РГР_Слєпцова_ДА-62. Програмна реалізація методу
 Скачать 145.82 Kb. Скачать 145.82 Kb.
|

4.1 Вирішення проблеми точностіПри кодуванні файлів великого обсягу виникає проблема представлення великого числа стандартними типами даних програмного середовища. Проблема була вирішена без застосування довгої арифметики, оскільки це б викликало значні проблеми зі швидкістю роботи програми. Вхідний файл розбивається на серії байт, які без проблем кодуються стандартним типом double. Таким чином в архів записується набір байт, що зустрічаються, та відповідні їм проміжки на інтервалі  , число біт в останньому байті, а також набір зашифрованих чисел [9]. , число біт в останньому байті, а також набір зашифрованих чисел [9].4.2 Використання адаптивного арифметичного кодуванняОскільки на практиці алгоритм арифметичного кодування застосовується для кодування файлів великого розміру, то виникають проблеми, пов’язані з точністю розрахунків та швидкодії програми. Для вирішення таких проблем використовують адаптивне арифметичне кодування (ідея описана у пункті 2.3.). При програмній реалізації алгоритму маємо справу з скінченною розрядною сіткою, тому в результаті виконання будь-яких арифметичних операцій над числами, бітове представлення яких містить досить велику кількість розрядів, призводить до накопичення похибки. Результатом є неправильна та неоднозначна робота алгоритму. А також це тягне за собою іншу проблему, пов’язану з тим, що операції над такими числами потребують часу, що призводить до значного погіршення швидкості роботи. Ідея вирішення цієї проблеми полягає в тому, щоб при кожному обчисленні границь проміжків Low та High (змінну High необхідно записати як максимально наближене до обчисленого числа значення) виконувати зсув ліворуч на один розряд та зберігати крайній лівий розряд (значущий), якщо він співпадає в обох змінних. На наступному кроці необхідно додати нульовий крайній правий розряд для змінної Low та крайній правий розряд для змінної High із числом 9. На останньому кроці отримаємо код у вигляді всіх накопичених значущих цифр + значення змінної Low на останньому кроці. Отримали результуючий код обмеженої довжини, який дозволяє декодеру однозначно відновити закодовану послідовність. 5. Реалізація обраного алгоритму 5.1 Особливості реалізаціїПрограма реалізована на основі класичного арифметичного кодування.класичний алгоритм є двопрохідним. Перший прохід для аналізу вхідних данних, тобто створення ймовірнісної таблиці, другий для, власне, самого кодування. Вся програма написана в одному файлі. Кількість біт ми задаємо за допомогою константи BITS_IN_REGISTER, максимальне можливе значення - TOP_VALUE (((long) 1 << BITS_IN_REGISTER) - 1). Ми працюємо в діапазонах FIRST_QTR (TOP_VALUE / 4 + 1),HALF (2 * FIRST_QTR), THIRD_QTR (3 * FIRST_QTR) відповідно. Кількість символів алфавіту дорівнює 256 (CountChars). Кінець файлу ми знаходимо як EOF_Symbol (CountChars + 1). Всього ж символів у нас CountChars + 1. Межею частоти (MAX_FREQUENCY) є 16383. Змінні межі lowLimit, highLimit. Є ряд побітових операцій з файлами bits_to_follow, buffer, bits_to_go, garbage_bits. Оскільки програма потребує дуже точних значень, відповідно треба обережно працювати з досить малими числами. Ініціалізуємо адаптивну модель start_model. Обновлюємо модель update_model. Для цього перевіряємо на переповнення лічильник частоти. Масштабуємо частоти при переповненні. Обновлюємо значення частот в таблиці. Для ініціалізації побітового введення start_inputing_bits приймаємо, що bits_to_go = 0, garbage_bits = 0. Функція введення біта input_bit. Ініціалізуємо побітове виведення start_outputing_bits. Приймаємо, що buffer = 0, bits_to_go = 8. Функція виведення біта output_bit. Далі ініціалізуємо межі start_encoding. Ініціалізуємо регістри перед декодуванням. Завантаження початку стиснутого повідомлення start_decoding. Кодуємо символ за допомогою функції encode_Symbol. Для цього перераховуємо значення меж. Висуваємо чергові біти. Далі зсуваємо вліво зі втягуванням чергового біта. Функція декодування decode_Symbol. За її допомогою ми визначаємо поточний масштаб частот, масштабуємо значення в регістрі. Шукаємо відповідний символ в таблиці. Перераховуємо межі. Видаляємо черговий символ зі вхідного потоку. В main містяться функції кодування і декодування. Зчитуємо і записуємо у файл. 5.1.1 Інтерфейс програми 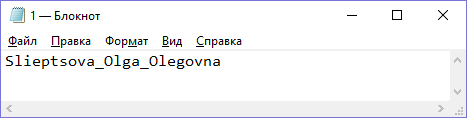 Рис 5.1 – Вхідні дані 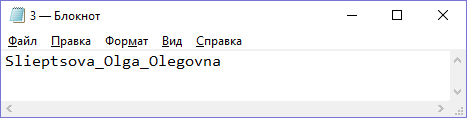 Рисунок 5.2 – Вихідні дані 5.2 Блок-схема алгоритму 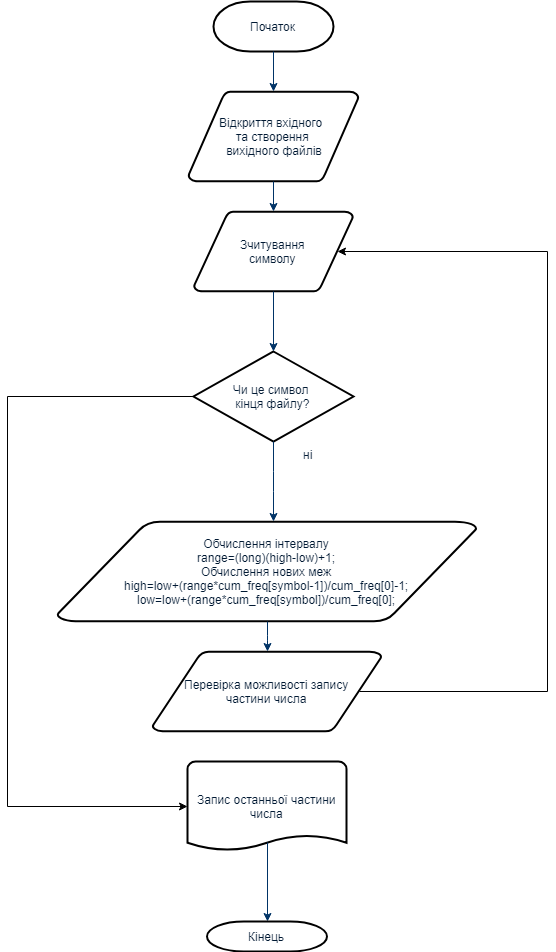 5.3 Результати архівування
Для перевірки ефективності роботи програми були використані файли різних типів, що містили інформацію, що мала різне представлення (кодування). Було досліджено наступні типи фалів: Текстовий файл Документ Microsoft Office Word Мультимедійний файл MP3 Файл DJVU Виконуваний файл PNG 5.4 Порівняння з типовими архіваторами WinRAR та 7-ZIP
6. ВИСНОВКИ При виконанні розрахунково-графічної роботи було розглянуто метод арифметичного кодування інформації. Було описано принцип його дії, а також обґрунтовано доцільність його застосування, до яка базується на понятті ентропії повідомлення У процесі виконання було розроблено програму, що реалізує архівування даних та їх подальше розархівування за алгоритмом арифметичного стиснення. Було виконано ряд тестів, згідно з якими найбільш ефективним алгоритм арифметичного стискання є при обробці файлів з низькою ентропією. Таким чином, арифметичне стиснення належить до групи статистичних методів стиснення інформації (тобто базується на частоті символів в повідомленні). Це один з найбільш ефективних алгоритмів статистичного стиснення, так як середня кількість біт на символ інформації в стислому вигляді має мінімальну різницю з ентропією повідомлення. Арифметичне кодування є майже оптимальним видом кодування, тобто дає коди, майже рівні довжинам оптимальних кодів з теореми Шеннона. Однак така ефективність досягається за рахунок великих обчислювальних витрат. Потрібна для представлення інтервалу [low; high) точність зростає разом з довжиною тексту. Поступове виконання допомагає обійти цю проблему, вимагаючи при цьому уважного врахування можливостей переповнення пам’яті. Тому реалізація алгоритму є дещо обмеженою. В процесі звуження кодового інтервалу, старші біти нижньої та верхньої межі інтервалу стають однаковими, тобто на них подальше звуження інтервалу вже не впливає. При декодуванні немає необхідності знати значення обох меж кінцевого інтервалу, що отриманий при кодуванні. Щоб завершити процес декодування, слід вчасно розпізнати кінець тексту. Для усунення неоднозначності кінець кожного тексту позначають спеціальним символом EOF. Коли зустрічається цей символ, процес декодування припиняється. Щодо ефективності стиснення: Взагалі, при кодування тексту арифметичним методом, кількість бітів в закодованій стpоці pівна ентpопіі цього тексту щодо використаної для кодування моделі. Тpи фактоpи викликають погіршення цієї хаpактеpистики: (1)Витрати на завершення тексту; (2) використання арифметики скінченої точності (хоча й існує модель реалізації з арифметикою безкінечної точності, на практиці нажаль втілити її неможливо, ми лише можемо за рахунок ресурсів комп’ютера збільшити цю точність і відповідно зменшити швидкість виконання) (3) таке масштабування лічильників, щоб їх сума не перевищувала максимальну частоту. Але насправді жоден з них не є дуже значним і дає змогу отримати досить ефективний та швидкий компресор даних. Слід також зауважити, що існують модифікації даного алгоритму, які використовують операції здвигу та суми без ділення та множення. Це дає змогу дуже сильно прискорити компресію даних з меншими затратами на її виконання. А отже ефективні реалізації модифікацій алгоритму арифметичного кодування будуть витісняти алгоритм Хаффмана в сферах, де продуктивність не є критичною вимогою. Але все ж таки арифметичне кодування є кращим якщо задача стоїть в якнайбільшому ступені компресії даних, а не в мінімізації затрат на цю саму компресію. 7 СПИСОК ВИКОРИСТАНОЇ ЛІТЕРАТУРИ:
8. Лістинг програми #include <stdio.h> // Количество битов #define BITS_IN_REGISTER 16 // Максимально возможное значение #define TOP_VALUE (((long) 1 << BITS_IN_REGISTER) - 1) // Диапазоны #define FIRST_QTR (TOP_VALUE / 4 + 1) #define HALF (2 * FIRST_QTR) #define THIRD_QTR (3 * FIRST_QTR) // Количество символов алфавита #define CountChars 256 // КонецФайла #define EOF_Symbol (CountChars + 1) // Всего символов #define NO_OF_SymbolS (CountChars + 1) // Порог частоты #define MAX_FREQUENCY 16383 // Перекодировка unsigned char index_to_char [NO_OF_SymbolS]; int char_to_index [CountChars]; // Таблицы частот int cum_freq [NO_OF_SymbolS + 1]; int freq [NO_OF_SymbolS + 1]; // границы long lowLimit, highLimit; long value; // побитывые операции с файлами long bits_to_follow; int buffer; int bits_to_go; int garbage_bits; FILE *in, *out; //------------------------------------------------------------ // Инициализация адаптивной модели void start_model (void) { int i; for ( i = 0; i < CountChars; i++) { char_to_index [i] = i + 1; index_to_char [i + 1] = i; } for ( i = 0; i <= NO_OF_SymbolS; i++) { freq [i] = 1; cum_freq [i] = NO_OF_SymbolS - i; } freq [0] = 0; } | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||