вопросы. общие вопросы. Программа ипрограммирование
 Скачать 1.45 Mb. Скачать 1.45 Mb.
|

Меню "Отправить отзыв"Если у вас возникли проблемы при применении Visual Studio или есть предложения по улучшению этого продукта, вы можете использовать меню Отправить отзыв в верхней части окна Visual Studio.  Вопрос 35 Составные типы данных Информация, поступающая в компьютер, состоит из определенного множества данных, относящихся к какой-то проблеме, — это именно те данные, которые относятся к конкретной задаче и из которых требуется получить желаемый ответ. В математике классифицируют данные в соответствии с некоторыми важными характеристиками. Принято различать целые, вещественные и логические данные, множества, последовательности, векторы, матрицы (таблицы) и т.д. В обработке данных на компьютере классификация играет даже боRльшую роль. Любая константа, переменная, выражение или функция относятся к некоторому типу. Тип данных определяет диапазон допустимых значений и операций, которые могут быть применены к этим значениям. Кроме того, тип данных задает формат представления объектов в памяти компьютера, ведь в конце концов любые данные будут представлены в виде последовательности двоичных цифр (нулей и единиц). Тип данных указывает, каким образом следует интерпретировать эту информацию. Тип любой величины может быть установлен при ее описании, а в некоторых языках может выводиться компилятором по ее виду (Fortran, Basic). Например, если переменная имеет целочисленный тип данных, то таким образом определен диапазон значений, которые могут быть сохранены в этой переменной (целые числа) и определены операции, которые могут быть применены к этой переменной (арифметические, логические, возможность ввода и вывода значений этой переменной). Каждый язык программирования поддерживает один или несколько типов данных. Наличие в языке программирования типизации означает жесткую связку операций и типов объектов, над которыми их можно выполнять. Не все языки обладают таким свойством. Например, в языке С практически любые операции можно выполнять над любыми данными (например, складывать два символа или число с логическим значением, но в большинстве случаев такие операции бессмысленны и соответствуют ошибке в программе, на которую компилятор указать не сможет). Классификация типов данныхЛюбые данные могут быть отнесены к одному из двух типов: простому (основному), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач. Данные простого типа — это символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из таких элементарных данных формируются структуры (сложные типы) данных. Принято различать следующие типы данных: · Простые. • Числовые типы. § Целочисленные. § Вещественные. • Символьный тип. • Логический тип. • Перечислимый тип. ◊ Множество. ◊ Указатель. · Составные. ◊ Массив. • Строковый тип. ◊ Запись. ◊ Последовательность. Рассмотрим перечисленные типы данных подробнее. Простые типыЧисловые типы.Значениями переменных таких типов являются числа. К ним могут применяться обычные арифметические операции, операции сравнения (в результате получается логическое значение). Принципиально различны в компьютерном представлении целые и вещественные типы. Целочисленные типы данных делятся, в свою очередь, на знаковые и беззнаковые. Целочисленные со знаком могут принимать как положительные, так и отрицательные значения, а беззнаковые — только неотрицательные значения. Диапазон значений при этом определяется количеством разрядов, отводимых на представление конкретного типа в памяти компьютера (см. “Представление чисел”). Вещественные типы бывают: с фиксированной точкой, то есть хранятся знак и цифры целой и дробной частей (в настоящее время в языках программирования реализуются редко), и с плавающей точкой, то есть число приводится к виду m х 2e, где m — мантисса, а e — порядок числа, причем 1/2 Символьный тип. Элемент этого типа хранит один символ. При этом могут использоваться различные кодировки, которые определяют, какому коду (двоичному числу) какой символ (знак) соответствует. К значениям этого типа могут применяться операции сравнения (в результате получается логическое значение). Символы считаются упорядоченными согласно своим кодам (номерам в кодовой таблице). Логический тип. Данные этого типа имеют два значения: истина (true) и ложь (false). К ним могут применяться логические операции. Используется в условных выражениях, операторах ветвления и циклах. В некоторых языках, например С, является подтипом числового типа, при этом ложь = 0, истина = 1 (или истинным считается любое значение, отличное от нуля). Перечислимый тип. Отражает самый прямолинейный способ описания простого типа — перечисление всех значений, относящихся к этому типу. Каждая константа такого типа получает свой порядковый номер, что позволяет реализовать ряд простых операций над этим типом, таких, как получить следующее по порядку значение данного типа. Множество как тип данных в основном совпадает с обычным математическим понятием множества. Допустимы стандартные операции с множествами и проверка на принадлежность элемента множеству. В некоторых языках рассматривается как составной тип (массив логических значений, i-й элемент которого указывает, находится ли i в множестве), однако эффективней реализовывать множество как машинное слово (или несколько слов), каждый бит которого характеризует наличие соответствующего элемента в множестве. Указатель (тип данных). Если описанные выше типы данных представляли какие-либо объекты реального мира, то указатели представляют объекты компьютерного мира, то есть являются исключительно компьютерными терминами. Переменная-указатель хранит адрес в памяти компьютера, указывающий на какую-либо информацию, как правило — на другую переменную. Составные типыСоставные типы формируются на основе комбинаций простых типов. Массив является индексированным набором элементов одного типа, простого или составного (см. “Операции с массивами”). Одномерный массив предназначен для компьютерной реализации такой структуры, как вектор, двухмерный массив — таблицы. Строковый тип. Хранит строку символов. Вообще говоря, может рассматриваться как массив символов, но иногда рассматривается в качестве простого типа. Часто используется для хранения фамилий людей, названий предметов и т.п. К элементам этого типа может применяться операция конкатенации (сложения) строк. Обычно реализованы также операции сравнения над строками, в том числе операции “<” и “>”, которые интерпретируются как сравнение строк согласно алфавитному порядку (алфавитом здесь является набор символов соответствующей кодовой таблицы). Во многих языках реализованы и специальные операции над строками: поиск заданного символа (подстроки), вставка символа, удаление символа, замена символа. Запись. Наиболее общий метод получения составных типов из простых заключается в объединении элементов произвольных типов. Причем сами эти элементы могут быть, в свою очередь, составными. Так, человек описывается с помощью нескольких различных характеристик, таких, как имя, фамилия, дата рождения, пол, и т.д. Записью (в языке С — структурой) называется набор различных элементов (полей записи), хранимый как единое целое. При этом возможен доступ к отдельным полям записи. К полю записи применимы те же операции, что и к базовому типу, к которому это поле относится (тип каждого поля указывается при описании записи). Последовательность. Данный тип можно рассматривать как массив бесконечного размера (память для него может выделяться в процессе выполнения программы по мере роста последовательности). Зачастую такой тип данных обладает лишь последовательным доступом к элементам. Под этим подразумевается, что последовательность просматривается от одного элемента строго к следующему, формируется же она путем добавления элементов в ее конец. В языке Pascal подобному типу соответствуют файловые типы данных. Преимущества от использования типов данныхТипы данных защищают программы по крайней мере от следующих ошибок: 1. Некорректное присваивание. Пусть переменная объявлена как имеющая числовой тип. Тогда попытка присвоить ей символьное или какое-либо другое значение приведет к ошибке еще на этапе компиляции. Такого рода ошибки трудно отследить обычными средствами. 2. Некорректная операция. Типизация позволяет избежать попыток применения выражений вида “Hello world” + 1. Поскольку, как уже говорилось, все переменные в памяти хранятся как наборы битов, то при отсутствии типов подобная операция была выполнима (и могла дать результат вроде “Hello worle”!). С использованием типов такие ошибки отсекаются опять же на этапе компиляции. 3. Некорректная передача параметров в процедуры и функции (см. “Подпрограммы”). Если функция “синус” ожидает, что ей будет передан числовой аргумент, то передача ей в качестве параметра строки “Hello world” может иметь непредсказуемые последствия. При помощи контроля типов такие ошибки также отсекаются на этапе компиляции или приводят к ошибкам выполнения программы, если значения параметра вводятся с клавиатуры или файла. Кроме того, типы данных позволяют программисту абстрагироваться от машинного представления информации в виде наборов нулей и единиц и строить программы, основываясь на знакомых понятиях, таких, как числа, множества, последовательности, и т.п. В конечном итоге это приводит к получению более надежных программ. Методические программыПри изучении данной темы самое главное — разделить следующие понятия: данные — тип данных — абстрактная структура данных — структура данных Типом данныхпеременной называют множество значений, которые может принимать эта переменная, и множество операций, которые применимы к этим значениям. Абстрактная структура данных (см. “Структуры данных”) — это некоторая математическая модель данных (см. выше), включающая различные операции, определенные в рамках этой модели. Для реализации абстрактной структуры в том или ином языке программирования используются структуры, которые представляют собой набор переменных, возможно различных типов данных, объединенных определенным образом. При этом одна и та же абстрактная структура данных может быть реализована через различные структуры языка программирования. Например, такая абстрактная структура данных, как список, может быть реализована с использованием массива, файла или списка динамических переменных. Примеры различных структур данных, реализующих абстрактную структуру граф, приведены в статье “Табличные модели” 2. Изучение конкретных типов данных производится в процессе рассмотрения определенного языка программирования в курсе информатики. При этом нельзя совсем не касаться таких вопросов, как представление определенного типа данных в памяти компьютера и диапазон значений, которые могут принимать переменные каждого из типов. Рассказывать стоит и о преобразованиях типов, как автоматических, выполняемых компилятором при анализе операции присваивания, например, вещественной переменной целочисленного выражения, так и производимых программистом, например, при переводе текстовой информации в числовую и т.д. Изучение особенностей представления целых чисел (а именно этот тип данных встречается в учебных задачах по программированию чаще всего) полезно проиллюстрировать следующим примером. Пример. С помощью программы на языке Borland Pascal вычислим значение n! (факториал числа n). Версия языка в данном случае указана потому, что ею определяется количество разрядов, отводимых на переменные определенного типа. В данном случае на переменные типа integer отводится 16 бит, что определяет диапазон значений этого знакового типа от –32 768 до 32 767. var a,i,n: integer; begin readln(n); a := 1; for i := 2 to n do a := a * i; writeln(a) end. При запуске этой программы для n = 7, 8 и 10 мы получим 5040, –25 216 и 24 320 соответственно. Первое полученное значение является верным, второе (отрицательное) может натолкнуть программиста на мысль, что в результате арифметических действий произошел выход за границу диапазона значений типа, а вот третье число само по себе может показаться верным, хотя, конечно, это не так. На этом примере можно показать, что правильный алгоритм решения задачи при неправильном выборе типов данных может привести к абсурдному результату. И при разработке программы одним из важных этапов является оценка возможных значений (в том числе промежуточных) используемых переменных и выбор подходящих типов данных. Следует подчеркнуть, что для целого типа выход за диапазон значений не приводит к прерыванию работы процессора (компьютер выдает неверные результаты), а для вещественных чисел (переполнение порядка) — это аварийная ситуация (floating point error), которая не пройдет незамеченной. Вопрос 36 Структурирование программ, принцип модульности Структурное программированиеСтруктурное программирование — парадигма программирования, в основе которой лежит представление программы в виде иерархической структуры блоков. По своей сути оно воплощает принципы системного подхода в процессе создания и эксплуатации программного обеспечения ЭВМ. Структурное программирование воплощает принципы системного подхода в процессе создания и эксплуатации программного обеспечения ЭВМ. В основу структурного программирования положены следующие достаточно простые положения: алгоритм и программа должны составляться поэтапно (по шагам). сложная задача должна разбиваться на достаточно простые части, каждая из которых имеет один вход и один выход. логика алгоритма и программы должна опираться на минимальное число достаточно простых базовых управляющих структур. Структурное программирование иногда называют еще «программированием без go to». Рекомендуется избегать употребления оператора перехода всюду, где это возможно, но чтобы это не приводило к слишком громоздким структурированным программам. goto (перейти на) — оператор безусловного перехода (перехода к определённой точке программы, обозначенной номером строки либо меткой) в некоторых языках программирования. В некоторых языках оператор безусловного перехода может иметь другое имя (например, jmp в языках ассемблера). Фундаментом структурного программирования является теорема о структурировании. Эта теорема устанавливает, что, как бы сложна ни была задача, схема соответствующей программы всегда может быть представлена с использованием ограниченного числа элементарных управляющих структур. Базовыми элементарными структурами являются структуры: следование, ветвление и повторение (цикл), любой алгоритм может быть реализован в виде композиции этих трех конструкций. 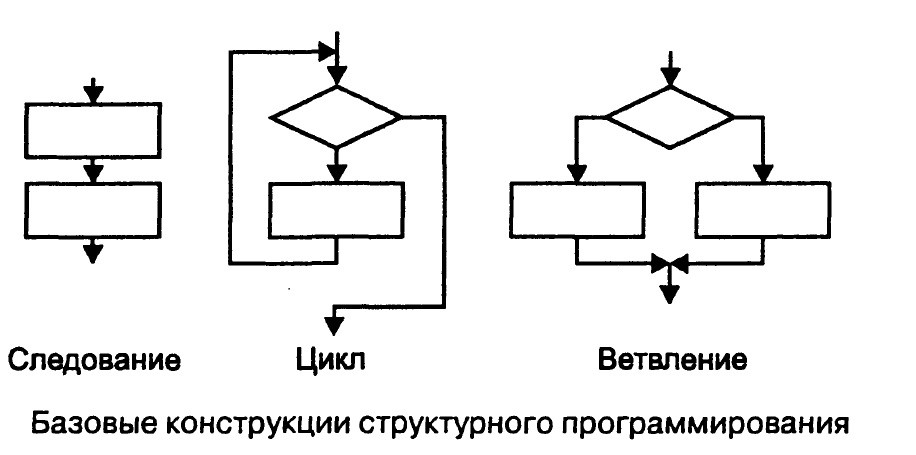 Достоинства структурного программирования:повышается надежность программ (благодаря хорошему структурированию при проектировании, программа легко поддается тестированию и не создает проблем при отладке); повышается эффективность программ (структурирование программы позволяет легко находить и корректировать ошибки, а отдельные подпрограммы можно переделывать (модифицировать) независимо от других); уменьшается время и стоимость программной разработки; улучшается читабельность программ. Модульное программированиеМодульное программирование является естественным следствием проектирования сверху вниз и заключается в том, что программа разбивается на части – модули, разрабатываемые по отдельности. В программировании под модулем понимается отдельная подпрограмма, а подпрограммы часто называются процедурами или процедурами-функциями. Поэтому модульное программирование еще называется процедурным.  Модуль должен обладать следующими свойствами:один вход и один выход – на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO (Input — Process — Output — вход-процесс-выход); функциональная завершенность – модуль выполняет перечень регламентированных операций для реализации каждой отдельной функции в полном составе, достаточных для завершения начатой обработки; логическая независимость – результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей; слабые информационные связи с другими программными модулями – обмен информацией между модулями должен быть по возможности минимизирован; обозримый по размеру и сложности программный код. Модули содержат определение доступных для обработки данных, операции обработки данных, схемы взаимосвязи с другими модулями. Каждый модуль состоит из спецификации и тела. Спецификации определяют правила использования модуля, а тело – способ реализации процесса обработки. Принципы модульного программирования программных продуктов во многом сходны с принципами нисходящего проектирования: сначала определяются состав и подчиненность функций, а затем — набор программных модулей, реализующих эти функции. Функционально-модульная структура приложения Вопрос 37 Основные понятия языка программирования Си Программа, написанная на языке Си, состоит из операторов. Каждый оператор вызывает выполнение некоторых действий на соответствующем шаге выполнения программы. При написании операторов применяются латинские прописные и строчные буквы, цифры и специальные знаки. К таким знакам, например, относятся: точка (.), запятая (,), двоеточие (:), точка с запятой (;) и др. Совокупность символов, используемых в языке, называется алфавитом языка. В персональном компьютере символы хранятся в виде кодов. Соответствие между каждым символом и его кодом задается специальной кодовой таблицей. На нее разработан стандарт ASCII, поэтому коды символов называют ASCII-кодами. Различают видимые и управляющие символы. Первые могут быть отображены на экране дисплея либо отпечатаны на принтере. Вторые вызывают определенные действия в машине, например: звуковой сигнал - код 710, возврат курсора на один шаг - код 810, горизонтальная табуляция - код 910, перевод курсора на новую строку - код 1010, перемещение курсора в начало строки - код 1310 и т.д. Такие управляющие символы имеют десятичные номера 0 - 31, 127. Для представления каждого символа в персональном компьютере используется один байт, поэтому общее число символов равно 28 = 256. Кодовая таблица, которая устанавливает соответствие между символом и его кодом, имеет 256 строк вида: код_символа_в_заданной_системе_счисления - символ. Первая половина кодовой таблицы является стандартной, а вторая используется для представления символов национальных алфавитов, псевдографических элементов и т.д. Важным понятием языка является идентификатор, который используется в качестве имени объекта (функции, переменной, константы и др.). Идентификаторы должны выбираться с учетом следующих правил: Они должны начинаться с буквы латинского алфавита (а,...,z, А,...,Z) или с символа подчеркивания (_). В них могут использоваться буквы латинского алфавита, символ подчеркивания и цифры (0,...,9). Использование других символов в идентификаторах запрещено. В языке Си буквы нижнего регистра (а,...,z), применяемые в идентификаторах, отличаются от букв верхнего регистра (А,...,Z). Это означает, что следующие идентификаторы считаются разными: name, NaMe, NAME и т.д. Идентификаторы могут иметь любую длину, но воспринимается и используется для различения объектов (функций, переменных, констант и т.д.) только часть символов. Их число меняется для разных систем программирования, но в соответствии со стандартом ANSI C не превышает 32 (в Си++ это ограничение снято). Если длина идентификатора установлена равной 5, то имена count и counter будут идентичны, поскольку у них совпадают первые пять символов. Идентификаторы для новых объектов не должны совпадать с ключевыми словами языка и именами стандартных функций из библиотеки. В программах на языке Си важная роль отводится комментариям. Они повышают наглядность и удобство чтения программ. Комментарии обрамляются символами /* и */. Их можно записывать в любом месте программы. В языке Си++ введена еще одна форма записи комментариев. Все, что находится после знака // до конца текущей строки, будет также рассматриваться как комментарий. Отметим, что компилятор языка Си, встроенный в систему программирования Borland C++, позволяет использовать данный комментарий и в программах на Си. Пробелы, символы табуляции и перехода на новую строку в программах на Си игнорируются. Это позволяет записывать различные выражения в хорошо читаемом виде. Кроме того, строки программы можно начинать с любой позиции, что дает возможность выделять в тексте группы операторов. Вопрос 38 Функциональное программирование Что такое функциональное программирование?Функциональное программирование — это парадигма декларативного программирования, в которой программы создаются путем последовательного применения функций, а не инструкций. Каждая из этих функций принимает входное значение и возвращает согласующееся с ним выходное значение, не изменяясь и не подвергаясь воздействию со стороны состояния программы. Для таких функций предусмотрено выполнение только одной операции, если же требуется реализовать сложный процесс, то используется уже композиция функций, связанных последовательно. В процессе ФП мы создаем код, состоящий из множества модулей, поскольку функции в нем могут повторно использоваться в разных частях программы путем вызова, передачи в качестве параметров или возвращения. Чистые функции не производят побочных эффектов и не зависят от глобальных переменных или состояний. 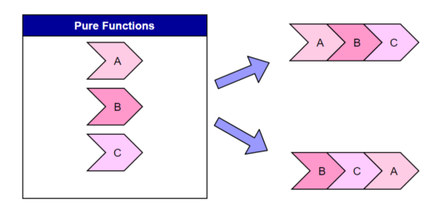 Визуальное представление функций в ФП Функциональное программирование используется, когда решения легко выражаются с помощью функций и не имеют ощутимой связи с физическим миром. В то время как объектно-ориентированные программы моделируют код по образцу реальных объектов, ФП задействует математические функции, в которых промежуточные или конечные значения не сопоставляются с объектами физического мира. К наиболее распространенным областям, применяющим ФП, относятся проектирование ИИ, алгоритмы классификации в МО, финансовые программы, а также продвинутые модели математических функций. Проще говоря: функциональные программы выполняют много чистых однозадачных функций, совмещенных в последовательность для решения сложных математических или не связанных с физическим миром задач. Преимущества функционального программированияЛегкая отладка: чистые функции и неизменяемые данные упрощают обнаружение мест определения значений переменных. В чистых функциях меньше факторов, влияющих на них, что позволяет быстрее находить проблемные участки кода. Отложенное вычисление: функциональные программы производят вычисления только при необходимости. Это позволяет им повторно использовать ранее полученные результаты и экономить время на выполнение. Модульность: чистые функции не полагаются на внешние переменные или состояния, в связи с чем их можно легко переиспользовать в разных местах программы. Кроме того, функции будут выполнять только одну операцию или вычисление, что не позволит вам при их использовании случайно импортировать лишний код. Лучшая читаемость: функциональные программы легко читать, потому что поведение каждой функции неизменяемо и изолировано от состояния программы. В результате вы зачастую можете легко понять, что будет делать функция, просто по ее имени. Параллельное программирование: программы легче создавать при помощи функционального подхода, потому что неизменяемые переменные снижают число изменений внутри этих программ. Каждой функции приходится работать только с вводом пользователя, и она может быть уверена, что состояние программы в основном останется прежним. Языки функционального программированияФункциональная парадигма поддерживается не во всех языках. Некоторые из них, например Haskell, спроектированы именно для этой задачи, в то время как другие, например JavaScript, реализуют возможности и ООП, и ФП. Есть же и такие языки, где функциональное программирование невозможно в принципе. Функциональные языки:Haskell: это наиболее популярный язык среди функциональных программистов. В нем реализована защита памяти, отличный сбор мусора, а также повышенная скорость, обусловленная ранней компиляцией машинного кода. Его богатая статическая система типов дает вам доступ к уникальным алгебраическим и полиморфным типам, которые делают процесс программирования более эффективным, а код более читаемым. Erlang: этот язык, как и его потомок, Elixir, заняли нишу лучших функциональных языков для параллельных систем. Несмотря на то, что в популярности он уступает Haskell, его нередко используют для бэкенд-программирования. В последнее время Erlang начал завоевывать внимание в сфере масштабируемых мессенджеров, таких как WhatsApp и Discord. Clojure: это ориентированный на функциональную парадигму диалект Lisp, который работает на виртуальной машине Java (JVM). Будучи преимущественно функциональным языком, он поддерживает как изменяемые, так и неизменяемые структуры данных, но при этом все же менее строг в функциональном плане, чем другие. Если вам нравится Lisp, то вы также полюбите и Clojure. F#: этот язык аналогичен Haskell (они находятся в одной языковой группе), но имеет меньше расширенных возможностей. Кроме того, в нем реализована слабая поддержка объектно-ориентированных конструкций. Языки с функциональными возможностямиScala: этот язык поддерживает как ООП, так и ФП. Его наиболее интересная особенность в наличии строгой системы статической типизации, как в Haskell, которая помогает создавать строгие функциональные программы. При проектировании Scala среди прочих стояла задача решить многие критические проблемы Java, поэтому данный язык очень подходит для Java-разработчиков, желающих попробовать функциональное программирование. JavaScript: несмотря на то, что приоритет в этом языке не на стороне функциональной парадигмы, JavaScript уделяет ей немало внимания в связи со своей асинхронной природой. В нем также поддерживаются такие важные функциональные возможности, как лямбда выражения и деструктуризация. Вместе эти атрибуты выделяют JS как ведущий язык для ФП. Python, PHP, C++: эти мультипарадигмальные языки тоже поддерживают функциональное программирование, но уже в меньшей степени, чем Scala и JavaScript. Java: этот язык относится к языкам общего назначения, но приоритет в нем отдается ООП, основанному на классах. Несмотря на то, что добавление лямбда выражений в некотором смысле помогает реализовывать более функциональный стиль, в конечном итоге Java остается языком ООП. Он позволяет заниматься функциональным программированием, но при этом в нем недостает ключевых элементов, которые бы оправдывали его освоение именно с этой целью. Принципы функционального программированияПеременные и функцииКлючевыми составляющими функциональной программы являются уже не объекты и методы, а переменные и функции. При этом следует избегать глобальных переменных, потому что изменяемые глобальные переменные усложняют понимание программы и ведут к появлению у функций побочных эффектов. Чистые функцииДля чистых функций характерны два свойства: они не создают побочных эффектов; они всегда производят одинаковый вывод при получении одинакового ввода, что еще можно называть как ссылочную прозрачность. Побочные эффекты же возникают, если функция изменяет состояние программы, переписывает вводную переменную или в общем вносит какие-либо изменения при генерации вывода. Отсутствие же побочных эффектов снижает риски появления ошибок по вине чистых функций. Ссылочная прозрачность означает, что любой вывод функции должен допускать замену на ее значение, не изменяя при этом результата программы. Этот принцип гарантирует, что вы создаете такие функции, которые выполняют только одну операцию и достигают согласованного вывода. Ссылочная прозрачность возможна только, если функция не влияет на состояние программы или в общем не старается выполнить более одной операции. Неизменяемость и состоянияНеизменяемые данные или состояния не могут изменяться после их определения, что позволяет сохранять постоянство стабильной среды для вывода функций. Лучше всего программировать каждую функцию так, чтобы она выводила один и тот же результат независимо от состояния программы. Если же она зависит от состояния, то это состояние должно быть неизменяемым, чтобы вывод такой функции оставался постоянным. Подходы функционального программирования обычно избегают применения функций с общим состоянием (когда несколько функций опираются на одно состояние) и функций с изменяющимся состоянием (которые зависят от изменяемых функций), потому что они уменьшают модульность программы. Если же вы не можете обойтись без функций с общим состоянием, сделайте это состояние неизменяемым. РекурсияОдно из серьезных отличий объектно-ориентированного программирования от функционального в том, что программы последнего избегают таких конструкций, как инструкции if else или циклы, которые в разных случаях выполнения могут выдавать разные выводы. Вместо циклов функциональные программы используют для всех задач по перебору рекурсию. Функции первого классаФункции в ФП рассматриваются как типы данных и могут использоваться как любое другое значение. Например, мы заполняем функциями массивы, передаем их в качестве параметров или сохраняем их в переменных. Функции высшего порядкаЭти функции могут принимать другие функции в качестве параметров или возвращать функции в качестве вывода. Они делают возможности вызова функций более гибкими и позволяют легче абстрагироваться от действий. Композиция функцийДля выполнения сложных операций функции можно выполнять последовательно. В этом случае результат каждой функции передается следующей функции в виде аргумента. Это позволяет с помощью всего одного вызова функции активировать целую серию их последовательных вызовов. Вопрос 39 Логическое программирование |