Самостоятельная работа 14. Самостоятельная работа по теме 2 Цель занятия закреплениезнаний о технологиях поиска информации в информационнопоисковых системах, формирование умения применять их. Задание Составьте схему Зарубежные и отечественные поисковые машины
 Скачать 81 Kb. Скачать 81 Kb.
|

|
Самостоятельная работа по теме 3.2 Цель занятия: закреплениезнаний о технологиях поиска информации в информационно-поисковых системах, формирование умения применять их. Задание 1. Составьте схему «Зарубежные и отечественные поисковые машины». Популярные поисковые машины Наиболее популярны следующие поисковые машины: – Google – http://www.google.com (рис. 4.1); – Yahoo! – http://www.yahoo.com; – AltaVista – http://www.altavista.com; – Lycos – http://www.lycos.com; – Excite – http://www.excite.com; – AOL Search – http://search.aol.com; – HotBot – http://www.hotbot.com. На этом, разумеется, список популярных поисковых систем не заканчивается – их количество исчисляется сотнями. Однако я уверен, что для работы с англоязычными сайтами вам с лихвой хватит и этих. Следует отметить, что практически все представленные выше поисковые машины могут работать и с кириллицей. Но для поиска информации на русском языке все-таки рекомендую отечественные поисковые системы: – Яндекс – http://www.yandex.ru; – Рамблер – http://www.rambler.ru; – Апорт – http://www.aport.ru; – mail.ru – http://www.mail.ru. Существуют и другие русскоязычные поисковые системы, однако эти наиболее популярны, особенно первые две. Задание 2. Составьте таблицу «Зарубежные и отечественные поисковые каталоги». Индексные (словарные) поисковые системы. AltaVista Search (AltaVista Company) — поиск в WWW и Usenet; имеет и каталоговую систему поиска (использует каталог LookSmart); возможность поиска графических, видео- и аудиофайлов Altavista — первая в мире поисковая система (изначально она размещалась по адресу: altavista.digital.com). Поисковые каталоги имеют древовидную структуру и больше напоминают систематические каталоги обычных библиотек. При открытии каталога, на титульную его часть, вынесены основные его разделы: работа, дом, дача, машины, спорт, здоровье, новости, развлечения, и так далее. Задание 3. Составьте алгоритм работы в поисковых системах: Google, Яndex, Рэмблер. Google: При том огромном объеме информации, который есть в Интернете, находить нужные сведения практически нереально без какого-то решения, которое помогало бы упорядочить их. Чтобы пользователи за доли секунды получали актуальные и полезные результаты, инструменты ранжирования Google упорядочивают сотни миллиардов страниц в поисковом индексе. Эти системы ранжирования включают целый ряд алгоритмов. Чтобы дать вам наиболее полезную информацию, они учитывают множество факторов, включая ваш поисковый запрос, релевантность и удобство найденных страниц, их надежность, а также ваше местоположение и настройки. Вес каждого фактора варьируется в зависимости от характера вашего запроса. Например, дате публикации контента придается большее значение, когда вы ищете актуальные новости, и меньшее, если вас интересует определение из словаря. Чтобы алгоритмы поиска отвечали самым высоким стандартам, мы придерживаемся установленной процедуры онлайн-тестирования, к которому привлекаются тысячи сторонних специалистов по оценке качества результатов поиска, представляющие разные страны и прошедшие дополнительную подготовку. Они следуют точным инструкциям, которые отражают наши цели в отношении поисковых алгоритмов и доступны для ознакомления всем желающим. Ниже приведены дополнительные сведения о ключевых факторах, от которых зависят результаты поиска. Анализ слов и выражений Подбор подходящих страниц Ранжирование релевантных страниц Показ наиболее подходящих результатов Учет сведений о пользователях Анализ слов и выражений Чтобы подобрать страницы, содержащие релевантные сведения, прежде всего необходимо проанализировать значение слов в запросе. Мы разрабатываем языковые модели, позволяющие определять, какие сочетания слов следует искать в индексе. Для этого выполняется ряд действий – от интерпретации орфографических ошибок до определения типа введенного запроса на основе результатов последних исследований в области понимания естественного языка. Например, даже если у введенного вами слова несколько значений, Google Поиск определит верное. Это стало возможным благодаря специальной системе синонимов, которая создавалась пять лет и позволяет существенно увеличить качество результатов по более чем 30% запросов на разных языках. Яндекс: Поисковой алгоритм – это набор формул, с помощью которых решается задача выдачи (ранжирования) страниц по результатам поиска. Запрос пользователя осуществляется по определенным ключевым словам и фразам. Поисковая система сама выбирает наиболее подходящие web ресурсы, соответствующие конкретному запросу, в зависимости от множества правил которые формирую алгоритмы поисковой системы. Рэмблер: Интернет постоянно растет, так же как растет и число пользователей, которые обращаются с запросами к поисковым системам. Увеличение объема информации и количества запросов, в свою очередь, приводит к повышению требований к скорости работы поисковых машин, качеству поиска и наглядности представления результатов. Так, для того чтобы пользователь остался доволен результатом, на сегодняшний день поисковой системе нужно собрать, обработать, обновить, найти и отсортировать в два раза больше документов, чем год назад. А основная задача поиска как раз и состоит в том, чтобы пользователь был доволен его результатами. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Рассмотрим 5 основных характеристик поисковой системы: полнота, точность, актуальность, скорость поиска, наглядность. Полнота это одна из основных характеристик поисковой системы, которая представляет собой отношение количества найденных по запросу документов к общему числу документов в Интрнете, удовлетворяющих данному запросу. Полнота поиска в большой мере зависит от работы системы сбора и обработки информации. В связи с постоянным ростом количества документов в сети, эта система в первую очередь должна быть масштабируемой. В Рамблере масштабируемость достигается за счет параллельного исполнения задачи произвольным количеством машин. Сбором информации занимается робот-паук, который обходит страницы с заданными URL и скачивает их в базу данных, а затем архивирует и перекладывает в хранилище суточными порциями. Робот размещается на нескольких машинах, и каждая из них выполняет свое задание. Так, робот на одной машине может качать новые страницы, которые еще не были известны поисковой системе, а на другой - страницы, которые ранее уже были скачаны не менее месяца, но и не более года назад. Хранилище у всех машин едино. При необходимости работу можно распределить другим способом, например, разбив список URL на 10 частей и раздав их 10 машинам. Параллельная работа программы позволяет легко выдерживать дополнительную нагрузку: при увеличении количества страниц, которые нужно обойти роботу, достаточно просто распределить задачу на большее число машин. В хранилище информация в сжатом виде собирается и разбивается на куски по 50 Мб. Эти части постепенно распределяются между 70 машинами, на которых запущена программа-индексатор. Как только индексатор на одной из машин заканчивает обработку очередной части страниц, он обращается за следующей порцией. В результате на первом этапе формируется много маленьких индексных баз, каждая из которых содержит информацию о некоторой части Интернета. Таким образом, вся интеллектуальная обработка данных осуществляется параллельно, поэтому ускорение процесса индексации достигается простым добавлением машин в систему. После того, как все части информации обработаны, начинается объединение (слияние) результатов. Благодаря тому, что частичные индексные базы и основная база, к которой обращается поисковая машина, имеют одинаковый формат, процедура слияния является простой и быстрой операцией, не требующей никаких дополнительных модификаций частичных индексов. Основная база участвует в анализе как одна из частей нового индекса. Так, если объединяются 70 новых частей, то в анализе участвует 71 фрагмент (70 новых + основная база предыдущей редакции). Кроме того, единый формат позволяет проводить тестирование частичных баз еще до объединения их с основной, и обнаруживать ошибки на более раннем этапе. Сборка единой базы из частичных индексных баз представляет собой простой и быстрый процесс. Сопоставление страниц не требует никакой интеллектуальной обработки и происходит со скоростью чтения данных с диска. Если информации, которая генерируется на машинах-индексаторах, получается слишком много, то процедура «сливания» частей проходит в несколько этапов. В начале частичные индексы объединяются в несколько промежуточных баз, а затем промежуточные базы и основная база предыдущей редакции пересекаются. Таких этапов может быть сколько угодно. Промежуточные базы могут сливаться в другие промежуточные базы, а уже потом объединяться окончательно. Точность - еще одна основная характеристика поисковой машины, которая определяется как степень соответствия найденных документов запросу пользователя. Повышение точности в поисковой машине Рамблер достигается за счет использования различных технологий на всех этапах обработки и поиска информации. Одним из наиболее интересных процессов является распознавание грамматических омонимов. Омонимы - это слова, которые имеют одинаковое написание, но различный смысл. Омонимы не только увеличивают размер индексной базы (так как для каждого такого слова приходится хранить все его возможные значения), но и отрицательно сказываются на точности поиска. Для того, чтобы результаты поиска были точнее, модуль синтаксического анализа проводит разбор окружения слов-омонимов с целью установления их наиболее вероятных значений. Например, если рядом со словом «печь» стоит существительное («пирожки», «картошка»), то с высокой вероятностью «печь» в данном контексте является глаголом. На сегодняшний день анализатор способен распознавать значения только грамматических омонимов. Синтаксический анализ позволяет также с определенной вероятностью распознавать некоторые имена собственные. Например, если в тексте несколько слов подряд написано с большой буквы, они чаще всего представляют собой имя собственное (Петр Петрович, Московский Государственный Университет). Данные о таких конструкциях учитываются при индексации и обработке запроса. Еще один способ повышения точности поиска - это выделение устойчивых обозначений и поиск их как отдельных лексических единиц. На сегодняшний день в Рамблере реализована система распознавания таких конструкций, например C++, б/у, п/п-к. Если по запросу С++ поднимать все тексты, в которых присутствуют латинская буква С, а также знак +, то получится огромное количество документов, далеко не все из которых соответствуют запросу; кроме того, это большая работа, значительно увеличивающая время поиска. Огромную роль в повышении точности поиска играет ранжирование. Пользователь очень редко просматривает больше трех страниц с результатами поиска. Поэтому субъективно он оценивает точность по «верхним» документам. Даже если нужный документ найден поисковой машиной, но расположен на двухсотой позиции, скорее всего, он никогда не будет найден пользователем. По умолчанию в Рамблере результаты ранжируются по степени соответствия (релевантности) запросу и группируются по сайтам. Помимо автоматических способов увеличения точности поиска, существуют различные средства, с помощью которых пользователь сам может уточнить поиск по отдельным запросам. В первую очередь к ним относится специальный язык поискового запроса, используя который можно ограничивать количество найденных документов. Например, запрос или его часть, взятые в кавычки, обрабатываются буквально, с учетом всех стоп-слов, форм, порядка, знаков препинания. Это повышает точность поиска, но уменьшает его полноту: если часть, заключенная в кавычки, неточна, нужный документ найден не будет. Увеличить точность можно с помощью использования поиска в найденном. Уточняющий поиск, проводится уже не по всей индексной базе, а только по результатам предыдущего поиска. Таким образом, круг найденных документов сужается. Актуальность - не менее важная характеристика поиска, которая определяется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу. На сегодняшний день индексная база поисковой системы Рамблер состоит из 8 частей, каждая из которых живет своей независимой жизнью. Весь Интернет условно разделен на 7 секторов и называется своим цветом: красный, оранжевый, желтый, зеленый, голубой, синий, фиолетовый. Сайт компании Рамблер относится к голубому сектору. Информация о web-ресурсах каждого сектора хранится в соответствующей части индексной базы. Восьмая часть - «быстрая база» - включает в себя страницы, на которых размещен счетчик Тор 100 и которые еще не успели попасть в основную индексную базу. Все части индексной базы собираются и обновляются по отдельности. Так, сегодня происходит переиндексация и обновление красного сектора, завтра - оранжевого и желтого, послезавтра - зеленого и т.д. Благодаря такому ступенчатому алгоритму в поисковой машине регулярно появляется свежая информация. Полный цикл обновления занимает около недели. При этом сбор информации происходит параллельно, а непосредственно на изготовление индекса документов одного сектора уходит всего несколько часов. Поэтому существует принципиальная возможность обновлять индексную базу быстрее. Разделение Интернета на 7 секторов условно. При необходимости он может быть разбит на 10, 20 или 40 секторов, каждый из которых будет обрабатываться автономно. В такой системе заложена возможность значительного увеличения нагрузки. С ростом объема информации в сети Интернет растет и индексная база поисковой машины. Постепенно переиндексация и сборка базы начинает занимать все больше времени, а процесс обновления индекса становится более громоздким. Поступление новых данных затягивается, информация начинает терять свою актуальность. Возможность «передела» Интернета на большее число секторов позволяет удерживать размер каждой части базы в оптимальном диапазоне, контролировать время ее сборки и обновления. «Быстрая база» отличается от остальных частей индекса меньшим объемом и очень оперативным обновлением: время ее построения занимает около двух часов. В базе содержится информация о страницах, на которых был установлен счетчик Тор 100. Участниками рейтинга Тор 100 являются новостные порталы, сайты крупных компаний, Интернет-магазины, форумы, - все наиболее популярные ресурсы в сети. Каждый раз при установке счетчика на новую страницу сайта, зарегистрированного в Тор 100, информация передается в поисковую систему. Страница ищется во всех цветах основной базы и, если она еще не известна поисковой системе, отправляется в очередь на обработку. Перед обработкой страницы дополнительно фильтруются, из них отбираются самые посещаемые. Таким образом, «сливки» с Интернета собираются два раза в день. «Быстрая база» представляет собой разумное решение проблемы актуальности данных в поиске. Информационное агентство может выложить новость через десять минут после ее появления, потому что тратит время только на верстку страницы. Поисковая машина должна сначала заиндексировать текст, а на это требуется гораздо больше времени. «Быстрая база» охватывает все ресурсы Интернет, зарегистрированные в Тор 100, на которых был размещен счетчик, и которые еще не успели попасть в основную базу. При этом индексируются как страницы с новостями, так и другие свежие документы, появившиеся в Тор 100. Наглядность представления результатов является необходимым компонентом удобного поиска. На плохой витрине легко не заметить хороший товар. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. В следствие нечеткости запросов или неточности поиска, даже первые страницы не всегда содержат только нужную информацию. Это означает, что пользователю часто приходится проводить свой собственный поиск внутри списка найденного. Различные элементы ответной страницы помогают ориентироваться в результатах поиска. Группировка по сайтам предназначена для того, чтобы на странице можно было вывести как можно больше Интернет-ресурсов, релевантных запросу пользователя. Это бывает важным, когда необходимо получить информацию из различных источников. Если более информативной для посетителя является дата обновления или релевантность отдельных документов, в ответной странице Рамблера существует возможность сортировки по этим параметрам. В некоторых случаях полезным бывает знание имени сайта. Если пользователя интересует конкретный Интернет-ресурс, имя может дать ему гораздо больше информации, чем заголовок страницы или цитата. Если запросу соответствует больше одной страницы с сайта, то в качестве результата поиска предъявляется наиболее релевантная из них, а ниже располагается частичный список остальных документов. Это увеличивает количество потенциально полезной информации на ответной странице и часто позволяет уточнить поиск без дополнительного запроса. Цитата помогает определить, насколько полезную информацию содержит найденный документ. Очень часто посетителю не требуется переходить по ссылке, чтобы обнаружить, что текст не соответствует его интересам и потребностям. Иногда ответ на вопрос пользователя содержится непосредственно в цитате документа. Это экономит время и повышает эффективность работы поисковой системы. Восстановить текст - иногда единственный способ получить доступ к содержимому найденного документа. Ресурс бывает недоступен по разным причинам. Документ может быть удален, перенесен, изменен, но его текстовое содержание некоторое время сохраняется в индексной базе. Кроме того, внутри самого документа часто отсутствует навигация, позволяющая быстро найти фрагмент, релевантный запросу. В восстановленном тексте все слова запроса подсвечиваются. Ассоциации представляют собой список запросов, которые часто подаются пользователями в течении одной поисковой сессии. Алгоритм построения ассоциаций устроен так, что они почти всегда связаны между собой по смыслу. В некоторых случаях ассоциации позволяют повысить качество поиска за счет уточнения запроса. Скорость поиска, здесь интересы пользователя и поисковой системы совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих. Обработка поискового запроса состоит из нескольких уровней (см. рис 1). 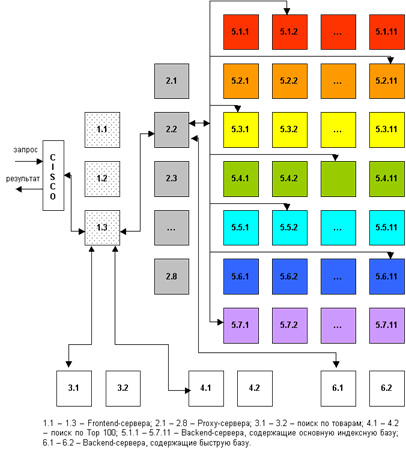 Рис. 1. Схема обработки поискового запроса Запрос поступает в поисковую систему через маршрутизатор Cisco. Маршрутизатор передает его наименее загруженной машине первого уровня - frontend. Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер. Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам и по базе Тор 100. На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, - backends. Та же информация отправляется на машины с «быстрой базой». На текущий момент в поиск включено 77 backend'ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend'ах первой группы, оранжевый сектор - на backend'ах второй группы и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend'ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу. После того, как запрос обработан на backend'ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend'ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим - с 6.1, четвертым - с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend. Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю. Каждый из этапов обработки запроса многократно продублирован и защищен системой балансировки нагрузки. Благодаря дублированию информации поисковая система Рамблер является устойчивой к сбоям на отдельных участках, авариям, отказам оборудования. Если одна их машин перестала функционировать, нагрузка перераспределяется на другие машины, и выпадения документов из поиска не происходит. Масштабируемость достигается простым добавлением в систему машин соответствующего уровня. До недавнего времени в Рамблере работало 45 backend'а. В связи с тем, что осенью нагрузка на поисковые системы обычно возрастает, число backend'ов было увеличено до 77, что позволило значительно ускорить вычисление запросов. Еще один способ повышения скорости поиска - «кэширование», сохранение информации о запросах и результатах поиска в буфере. Многие люди дают одни и те же поисковые запросы. Вычислять их каждый раз заново было бы неразумной тратой времени. Поэтому если запрос уже обрабатывался в течение некоторого интервала времени, результаты поиска отдаются пользователю из «кэша». Лингвистический анализ текста документов и запроса также позволяет ускорить обработку информации. Например, определение значения омонимов уменьшает количество нерелевантных запросу документов, которые нужно ранжировать и цитировать. Выделение устойчивых обозначений (С++, б/у) на этапах индексации и обработки запроса приводит одновременно к повышению точности и сокращению временных затрат на обработку каждого отдельного элемента обозначения (раньше запрос С++ обрабатывался как отдельно латинское С, отдельно плюс и еще один плюс. Запрос вычислялся долго, а среди результатов поиска было много нерелевантных документов, например, страницы, содержащие математические формулы и т.п.) С этой же целью используются словари стоп-слов. Стоп-слова - это наиболее частотные слова языка, которые встречаются практически в любом тексте и являются малоинформативными. В основном, это служебные слова - предлоги, частицы, артикли. Если нет специальных указаний, поисковая машина игнорирует стоп-слова, встречающиеся в запросе, чтобы не тратить время на обработку дополнительной информации, снижающей качество поиска. Задание 4. Составьте алгоритм работы с каталогами Yahoo, Апорт Yahoo считается одной из ведущих поисковых систем. Поисковые запросы в Yahoo составляют около 28% от всего поискового трафика. Портал Yahoo продолжает предлагать своим пользователям неограниченные возможности благодаря постоянно совершенствующемуся алгоритму. Yahoo неоднократно и кардинально меняла принципы своей работы. Задача Yahoo – предоставление релевантных результатов своим пользователям в тех областях, где компьютерные алгоритмы «не оправдывают ожиданий» (речь идет о персонализированных результатах и мнениях). Компания Yahoo ввела «социальный поиск», которому дали название My Web 2.0. Новый вид поисковой системы – социальная поисковая система, которая дополняет Интернет-поиск, позволяя пользователям получать ответы на интересующие вопросы не только в Интернет-ресурсах, но и непосредственно от знакомых и друзей.Технология, которой руководствуется «социальный поиск», называется My Rank. My Rank обладает всеми преимуществами алгоритмического поиска и совмещает в себе многие достоинства, руководствуясь всего одной идеей: субъективное мнение по тем или иным вопросам. Технология My Rank позволяет получать ответы на интересующие вопросы не только от поисковиков, но и от определённых людей, оценивать эти мнения с целью нахождения оптимальных ответов, которые, по Вашему мнению, являются наиболее релевантными. Тем более, речь идет о людях, которые Вам знакомы, которые разделяют Ваши интересы, работают, возможно, в Вашей структуре и потенциально искали ответы на те же вопросы, что и Вы. Совмещая возможности алгоритмического поиска с возможностью «войти в знакомое сообщество», технология My Rank способствует нахождению более релевантных ответов. Все это становится реальностью благодаря предоставляемой возможности избирать, сохранять и делиться информацией с другими людьми, точно так же, как и получать информацию, с которой готовы поделиться другие люди.Социальный поиск привнес нечто новое в Интернет. Теперь поисковые результаты находятся в некоторой зависимости от мнения определенных людей. Концептуальный поиск от Yahoo На протяжении длительного периода времени Yahoo стремится стать уникальной концептуальной поисковой системой. Какая теория лежит за понятием «концептуальная модель поисковой системы»? Компания Yahoo придерживается следующего мнения: все, что люди выражают сложной терминологией, можно заключить в простые понятия. Например, «Гавайи» и «Нью-Йорк» - абсолютно разные запросы, как по длине, так и по количеству слов, но в человеческом восприятии они совмещают в себе одно понятие. И, наоборот, человек воспринимает запрос «правоохранительные органы Нью-Йорка» как запрос, содержащий 2 разных понятия: «Нью-Йорк» и «правоохранительные органы». Люди рассуждают о логической связи между понятиями. Например, понятия «правоохранительные органы» и «полиция» можно отнести к смежным областям. Пользователь, который вводит в поисковую строку одно из понятий, может заинтересоваться сайтами, которые относятся к смежному понятию, даже, если оно не содержит слов запроса. До сих пор остается непонятным, какую технологию использует Yahoo, совершенствуя концептуальный поиск. Есть основания подозревать, что Yahoo предложит концептуальный поиск в виде отдельной поисковой системы, с использованием «социального поиска». Тем не менее, стремление предложить пользователям точную информацию в соответствии с их индивидуальными потребностями, выглядит, по меньшей мере, утопично. Поговорим о стратегиях оптимизации и поведении поисковой системы при обхождении сайта поисковыми роботами. Yahoo уделяет первостепенное значение плотности ключевых слов. По некоторым оценкам, плотность ключевых слов в < title > составляет около 10% от требований алгоритма рассматриваемой поисковой системы. На первый взгляд, кажется, что алгоритм Yahoo представляет собой полную противоположность приоритетам, которым уделяет внимание Google. Но на самом деле это не так. Некоторые ассоциируют нынешний алгоритм Yahoo с алгоритмом Google двухлетней давности. С момента появления алгоритма Inktomi, поисковая система Yahoo стала уделять большее внимание обратным ссылкам, и все же это не является основополагающим компонентом работы алгоритма Yahoo, в отличие от алгоритма Google. Оптимизируя под Yahoo, важно помнить, что алгоритм этой поисковой системы заинтересован в таких факторах, как контент, использование ключевых слов на странице, плотность ключевых слов на странице, жирный текст. Учитываются такие внешние факторы, как ссылочный текст, входящие ссылки и т.д. Yahoo предпочитает видеть ключевые слова в самих URL сайта или страниц, но отдает предпочтение жирному тексту, тексту, заключенному в < h1>. Апорт:Управление индексированием в поисковой системе Апорт При просмотре содержимого сервера для индексирования Апорт проверяет файл robots.txt и поддерживает мета-теги Robots. При просмотре содержимого сервера для индексирования Апорт проверяет файл robots.txt. Таким образом, можно ограничить "деятельность" Апорта на сервере. Поисковый робот Апорт имеет имя Aport. Именно это имя может быть использовано для ограничения индексирования через robots.txt. Также поисковая система Апорт поддерживаются мета-теги Robots, позволяющие, установить правила поведения робота на индивидуальной странице сайта и в случае, если нет возможности изменять файл robots.txt на сервере. Добавление страниц в поисковой системе Апорт Регистрация сайта в Апорте производится со страницы Добавить URL. Добавлять следует только корень сайта. Регистрация сайта в Апорте производится со страницы http://catalog.aport.ru/rus/reg/add.ple. Эта страница доступна по ссылке Добавить URL почти с любой страницы Апорта. Добавлять следует только корень сайта, остальные страницы будут найдены Апортом по ссылкам. Апорт является поисковой системой по российскому Интернету, поэтому добавлять в нее можно русскоязычные сайты, а также сайты, имеющие непосредственное отношение к российскому Интернету. В случае отказа в автоматическом добавлении сайта (например, если поисковый робот не найдет на его корневой странице русскоязычного текста) можно обратиться с просьбой о добавлении сайта по e-mail: addurl@rol.ru Индексация ресурсов поисковой системой Апорт Апорт - полнотекстовая поисковая система. Это означает, что она индексирует все слова, которые бы увидел на экране человек, просматривая конкретную страницу сервера. Апорт периодически проверяет имеющиеся в его базе сайты и приводит свою базу в соответствие с произошедшими там изменениями. Период проверки в значительной степени зависит от конкретного сайта (учитывается его популярность, динамичность обновления по данным собранным апортом при предыдущих заходах на сайт и ряд других факторов). С момента добавления сайта в поисковую систему Апорт до момента его появления в поисковой базе проходит от двух-трех дней до двух недель. В отдельных случаях, (например, в случае нестабильной связи с добавленным сайтом), это время может оказаться несколько больше. Апорт индексирует все статические документы (в Url которых не встречается символ "?"), найденные его поисковым роботом по ссылкам на сайте. Это правило может не соблюдаться для больших по объему сайтов, а также для сайтов, замеченных в применения поискового спама. Документы, содержащие в Url символ "?", индексируются поисковой системой Апорт выборочно. При этом используется квотирование количества таких документов для каждого сайта. Размер квоты вычисляется автоматически в зависимости от ряда условий, в частности от индекса цитируемости сайта, и может, в частности, быть для некоторых сайтов нулевым. Необходимо учитывать, что полная индексация сайта может происходить постепенно, а также то, что содержание базы является прерогативой поисковой системы и каких-либо гарантий по индексации (а также сохранению в индексе уже проиндексированных документов) Апорт не дает. Для документов HTML кроме основного текста документа индексируются также: заголовок документа (TITLE), ключевые слова (META KEYWORDS), описания страниц (META DESCRIPTION) и подписи к картинкам (ALT). Кроме того, Апорт индексирует как принадлежащие документу, тексты гиперссылок на этот документ с других страниц, находящихся, как внутри сайта, так и за его пределами, а также составленные (или проверенные) редакторами описания сайтов из каталога Апорт. Апорт-каталог один из крупнейших в Рунете каталогов интернет-ресурсов. Более 140 000 составленных вручную описаний сайтов, распределенных по 7000 категориям тематического и 3000 географического рубрикаторов. Начальная страница каталога совпадает с главной страницей проекта www.aport.ru. Преимущества поисковой системы Англо-русский и русско-английский перевод в он-лайн режиме запросов и результатов поиска; Автоматическая проверка орфографии запросов; Более информативная выдача (в результатах поиска «Апорт» выдает более одного предложения по каждому сайту); Использование при поиске всех возможных форм слова; Официальная сертификация Microsoft в качестве локальной поисковой системы для Internet Explorer (русская версия); Полное индексирование контента, заголовков страниц, «META KEYWORDS» (до 10 ключевых слов) и подписей к рисункам; Ручная проверка описаний страниц. Виды поиска Простой поиск В данном случае, используются поисковые запросы из одного или нескольких слов. При этом поисковая система выдает документы, где представлены почти все слова из запроса (частицы, междометия и др. элементы, не несущие логической нагрузки, игнорируются). Специальный поиск При подаче запросов могут использоваться логические операторы: И (AND, &, +, И), ИЛИ (OR, |, ИЛИ), НЕ (NOT, -, НЕ), и многие другие. Система «Апорт» поддерживает поиск как по целой фразе, так и по отдельной части слова. При этом фраза должна быть заключена в кавычки, а недостающая часть слова обозначена «звездочкой» - *. Также, «Апорт» распознает и некоторые специальные операторы, благодаря чему можно искать документы с определенным количеством слов между ключевиками, с заданной датой и адресом (URL) и ограничивать область поиска на странице (заголовком, тегами «META KEYWORDS», «ALT» и т.д.). Популярные сервисы «Апорт» В настоящее время возможности поисковой системы «Апорт» не так обширны, но все-таки значительны. На официальном сайте поисковика можно найти каталог, охватывающий добрую часть русскоязычных Интернет-ресурсов, с удобным рубрикатором и системой выдачи. Также, на «Апорт» представлена актуальная информация различного рода: это и программа телевидения, и новости, и прогноз погоды, и котировки валют. Особый блок сервисов поисковика составляют почта, справочная информация (в разделе «Словари») и поиск объекта по адресу (для Москвы, Санкт-Петербурга, а также для федеральных округов РФ: Дальневосточного, Приволжского, Северо-Западного, Сибирского, Уральского, Центрального и Южного). С помощью «Доски объявлений» от «Апорт» можно приобрести, продать, подарить или принять в дар все, что угодно: от котят до земельных участков. Данный сервис предлагает еще и поиск работы, однако найти здесь настоящие вакансии среди сомнительных объявлений довольно сложно. Апорт-лайт Страница поиска без рекламы. Эта страница позволяет максимально быстро и эффективно использовать поисковую систему. На странице присутствуют только необходимые для поиска элементы - строка запроса и кнопка. Также, для удобства пользователей существует “подсказка” при наборе запроса в поисковой строке. В качестве “подсказки” используется база запросов, которые были набраны пользователями при обращении к Апорту. Мапорт Мелодии, логотипы и java-игры для всех популярных моделей мобильных телефонов. Удобная систематизация и навигация позволяет пользователям найти интересующий их контент, а система подписки дает возможность постоянно получать информацию о новинках сайта. ТВ-программа Программа телепередач на текущую и следующую недели. Также можно ознакомиться с анонсами наиболее интересных передач и фильмов. Погода на Апорте Прогноз погоды для различных городов Мира. Информационной блок с прогнозом погоды отображается на странице www.aport.ru. По умолчанию в этом блоке показывается погода для Москвы, но можно настроить отображение погоды для любого интересующего города. Для этого нужно перейти на страницу погоды для выбранного города и щелкнуть по кнопке “Публиковать на www.aport.ru”. Это и просто, и удобно! WAP.Aport.ru Версия Апорта для мобильных телефонов. Сегодня это быстрый поиск по интернет-сайтам и/или каталогам музыкальных файлов (midi, mp3), это прогноз погоды на неделю вперед, это курсы основных валют и доступ к почте. Апорт – справка Апорт-справка – это совместный проект с компанией <Евро-Адрес>, содержит базу данных справочной информации о более чем 300 000 организаций РФ. С помощью системы поиска, удобной навигации по каталогу товаров и услуг, региональному рубрикатору пользователь получает список организаций с указанием названия, адреса, телефонов, URL, электронной почты, дополнительных сведений о виде и предмете деятельности. Координаты организаций отображаются на географической карте. Заключение После долгого молчания, когда интернет-общественность уже окрестила «Апорт» полуживым проектом, поисковая система вдруг неожиданно очнулась от спячки и объявил об обновлении серверного парка. В целом, в поисковой системе «Апорт» задействовано более 50 высокопроизводительных серверов. В эту цифру входят: front-end серверы, принимающие и обрабатывающие запросы от пользователей; поисковые серверы, на которых хранится база «Апорт», по которой ведется поиск документов; индексирующие серверы, которые производят обновление базы документов; серверы поиска и индексации по дополнительным базам «Апорта»: поиска по знакомствам от «Омена», портальным новостям Рол.Ру, товарам, энциклопедии «Кругосвет», рефератам от Реферат.Ru, поиска по импортируемым новостям с других сайтов (новости Апорт.Ру), поиска по каталогу «Апорт», по вакансиям. — всего более двух десятков дополнительных баз; комплекс из нескольких серверов, обеспечивающих ряд внутренних сервисов «Апорта»: работу с подсчетом индекса цитирования сайтов, обработку добавляемых сайтов в базу «Апорта», систему фильтрации сайтов в базе и удаление поискового спама из базы, работу со статистикой поиска, обновление базы географического таргетинга, etc На данный момент в поисковой системе «Апорт» проиндексировано более миллиона сайтов, суммарный объем проиндексированных документов превышает 2 Тб. Дальнейший рост размера базы и увеличение количества кластеров в поисковой машине будет соответствовать увеличению содержимого Рунета. В настоящее время максимальное время обработки запроса поисковой системой «Апорт» не превышает 100 мс, а среднее время обработки равно 78 мс. В сутки в среднем на поисковую систему приходит около 750 тысяч запросов, то есть, около 9 запросов в секунду. При этом стоит отметить, что поисковая система обладает возможностью изменять внутренние параметры поиска в зависимости от текущей нагрузки, что позволяет избегать ситуации с перегруженностью поисковых серверов, и в тоже время, в случае наличия свободных аппаратных ресурсов, выдавать расширенные результаты поиска. В настоящее время имеется достаточный запас аппаратных ресурсов, что позволяет без увеличения времени поиска производить расширение как объема базы, так и увеличение функциональных возможностей поиска. Сейчас главным разработчиком системы является Алексей Боков. До перехода в РОЛ он занимался разработками в области компиляторов языков программирования в одной из российских процессинговых компаний. На рынке существует мнение, что время прежнего «Апорта» — как ни крути — прошло, и оно уже никогда не вернется. За несколько лет «Апорт» растерял былые позиции, и вернуться на прежний уровень будет очень и очень сложно. РОЛ использовал и использует свои основные ресурсы для развития главного бизнеса — доступа в Интернет. Задача вступить в конкурентную борьбу с ведущими поисковыми машинами Рунета у нас никогда не стояла, это скорее вопрос к «Гуглу». Апорт не потерял свои позиции, он просто не рос так, как росли «Яндекс» и «Рамблер». Тем не менее, у нас достаточно крепкое ядро аудитории. Мы благодарны пользователям за то, что они понимают качество поиска «Апорта» без дополнительного маркетингового бюджета со стороны РОЛ. Задание 5. Составьте словарь терминов по изученной теме. ИНФОРМАЦИОННОЕ ОБЩЕСТВО [information society] - общество будущего, на которое воздействует информатика и средства вычислительной техники, минимизирующие противоречия в обществе и повышающие интенсивность использования информацию из самых разнообразных источников (библиотеки, радио, компьютер и др.). ИНФОРМАЦИОННОЕ ПОЛЕ [information field] - одно из трех полей (гравитационное, энергетическое и информационное), в которых идет жизнь на Земле, воздействующее потоками информации и знаний, например, на органы чувств человека через сигнальную систему. ИНФОРМАЦИОННОЕ ПРОИЗВОДСТВО [information production] - процесс создания и распространения информации или ее представлений. Как и в материальном производстве можно выделить две стороны способа производства: производительные информационные силы - люди, участники информационного производства, информационные производственные отношения - совокупность информационных отношений между людьми в процессе производства, распределение и потребления информации. ИНФОРМАЦИОННО-ПОИСКОВАЯ СИСТЕМА (ИПС) [search information system] - аппаратная и программная система, предназначенная для хранения и накопления данных в базе, оперативного поиска сведений в соответствии с запросами пользователя и выдачи ему сообщения по результатам поиска. Информация для человека — знания, которые он получает из различных источников. Сообщение, полученное человеком, может пополнить его знания, если содержащиеся в нем сведения являются для человека понятными и новыми. Информационная культура —умение целенаправленно работать с информацией и использовать для ее получения, обработки и передачи компьютерную информационную технологию, современные технические средства и методы. |