Магистерская диссертация. 1Магистр. Разработка рекомендательной системы для выбора инвестиционных инструментов
 Скачать 0.74 Mb. Скачать 0.74 Mb.
|

|
3.1 Компоненты и структура проекта Компьютерная эра привнесла новый элемент в бизнес, университеты и множество других организаций: набор компонентов, называемый информационной системой, которая занимается сбором и организацией данных и информации. Информационная система описывается как состоящая из пяти компонентов. Компьютерное железо – это физическая технология, которая работает с информацией. Аппаратное обеспечение может быть маленьким, как смартфон, который помещается в карман, или большим, как суперкомпьютер, заполняющий здание. Аппаратное обеспечение также включает периферийные устройства, которые работают с компьютерами, такие как клавиатуры, внешние дисковые накопители и маршрутизаторы. С появлением Интернета вещей, в котором все, от бытовой техники до автомобилей и одежды, сможет получать и передавать данные, датчики, взаимодействующие с компьютерами, проникают в человеческую среду. Компьютерное программное обеспечение – благодаря ему аппаратное обеспечение должно знать, что делать, и в этом заключается роль программного обеспечения. Программное обеспечение можно разделить на два типа: системное программное обеспечение и прикладное программное обеспечение. Основной частью системного программного обеспечения является операционная система, такая как Windows или iOS, которая управляет работой оборудования. Прикладное программное обеспечение предназначено для конкретных задач, таких как работа с электронной таблицей, создание документа или разработка веб- страницы. Телекоммуникации – этот компонент соединяет оборудование вместе, чтобы сформировать сеть. Соединения могут быть проводными, такими как кабели Ethernet или оптоволокно, или беспроводными, например, через Wi-Fi. Сеть может быть спроектирована так, чтобы связать компьютеры в определенной области, например, в офисе или школе, через локальную сеть (LAN). Если компьютеры более рассредоточены, сеть называется глобальной сетью (WAN). Сам Интернет можно рассматривать как сеть сетей. Базы данных и хранилища данных – в этом компоненте находится «материал», с которым работают другие компоненты. База данных – это место, где собираются данные и откуда их можно извлечь, запросив их с использованием одного или нескольких определенных критериев. Хранилище данных содержит все данные в любой форме, необходимой организации. Базы данных и хранилища данных приобрели еще большее значение в информационных системах с появлением «больших данных» — термина, обозначающего поистине огромные объемы данных, которые можно собирать и анализировать. Человеческие ресурсы и процедуры – последним и, возможно, самым важным компонентом информационных систем является человеческий фактор: люди, необходимые для работы системы, и процедуры, которым они следуют, чтобы знания, содержащиеся в огромных базах данных и хранилищах данных, можно было превратить в знания, которые можно интерпретировать, что произошло в прошлом и направлять будущие действия. В этом списке основным термином является алгоритм, который, как и большинство общих понятий, имеет множество определений. например: Алгоритм – это конечный набор правил, который определяет последовательность операций для решения определенного набора задач и имеет пять важных характеристик: конечность, определенность, ввод, вывод, эффективность. Алгоритм – это точная инструкция, которая определяет вычислительный процесс, который варьируется от различных исходных данных до желаемого результата. В общем, алгоритм – это уникальное описание порядка (последовательности) выполнения действий из определенного набора, которое позволяет получить желаемый результат за конечное количество шагов. Мы можем сказать, что компьютерная программа - это способ реализации концепции алгоритма, а язык программирования - это инструмент для описания алгоритмов. Однако определение алгоритма не говорит о том, с чем выполняются действия, выполняемые в нем. В принципе, это могут быть управляемые объекты внешней среды, но они также являются частью концепции алгоритма (рис.4). 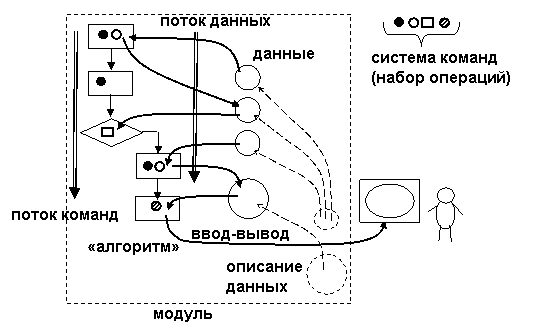 Рисунок 4 – Структурная схема компьютерной программы Компьютерная программа, в отличие от абстрактного алгоритма, имеет свои собственные элементы, над которыми она выполняет действия и которые являются ее составной частью. Таким образом, это замкнутая система, отделенная от внешней среды. Давайте посмотрим, из каких частей все еще состоит компьютерная программа. Все они должны быть выражены в соответствующих компонентах языка программирования: прежде всего, программа работает не с пользователем, а с данными. Этим первым и основным компонентом программы являются объекты (объекты), с помощью которых реализуется алгоритм. Данные состоят из отдельных переменных, которые связаны как напрямую (через указатели), так и косвенно (оба ввода являются результатом); на языке программирования существуют инструменты описания данных, которые позволяют программисту разрабатывать различные формы их представления - типы данных; программа основана на ряде операций (командной системе), которые могут выполняться с данными. Этот набор включает в себя арифметические операции, назначение (сохранение результата в переменной), ввод-вывод, проверку значения переменной и т. д.; вторым основным компонентом программы является описание последовательности, последовательности выполняемых действий, которое также называется алгоритмом в более узком смысле или алгоритмическим компонентом. Обычно он состоит из двух частей. Первая часть - выражения, представляет собой описание линейной последовательности выполнения простейших действий из ряда операций (арифметических операций, назначений, условных выражений). Они включены во второй компонент - операторы, которые задают определенную последовательность действий; как уже упоминалось, программа работает исключительно с данными, что определяет суть алгоритма. Набор действий содержит команды ввода-вывода, которые обмениваются данными между переменной и внешней средой (через устройства ввода-вывода). С "программно-эгоцентрической" точки зрения это выглядит чистой формальностью и не является неотъемлемой частью программы; Каждая программа запускается на компьютере. Давайте посмотрим, как компоненты программы и компьютерной архитектуры коррелируют друг с другом: компоненты программы находятся в памяти. По сути, память является общей для всех вас, но логически она разделена на области, называемые сегментами. Прежде всего, это сегмент данных, который, конечно же, содержит данные программы. Алгоритмический компонент (выражения, операторы) также находится в памяти в собственном сегменте команд; одновременное хранение "алгоритма" и данных соответствует принципу хранимой программы. Перед загрузкой в память те же компоненты находятся в программном файле, который представляет собой точную копию представления программы в памяти «образ памяти». Это позволяет рассматривать всю программу (включая алгоритм) как данные для работы других программ, таких как переводчики; операции, выполняемые в программе, соответствуют командной системе процессора, на котором она выполняется. К ним также относятся команды, которые предоставляют процедуру (операторы), заданную в программе. Наконец, язык программирования также содержит компоненты, предназначенные для описания соответствующих частей программы: инструменты определения данных: определение типов данных (формы представления) и переменных; набор операций для основных типов данных (включая ввод-вывод) и сборщиков выражений; набор операторов, которые определяют различные параметры порядка выполнения выражений в программе (последовательность, условие, повтор, блок); разделение программ на независимые части - модули (функции, процедуры), которые взаимодействуют друг с другом через программные интерфейсы. Определение программы уже давно дается в простой формуле: «программа = алгоритм + данные». Но в нем алгоритм и данные не просто «складываются» в целое как независимые части, а являются двумя взаимозависимыми элементами. Теперь приступим к более подробному рассмотрению алгоритма. 3.2 Фрагменты кода реализации Когда дело доходит до принятия правильных решений, слишком сильно полагаться на автоматические решения, основанные на восприятии, или слишком сильно полагаться на условности, когда информация обрушивается на нас со всех сторон, может быть опасно. Иногда вы не замечаете или не ищете важную информацию, которая поддерживает принятие решений. Это может быть из-за нашей предвзятости или нехватки времени, средств и других ресурсов. Однако, когда дело доходит до принятия организационных решений, возможно, вы не захотите рисковать. Причины очевидны. Одно неверное решение может испортить многие вещи, включая имидж вашего бренда, жизненный цикл продукта, финансовое положение и бренд работодателя. Во многих ситуациях вы не можете применить основы экономики, статистики и исследования операций, чтобы сделать осознанный выбор. Рассмотрим системы, основанные на знаниях, которые поддерживают деятельность по принятию бизнес-решений. Здесь на помощь приходит система поддержки принятия решений. Это компьютеризированная система, которая помогает вам принимать решения по планированию, производству, эксплуатации и управлению на основе доступной информации. Но мы должны помнить, что эти системы не являются лицами, принимающими решения. Они просто помогают в принятии решений, предлагая информацию, которую пользователь может упустить, и обеспечивая точные расчеты. Окончательное решение принимает пользователь. Теперь, когда мы знаем, что делает система поддержки принятия решений, давайте разберемся, что это такое и как она работает. Система поддержки принятия решений – это компьютерное приложение или программа, которая собирает, объединяет и анализирует необработанные данные, документы, основы социальных наук, прикладных наук, математики и управленческих наук, а также личные знания (лиц, принимающих решения) и может выявить проблемы и найти пути их решения для облегчения принятия оптимальных решений. Система поддержки принятия решений – это интерактивное компьютерное приложение, имеющее полный доступ к информации о вашей организации. При использовании он предлагает сравнительные данные между одним периодом и следующим. Он прогнозирует показатели выручки на основе предположений, связанных с продажами продукции. DSS достаточно умен, чтобы помочь вам понять расходы и последствия, возникающие в результате различных альтернативных решений. Система поддержки принятия решений помогает преодолеть барьеры на пути к принятию правильных решений, в том числе: отсутствие опыта; предвзятость; нехватка времени; неверные расчеты; не рассматривая альтернативы. Путь системы поддержки принятия решений начался в конце 1960-х годов с DSS на основе моделей. В 1970-х годах в этой области развивалась теория, и именно в середине 1980-х годов произошло внедрение DSS на основе электронных таблиц, систем финансового планирования и Group DSS. В конце 19080-х и начале 1990-х годов произошла эволюция бизнес-аналитики, хранилищ данных, ODSS (Система поддержки принятия организационных решений) и EIS (Информационная система для руководителей). Середина 1990-х ознаменовала начало систем поддержки принятия решений, основанных на знаниях и в Интернете. Системы поддержки принятия решений можно разделить на следующие категории: DSS на основе модели – модельно-ориентированный DSS был основан на простых количественных моделях. Он использовал ограниченные данные и делал упор на манипулирование финансовыми моделями. Модельно-ориентированная DSS использовалась при планировании производства, составлении графиков и управлении. Он обеспечивал самые элементарные функциональные возможности для производственных предприятий. DSS на основе данных – DSS, управляемый данными, делал упор на доступ и манипулирование данными, предназначенными для конкретных задач, с использованием общих инструментов. Хотя он также предоставлял элементарную функциональность для бизнеса, он в значительной степени полагался на данные временных рядов. Он смог поддержать принятие решений в ряде ситуаций. Коммуникационный DSS – как следует из названия, коммуникационная DSS использует коммуникационные и сетевые технологии для облегчения принятия решений. Основное различие между этим и предыдущими классами DSS заключалось в том, что он поддерживал совместную работу и общение. Он использовал различные инструменты, включая компьютерные доски объявлений, аудио- и видеоконференции. DSS на основе документов – DSS, управляемая документами, использует большие базы данных документов, в которых хранятся документы, изображения, звуки, видео и гипертекстовые документы. Он имеет основной инструмент поисковой системы, связанный с поиском данных, когда это необходимо. Сохраняемая информация может представлять собой факты и цифры, исторические данные, протоколы совещаний, каталоги, деловую переписку, спецификации продуктов и т. д. DSS, основанная на знаниях – DSS, основанные на знаниях, – это человеко-компьютерные системы, обладающие опытом решения проблем. Они сочетают искусственный интеллект с когнитивными способностями человека и могут предлагать действия пользователям. Примечательным моментом является то, что эти системы имеют опыт работы в определенной области. Веб-DSS – веб-система DSS считается самой сложной системой поддержки принятия решений, которая расширяет свои возможности за счет использования всемирной сети и Интернета. Эволюция продолжается с развитием интернет-технологий. Раньше основное внимание уделялось ускорению принятия решений; однако по мере развития концепции она перешла к созданию интерактивных компьютерных систем, которые могли бы использовать данные и предлагать идеи для решения плохо структурированных проблем. Определение, дизайн, интеллектуальные возможности и объем DSS продолжают развиваться со временем. Современная DSS более сложна и приспособлена для принятия более сложных решений. Системы поддержки принятия решений приобрели огромную популярность в различных областях, включая военные, безопасность, медицину, производство, проектирование и бизнес. Они могут помочь в принятии решений в ситуациях, когда важна точность. Кроме того, они обеспечивают доступ к соответствующим знаниям, объединяя различные формы и источники информации, способствуя когнитивным нарушениям человека. Хотя DSS использует искусственный интеллект для решения проблем, не следует переоценивать его важность. Это способ получить сравнительные данные на основе некоторых или комбинации некоторых формальных методов. Окончательное решение остается за вами. Мы уже видели классификацию систем поддержки принятия решений на основе используемых технологий в разделе истории. Давайте теперь посмотрим на категоризацию на основе характера операций: Система файловых ящиков: как следует из названия, система поддержки принятия решений файловых ящиков предоставляет информацию, полезную для принятия конкретного решения. Он работает как ящик для файлов, где разные типы информации хранятся под разными именами или категориями. Системы анализа данных –это системы поддержки принятия решений, основанные на формуле; и поэтому используются для сравнительного анализа. Они используют простые инструменты обработки данных, такие как анализ запасов. Система анализа информации. Этот тип системы поддержки принятия решений анализирует различные наборы данных для создания информационных отчетов, которые можно использовать для оценки ситуации для принятия решений. Система бухгалтерского учета и финансовой поддержки: этот тип системы поддержки основан на отслеживании денежных средств и запасов. Представление или модель решателя – этот тип системы выполняет или представляет принятие решений в определенной области или для конкретной проблемы. Он рассчитывает и сравнивает результаты различных путей принятия решений. Лицо, принимающее решение, может провести анализ «что, если» и принять обоснованное решение на основе полученных результатов. Модель оптимизации –этот DSS основан на стимулируемых моделях, в основном предоставляющих рекомендации по управлению операциями. Основное внимание уделяется предоставлению оптимальных решений по планированию работ, ассортименту продукции и решениям по подбору материалов. Система предложений: этот тип системы поддержки предлагает оптимальное решение для конкретной ситуации, помогая собирать и структурировать данные. Категоризация DSS на основе входных данных: Текстовый DSS Ориентированность на базу данных Ориентирован на электронные таблицы Ориентация на правила Решатель (конкретная ситуация) Ориентирован Составная/гибридная: эта система поддержки сочетает в себе две или более структуры, представленные выше, чтобы предложить несколько функций. Классификация DSS на основе предлагаемой поддержки Персональный DSS Группа DSS Организационная СПР Категоризация DSS на основе типа и частоты принятия решений: Институциональный DSS: институциональная система поддержки принятия решений поддерживает повторяющиеся решения на постоянной основе. В основном это запрограммированные решения, которые принимаются ежедневно. Например, установление порядка решения технических проблем, принятие дисциплинарных мер, изготовление единиц, механический процесс устранения неполадок и т. д. Ad-hoc DSS: специальная система поддержки принятия решений поддерживает один тип решения в непредвиденной ситуации. Принятое решение уникально для проблемы. Этот тип системы используется для поддержки незапрограммированных решений, поскольку доступная информация является неполной. Как и любая другая программная система, DSS также имеет компоненты и этапы разработки. Независимо от того, какую систему поддержки принятия решений вы хотите разработать, вы должны планировать эти четыре компонента: Исходные данные: как упоминалось ранее, это может быть правило, проблема, электронная таблица, текст или база данных. Знания/опыт пользователя Результат Решения Многое уходит на разработку и создание системы поддержки принятия решений. Она работает как вспомогательная система только после того, как в процессе своего развития получает подпитку интеллектом. Разработка DSS –сложный процесс, поэтому он занимает больше времени. Он повторяется через три этапа - входы, действия и выходы на каждом этапе жизненного цикла разработки системы. Для этого мы предоставляем входные данные, выполняем желаемую деятельность и измеряем результат. При дальнейшем продвижении система дает правильный результат, или же мы возвращаемся к фазе ввода и вносите коррективы. Проектирование и разработка структуры DSS проходят следующие этапы: Интеллект – на данном этапе целью является поиск проблем/ситуаций/условий, требующих решения. Ожидается, что разработчик, определит контекст проблемы, для которой требуется поддержка. Также следует определить цели и доступные ресурсы, чтобы полученные результаты соответствовали ожиданиям. Дизайн – на этом этапе проводится анализ всех возможных действий, а также определение дизайна и конструкции системы. Проектирование системы включает в себя определение компонентов, платформы, библиотек функций и специальных языков, в то время как структура системы определяет подход к прототипу. Этот этап также включает в себя определение требований к оборудованию. Выбор. После того, как был составлен список и проанализированы все возможные варианты действий на шаге 2, необходимо выбрать лучший из них, в зависимости от бизнес-целей и полученных результатов. Реализация – это заключительный этап, на котором происходит тестирование, оценка, корректировка и развертывание. Тем не менее, это конечный продукт, но его можно настроить, уточнить и обновить в зависимости от ваших действий и требований. При разработке пользовательского DSS необходимо учитывать следующие важные факторы: функции управления данными; доступные аппаратные платформы; пользовательский интерфейс; совместимость с другими приложениями; расходы. Система поддержки принятия решений помогает повысить прибыль, только если она адаптирована к вашим конкретным потребностям и реализована правильно. Сначала создадим алгоритм процесса поддержки пользователя для принятия решения о сделке. Данный алгоритм изображен на рисунке 5. 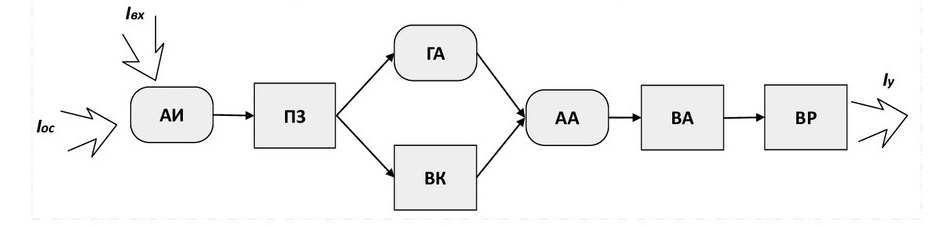 Рисунок 5 – Алгоритм процесса поддержки пользователя Расшифруем данный алгоритм: АИ – анализ информации; ПЗ – постановка задачи; ГА – генерация альтернатив; ВК – выбор критерия; АА – анализ альтернатив; ВА – выбор альтернативы; ВР – выбор решения; Iос – обратная связь; Iвх – входная информация; Iу – управляющая информация. Задача подготовки данных включает в себя экс-дивиденды/права на полученные данные, создание большого количества общепризнанных технических индикаторов в качестве функций и использование нормализации максимума-минимума для работы с функциями, так что предварительно обработанные данные могут быть используется в качестве входных данных алгоритмов ML. Также торговые сигналы акций генерируются алгоритмами ML. В этой части мы обучаем модели DNN и традиционные алгоритмы ML методом WFA; затем обученные модели машинного обучения предсказывают направление движения акций в будущем, что считается торговым сигналом. Фреймворк для прогнозирования тенденций цен на акции на основе алгоритмов машинного обучения. Данный алгоритм изображен в приложении А. Учитывая обучающий набор данных D, задача алгоритма WFA состоит в том, чтобы правильно классифицировать метки классов. Для построения данного алгоритма мы будем использовать шесть традиционных моделей ML (LR, SVM, CART, RF, BN и XGB) и шесть моделей DNN (MLP, DBN, SAE, RNN, LSTM и GRU) в качестве классификаторов для прогнозирования взлетов и падений. падение цен на акции. WFA представляет собой скользящий метод обучения. Мы используем последние данные вместо всех прошлых данных для обучения модели, а затем применяем обученную модель для реализации прогноза для данных вне выборки (тестовый набор данных) для будущего периода времени. После этого на новом тренировочном наборе, представляющем собой предыдущий тренировочный набор, проходим на один шаг вперед, проводится обучение следующего раунда. WFA может повысить надежность и надежность торговой стратегии в торговле в реальном времени. Здесь мы опишем использование алгоритма машинного обучения и метод WFA для прогнозирования тренда цен на акции в качестве торговых сигналов. На каждом этапе мы используем данные за последние 250 дней (один год) в качестве обучающего набора и данные за следующие 5 дней (одну неделю) в качестве тестового набора. Каждая акция содержит данные за 2000 торговых дней, поэтому требуется (2000-250)/5 = 350 тренировок, чтобы получить в общей сложности 1750 прогнозов, которые являются торговыми сигналами ежедневной торговой стратегии. Метод WFA показан на рисунке 6. 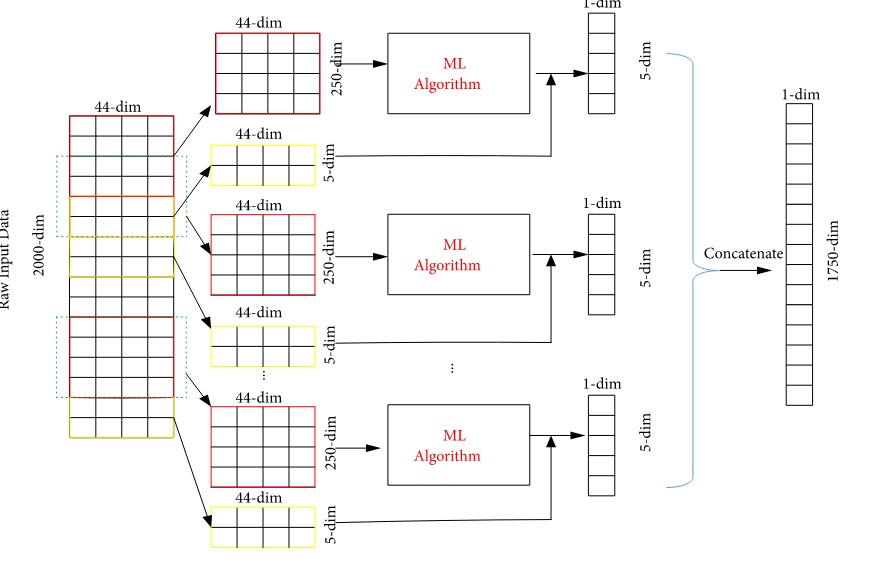 Рисунок 6 – Принципиальная схема WFA (обучение и тестирование). Теперь рассмотрим алгоритм режимов работы программы. Алгоритм режимов работы программы представлен на рисунке 7. 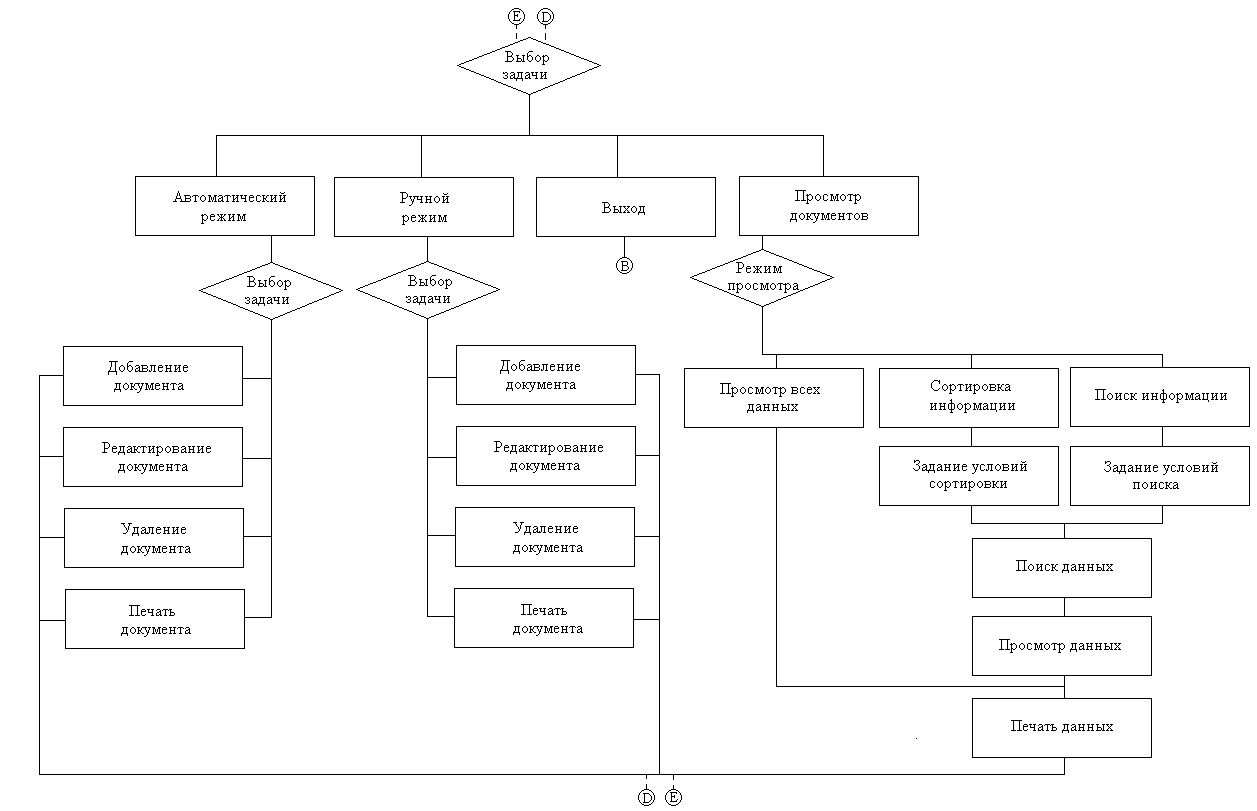 Рисунок 7 – Алгоритм режимов работы программы Работа программы будет проходить в 3 режимах: Автоматический режим – режим при котором программе предоставляются полная или частичная автономность работы, перед включением которого пользователь настраивает ее под необходимый результат. Ручной режим – режим при котором все необходимые действия для совершения сделки выполняет пользователь. Режим просмотра документов – режим в котором пользователь может просмотреть архив операций, созданный на его аккаунте. На основе этого была разработана оригинальная экономико-математическая модель в виде задачи оптимизации с двумя критериями. Данный алгоритм изображен на рисунке 8.  Рисунок 8 – Алгоритм принятия решения Методика оценки эффективности инвестиционного проекта по данной модели состоит из следующих этапов: выбор инвестиционного проекта для оценки; выбор источников информации об организации для экспресс-анализа; сбор информации об организации для экспресс-анализа; подробный анализ организации, осуществляющей инвестиционный проект; выбор источников информации об инвестиционном проекте; сбор информации об инвестиционном проекте; оценка ожидаемой эффективности инвестиционного проекта на основе построения оригинальной экономико-математической модели; анализ результатов и выдача рекомендаций; общие выводы и рекомендации; решение о реализации инвестиционного проекта. Рассмотрим эти этапы подробнее. Первый этап методики оценки эффективности заключается в постановке на оценку набора инвестиционных проектов или сценариев реализации инвестиционного проекта. Если одновременно для оценки эффективности необходимо предварительно определить ряд инвестиционных проектов, сценарии реализации проектов могут быть определены непосредственно в процессе оценки путем изменения параметров инвестиционного проекта, которые можно варьировать с определенной градусный шаг и в установленных пределах изменения. На втором этапе определяются источники информации для экспресс-анализа. Источники информации принято классифицировать по двум основным признакам: по месту получения и по месту назначения. В зависимости от места получения информации источники делятся на: внешним сторонам, включая информацию, собранную вне оцениваемой организации (законы и нормативные акты, публикации различных государственных, статистических, научно-исследовательских и консультационных учреждений, журналы, справочники, тематические и отраслевые сайты, отзывы партнеров и клиентов организации и т. д.); внутренние, содержащим данные, собираемые внутри организации или по ее запросу (юридические, бухгалтерские и финансовые документы, внутреннюю статистическую отчетность, базы данных организации, материалы ранее проведенных обследований организации, анкетирование и интервью с руководителями и работниками, планы деятельности и развития организации). В зависимости от назначения источники информации делятся на: первичные - источники информации, формируемые сначала для определенной цели (проводимые организацией или по ее заказу исследования, опросы и т. п.). Первичные источники нужны в тех случаях, когда данных из вторичных источников недостаточно для проведения комплексной оценки организации; вторичные - это уже существующие источники информации, созданные для различных целей (финансовая отчетность, оперативная информация, отчетность в налоговые органы и т.д.), но они могут использоваться и для других целей, например. B. для оценки эффективности или анализа деятельности организаций. На третьем этапе оценки эффективности инвестиционного проекта осуществляется сбор информации об организации, реализующей инвестиционный проект. Существует два основных метода сбора информации: кабинетное исследование и полевое исследование. Кабинетный метод сбора информации – это сбор данных из различных вторичных источников. Метод основан на разных источниках информации, что позволяет использовать большие объемы данных. Большая часть информации, получаемой в ходе применения кабинетного метода, не требует больших затрат для организации или даже бесплатна, так как поступает из легкодоступных источников информации, таких как материалы СМИ, правительственные публикации, различные отчеты, внутренние документы, официальная статистика, интернет. источники. Основными преимуществами кабинетного метода сбора информации являются дешевизна источников информации, быстрота сбора данных, возможность использования нескольких источников информации, а также сравнительная достоверность данных, получаемых из объективных источников информации. Среди недостатков - недостаточная полнота, неактуальность или недостоверность информации. Полевые методы сбора информации заключаются в сборе и обработке первичных источников информации и делятся на качественные и количественные. Качественные методы собирают информацию о качественных свойствах исследуемых объектов, малопригодную для статистической обработки. На основании этого алгоритма построим схему БД в центре, которой будет конкретный объект инвестирования. Данная схема изображена на рисунке 9. 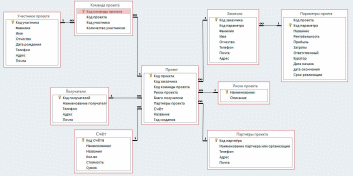 Рисунок 9 – Логическая схема БД программы Теперь приступим к описанию предметной области. Данная область является схемой базы данных программы. При её рассмотрении было выбрано девять сущностей, атрибуты и типы данных этих атрибутов приведены в таблице 1–9. Таблица 1 – Сущность Komanda
Таблица 2 – Сущность Uchastniki
Таблица 3 – Сущность Proekt
Таблица 4 – Сущность Zakazchik
Таблица 5 – Параметры проекта
Таблица 6 – Сущность Poluchateli
Таблица 7 – Сущность Schet
Таблица 8 – Сущность Partner
Таблица 9 – Сущность Riski
Теперь перейдем к описанию интерфейса разработанного приложения. 3.3 Описание интерфейса В вычислительной технике интерфейс – это общая граница, через которую два или более отдельных компонента компьютерной системы обмениваются информацией. Обмен может осуществляться между программным обеспечением, компьютерным оборудованием, периферийными устройствами, людьми и их комбинациями. Некоторые аппаратные устройства компьютера, такие как сенсорный экран, могут как отправлять, так и получать данные через интерфейс, в то время как другие, такие как мышь или микрофон, могут предоставлять только интерфейс для отправки данных в данную систему. Пользовательский интерфейс – это точка взаимодействия между компьютером и людьми; он включает в себя любое количество модальностей взаимодействия (таких как графика, звук, положение, движение и т. д.), при которых данные передаются между пользователем и компьютерной системой. Графический пользовательский интерфейс (GUI) представляет собой форму пользовательского интерфейса, которая позволяет пользователям взаимодействуйте с электронными устройствами с помощью графических значков и звуковых индикаторов, таких как первичная нотация, вместо текстовых пользовательских интерфейсов, печатных меток команд или текстовой навигации. Графические интерфейсы были введены в ответ на воспринимаемое крутоекривая обучения интерфейсов командной строки (CLI), которые требуют ввода команд на клавиатуре компьютера. Действия в графическом интерфейсе обычно выполняются путем прямого манипулирования графическими элементами. Помимо компьютеров, GUI используются во многих портативных мобильных устройствах, таких как MP3 - плееры, портативные медиаплееры, игровые устройства, смартфоны и небольшие бытовые, офисные и промышленные элементы управления. Проектирование визуальной композиции и временного поведения графического интерфейса пользователя является важной частью программирования приложений в области взаимодействия человека с компьютером. Его цель состоит в том, чтобы повысить эффективность и простоту использования лежащего в основе логического дизайна хранимой программы, дисциплины дизайна, называемой удобством использования. Методы дизайна, ориентированного на пользователя, используются для обеспечения того, чтобы визуальный язык, представленный в дизайне, соответствовал задачам. Видимые функции графического интерфейса приложения иногда называют chrome или GUI. Как правило, пользователи взаимодействуют с информацией, манипулируя визуальными виджетами, которые позволяют взаимодействовать с данными, которые они хранят. Виджеты хорошо продуманного интерфейса выбираются для поддержки действий, необходимых для достижения целей пользователей. Модель -представление-контроллер допускает гибкие структуры, в которых интерфейс не зависит от функций приложения и косвенно связан с ними, поэтому графический интерфейс можно легко настроить. Это позволяет пользователям выбирать или создавать другой скин по желанию и облегчает работу дизайнера по изменению интерфейса по мере развития потребностей пользователя. Хороший дизайн графического интерфейса больше относится к пользователям и меньше к архитектуре системы. Крупные виджеты, такие как окна, обычно представляют собой рамку или контейнер для основного содержимого презентации, такого как веб-страница, сообщение электронной почты или рисунок. Меньшие обычно действуют как инструмент пользовательского ввода. GUI может быть разработан для требований вертикального рынка как GUI для конкретных приложений. В мобильных телефонах и портативных игровых системах также используются графические интерфейсы пользователя с сенсорным экраном для конкретных приложений. Новые автомобили используют GUI в своих навигационных системах и мультимедийных центрах или в комбинациях навигационных мультимедийных центров. Интерфейс программы основан на стандартных схемах, используемых в аналогичных приложениях на мобильных телефонах. В этом разделе справки подробно описаны все элементы управления и то, как они работают. Экран приложения состоит из: Начального экрана приложения. Название окна. Заголовок содержит информацию о том, в каком разделе находится пользователь; Основная область. Основная рабочая область окна. Полоса прокрутки, показывающая текущее положение относительно полного размера главного окна. Черная толстая полоса показывает текущее местоположение. Кнопки меню или действий. Индикаторов. Показатель занятости. Песочные часы означают, что приложение обрабатывает данные или обменивается ими с сервером. Этот индикатор показывает, насколько интенсивно работает приложение. Программа использует следующие элементы управления: поля ввода; кнопки радио; кнопки выбора; меню; списки; таблицы. Поле ввода – это элемент управления, который дает пользователю возможность вводить информацию. Это может быть любая информация - от имени пользователя до значения цены активации ордера. Редактирование поля ввода начинается, когда вы нажимаете клавишу выбора. Кнопки радио – это элемент управления, который позволяет пользователю выбрать один из нескольких предлагаемых параметров. Кнопки радиоприемника расположены группами. В каждой группе пользователь может выбрать опцию с помощью кнопки выбора правой или левой клавиши. Кнопки выбора работают как переключатель - у них есть два положения - вкл. и выкл. Меню появляется на экране, когда вы нажимаете одну из программных клавиш на своем мобильном телефоне. Меню позволяет вам либо выполнить действие, либо перейти в раздел терминала. Списки - это элемент управления, который позволяет вам выбирать значение из предлагаемых значений. Список можно свернуть и расширить. Свернутый список можно найти ниже. Таблицы – используются для отображения данных котировок, открытых, закрытых позиций, новостей, выданных ордеров, их истории и текущего состояния учетной записи. Выводы по третьей главе В данной главе мы описали компоненты и структуру проекта, схему базы данных, виды разработанных алгоритмов с соответствующими спецификациями к ним, и также описали разработанный интерфейс программного обеспечения. |