Проектирование иас фирмыпровайдера
 Скачать 158.89 Kb. Скачать 158.89 Kb.
|

Инфологическая модель представления данных фирмы-провайдера.Инфологическое проектирование, прежде всего, связано с попыткой представления семантики предметной области в модели БД. Реляционная модель данных в силу своей простоты и лаконичности не позволяет отобразить семантику, то есть смысл предметной области. Ранние теоретико-графовые модели в большей степени отображали семантику предметной области. Они в явном виде определяли иерархические связи между объектами предметной области. ERwin - лидер среди средств моделирования баз данных и хранилищ данных. Позволяет проектировать, документировать и сопровождать базы данных различных типов. Поддерживая прямое и обратное проектирование для 20 типов СУБД, ERwin повышает качество разрабатываемой БД, производительность труда и скорость разработки. В основе ER-модели лежат следующие базовые понятия: Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей. В данном примере атрибутами являются «персональные данные», «многоуровневая БД», «административный интерфейс для ручного управления» и т.д. Между сущностями могут быть установлены связи – бинарные ассоциации, показывающие каким образом сущности соотносятся или взаимодействуют между собой. Кроме того, в ER-модели допускается принцип категоризации сущностей. Это значит, что, как и в объектно-ориентированных языках программирования, вводится понятие подтипа сущности, то есть сущность может быть представлена в виде двух или более своих подтипов — сущностей, каждая из которых может иметь общие атрибуты и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются как взаимоисключающие, и при разделении сущности на подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Если на уровне анализа не удается выявить полный перечень подтипов, то вводится специальный подтип, называемый условно ПРОЧИЕ, который в дальнейшем может быть уточнен: В реальных системах бывает достаточно ввести подтипизацию на двух-трех уровнях. Логическая структура хранилища данных представлена на рис. 9. 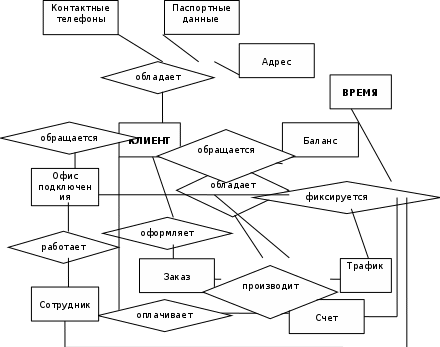 Рис. 9 Инфологическая модель представления данных фирмы-провайдера. Ключевые показатели эффективности предметной области.Суть метода управления при помощи KPI (от англ. Key Performance Indicator) заключается в построении «дерева целей» (иначе – «нормативов»), тесно увязанных с бизнес-задачами компании (или отдельного подразделения, или даже отдельного сотрудника) и отслеживание выполнения каждого норматива. Метод позволяет держать под контролем ключевые параметры в заданном коридоре, выстраивать эффективную систему мотивации сотрудников, своевременно находить критические точки и узкие места в работе подразделений или организации в целом. Для каждой компании набор KPI может быть совершенно разным, как разными будут и глобальные цели и задачи предприятий. В данной компании будет использован следующий набор ключевых показателей: Финансы и Экономика: - затраты на содержание оборудования; - рыночная стоимость компании; - оборот; - общая сумма активов; - затраты на аренду сетей; - доходы от предоставления в аренду сетей; Рынок и Клиенты: - количество новых клиентов; - доход от новых клиентов; - количество потерянных клиентов; - расходы на маркетинг; Сотрудники: - количество сотрудников; - доходы и расходы на одного сотрудника; - расходы на обучение персонала; - уровень автоматизации; - текучесть кадров; - число прошедших обучение в отчетный период; - общие затраты на текучесть; Бизнес-процессы: - время обработки заявки; - операционные издержки; - время внедрения новых технологий; - время реагирования на претензии; - рост производительности труда; - сроки проведения технических работ. Обоснование выбора структуры данныхУспешная компания сегодня должна принимать множество различных решений. И чем более обоснованные решения будут приняты, тем большего успеха и прибыли достигнет предприятие. Для многих лиц, играющих ключевую роль в принятии решений, способность быстрее и эффективнее конкурента анализировать бизнес-процессы означает принятие более правильных решений, достижение большей прибыльности и большего успеха. Оптимизация реляционной базы данных предоставила компаниям возможность продуктивно собирать данные о транзакциях, поставляя информации лицам, принимающим решения. Тем не менее, имеется верхний предел объема данных, который может содержаться в реляционной базе данных, при котором еще сохраняется возможность достаточно эффективно осуществлять анализ. OLAP позволяет выполнять быстрый и эффективный анализ над большими объемами данных. Данные хранятся в многомерном виде, что наиболее близко отражает естественное состояние реальных бизнес-данных. Кроме того, OLAP предоставляет пользователям возможность быстрее и проще получать сводные данные. С его помощью они могут при необходимости углубляться (drill down) в содержимое этих данных для получения более детализированной информации. Прикладной частью OLAP-системы является OLAP-сервер. Эта составляющая выполняет всю работу (в зависимости от модели системы), и хранит в себе всю информацию, к которой обеспечивается активный доступ. Архитектурой сервера управляют различные концепции. В частности, основной функциональной характеристикой OLAP-продукта является использование для хранения данных многомерной (ММБД, MDDB) либо реляционной (РДБ, RDB) базы данных. MOLAP - это Multidimensional On-Line Analytical Processing, то есть Многомерный OLAP. Это означает, что сервер для хранения данных использует ММБД. Поскольку большинство OLAP-продуктов основаны на МДБД, под OLAP часто понимают также и MOLAP. Смысл использования ММБД очевиден. Она может эффективно хранить многомерные по своей природе данные, обеспечивая средства быстрого обслуживания запросов к базе данных. Данные передаются от источника данных (как это описано выше) в многомерную базу данных, а затем база данных подвергается агрегации. Предварительный расчет - это то, что ускоряет OLAP-запросы, поскольку расчет сводных данных уже произведен. Время запроса становится функцией исключительно времени, необходимого для доступа к отдельному фрагменту данных и выполнения расчета. Этот метод поддерживает концепцию, согласно которой работа производится единожды, а результаты затем используются снова и снова. Многомерные базы данных являются относительно новой технологией. Использование ММБД имеет те же недостатки, что и большинство новых технологий. А именно - они не так устойчивы, как РБД, и в той же мере не оптимизированы. Другое слабое место ММБД заключается в невозможности использовать большинство многомерных баз в процессе агрегации данных, поэтому требуется время для того, чтобы новая информация стала доступна для анализа. ROLAP - это Relational On-Line Analytical Processing, то есть Реляционный OLAP. Термин ROLAP обозначает, что OLAP-сервер базируется на реляционной базе данных. Исходные данные вводятся в реляционную базу данных, обычно по схеме "звезда" или схеме "снежинка", что способствует сокращению времени извлечения. Сервер обеспечивает многомерную модель данных с помощью оптимизированных SQL-запросов. Существует ряд причин для выбора именно реляционной, а не многомерной базы данных. РБД - это хорошо отработанная технология, имеющая множество возможностей для оптимизации. Использование в реальных условиях дало в результате более проработанный продукт. К тому же, РБД поддерживают более крупные объемы данных, чем ММБД. Они как раз и спроектированы для таких объемов. Модель структуры хранилища данных.Разновидность схемы типа звезды, предусматривающая нормализацию таблиц измерений. Первичные ключи в них состоят из единственного атрибута (соответствуют единственному элементу измерения). Это позволяет минимизировать избыточность данных и более эффективно выполнять запросы, связанные со структурой значений измерений. Модель структуры хранилища данных представлена на рис. 10. 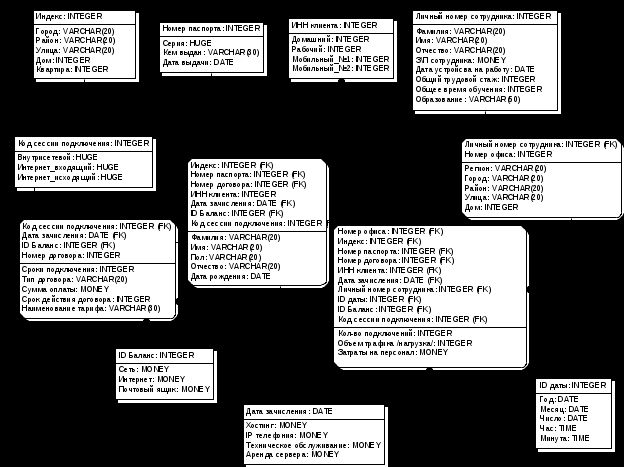 Рис. 10 Модель структуры хранилища данных фирмы-провайдера. Нерегламентированые запросы, на которые отвечает система.Запросы, которые формируются самими пользователями, называются нерегламентированными. Т.е. самих вариантов нерегламентированных запросов может быть очень и очень много, но если они достаточно редки, то выполняющиеся в тысячи раз чаще регламентированные запросы даже при небольшом числе их возможных вариантов составляют в системе большинство. Вот наиболее часто используемые нерегламентированные запросы в данной системе: Количество подключений в регионе за декабрь 2008 года. Объем трафика (нагрузка) в районе города в выходные дни. Затраты на техническое обслуживание в городе за прошлый год. Доход с конкретного офиса в прошлом месяце. Затраты на сотрудников в регионе в декабре 2008 года. Модель метаданныхМетаданные (или данные о данных) являются ключевым элементом в Хранилище Данных. Именно благодаря использованию метаданных Хранилище становится гибким и удобным средством доставки информации для поддержки принятия решений. Они содержат полное описание логической и физической структуры данных, всех процессов загрузки данных, специализированных приложений для анализа и представления данных в определенных областях, а также дополнительную информацию обо всех элементах Хранилища, помогающую легко ориентироваться в его сложной структуре. Метаданными явно или скрыто пользуются все группы пользователей Хранилища, начиная от наименее подготовленных конечных пользователей, приложения для которых управляются Метаданными, до Администратора данных и разработчиков. Обоснованный выбор инструментария для реализации ХД.Для выбора инструментария проектирования ИАС рассмотрим Deductor и Oracle Data Mining. Deductor -- описание аналитической платформы Deductor является аналитической платформой, т.е. основой для создания законченных прикладных решений. Реализованные в Deductor технологии позволяют на базе единой архитектуры пройти все этапы построения аналитической системы: от создания хранилища данных до автоматического подбора моделей и визуализации полученных результатов. Область применения Deductor предназначен для решения широкого спектра задач, связанных с обработкой структурированных, представленных в виде таблиц, данных. Прикладная область значения не имеет: механизмы, реализованные в Deductor, с успехом применяются на финансовых рынках, в страховании, торговле, телекоммуникациях, промышленности, медицине, в логистических и маркетинговых задачах и множестве других. Корпорация Oracle предлагает своим пользователям набор продуктов класса и сервисов класса Data Mining (Добыча Данных или ИАД (Интеллектуальный Анализ Данных)). Этот набор помогает компаниям понять и предвидеть поведение клиентов (покупателей, заказчиков) и создавать полные интегрированные решения по управлению отношениями с клиентами (CRM). В настоящее время вы можете использовать комплект Oracle Data Mining Suite (ранее известный как "Oracle Darwin") для построения моделей предсказания (predictive models), обнаруживающих скрытые в ваших данных закономерности и новую ценную информацию, которая может быть использована: в системах раннего обнаружения экстремальных ситуаций; для более полного понимания поведения и запросов клиентов и рыночной ситуации; для определения эффективности различных видов продаж; как помощь в борьбе со злоумышленниками. Oracle Data Mining Suite предоставляет легкий в использовании, интуитивно понятный пользовательский интерфейс. Oracle Data Mining Suite предлагает мастер-утилиты (wizards) для упрощения и автоматизации шагов data mining. Например, мастер Key Fields в Oracle Data Mining Suite автоматически находит переменные, которые наиболее нужны (максимально влияют) при решении некоторого конкретного вопроса. Мастер Model Seeker автоматически строит многие модели data mining, показывает интерактивные графы (interactive graphs) и таблицы результатов, а также рекомендует наилучшие модели. Oracle Data Mining Suite предлагает всю эту функциональность в дружественной пользователю среде, которую бизнес-аналитики могут использовать, причем они могут использовать мощные, возможно, многопроцессорные (SMP) системы и, благодаря этому, смогут "раскапывать" огромные массивы данных и извлекать больше ценной информации. Oracle Data Mining Suite может получать данные из различных сетевых источников данных. Oracle Data Mining Suite извлекает информацию из баз данных Oracle, используя технологию прямого доступа к данным Oracle (OCI). Корпорация Oracle также предоставляет шлюзы (gateways) к данным, хранимым в других базах данных. Как только вы обеспечите Oracle Data Mining Suite данными, вам часто будет нужно подготовить эти данные для анализа, и Oracle Data Mining Suite предоставляет обширный набор функций преобразования, таких как отбор образцов (sampling), случайный выбор (randomization), генерация новых вычисляемых полей, обработка (handling) отсутствующих значений, слияние (merging), замена значений, расщепление набора данных в последовательность (train) поднаборов, тестирование и наборы данных для сверки (evaluation datasets) и так далее. На фазе построения моделей Oracle Data Mining Suite предоставляет множество алгоритмов -C&RT, деревья классификации и регрессии (classification and regression trees), также известных как деревья решений, нейронные сети (neural networks), алгоритм нахождения ближайших k соседей (k-nearest-neighbors technique of memory-based reasoning) и кластеризация (clustering). Все эти алгоритмы полнофункциональны (full-featured), протестированы, документированы и хорошо поняты. Кроме того, они очень мощны, так как все они были реализованы таким образом, чтобы использовать аппаратуру параллельных вычислений для скорости и обработки больших объемов данных - гигабайтов и терабайтов. На основе произведенного анализа более подходящим вариантом является Deductor. Система мониторинга качества данных и аналитическая система реализованы на базе единой платформы Deductor Используются развитые средства Deductor для обработки больших объемов данных Учтены особенности сферы розничной торговли Не требуется дополнительного программирования Заключение.В данной работе была разработана информационно-аналитическая система, позволяющая структурировать, хранить и оптимально использовать имеющуюся информацию. Были применены Case средства BPwin и ERwin, в качестве структуры данных была выбрана Relational On-Line Analytical Processing. Также были приведены примеры нерегламентированных запросов и определены ключевые показатели эффективности. Список литературы.Вендров А.М. Практикум по проектированию программного обеспечения экономических информационных систем: Учеб. пособие. – М.: Финансы и статистика, 2004. – 192с. www.sql.ru www.olap.ru www.cfin.ru www.citforum.ru www.hr-portal.ru |