речи очень существенно для эффективной синхронизации передающей и приемной сторон: приемник может, незначительно изменяя длительности пауз, производить подстройку скорости воспроизведения для каждого отдельного сеанса связи, что исключает необходимость синхронизации тактовых генераторов всех элементов сети, как это имеет место в ТфОП. Детектор речевой активности (Voice Activity Detector - VAD) необходим для определения периодов времени, когда пользователь говорит. Детектор VAD должен обладать малым временем реакции, чтобы не допускать потерь начальных слов и не упускать бесполезные фрагменты молчания в конце предложений; в то же время детектор VAD не должен срабатывать от воздействия фонового шума. Детектор VAD оценивает энергию входного сигнала и, если она превышает некоторый порог, активизирует передачу. Если бы детектор отбрасывал всю информацию до момента, пока энергия сигнала не стала выше порога, то происходило бы отрезание начальной части периода активности. Поэтому реализации VAD требуют сохранения в памяти нескольких миллисекунд информации, чтобы иметь возможность запустить передачу до начала периода активности. Это увеличивает, в некоторой степени, задержку прохождения сигнала, однако ее можно минимизировать или свести к нулю в кодерах, работающих с блоками отсчетов. Поддержка прерывистой передачи (Discontinuous Transmission -DTX) позволяет кодеку прекратить передачу пакетов в тот момент, когда VAD обнаружил период молчания. Некоторые наиболее совершенные кодеры не прекращают передачу полностью, а переходят в режим передачи гораздо меньшего объема информации (интенсивность, спектральные характеристики), нужной для того, чтобы декодер на удаленном конце мог восстановить фоновый шум. Генератор комфортного шума (Comfort Noise Generator - CNG) служит для генерации фонового шума. В момент, когда в речи активного участника беседы начинается период молчания, терминалы слушающих могут просто отключить воспроизведение звука. Однако это было бы неразумно. Если в трубке возникает «гробовая тишина», т.е. фоновый шум (шум улицы и т.д.), который был слышен во время разговора, внезапно исчезает, то слушающему кажется, что соединение по каким-то причинам нарушилось, и он обычно начинает спрашивать, слышит ли его собеседник. Генератор CNG позволяет избежать таких неприятных эффектов. Простейшие кодеки просто прекращают передачу в период молчания, и декодер генерирует какой-либо шум с уровнем, равным минимальному уровню, отмеченному в период речевой активности. Более совершенные кодеки (G.723.1 Annex A, G. 729 Annex В) имеют возможность предоставлять удаленному декодеру информацию для восстановления шума с параметрами, близкими к фактически наблюдавшимся. Размер кадра Большинство узкополосных кодеков обрабатывает речевую информацию блоками, называемыми кадрами (frames), и им необходимо производить предварительный анализ отсчетов, следующих непосредственно за отсчетами в блоке, который они в данный момент кодируют. Размер кадра важен, так как минимальная теоретически достижимая задержка передачи информации (алгоритмическая задержка) определяется суммой этого параметра и длины буфера предварительного анализа. В действительности процессоры цифровой обработки сигналов, которые выполняют алгоритм кодирования, имеют конечную производительность, так что реальная задержка сигнала больше теоретической. Можно, казалось бы, заключить, что кодеки с меньшим размером кадра лучше в смысле такого важного критерия как минимизация задержки. Если, однако, учесть, что происходит при передаче информации по сети, то мы увидим, что к кадру, сформированному кодеком, добавляется множество дополнительной информации - заголовки IP (20 байтов), UDP (8 байтов), RTP (12 байтов). Для кодека с длительностью кадра 30 мс посылка таких кадров по сети привела бы к передаче избыточной информации со скоростью 10.6 кбит/с, что превышает скорость передачи речевой информации у большинства узкополосных кодеков. Поэтому обычно используется пересылка нескольких кадров в пакете, при этом их количество ограничено максимально допустимой задержкой. В большинстве случаев в одном пакете передается до 60 мс речевой информации. Чем меньше длительность кадра, тем больше кадров приходится упаковывать в один пакет, т.е. задержка определяется вовсе не длиной кадра, а практически приемлемым объемом полезной нагрузки в пакете. Кроме того, кодеки с большей длиной кадра более эффективны, так как здесь действует общий принцип: чем дольше наблюдается явление (речевой сигнал), тем лучше оно может быть смоделировано. Чувствительность к потерям кадров Потери пакетов являются неотъемлемым атрибутом IP-сетей. Так как пакеты содержат кадры, сформированные кодеком, то это вызывает потери кадров. Но потери пакетов и потери кадров не обязательно напрямую связаны между собой, так как существуют подходы (такие как применение кодов с исправлением ошибок -forward error correction), позволяющие уменьшить число потерянных кадров при данном числе потерянных пакетов. Требующаяся для этого дополнительная служебная информация распределяется между несколькими пакетами, так что при потере некоторого числа пакетов кадры могут быть восстановлены. Однако положительный эффект от введения избыточности для борьбы с потерями пакетов не столь легко достижим, поскольку потери в IP-сетях происходят пачками, т.е. значительно более вероятно то, что будет потеряно сразу несколько пакетов подряд, чем то, что потерянные пакеты распределятся в последовательности переданных пакетов по одному. Так что если применять простые схемы введения избыточности (например, повторяя каждый кадр в двух последовательно передаваемых пакетах), то в реальных условиях они, хотя и увеличат объем избыточной информации, но, скорее всего, окажутся бесполезными. Кроме того, введение избыточности отрицательно сказывается на задержке воспроизведения сигнала. Например, если мы повторяем один и тот же кадр в четырех пакетах подряд, чтобы обеспечить возможность восстановления информации при потере трех подряд переданных пакетов, то декодер вынужден поддерживать буфер из четырех пакетов, что вносит значительную дополнительную задержку воспроизведения. Влияние потерь кадров на качество воспроизводимой речи зависит от используемого кодека. Если потерян кадр, состоящий из N речевых отсчетов кодека G.711, то на приемном конце будет отмечен пропуск звукового фрагмента длительностью М*125 мкс. Если используется более совершенный узкополосный кодек, то потеря одного кадра может сказаться на воспроизведении нескольких следующих, так как декодеру потребуется время для того, чтобы достичь синхронизации с кодером - потеря кадра длительностью 20 мс может приводить к слышимому эффекту в течение 150 мс и более. Кодеры типа G.723.1 разработаны так, что они функционируют без существенного ухудшения качества в условиях некоррелированных потерь до 3% кадров, однако при превышении этого порога качество ухудшается катастрофически. |