вопросы. общие вопросы. Программа ипрограммирование
 Скачать 1.45 Mb. Скачать 1.45 Mb.
|

|
1 Термины «программа» и «программирование». Определение. Программа - это данные, предназначенные для управления конкретными компонентами системы обработки информации в целях реализации определенного алгоритма. Программирование– научная и практическая деятельность по созданию программ. 2 Перечислите даты и основные события в истории развития языков программирования
3 Что представляют собой языки программирования первого и второго поколения? К первому поколению (1GL) относят машинные языки — языки программирования на уровне команд процессора конкретной машины. Для программирования не использовался транслятор, команды программы вводились непосредственно в машинном коде переключателями на передней панели машины. Такие языки были хороши для детального понимания функционирования конкретной машины, но сложны для изучения и решения прикладных задач.(языки ассемблера) Языки второго поколения (2GL) создавались для того, чтобы облегчить тяжёлую работу по программированию, перейдя в выражениях языка от низкоуровневых машинных понятий ближе к тому, как обычно мыслит программист. Эти языки появились в 1950-е годы такие языки как Фортран и Алгол. Наиболее важной проблемой, с которыми столкнулись разработчики языков второго поколения, стала задача убедить в том, что созданный компилятором код выполняется достаточно хорошо, чтобы оправдать отказ от программирования на ассемблере. Разработчикам должны были продемонстрировать, что они действительно могут генерировать почти такой же эффективный код, как и при ручном кодировании, причём практически для любой исходной задачи. 4 Достоинства и недостатки языков высокого уровня Главные преимущества: более понятный человеку код и возможность переноса программ с одного процессора на другой. Хотя последнее утверждение очень спорно, тем не менее, при выполнении определенных условий перенос программы все же возможен. Также сильно упрощается реализация многих стандартных функций и появляется аппаратная независимость языка. недостатки. Самый серьезный из них определяется увеличенным объемом машинного кода, по сравнения с реализацией того же алгоритма на ассемблере. Фактически, больший объем является платой за универсальность и простоту разработки программ. Несколько снижают остроту проблемы рост памяти микроконтроллеров и увеличение их быстродействия. Другие, традиционно называемые недостатки, такие как высокая стоимость компиляторов и сложность отладки. 5 Интерпретатор и компилятор. Принципы работы, достоинства и недостатки Компилятор и Интерпретатор имеют одно предназначение — конвертировать инструкции языка высокого уровня (как C или Java) в бинарную форму, понятную компьютеру. Это программное обеспечение, используемое для запуска высокоуровневых программ и кодов выполняемых различные задачи. Для разных высокоуровневых языков разработаны специфичные компиляторы/интерпретаторы. Не смотря на то что как компилятор так и интерпретатор преследуют одну и ту же цель, они отличаются способом выполнения своей задачи, то есть конвертирования высокоуровневого языка в машинные инструкции. Компилятор Компилятор транслирует высокоуровневый язык в машинный. Когда пользователь пишет код на языке высокого уровня, таком как Java, и хочет его выполнить, то прежде чем это может быть сделано, будет использован специальный компилятор разработанный для Java. Компилятор сначала сканирует всю программу, а потом транслирует ее в машинный код, который будет выполнен компьютерным процессором, после чего будут выполнены соответствующие задачи. 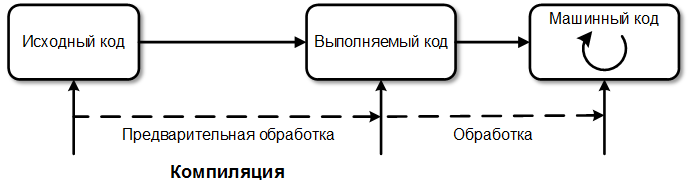 Интерпретатор Интерпретаторы не очень сильно отличаются от компиляторов. Они также конвертируют высокоуровневые языки в читаемые машиной бинарные эквиваленты. Каждый раз когда интерпретатор получает на выполнение код языка высокого уровня, то прежде чем сконвертировать его в машинный код, он конвертирует этот код в промежуточный язык. Каждая часть кода интерпретируется и выполняется отдельно и последовательно, и если в какой-то части будет найдена ошибка, она остановит интерпретацию кода без трансляции следующей части кода. 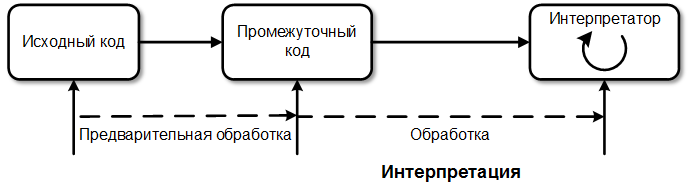 сначала исходный код конвертируется в промежуточную форму, а затем выполняется интерпретатором. Ниже перечислены главные отличия между компилятором и интерпретатором: Интерпретатор берет одну инструкцию, транслирует и выполняет ее, а затем берет следующую инструкцию. Компилятор же транслирует всю программу сразу, а потом выполняет ее. Компилятор генерирует отчет об ошибках после трансляции всего, в то время как интерпретатор прекратит трансляцию после первой найденной ошибки. Компилятор по сравнению с интерпретатором требует больше времени для анализа и обработки языка высокого уровня. Помимо времени на обработку и анализ, общее время выполнения кода компилятора быстрее в сравнении с интерпретатором. Основной недостаток компиляторов – трудоемкость трансляции языков программирования, ориентированных на обработку данных сложной структуры, заранее неизвестной или динамически меняющейся во время работы программы. С помощью интерпретатора для исследования содержимого памяти допустимо в любой момент прервать работу программы, организовать диалог с пользователем, выполнить любые сложные преобразования данных и при этом постоянно контролировать программно-аппаратную среду, что и обеспечивает высокую надежность работы программы. 6 Что представляют собой языки программирования третьего и четвертого поколения? Под третьим поколением (3GL) первоначально понимались все языки более высокого уровня, чем ассемблер. Главной отличительной чертой стала независимость от аппаратного обеспечения, т е выражение алгоритма в форме, не зависящей от конкретных характеристик машины, на которой он будет исполняться. Код перед исполнением транслируется либо непосредственно в машинные команды, либо в код на ассемблере и затем уже ассемблируется. При компиляции, в отличие от предыдущих поколений, уже нет соответствия один-к-одному между инструкциями программы и генерируемым кодом. Стала широко использоваться интерпретация программ — при этом инструкции программы не преобразуются в машинный код, а исполняются непосредственно одна за другой. Языки программирования четвёртого поколения (4GL) -Языки этого поколения предназначены для реализации крупных проектов, повышают их надежность и скорость создания, ориентированы на специализированные области применения, и используют не универсальные, а объектно-ориентированные языки, оперирующие конкретными понятиями узкой предметной области. В эти языки встраиваются мощные операторы, позволяющие одной строкой описать такую функциональность, для реализации которой на языках младших поколений потребовались бы тысячи строк исходного кода. 7 Декларативный подход к программированию, описание. Декларати́вное программи́рование — парадигма программирования, в которой задаётся спецификация решения задачи, то есть описывается, что представляет собой проблема и ожидаемый результат. Противоположностью декларативного является императивное программирование, описывающее на том или ином уровне детализации, как решить задачу и представить результат. Декларативное программирование идёт от человека к машине, тогда как императивное — от машины к человеку. Декларативные программы не содержат переменных и операторов присваивания, обеспечивается ссылочная прозрачность. Наиболее близким к «чисто декларативному» программированию является написание исполнимых спецификаций. В этом случае программа представляет собой формальную теорию, а её выполнение является одновременно автоматическим доказательством этой теории (соответствие Карри — Ховарда), и характерные для императивного программирования составляющие процесса разработки (проектирование, отладка и другие) в этом случае исключаются: программа проектирует и доказывает сама себя. К подвидам декларативного программирования относят функциональное и логическое программирование — программы на таких языках содержат алгоритмические составляющие, архитектура в императивном понимании в них отсутствует: схема программы является непосредственно частью исполняемого кода. На повышение уровня декларативности нацелено языково-ориентированное программирование. 8 Архитектура фон Неймана. Описание, состав, цикл работы. Принципы, лежащие в основе архитектуры ЭВМ, были сформулированы в 1945 году Джоном фон Нейманом, который развил идеи Чарльза Беббиджа, представлявшего работу компьютера как работу совокупности устройств: обработки, управления, памяти, ввода-вывода. Его ключевыми элементами являются: память — оперативное запоминающее устройство (ОЗУ); центральный процессор (ЦП);( счетчик команд) арифметико-логическое устройство (АЛУ), способное выполнять базовые операции преобразования данных; устройство управления (УУ); счетчик команд (СК); устройства ввода-вывода. Память компьютера представляет собой линейный набор пронумерованных ячеек. элемент ЦП — специальный регистр, который содержит адрес (номер) ячейки памяти, хранящей следующую команду, подлежащую исполнению. Команды и данные кодируются двоичными кодами и хранятся в одной и той же памяти. Команда может содержать несколько битов, отведенных под код действия — К, адрес первого операнда, и адрес второго операнда. Это позволяет создавать программы, изменяющие собственные команды — преобразующие их подобно данным. Но есть недостаток — программа при выполнении может непреднамеренно или целенаправленно разрушить саму себя или другие программы, находящиеся в памяти! Все вычисления выполняются централизованно — в АЛУ под управлением УУ. Команда извлекается из памяти, передается в процессор, где декодируется устройством управления. Из памяти с использованием адресов, указанных в команде, извлекаются операнды. УУ побуждает АЛУ выполнить операцию в соответствии с дешифрированным кодом операции К. Результаты операции пересылаются в память — по адресу, указанному в команде. После этого значение счетчика команд автоматически увеличивается — на следующем цикле извлечению из памяти подлежит следующая команда. Процесс повторяется. канал обмена процессора с памятью. Чем больше число объектов— тем больше времени требуется, чтобы найти решение: приходится на каждом шаге передавать информацию от процессора в память и обратно. общее быстродействие будет зависеть от возможностей канала обмена. важнейшие моменты работы фон-неймановской машины:. Команды программы выполняются одна за другой в единственном центральном процессоре — это принципиально последовательная архитектура. После выполнения предыдущей команды автоматически выполняется следующая, если только предыдущая команда не была командой, изменившей счетчик команд (командой безусловного или условного перехода). Хранение команд и данных в одной и той же памяти, с одной стороны, дает определенную гибкость, с другой — создает проблемы с безопасностью и замедляет работу ЭВМ в целом. 9 Команды перехода Команды переходов предназначены для организации всевозможных циклов, ветвлений, вызовов подпрограмм и т.д., то есть они нарушают последовательный ход выполнения программы. Эти команды записывают в регистр-счетчик команд новое значение и тем самым вызывают переход процессора не к следующей по порядку команде, а к любой другой команде в памяти программ. Некоторые команды переходов предусматривают в дальнейшем возврат назад, в точку, из которой был сделан переход, другие не предусматривают этого. Команды переходов без возврата делятся на две группы: - команды безусловных переходов; - команды условных переходов. Несколько примеров команд условных переходов: переход, если равно нулю; переход, если не равно нулю; переход, если есть переполнение. Специально для проверки условий перехода применяется команда сравнения (CMP), предшествующая команде условного перехода Команды переходов с дальнейшим возвратом в точку, из которой был произведен переход, применяются для выполнения подпрограмм, то есть вспомогательных программ. Эти команды называются также командами вызова подпрограмм. Все команды переходов с возвратом предполагают безусловный. При этом они требуют одного входного операнда, который может указывать как абсолютное значение нового адреса, так и смещение, складываемое с текущим значением адреса. Текущее значение счетчика команд (текущий адрес) сохраняется перед выполнением перехода в стеке. Для обратного возврата в точку вызова подпрограммы (точку перехода) используется специальная команда возврата (RET или RTS). Эта команда извлекает из стека значение адреса команды перехода и записывает его в регистр-счетчик команд. 10 Структура программы на императивном языке программирования. Метки и операторы 11 Типовые конструкции императивного языка: линейный участок, условный оператор 12 Рекурсия и итерация Рекурсией называется такой способ организации обработки данных, при котором программа (или функция) вызывает сама себя или непосредственно, или из других программ (функций). Функция называется рекурсивной, если во время ее обработки возникает ее повторный вызов, либо непосредственно, либо косвенно, путем цепочки вызовов других функций. Итерацией называется такой способ организации обработки данных, при котором некоторые действия многократно повторяются, не приводя при этом к рекурсивным вызовам программ (функций). Перед написанием рекурсивных функций на любом языке программирования, как правило, необходимо записать рекуррентное соотношение, определяющее метод вычисления функций. Рекуррентное соотношение должно содержать как минимум два условия: I) условие продолжения рекурсии (шаг рекурсии); II) условие окончания рекурсии. Рекурсию будем реализовывать посредством вызова функции самой себя. При этом в теле функции сначала следует проверять условие продолжения рекурсии. Если оно истинно, то выходим из функции. Иначе совершаем рекурсивный шаг. Итеративный вариант функций будем реализовывать при помощи оператора цикла for. 13 Виды циклов в императивных языках 14 Структурное программирование Структурное программирование – это метод, предполагающий создание улучшенных программ. Он служит для организации проектирования и кодирования программ таким образом, чтобы предотвратить большинство логических ошибок и обнаружить те, которые допущены. Главным в структурном программировании является возможность разбиения программы на составляющие ее элементы. Структурное программирование тесно связано такими понятиями как «нисходящее проектирование» и «модульное программирование». Метод нисходящего проектирования предполагает последовательное разложение функции обработки данных на простые функциональные элементы («сверху-вниз»). Модульное программирование основано на понятии модуля – логически взаимосвязанной совокупности функциональных элементов, оформленных в виде отдельных программных модулей. Структурное программирование состоит в получении правильной программы из некоторых простых логических структур. Оно базируется на строго доказанной теореме о структурировании, которая утверждает, что любую правильную программу можно написать с использованием только следующих основных логических структур: · линейной (следование); представляет собой естественный ход выполнения алгоритма — любую последовательность операторов, выполняющихся друг за другом. · нелинейной (развилка); представляет фактор принятия решения, включает проверку некоторого логического условия Р и, в зависимости от результатов этой проверки, выполнение оператора S1 либо оператора S2. · циклической (цикл, или повторение). представляет фактор повторяемости вычислений, обеспечивает многократное повторение выполнения оператора S, пока выполняется (истинно) логическое условие, реализуется оператором while… do Каждая из структур может рассматриваться как один функциональный блок с одним входом и одним выходом. Таким образом, можно ввести преобразование любой структуры в функциональный блок. 15 Операторы в структурном программировании Структурные операторы представляют собой совокупности нескольких операторов. К ним относятся: - составной оператор; - операторы цикла; - условный оператор; - оператор варианта; - оператор присоединения. Составным оператором называется последовательность операторов, ограниченных ключевыми словами Begin и End ; Основное назначение составных операторов – обеспечить возможность писать программы по современной технологии структурного программирования – без оператора GOTO. Условный оператор предназначен для оформления конструкции "Развилка" структурного программирования. If < условие > Then <оператор 1> Else <оператор 2> ;. Здесь If (если), Then (тогда), Else (иначе) – зарезервированные слова; Условный оператор реализует следующий алгоритм. Сначала вычисляется условное выражеие < условие > . Если результат равен True, то выполняется <оператор 1> (<оператор 2> пропускается); если результат есть False то выполняется <оператор 2> (<оператор 1> пропускается. Цикл с предусловием, конструкция While. В алгоритмах возможны две конструкции циклических процессов: циклы с предусловием и циклы с постусловием. Для оформления таких конструкций в ТР есть соответствующие операторы, причем для цикла с предусловием предусмотрено два вида цикла: цикл While и цикл For. Форма записи цикла While имеет вид: While < условие > do < оператор >; Оператор присваивания. Этот оператор предназначен для задания значений переменным. Форма записи А : = В; где А – простая переменная, переменная с индексами или имя массива. 16 Обработка исключений Обработка исключений — это работа блока(ов) catch. Ключевое слово catch используется для определения блока кода, который обрабатывает исключения определенного типа данных. Блоки try и catch работают вместе. Блок try обнаруживает любые исключения, которые были выброшены в нем, и направляет их в соответствующий блок catch для обработки. Блок try должен иметь, по крайней мере, один блок catch, который находится сразу же за ним, но также может иметь и несколько блоков catch, размещенных последовательно. Как только исключение было поймано блоком try и направлено в блок catch для обработки, оно считается обработанным и выполнение программы возобновляется. Параметры catch работают так же, как и параметры функции, причем параметры одного блока catch могут быть доступны и в другом блоке catch (который находится за ним). Исключения фундаментальных типов данных могут быть пойманы по значению, но исключения не фундаментальных типов данных должны быть пойманы по константной ссылке, дабы избежать ненужного копирования. Как и в случае с функциями, если параметр не используется в блоке catch, то имя переменной можно не указывать. 17) Процедурное программирование Процедурное программирование – это программирование, в котором отражен фон Неймановской архитектуры компьютера. Все программы, написанные на данном языке, являют собой определенную последовательность команд, которые устанавливают некий алгоритм для разрешения того или иного пакета задач. Самой важной командой является операция присвоения, что предназначена для установления и корректировки содержимого в памяти компьютера главная идея данного языка? Основная особенность процедурных языков программирования заключается в применении памяти компьютера для сбережения информации. Функционирование программы сводится к постоянному и поочередному выполнению разных команд с целью трансформировать содержимое памяти, изменить его исходное состояние и привести к необходимым результатам. Процедурное программирование началось с создания языка высокого уровня под названием Фортран. Его создали в начале пятидесятых годов в США фирма IBM. Первые публикации о нем появились только в 1954 году. Процедурно-ориентированный язык программирования Фортран была разработан для выполнения научно-технических задач. Главными объектами языка выступают числовые переменные, вещественные и целые числа. Все выражения строятся на четырех главных арифметических вычислениях: возведение в степень, операции отношения, круглых скобок, логические манипуляции И, НЕ, ИЛИ. – Главными операторами языка выступают вывод, ввод, переход (условный, безусловный), вызов подпрограмм, циклы, присваивание. Процедурное программирование на языке Фортран очень долгое время был самым востребованным в мире. За время существования языка была накоплена огромнейшая база разных библиотек, программ, что были написаны именно на Фортране. Сейчас все еще ведутся работы над введением очередного стандарта Фортрана. В 2000 году была разработана версия Фортран F2k, у которого стандартная версия называется HPF. Она была создана для параллельных суперкомпьютеров. К слову, в языках PL-1 и Бейсик использованы многие стандарты именно с Фортраны. СУЩЕСТВУЮТ ЯЗЫКИ : Кабол, Алгол ,Бейсик, ПЛ/1, Паскаль Язык С. 18)Статистическая и динамическая типизация. Явные и неявные типы данных Тип — это коллекция возможных значений. Целое число может обладать значениями 0, 1, 2, 3 и так далее. Булево может быть истиной или ложью. Можно придумать свой тип, например, тип "ДайПять", в котором возможны значения "дай" и "5", и больше ничего. Это не строка и не число, это новый, отдельный тип. Статически типизированные языки Статические языки проверяют типы в программе во время компиляции, еще до запуска программы. Любая программа, в которой типы нарушают правила языка, считается некорректной. Например, большинство статических языков отклонит выражение "a" + 1 (язык Си — это исключение из этого правила). Компилятор знает, что "a" — это строка, а 1 — это целое число, и что + работает только когда левая и правая часть относятся к одному типу. Так что ему не нужно запускать программу чтобы понять, что существует проблема. Каждое выражение в статически типизированном языке относится к определенному типу, который можно определить без запуска кода. Многие статически типизированные языки требуют обозначать тип. Функция в Java public int add(int x, int y) принимает два целых числа и возвращает третье целое число. Другие статически типизированные языки могут определить тип автоматически. Та же самая функция сложения в Haskell выглядит так: add x y = x + y. Мы не сообщаем языку типы, но он может определить их сам, потому что знает, что + работает только на числах, так что x и y должны быть числами, значит функция add принимает два числа как аргументы. Это не уменьшает "статичность" системы типов. Система типов в Haskell знаменита своей статичностью, строгостью и мощностью, и в по всем этим фронтам Haskell опережает Java. Динамически типизированные языки Динамически типизированные языки не требуют указывать тип, но и не определяют его сами. Типы переменных неизвестны до того момента, когда у них есть конкретные значения при запуске. Например, функция в Python def f(x, y): return x + y может складывать два целых числа, склеивать строки, списки и так далее, и мы не можем понять, что именно происходит, пока не запустим программу. Возможно, в какой-то момент функцию f вызовут с двумя строками, и с двумя числами в другой момент. В таком случае x и y будут содержать значения разных типов в разное время. Поэтому говорят, что значения в динамических языках обладают типом, но переменные и функции — нет. Значение 1 это определенно integer, но x и y могут быть чем угодно. явная и неявнаяЕщё типизацию делят на явную и неявную. Когда типизация неявная, тип определяется сам в момент, когда вы записываете в переменную информацию. Например, если в Python написать так: b = 8 Он прочитает, что вы записали в переменную b целое число, и определит b как integer (int). Явная типизация значит, что тип переменной написан. Например, в С переменная записывается вот так: int b = 8; Само по себе разделение типизации на явную и неявную не столь важно: в статически типизированных языках она почти всегда явная, а в динамически — неявная. Слабая и сильнаяЕсли у языка сильная типизация (её ещё называют строгой), это значит, что он требует, чтобы разработчики строго следовали правилам работы с типами: если вы обозначили что-то как целое число, будьте добры с ним работать как с целым числом. Языки со слабой типизацией «добрее»: если вы решите прибавить число к тексту, они не будут ругаться, а попробуют сделать то, что вы просите. Правда, результат может быть не совсем таким, как вы планировали. Пример В JavaScript, языке со слабой типизацией, можно сложить строку с числом, например вот так 2+1 и получить строку 21 А в Java так сделать нельзя: появится ошибка 19)Простые типы данных Данные простого типа – это символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных. Числовые типы.Значениями переменных таких типов являются числа. К ним могут применяться обычные арифметические операции, операции сравнения (в результате получается логическое значение). Принципиально различны в компьютерном представлении целые и вещественные типы. Целочисленные типы данных делятся, в свою очередь, на знаковые и беззнаковые. Целочисленные со знаком могут принимать как положительные, так и отрицательные значения, а беззнаковые — только неотрицательные значения. Диапазон значений при этом определяется количеством разрядов, отводимых на представление конкретного типа в памяти компьютера (см. “Представление чисел”). Вещественные типы бывают: с фиксированной точкой, то есть хранятся знак и цифры целой и дробной частей (в настоящее время в языках программирования реализуются редко), и с плавающей точкой, то есть число приводится к виду m х 2e, где m — мантисса, а e — порядок числа, причем 1/2 Символьный тип. Элемент этого типа хранит один символ. При этом могут использоваться различные кодировки, которые определяют, какому коду (двоичному числу) какой символ (знак) соответствует. К значениям этого типа могут применяться операции сравнения (в результате получается логическое значение). Символы считаются упорядоченными согласно своим кодам (номерам в кодовой таблице). Логический тип. Данные этого типа имеют два значения: истина (true) и ложь (false). К ним могут применяться логические операции. Используется в условных выражениях, операторах ветвления и циклах. В некоторых языках, например С, является подтипом числового типа, при этом ложь = 0, истина = 1 (или истинным считается любое значение, отличное от нуля). Перечислимый тип. Отражает самый прямолинейный способ описания простого типа — перечисление всех значений, относящихся к этому типу. Каждая константа такого типа получает свой порядковый номер, что позволяет реализовать ряд простых операций над этим типом, таких, как получить следующее по порядку значение данного типа. Множество как тип данных в основном совпадает с обычным математическим понятием множества. Допустимы стандартные операции с множествами и проверка на принадлежность элемента множеству. В некоторых языках рассматривается как составной тип (массив логических значений, i-й элемент которого указывает, находится ли i в множестве), однако эффективней реализовывать множество как машинное слово (или несколько слов), каждый бит которого характеризует наличие соответствующего элемента в множестве. Указатель (тип данных). Если описанные выше типы данных представляли какие-либо объекты реального мира, то указатели представляют объекты компьютерного мира, то есть являются исключительно компьютерными терминами. Переменная-указатель хранит адрес в памяти компьютера, указывающий на какую-либо информацию, как правило — на другую переменную. 20)Целые числа в языках программирования Целое (тип данных) Целое, целочисленныйтипданных (англ. Integer), в информатике — один из простейших и самых распространённых типов данных в языках программирования. Служит для представления целых чисел. Множество чисел этого типа представляет собой подмножество бесконечного множества целых чисел, ограниченное максимальным и минимальным значениями. Если используется 32-разрядное машинное слово, то целое со знаком будет представлять значения от -2 147 483 648 (-231) до 2 147 483 647 (231-1); всего FFFF FFFF16 возможных значений. В памяти типовой компьютерной системы целое число представлено в виде цепочки битов фиксированного (кратного 8) размера. Эта последовательность нолей и единиц — ни что иное, как двоичная запись числа, поскольку обычно для представления чисел в современной компьютерной технике используется позиционный двоичный код. Диапазон целых чисел, как правило, определяется количеством байтов в памяти компьютера, отводимых под одну переменную. Многие языки программирования предлагают выбор между короткими (англ. short), длинными (англ. long) и целыми стандартной длины. Длина стандартногоцелоготипа, как правило, совпадает с размером машинного слова на целевой платформе. Для 16-разрядных операционных систем - этот тип (int) составляет 2 байта и совпадает с типом short int (можно использовать как short, опуская слово int), для 32-разрядных операционных систем он будет равен 4 байтам и совпадает с длинным целым long int (можно использовать как long, опуская слово int), и в этом случае будет составлять 4 байта. Короткое целое short int, для 16-разрядных операционных систем, 32-разрядных операционных систем, 64-разрядных операционных систем составляет — 2 байта. Также в некоторых языках может использоваться тип данных двойное длинное long long, который составляет 8 байт. Для 64-разрядных операционных систем учитывая разность моделей данных (LP64, LLP64, ILP64), представление целого типа на разных моделях данных может отличаться между собой. Тип int и long может составлять как 4 так и 8 байт. Стоит отметить, что каждый язык программирования реализует свою сигнатуру представления целых чисел, которая может отличатся от международных стандартов, но обязана его/их поддерживать. К примеру можно отнести кросс-платформенную библиотеку Qt, где целое представляется типом qintX и quintX, где X-8,16,32,64. Целые типы подразделяются на беззнаковые (англ. unsigned) и знаковые (англ. signed). Беззнаковые целыеБеззнаковые целые представляют только неотрицательные числа, при этом все разряды кода используются для представления значения числа и максимальное число соответствует единичным значениям кода во всех разрядах: 111...111. m-байтовая переменная целого типа без знака, очевидно, принимает значения от 0 до +28m-1. В C и C++ для обозначения беззнаковых типов используется префикс unsigned. В C# в качестве показателя беззнаковости используется префикс u (англ. unsigned). Например, для объявления беззнакового целого, равного по размеру одному машинному слову используется тип uint. Беззнаковые целые, в частности, используются для адресации памяти, представления символов. Иногда в литературе[1] встречаются рекомендации не использовать тип беззнаковые целые, поскольку он может быть не реализован процессором компьютера, однако вряд ли этот совет следует считать актуальным — большинство современных процессоров (в том числе x86-совместимые[2]) одинаково хорошо работают как со знаковыми, так и с беззнаковыми целыми. В некоторых языках, например java, беззнаковые целые типы (за исключением символьного) отсутствуют.[3] Неправильное использование беззнаковых целых может приводить к неочевидным ошибкам из-за возникающего переполнения[4]. В приведённом ниже примере использование беззнаковых целых в цикле в C и C++ превращает этот цикл в бесконечный: char ar[N]; for (unsigned int i = N-1; i >= 0; --i) ar[i] = i; Целые со знакомСуществует несколько различных способов представления целых значений в двоичном коде в виде величины со знаком (англ.)русск.. В частности можно назвать прямой и обратный коды. Знак кодируется в старшем разряде числа: 0 соответствует положительным, а 1 отрицательным числам. Могут быть использованы и более экзотические представления отрицательных чисел, такие, как, например, система счисления по основанию -2.[5] Однако для большинства современных процессоров обычным представлением чисел со знаком является дополнительный код. Максимальное положительное число представляется двоичным кодом 0111...111, максимальное по модулю отрицательное кодом 1000...000, а код 111...111 соответствует -1. Такое представление чисел соответствует наиболее простой реализации арифметических логических устройств процессора на логических вентилях и позволяет использовать один и тот же алгоритм сложения и вычитания как для беззнаковых чисел, так и для чисел со знаком (отличие — только в условиях, при которых считается, что наступило арифметическое переполнение). m-байтовая переменная целого типа со знаком принимает значения от −28m-1 до +28m-1-1. Работа со строкамиДовольно частыми операциями являются получение строки из числового значения во внутреннем представлении и обратно — число из строки. При преобразовании в строку обычно доступны средства задания форматирования в зависимости от языка пользователя. Ниже перечислены некоторые из представлений чисел строкой. Десятичноечисло (англ. decimal). При получении строки обычно можно задать разделители разрядов, количество знаков (добавляются лидирующие нули если их меньше) и обязательное указание знака числа. Число в системе счисления, которое является степенью двойки. Самые частые: двоичное (binary англ. binary), восьмиричное (англ. octal) и шестнадцатиричное (англ. hexadecimal). При получении строки обычно можно задать разделители групп цифр и минимальное количество цифр (производится дополнение нулями если их меньше). Так как эти представления чаще всего используются в программировании, то здесь обычно доступны соответствующие опции. Например, указание префикса и постфикса для получения значения в соответствии с синтаксисом языка. Для 16-ричных актуально указание регистра символов, а так же обязательное добавление нуля, если первая цифра представлена буквой (чтобы число не определялось как строковый идентификатор). Римскоечисло (англ. roman). Словесноепредставление (в том числе суммапрописью) — число представляется словами на указанном натуральном языке. |