работа. Лабораторная работа 1 (1). Построение моделей идентификации
 Скачать 0.82 Mb. Скачать 0.82 Mb.
|

|
Лабораторная работа 1 Тема: «Построение моделей идентификации» 1.1. Задание: Методами регрессионного анализа построить модель идентификации второго порядка Провести статистический анализ модели. Проверить целесообразность включения в модель члена третьего порядка, т.е. перехода к модели Для получения выборки «экспериментальных» данных необходимо осуществить математический эксперимент с уравнением в котором величина x измеряется точно, а Математический эксперимент проводится по следующей схеме: с помощью датчика равномерно распределенных на отрезке [0, 1] случайных чисел определяется случайное число величина x определяется нормированием случайного числа на интервал [0, d] c помощью датчика нормально распределенных [0, 1] случайных чисел определяется случайное число «экспериментальная» величина Результатом математического эксперимента является выборка 10 случайных пар Таблица 1.1 Исходные данные для проведения математического эксперимента
1.2. Теоретические сведения 1.2.1. Выбор формы идентификации и регрессионный анализ Математически задача идентификации формулируется следующим образом. Имеется n пар экспериментальных точек которая описывает характеристики изучаемой системы. Уравнение (1.2) называется уравнением регрессии. Построение модели идентификации начинается с выбора формы модели, т.е. вида зависимости (1.2). При этом на практике могут встретится два случая. Форма математической модели известна заранее. В этом случае задача идентификации сводится к определению коэффициентов этой модели. Форма математической модели заранее неизвестна. В этом случае целесообразно использовать для построения модели общее разложение функции в ряд Тейлора. В данной лабораторной работе при идентификации ставится задача нахождение приближенной модели в виде полинома степени p Согласно методу наименьших квадратов, искомый вектор где 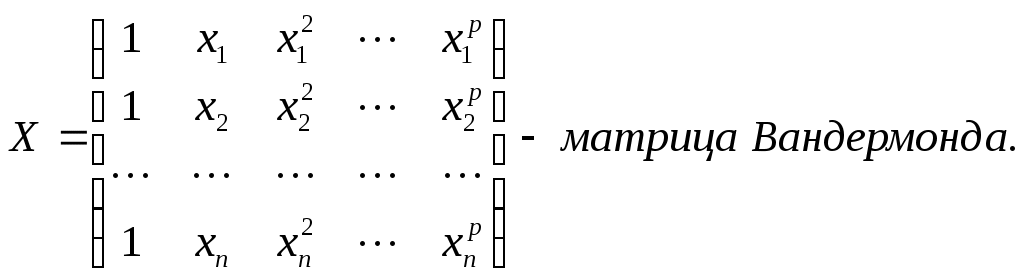 Таким образом, для определения коэффициентов уравнения регрессии необходимо произвести следующие операции: составить матрицу независимых переменных Вандермонда найти транспонированную матрицу переменных найти обратную матрицу 1.2.2. Статистический анализ модели После вычисления коэффициентов регрессии необходимо провести статистический анализ полученной модели. Для этого необходимо вычислить следующие характеристики регрессионной зависимости: величину остаточной суммы квадратов отклонений фактических значений средние квадраты остаточных сумм критерий Фишера здесь F – отношение характеризуется двумя последовательно записанными значениями степеней свободы числителя и знаменателя. При этом, так как точность статистических оценок возрастает с ростом числа степеней свободы, то число степеней свободы точной величины Полученную величину F – отношения оценку связи коэффициентов регрессии между собой Эта оценка проводится по ковариационной матрице 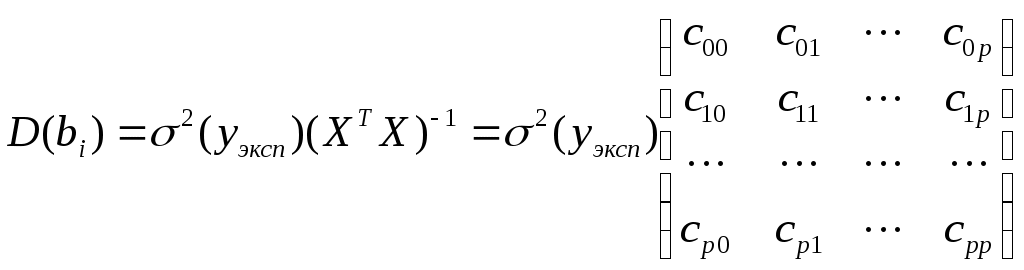 . .Диагональные элементы матрицы определяют дисперсии коэффициентов регрессии, а недиагональные – взаимосвязь этих коэффициентов. Коэффициент корреляции может изменяться в пределах Для сравнения моделей необходимо: рассчитать дополнительную сумму квадратов где определить число степеней свободы дополнительной суммы квадратов посчитать средний квадрат дополнительной суммы определить роль дополнительной информации с помощью критерия Фишера Если полученное значение критерия Фишера значимо 1.3. Пример построения модели идентификации Для получения выборки «экспериментальных» данных осуществим математический эксперимент с уравнением по следующей схеме: с помощью датчика равномерно распределенных на отрезке [0, 1] случайных чисел определяется случайное число величина x определяется нормированием случайного числа на интервал [0, 6] c помощью датчика нормально распределенных [0, 1] случайных чисел определяется случайное число «наблюдаемая» величина Результаты математического эксперимента (выборка 10 случайных пар Построим модель идентификации Найдем составляющие уравнения (1.4)  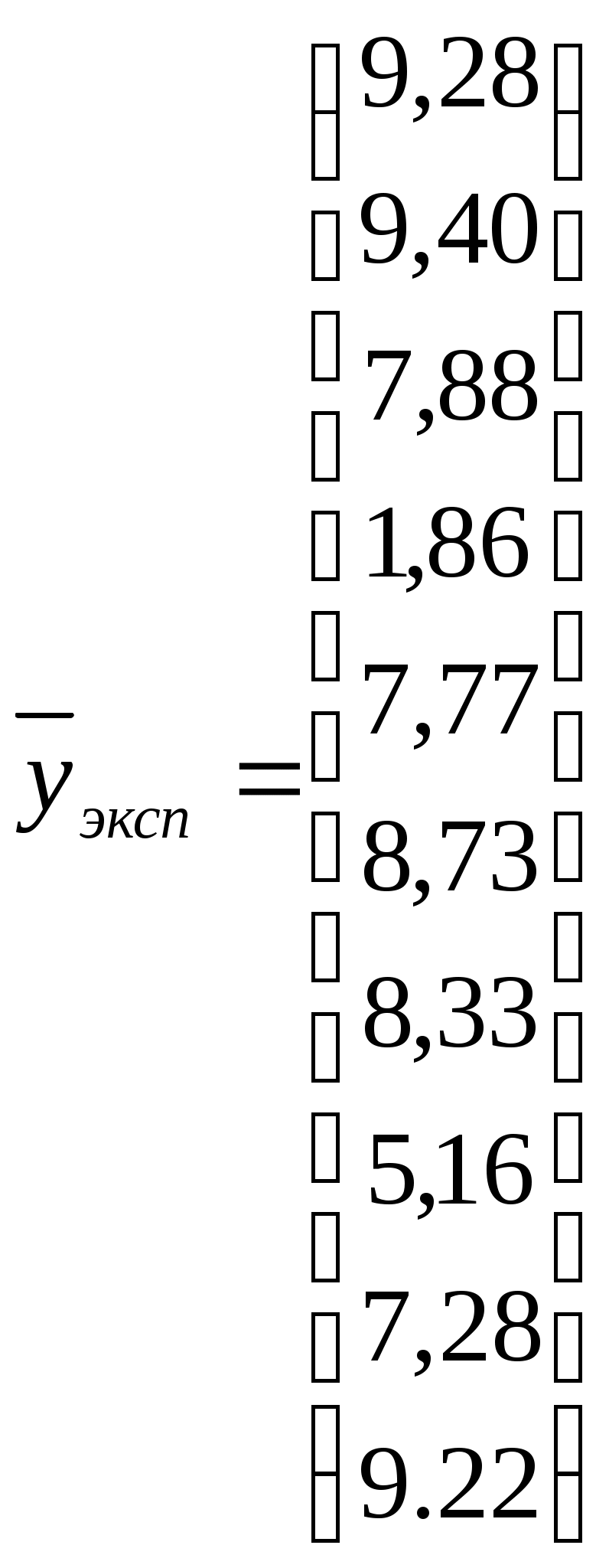 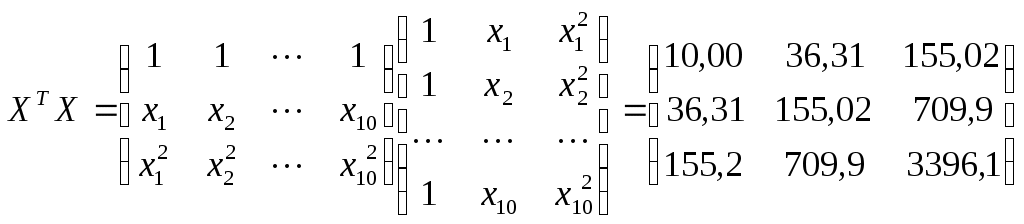 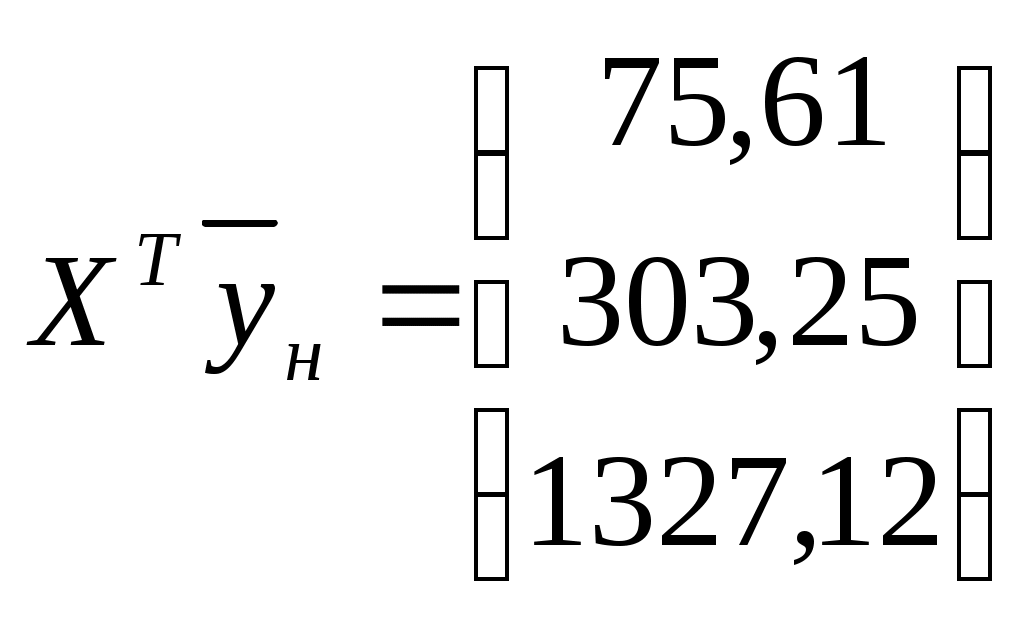 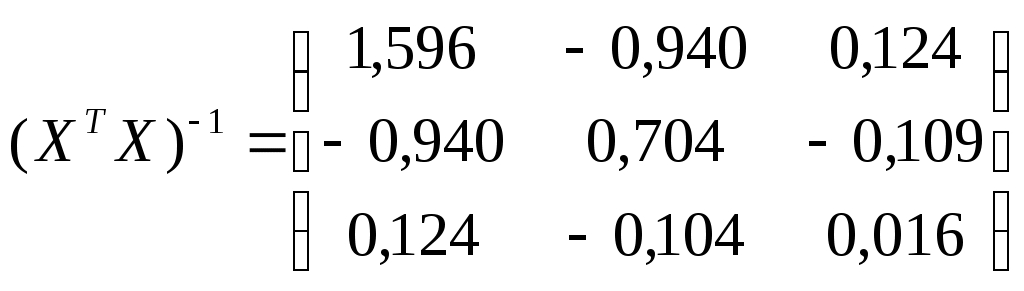 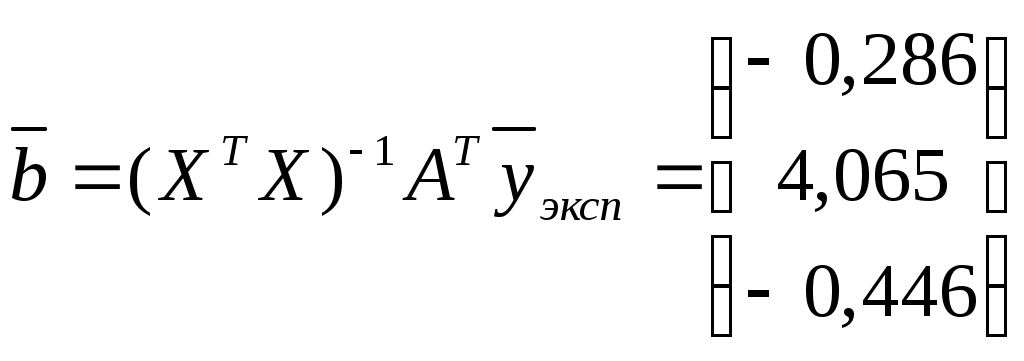 Таким образом, получена зависимость на рис.1.1- ряд 2. Из рисунка видно, что полученная модель качественно правильно воспроизводит исходное описание. Статистические характеристики модели имеют следующие значения: остаточная сумма квадратов число степеней свободы остаточной суммы квадратов средние квадраты остаточных сумм критерий Фишера 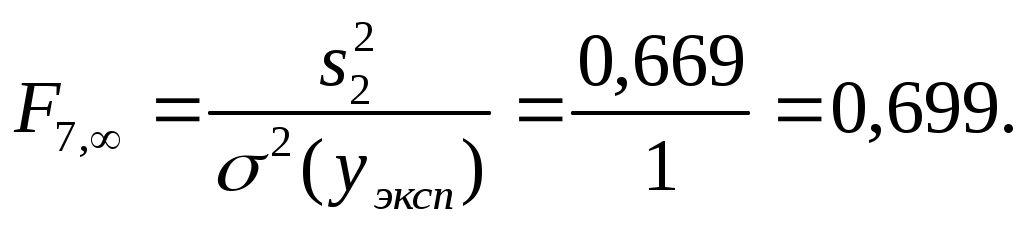 По таблицам распределения критерия Фишера Определим связи коэффициентов регрессии между собой 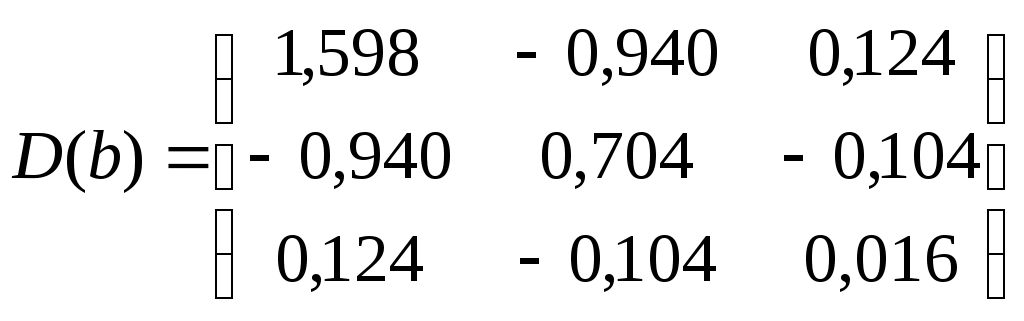 ; ;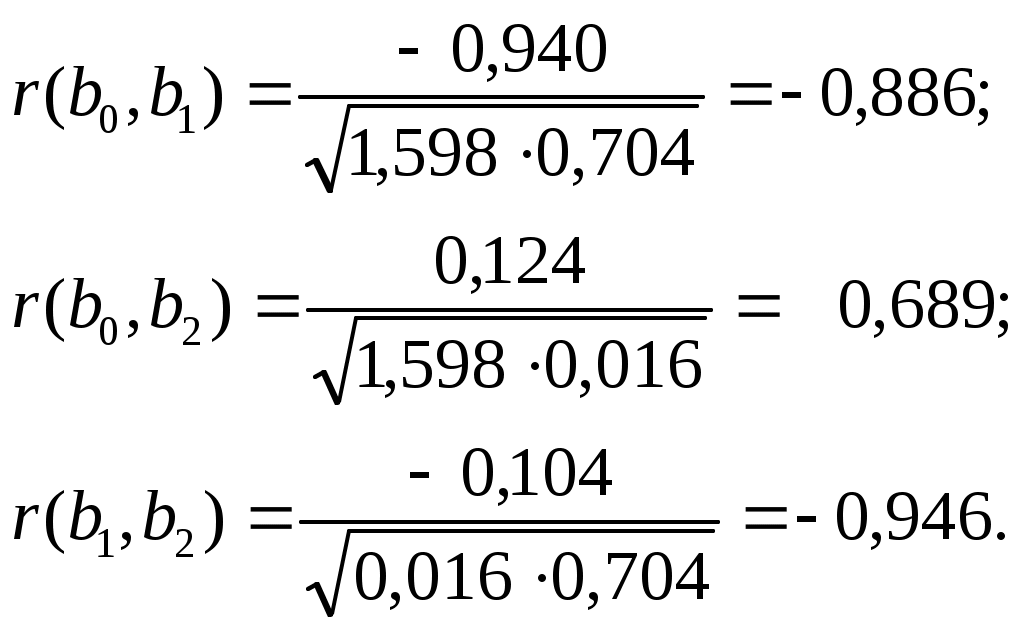 Таким образом, коэффициенты регрессии достаточно сильно связаны между собой. Поскольку форма модели заранее неизвестна, целесообразно рассмотреть возможность использования кубической модели В результате расчетов найдены коэффициенты такой модели на рис.1.1 – ряд 1. 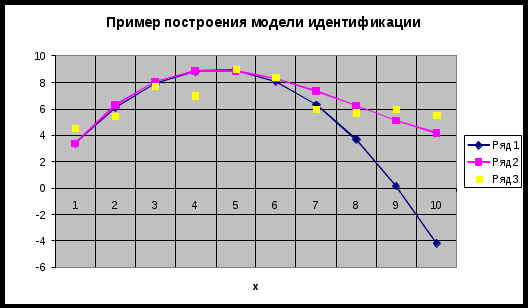 Для проверки целесообразности включения в модель члена третьей степени вычисляется остаточная сумма квадратов для уравнения (1.5), дополнительная сумма квадратов, средний квадрат и величина Фишера: 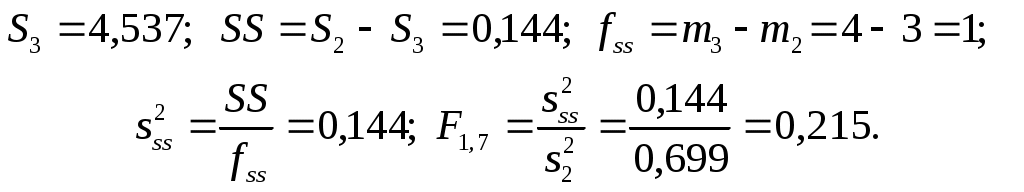 По таблицам распределения (прил. 1) определяем критическое значение Фишера Лабораторная работа № 2 |