Разработка информационной системы контроля проезда автотранспорта
 Скачать 3.56 Mb. Скачать 3.56 Mb.
|

1.3. Пути решения поставленных задач и общая схема проведения исследованийРазрабатываемая информационная система контроля проезда автотранспорта является распределенной системой, физически расположенной в двух больших помещениях – на контрольно-пропускном пункте и в администрации. При этом функции, выполняемые на каждом рабочем месте различны. На контрольно-пропускном пункте выполняется регистрация проезда автотранспорта. На рабочих местах администрации выполняется обработка данных о проезде автотранспорта, формируются отчеты о нахождении автотранспорта на территории гаражно-складских помещений и формируются платежные документы на оплату. Режим работы контрольно-пропускного пункта – круглосуточный, администрации – рабочее время с 8.00 по 18.00. Учитывая различные исполняемые функции и необходимость ограничения доступа к данным со стороны контролеров контрольно-пропускного пункта, программное обеспечение на контрольно-пропускном пункте и в администрации должно быть различным, но функционирование должно вестись на основе единой распределенной базы данных. В целях безопасности компьютеры администрации в нерабочее время выключаются, компьютеры на контрольно-пропускном пункте работают круглосуточно. При этом на контрольно-пропускном пункте должна храниться только информация о проездах автотранспорта и не содержать данные о результатах их обработки, формируемых платежных документах и произведенных оплатах. Поэтому необходима разработка распределенной информационной системы, основу которой составляет распределенная база данных, а специальное программное обеспечение разрабатывается отдельно для контрольно-пропускного пункта и администрации гаражно-складских помещений. Разработка распределенной информационной системы включает следующие этапы. 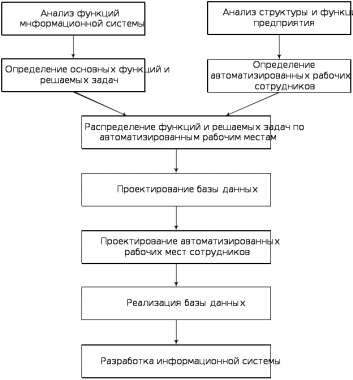 Рисунок 1.6 – Этапы разработки информационной системы предприятия Одним из основных и самых сложных является проектирование и разработка распределенной базы данных, эффективность которой во многом влияет на эффективность функционирования всей информационной системы. В отличие от централизованных, специфика проектирования распределенных баз данных (РБД) состоит в необходимости учитывать не только объекты и связи предметной области, но и ряд других факторов, касающихся условий функционирования РБД, таких как, порядок решения задач, информационные потребности задач, частота обращения к данным на различных узлах ИВС и т.д. Один из ключевых принципов проектирования РБД состоит в максимальной локализации данных и прикладных задач их использующих. Этот принцип основывается на том, что, во-первых, физически скорость доступа к данным с удаленного узла ИВС всегда ниже скорости доступа к данным на своем (локальном) узле, во-вторых, в территориально распределенных информационных сетях надежность доступа к данным на локальном узле несоизмеримо выше надежности удаленного доступа по сети к данным, хранящимся на других узлах, особенно, если узлы размещаются в разных зданиях. Поэтому, несмотря на то, что современные системы управления базами данных (СУБД) обеспечивают наиболее развитую связь между узлами сети, основной целью проектирования РБД является сокращение количества этих связей за счет по возможности наиболее близкого расположения данных к прикладным задачам, их использующим. Однако на практике редко удается разграничить данные и прикладные задачи, приписываемые строго определенному узлу сети. Как правило, разработчик сталкивается с ситуацией, когда одни и те же данные необходимы на различных узлах сети. Поэтому считается, что в хорошо спроектированной РБД "90% используемых данных должны находиться в локальном узле и только 10% - в удаленном". Данное эвристическое правило не может являться строгой количественной оценкой качества РБД, а показывает только общую тенденцию к максимальной локализации, которой необходимо придерживаться при проектировании РБД для обеспечения максимальной эффективности обработки данных. Необходимость согласования структуры РБД и решаемых задач приводит к необходимости изменения не только размещения таблиц, но и их структуры. В связи с этим, проектирование распределенной структуры целесообразно разбивать на два шага: фрагментация таблиц БД в зависимости от их применяемости прикладными задачами; размещение полученных фрагментов таблиц по узлам сети в соответствии с правилом максимальной локализации и ограничениями, налагаемыми требованиями к РБД. Фрагментация есть процесс разбиения таблицы на несколько частей. Цель фрагментации состоит в выделении фрагментов, потенциально обладающих свойством максимальной локальности относительно выполняемых над ними операций. Это значит, что каждый фрагмент размещается там, где чаще всего используется. После размещения по узлам ИВС фрагменты таблиц рассматриваются как самостоятельные таблицы РБД. В ряде случаев фрагментация таблиц может привести к дополнительным издержкам, заключающимся в необходимости выполнения дополнительных операций соединения таблиц при одновременной потребности в данных, хранящихся в различных фрагментах. Поэтому, следует предусматривать возможность отказа от фрагментации тех или иных объектов, если издержки фрагментации не компенсируются преимуществами локальной обработки. Размещение - это процесс отображения каждого фрагмента таблицы в один или более узлов ИВС. Фрагменты являются неделимыми размещаемыми единицами, поэтому разработчики баз данных в качестве фрагментов должны выбирать блоки информации, однородные с точки зрения доступа к ним, т.е. все экземпляры одного фрагмента должны быть равнодоступны. Размещение таблиц РБД может быть избыточным или без избыточным. При безызбыточном размещении каждый фрагмент отображается точно в один узел ИВС. При избыточном размещении каждый фрагмент отображается в один или более узлов. Безызбыточное размещение позволяет значительно упростить хранение и обработку информации в ИВС. Однако, низкая степень надежности (при выходе из строя любого узла ИВС теряется хранимая на нем информация) и увеличение времени функционирования РБД (за счет увеличения затрат на удаленный доступ к данным, хранящимся на других узлах ИВС) делают применение без избыточного способа размещения данных неприемлемым для большинства ИСС. Таким образом, при разработке РБД фрагменты данных должны распределяться по узлам ИВС с некоторой степенью избыточности. В связи с тем, что информационные потребности для разных данных различны, то количество размещаемых копий целесообразно определять для каждой таблицы отдельно. Выгоды, получаемые от дублирования фрагментов, прямо пропорциональны соотношению объемов операций считывания данных (большее количество данных размещается в локальных узлах считывания) и обратно пропорциональны объемам операций их обновления (поддержание непротиворечивости базы данных требует распространения корректур на все копии обновляемых фрагментов). При этом, дублирование повышает устойчивость системы против отказов, так как: - независимая потеря нескольких копий той же информации маловероятна; - в случае потери локальных копий данных в системе могут использоваться другие копии. Таким образом, при проектировании распределенной структуры БД разработчик должен решить следующие задачи: 1) для каждой таблицы БД провести фрагментацию в соответствии с информационной потребностью решаемых на узлах ИВС задач; 2) определить целесообразное количество копий каждого фрагмента данных; 3) провести размещение фрагментов данных по узлам ИВС. Наиболее развитой и полной из известных является методология проектирования РБД DATA-ID, разработанная в Миланском политехническом институте, которая, в отличие от остальных известных методов, содержит полный цикл проектирования РБД. Однако, как показал анализ, методология DATA-ID дает только общие направления проектирования РБД и ее непосредственное применение затруднительно по следующим причинам: - выполнение этапов проектирования распределенной структуры выполняется на основе эвристических алгоритмов и общих рекомендаций, что значительно затрудняет ее проектирование, снижает обоснованность выбранного варианта и повышает вероятность получения нерационального варианта структуры РБД; - при распределении данных учитывается только локальность данных по отношению к прикладным задачам, и не рассматриваются вопросы обеспечения надежности функционирования РБД; - не определены показатели эффективности функционирования РБД, что делает невозможным оценку РБД и сравнение различных вариантов ее построения. Поэтому в данной работе предлагается адаптировать существующие методы проектирования РБД к решению поставленной задачи и провести их апробацию на примере разработки информационной системы контроля проезда автотранспорта. Одним из основных направлений решения задач проектирования есть разбиение общей задачи на последовательность частных задач с целью сокращения размерности решаемых задач на каждом этапе. В работе для решения задачи предлагается процесс проектирования РБД разбить на ряд этапов, приведенных на технологической схеме, что позволяет сократить размерность задачи путем последовательной оптимизации параметров РБД на каждом этапе.  Рис. 1.7 – Этапы проектирования распределенной базы данных |