Структуры данных и эффективность алгоритмов. 4
 Скачать 2.32 Mb. Скачать 2.32 Mb.
|

Структуры данных как способы представления АТД.На сегодняшний день разработано и исследовано достаточно обширное количество разнообразных структур данных, позволяющих представлять АТД, широко используемые в практике программирования, и эффективно реализовать соответствующие операции. Структурные типы данных и структуры данных принято классифицировать на статические и динамические. В случае статических типов конструктор (описатель) этого типа данных фиксирует количество компонентов и взаимосвязи между ними, все значения такого типа одинаковы по количеству компонентов и взаимосвязям между ними. В случае динамических типов конструктор не фиксирует количество компонентов, операции со значениями такого типа могут допускать добавление или удаление компонентов и изменение взаимосвязей между ними. Среди вышеприведенных базовых структурных типов данных - записи (структуры) являются статическими типами, а файлы динамическими (но ограниченно - допустимо только добавление компонентов в конец файла). Массивы имеют промежуточный статус. В классическом Pascal допускаются только статические массивы, а в Java и С# массив объявляется как динамический, но в периоде выполнения должен быть инициализирован (создан), после чего фактически становится статическим. АТД «Граф» может быть определен как статический тип данных, не допускающий операции добавления и удаления вершин и ребер, и представлен, например, статической матрицей смежности16. Но для каких-то приложений АТД «Граф» необходим как динамический тип данных с операциями, позволяющими изменять количество компонентов (вершин) и связи между ними (ребра). В этом случае для представления графа потребуется связная динамическая структура данных (реализуемая на основе указателей). Рекурсивный тип данных - это структурный тип, у которого хотя бы один из компонентов имеет такой же тип, т.е. имеем ситуацию - тип части совпадает с типом целого (или в более общем случае - опосредованно зависит от него через другие совместно определяемые типы данных). Аналогичное определение для рекурсивных структур данных - значений рекурсивного типа данных. Последовательность можно определить как рекурсивный тип данных - как пару (заголовок, хвост), где заголовок – первый элемент последовательности, а хвост – последовательность остальных её элементов. Но это скорее итерация, чем полноценная рекурсия, однако, если:
то мы получаем рекурсивный (по существу) тип данных (и соответствующую рекурсивную структуру данных – значений этого типа), известный как LISP-список. Отметим, что LISP-список:
Для рекурсивных типов данных естественным является набор операций, согласованный с рекурсивной структурой значений этого типа, и рекурсивные методы обработки таких данных.
Для представления последовательностей используются массивы и линейные связные списковые структуры данных (с указателями). Используются также и смешанные способы представления на основе этих структур данных. Например, последовательность сложных (объемных) элементов может быть представлена вектором указателей на её элементы. Различные способы представления имеют различные сложностные характеристики по памяти и времени (в частности разные для разных операций) и могут оказаться более или менее приемлемыми в различных ситуациях. Список базовых операций для (различного вида) последовательностей 17 [13 п.5.3.]:
Для варианта с последовательным доступом к компонентам аргумент «позиция» (номер) становится не нужным, все операции привязываются к текущей позиции. Пусть Отметим, что массив – фактически статическая структура данных, а потому требует предварительного резервирования памяти, в то время как предварительная оценка максимального размера обрабатываемой последовательности для решаемой задачи может оказаться затруднительной. Кольцевой массив (circulararray) – структура данных, основанная на техническом приеме, когда конец вектора как бы подклеивается к его началу. Последовательность хранится в таком векторе, начиная с некоторого (вообще говоря) промежуточного индекса в порядке возрастания индекса (с перескоком к нулевому на правой границе). Такой прием используется, когда операции добавления-удаления допускаются с обоих (или разных) концов последовательности, например в реализации очередей. Он позволяет повторно использовать освобождающийся сегмент вектора и при этом устранить необходимость сдвига элементов последовательности. Вектор
Основной недостаток реализации вектора на основе простого массива состоит в необходимости предварительного указания размера массива, то есть максимального числа элементов вектора. Если же действительное число элементов значительно меньше N, то при такой реализации бесполезно занимается место в памяти. Хуже того, если Предположим, имеются средства увеличения размера массива А, содержащего элементы вектора S. Безусловно, в Java (и других языках программирования) в действительности невозможно увеличить размер массива, его длина ограничена заданным значением и вызове метода insertAtRank выполняются следующие операции: 1) создается новый массив 2) копируется A[i] в B[i], где / = 0, ..., N- 1; 3) присваивается А = В, то есть используется В как массив, содержащий S. Данная стратегия замещения массивов известна как расширяемый массив, так как она как бы продолжает исходный массив для размещения. C точки зрения эффективности приведенная стратегия замещения массивов кажется относительно медленной, так как для замещения одного массива при необходимости вставки элемента требуется O{n) времени, что не очень приемлемо. Тем не менее, следует отметить, что после замещения массива появляется возможность добавления Утверждение 5.1. Пусть S— вектор, реализованный на основе расширяемого массива А, как было описано выше. Общее время выполнения последовательности п операций проталкивания в массиве S при условии, что S изначально пустой, а А имеет размер N= n, есть O(n). Для доступа к месту расположения элемента в списке может применяться не только понятие разряда. Если имеется список S, реализованный на основе однонаправленного или двусвязного списка, более удобным и эффективным является использование для определения места доступа и обновления списка узлов вместо разрядов. Рассмотрим абстрактное понятие узла, описывающего определенное «место» в списке, не вдаваясь в детали реализации списка. Пусть S— линейный список, реализованный с помощью двусвязного списка. Простейшей его реализацией будет структура последовательно связанных компонент, изображенная на рис.  Каждая компонента в этой структуре состоит из двух ячеек памяти. Первая ячейка содержит сам элемент, вторая — указатель следующего элемента. Это можно реализовать в виде двух массивов, которые названы ИМЯ и СЛЕДУЮЩАЯ. 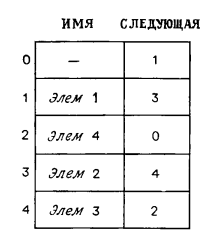 Если КОМПОНЕНТА — индекс в рассматриваемом массиве, то ИМЯ [КОМПОНЕНТА] — сам элемент, хранящийся там, а СЛЕДУЮЩАЯ [КОМПОНЕНТА]— индекс следующего элемента в списке (если такой элемент существует). Если КОМПОНЕНТА — индекс последнего элемента в этом списке, то СЛЕДУЮЩАЯ[КОМПОНЕНТА]=0. procedure ВСТАВИТЬЭЛЕМЕНТ(СВОБОДНАЯ, ПОЗИЦИЯ): begin ИМЯ[СВОБОДНАЯ] СЛЕДУЮЩАЯ[СВОБОДНАЯ] СЛЕДУЮЩАЯ [ПОЗИЦИЯ] end Очевидным образом, время выполнения операции вставки не зависит от длины списка. Часто в один и тот же массив вкладываются несколько списков. Обычно один из этих списков состоит из незанятых ячеек (будем называть его свободным списком). Для добавления элемента к списку А можно так изменить процедуру ВСТАВИТЬ, чтобы незанятая ячейка получалась путем удаления первой ячейки в свободном списке. При удалении элемента из списка А соответствующая ячейка возвращается в свободный список для будущего употребления. Реализация связным списком позволяет выделять память динамически (в периоде выполнения) - столько и тогда, сколько и когда действительно требуется. Двусвязный список используется, когда необходим равноправный доступ, как к следующему, так и предшествующему элементам последовательности.
Еще две основные операции над списками — конкатенация (сцепление) двух списков, в результате которой образуется единственный список, и обратная к ней операция расцепления списка, стоящего после некоторого элемента, результатом которой будут два списка. Конкатенацию можно выполнить за ограниченное (постоянной величиной) число шагов, включив в представление списка еще один указатель. Этот указатель дает индекс последней компоненты списка и тем самым позволяет обойтись без просмотра всего списка для определения его последнего элемента. Расцепление можно сделать за ограниченное (постоянной величиной) время, если известен индекс компоненты, непосредственно предшествующей месту расцепления. Списки можно сделать проходимыми в обоих направлениях, если добавить еще один массив, называемый ПРЕДЫДУЩАЯ. Значение ПРЕДЫДУЩАЯ[i] равно ячейке, в которой помещается тот элемент списка, который стоит непосредственно перед элементом из ячейки. Список такого рода называется дважды связанным. Из дважды связанного списка можно удалить элемент или вставить в него элемент, не зная ячейку, где находится предыдущий элемент. В определенном смысле близким к понятию последовательность является понятие «Разреженный массив» (SparseArray) – массив в котором ненулевые элементы составляют лишь малую долю от общего числа элементов. Такие вектора и матрицы часто встречаются в практических задачах линейной алгебры. С одной стороны, с концептуальной точки зрения – это статические типы (и структуры) данных с классическим набором операций линейной алгебры. Но с другой стороны, количество (и места) нулей в таком векторе может изменяться – его можно трактовать как последовательность ненулевых элементов с индексом в качестве позиции элемента. Интересный и во многих отношениях полезный пример рассмотрен в классическом энциклопедическом труде «Искусство программирования» Кнут Д.Э. [14], задача «Осевое преобразование разреженной матрицы» т.1. п.2.2.6. «Массивы и ортогональные списки». В алгоритме решения этой задачи используется ортогонально (по строкам и столбцам) связное представление для разреженной матрицы, которое можно определить как базовый класс «Ортогональные списки» с парой индексов в качестве позиции элемента и операциями, аналогичными приведенным для последовательностей. А наследованием можно определить класс для разреженных матриц с классическим набором операций линейной алгебры. Отметим другой вариант трактовки разреженных массивов – как разновидность АТД Словарь с парой индексов в качестве ключа элемента. Линейные структуры данных, массивы и линейные связные списковые структуры (с указателями), используются и для представления множеств (и наборов). Со списком часто работают очень ограниченными приемами. Например, элементы добавляются или удаляются только на конце списка. Иными словами, элементы вставляются и удаляются по принципу "последний вошел — первый вышел". В этом случае список называют стеком или магазином. Часто стек реализуется в виде одного массива. Например, список Элем 1, Элем 2, Элем 3 можно было бы хранить в массиве ИМЯ, как показано на рисунке 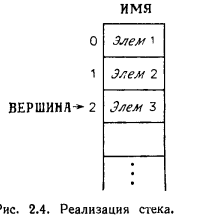 Переменная ВЕРШИНА является указателем последнего элемента, добавленного к стеку. Чтобы добавить (ЗАТОЛКНУТЬ) новый элемент в стек, значение ВЕРШИНА увеличивают на 1, а затем помещают новый элемент в ИМЯ1ВЕРШИНА]. (Поскольку массив ИМЯ имеет конечную длину Другой специальный вид списка — очередь, т. е. список, в который элементы всегда добавляются с одного (переднего) конца, а удаляются с другого. Как и стек, очередь можно реализовать одним массивом, как показано на рис. 2.5, где приведена очередь, содержащая список из элементов Р, Q, R, S, Т. 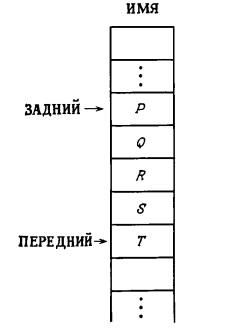 Реализация очереди в виде одного массива Два указателя обозначают ячейки текущего переднего и заднего концов очереди. Чтобы добавить (ВПИСАТЬ) новый элемент к очереди, как и в случае стека, полагают ПЕРЕДНИЙ = ПЕРЕДНИЙ +1 и помещают новый элемент в ИМЯ1ПЕРЕДНИЙ]. Чтобы удалить (ВЫПИСАТЬ) элемент из очереди, заменяют ЗАДНИЙ на ЗАДНИЙ +1. Заметьте, что эта техника с точки зрения доступа к элементам основана на принципе "первый вошел — первый вышел". Поскольку массив ИМЯ имеет конечную длину, скажем Элементы, расположенные в виде списка, сами могут быть сложными структурами. Работая, например, со списком массивов, мы на самом деле не добавляем и не удаляем массивы, ибо каждое добавление или удаление потребовало бы времени, пропорционального размеру массива. Вместо этого мы добавляем или удаляем указатели массивов. Таким образом, сложную структуру можно добавить или удалить за фиксированное время, не зависящее от ее размера. Представления множеств Обычно списки применяются для представления множеств. При этом объем памяти, необходимый для представления множества, пропорционален числу его элементов. Время, требуемое для выполнения операции над множествами, зависит от природы операции. Например, пусть А и В — два множества. Операция Подобным же образом операция Другой способ представления множества, отличный от представления его в виде списка,— представление в виде двоичного (битового) вектора. Пусть U — универсальное множество (т. е. все рассматриваемые множества являются его подмножествами), состоящее из Для представления множеств посредством характеристических 0-1-векторов необходимо иметь оценку мощности универсального множества (т.к. массив – статическая структура данных) и установить взаимно однозначное соответствие18 между элементами универсального множества и областью допустимых значений индексов массива-вектора. При таком представлении базовые операции для множеств реализуются с хорошими характеристиками по времени, но по памяти оно может оказаться расточительным, если универсальное множество очень большое, а используемые его подмножества относительно очень маленькие (получаем случай очень разреженного массива). Для реализации теоретико-множественных операций (, , разность) потребуется полный просмотр такого вектора (размером, равным мощности универсального множества). Представление множеств линейными связными списками устраняет ограничения, свойственные статическим структурам данных, но при этом теряются возможности эффективного прямого доступа по индексу – операция Принадлежать (Найти элемент) реализуема только просмотром списка. Аналогичные характеристики для представления упорядоченных множеств массивами и линейными связными списками, причем появляются проблемы поддержания отношения порядка и соответствующие варианты решения этих проблем. Для представления более сложных АТД используются более сложно организованные структуры данных. |