Курсач2. Пояснительная записка к курсовому проекту по дисциплине Теория экономических информационных систем
 Скачать 0.57 Mb. Скачать 0.57 Mb.
|

2МЕТОДЫ ОРГАНИЗАЦИИ ДАННЫХМетоды хранения данных в памяти ЭВМ обычно предполагают разделенное хранение значений каждой составной единицы информации. Отдельное значение СЕИ, находящееся в памяти ЭВМ, называются записью. Запись состоит из значений атрибутов, входящих в структуру СЕИ. Множество записей образует массив или файл. Как правило, файл содержит записи, принадлежащие одной и той же СЕИ, хотя в общем случае это не является обязательным. Под организацией значений данных понимают относительно устойчивы порядок расположения записей данных в памяти ЭВМ и способ обеспечения взаимосвязи между записями. Организация значений данных может быть линейной и нелинейной. При линейной организации данных каждая запись, кроме первой и последней, связана с одной из предыдущих и одной из последующих записями. У записей, соответствующих нелинейной организации данных, количество предыдущих и последующих записей может быть произвольным.
Списковая (цепная) организация данных позволяет связать физически разнесенные в памяти компьютера данные в логическую последовательность (цепочку). Списковая организация – это линейная организация данных, в которой логическая последовательность записей обеспечивается с помощью специальных указателей (адресов связи). Для списковой организации используются понятия-синонимы "строка" и "цепь". Адресом связи некоторой записи называется атрибут в составе записи, в котором хранится начальный адрес или номер записи, обрабатываемой после данной. Обычная последовательность обработки записей в списке определяется возрастанием значений ключей в записях. В записи списка выделяются собственная информация (содержательные сведения) и ассоциативная информация, т. е. адрес связи. Описание записей на языке программирования может быть произведено двумя способами:
Второй вариант является более практичным, особенно если требуется хранить список на внешнем запоминающем устройстве. Возможны два способа организации списка – совместное размещение собственной и ассоциативной информации, когда запись и её адрес связи образуют одно целое, и раздельное, когда имеется списковая организация адресов связи и последовательное хранение собственной информации. При совместном размещении запись и ее адрес связи располагаются в памяти вплотную.При раздельном же ассоциативная информация, относящаяся к каждой записи, образует звено связи. На графических иллюстрациях прямоугольником со стрелкой изображается адрес связи. Стрелка указывает на элемент данных, адрес хранения которого содержится в адресе связи. Раздельное размещение собственной и ассоциативной информации оправдано, если имеется возможность разделить звенья связи в различных участках памяти, отличающихся по быстродействию и скорости обмена. Адрес связи, отмечающий первую обрабатываемую запись, называется указателем списка (УС). Список начинается с УС. Основные возможности списковой организации данных обеспечивает однонаправленный список, в котором реализуется взаимосвязь между записями типа "следующий". Каждая запись имеет адрес связи, содержащий адрес расположения следующей записи. Если следующая запись отсутствует, то вместо адреса связи в указатель помещается специальный знак, который называется признаком конца списка. На графических иллюстрациях адрес связи, соответствующий концу списка, перечеркивается. Задание 4: Построить однонаправленный линейный список для следующих значений атрибутов: любые 10 чисел [1..100]. Произвести корректировку (запись и удаление). Сформируем список из записей с такими значениями атрибутов: 13, 73, 18, 9, 84, 19, 66, 62, 41, 71 (рисунок 3.1). Произведем корректировку со следующими значениями:
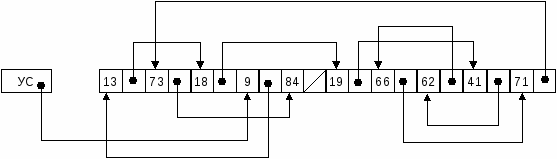 Рис. 3.1 – Формирование упорядоченного списка из неупорядоченных записей 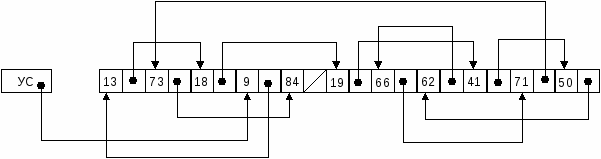 Рис. 3.2 – Корректировка списка с учетом поступления новой записи с ключом 50 При поступлении новой записи находится ее место в списке и производится перезапись адресов связи с целью включения ее в цепочку. 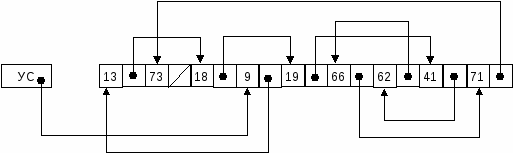 Рис. 3.3 – Корректировка списка с учетом удаления записи с ключом 84 При формировании упорядоченного списка записей возможны два варианта:
Для сортировки можно использовать:
Для поиска данных в однонаправленном списке используют единственный метод – последовательный поиск. Ключевой атрибут первой записи (ее адрес извлекается из УС) сравнивается с искомым значением, затем такое же сравнение выполняется для ключа второй записи, которая извлекается по адресу связи первой и т. д. Неэффективность бинарного поиска для списковой организации объясняется тем, что для достижения искомого значения ключа требуется последовательное движение по списку в соответствии с адресами связи, и суммарное количество переходов от записи к записи достаточно велико.
Цепным каталогом называется сплошной участок памяти (или несколько таких участков), в котором одновременно размещаются список обрабатываемых записей и список свободных позиций памяти. Адрес связи, отмечающий первую свободную позицию памяти, называется указателем свободной памяти (УСП). Адрес связи последней записи (или последней свободной позиции) в списке называется концом списка и отмечается нулевым значением. Задание 5: Построить цепной каталог для следующих значений атрибутов: любые 10 чисел [1..100]. Определить УС и УСП. Произвести корректировку (запись и удаление). Возьмем значения атрибутов 25, 74, 15, 10, 81, 38, 30, 56, 92, 5, и разместим их в цепном каталоге (таблица 3.1). Добавим запись с ключом 29 (таблица 3.2) и удалим запись с ключом 92 (таблицы 3.3 и 3.4). Включение и исключение записей в цепном каталоге предполагает поиск местоположения включаемой (исключаемой) записи и замену значений адресов связи для установки новой последовательности записей основного списка свободной памяти. Таблица 3.1 – Формирование цепного каталога
УС = 13 УСП = 2 Алгоритм вставки записи с ключом А в цепной каталог следующий:
Таблица 3.2 – Операция вставки записи с ключом 29 в цепной каталог
УС = 13 УСП = 4 Один из алгоритмов удаления записи с ключом А из цепного каталога следующий:
Таблица 3.3 – Операция удаления записи с ключом 92 из цепного каталога (в начало)
УС = 13 УСП = 12 Существует и другой алгоритм удаления:
Время корректировки складывается из времени реализации поиска и времени на замену значений адресов связи. В последнем случае число пересылок адресов связи всегда одинаково и не зависит от числа записей в цепном каталоге, поэтому затраты времени на поиск при корректировке являются доминирующими и время корректировки пропорционально числу записей.
При нелинейной организации данных каждая из множества записей связана с произвольным количеством предшествующих и последующих. Наиболее используемыми вариантами нелинейной организации данных являются деревья и нелинейные списки. Таблица 3.4 – Операция удаления записи с ключом 92 из цепного каталога (в конец)
УС = 13 УСП = 2
Древовидной организацией данных (деревом) называется множество записей, расположенных по уровням следующим образом:
Количество уровней называется рангом дерева. Записи дерева, которые образуются от общей записи (i – 1)-го уровня, образуют группу. Максимальное число элементов в группе называется порядком дерева. Деревья обычно формируются двунаправленными, адрес связи от записи уровня (i + 1) к записи i-го уровня называется обратным. Рассмотрим бинарные деревья. Эти деревья имеют порядок 2, и составляющие их записи могут быть упорядоченными. Для этого один из атрибутов записи должен быть ключевым. Введем ряд понятий. Записи, у которых заполнены два адреса, называются полными. Записи с одним адресом называются неполными. Записи с двумя незаполненными адресами называются концевыми. Адреса делятся на правые и левые. Правую (левую) ветвь записи образует поддерево, адресованное из этой записи через правый (левый) адрес связи. В упорядоченном бинарном дереве каждый элемент на своей левой ветви имеет элементы с меньшими, чем у него значениями ключей, а на правой ветви – элементы с большими значениями. Это определение позволяет также различать левые и правые адреса (ветви). Упорядоченное бинарное дерево формируется из неупорядоченного массива записей по следующему алгоритму:
При формировании упорядоченного бинарного дерева производится сравнение правых признаков: где М – число записей исходного массива, для которых строится дерево. |